This post has been languishing in draft form for well over a month thanks to travel and me losing interest in the subject. I’m going to try to get it out of the way quickly and move on.
Last time I noted the presence of apparent outliers in the relationship between stellar mass and rotation velocity and pointed out that most of them are due to model failures of various sorts rather than “cosmic variance.” That would seem to suggest the need for some sample refinement, and the question then becomes how to trim the sample in a way that’s reproducible.
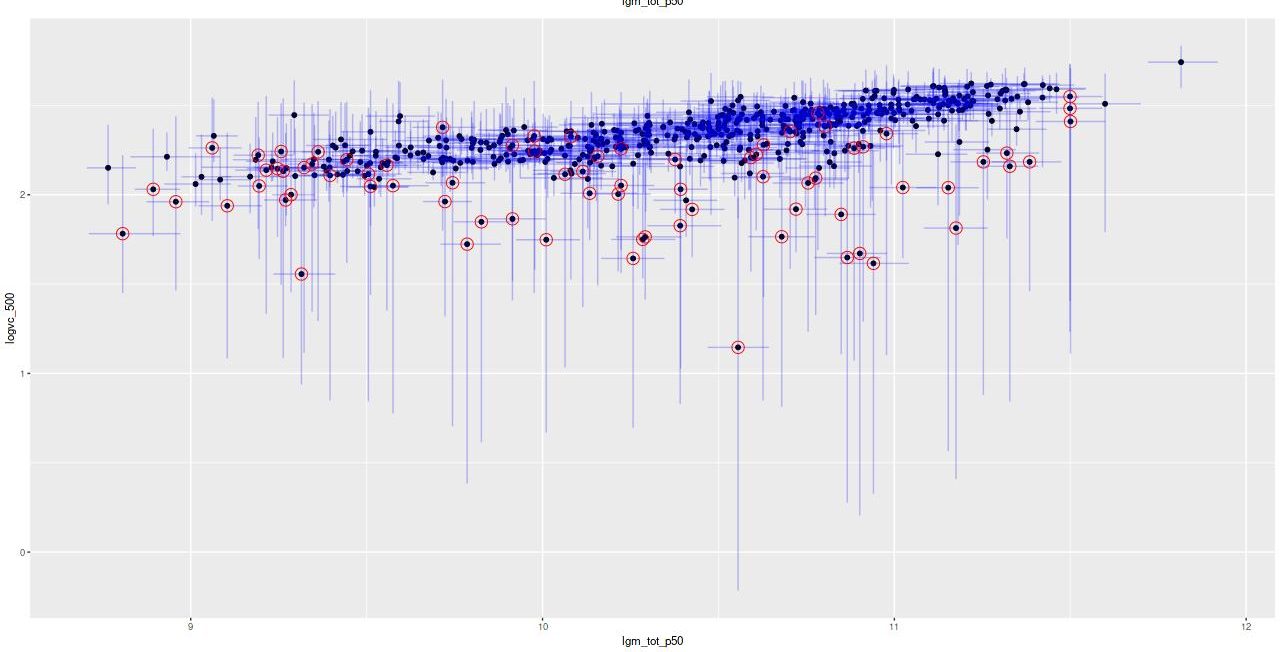
An obvious comment is that all of the outliers fall below the general trend and (less obviously perhaps) most have very large posterior uncertainties as well. This suggests a simple selection criterion: remove the measurements which have a small ratio of posterior mean to posterior standard deviation of rotation velocity. Using the asymptotic circular velocity v_c in the atan mean function and setting the threshold to 3 standard deviations the sample members that are selected for removal are circled in red below. This is certainly effective at removing outliers but it’s a little too indiscriminate — a number of points that closely follow the trend are selected for removal and in particular 19 out of 52 points with stellar masses less than \(10^{9.5} M_\odot\) are selected. But, let’s look at the results for this trimmed sample.
Posterior distribution of asymptotic velocity `v_c` vs stellar mass. Circled points have posterior mean(v_c)/sd(v_c) < 3.
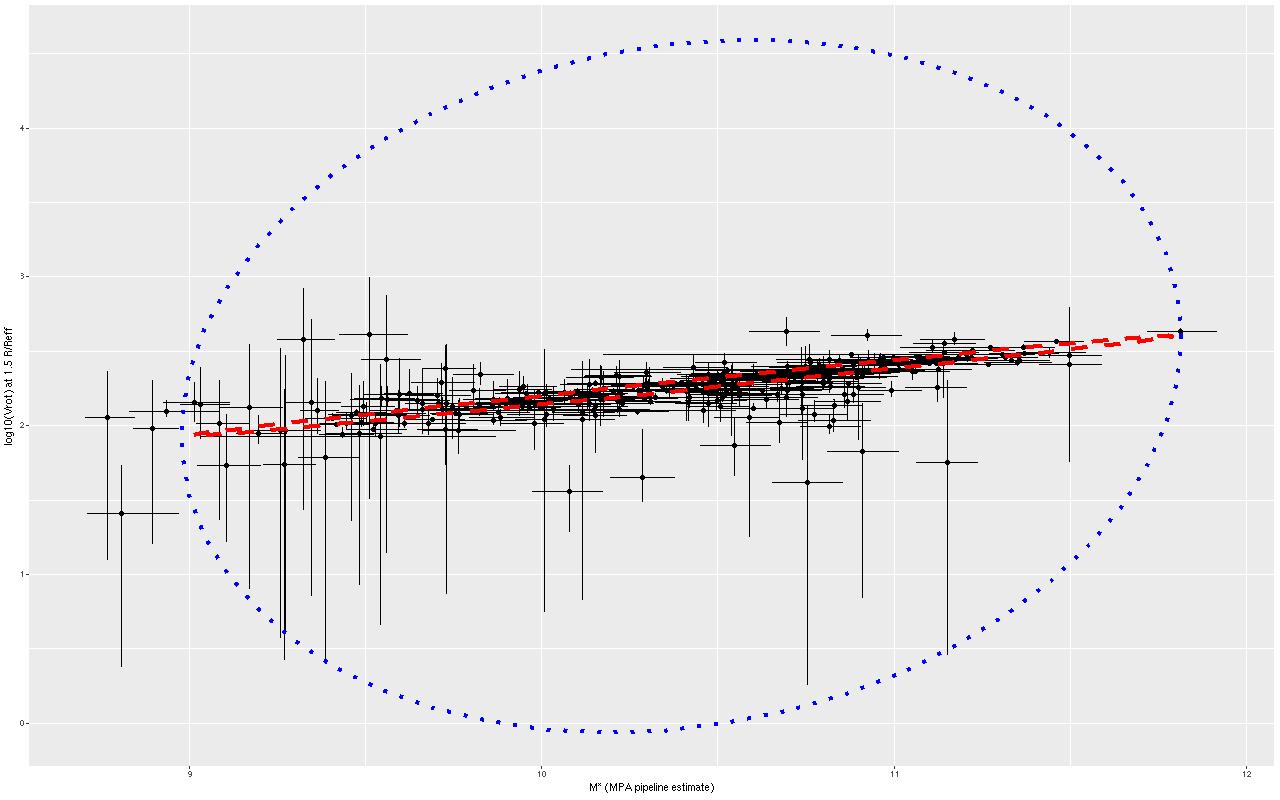
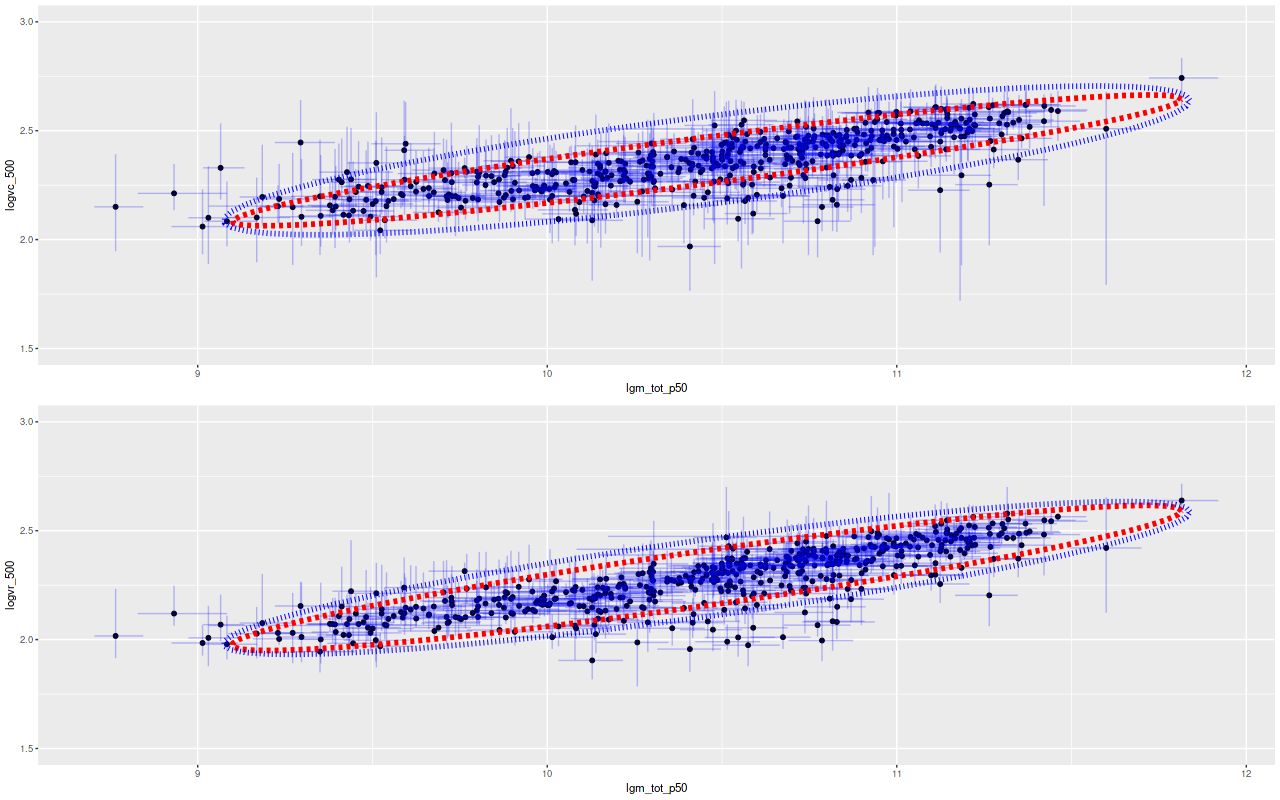
Again I model the joint relationship between mass and circular velocity using my Stan implementation of Bovy, Hogg, and Roweis’s “Extreme deconvolution” with the simplification of assuming gaussian errors in both variables. The results are shown below for both circular velocity fiducials. Recall from my previous post on this subject the dotted red ellipse is a 95% joint confidence interval for the intrinsic relationship while the outer blue one is a 95% confidence ellipse for repeated measurements. Compared to the first time I performed this exercise the former ellipse is “fatter,” indicating more “cosmic variance” than was inferred from the earlier model. I attribute this to a better and more flexible model. Notice also the confidence region for repeated measurements is tighter than previously, reflecting tighter error bars for model posteriors.
Joint distribution of stellar mass and velocity by “Extreme deconvolution.” Inner ellipse: 95% joint confidence region for the intrinsic relationship. Outer ellipse: 95% confidence ellipse for new data.
Top: Asymptotic circular velocity v_c.
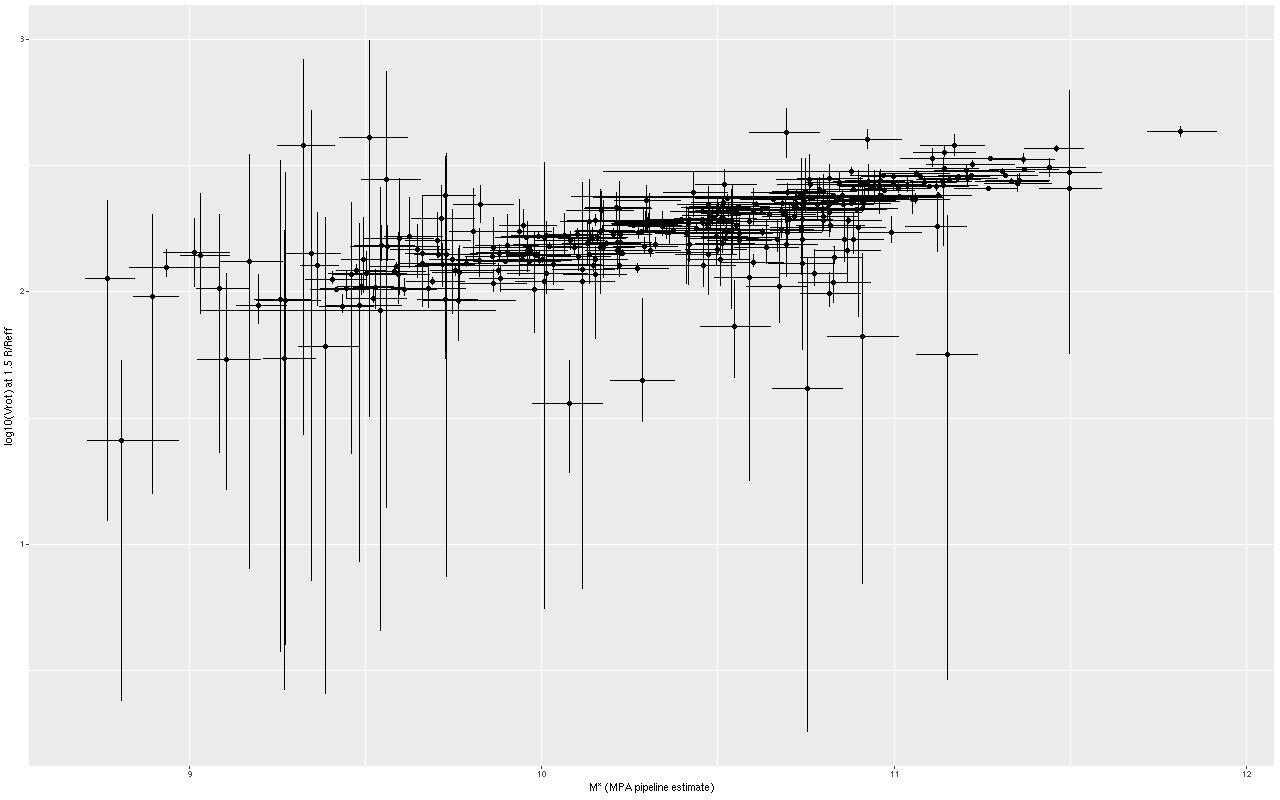
Bottom: Circular velocity at 1.5 r_eff.
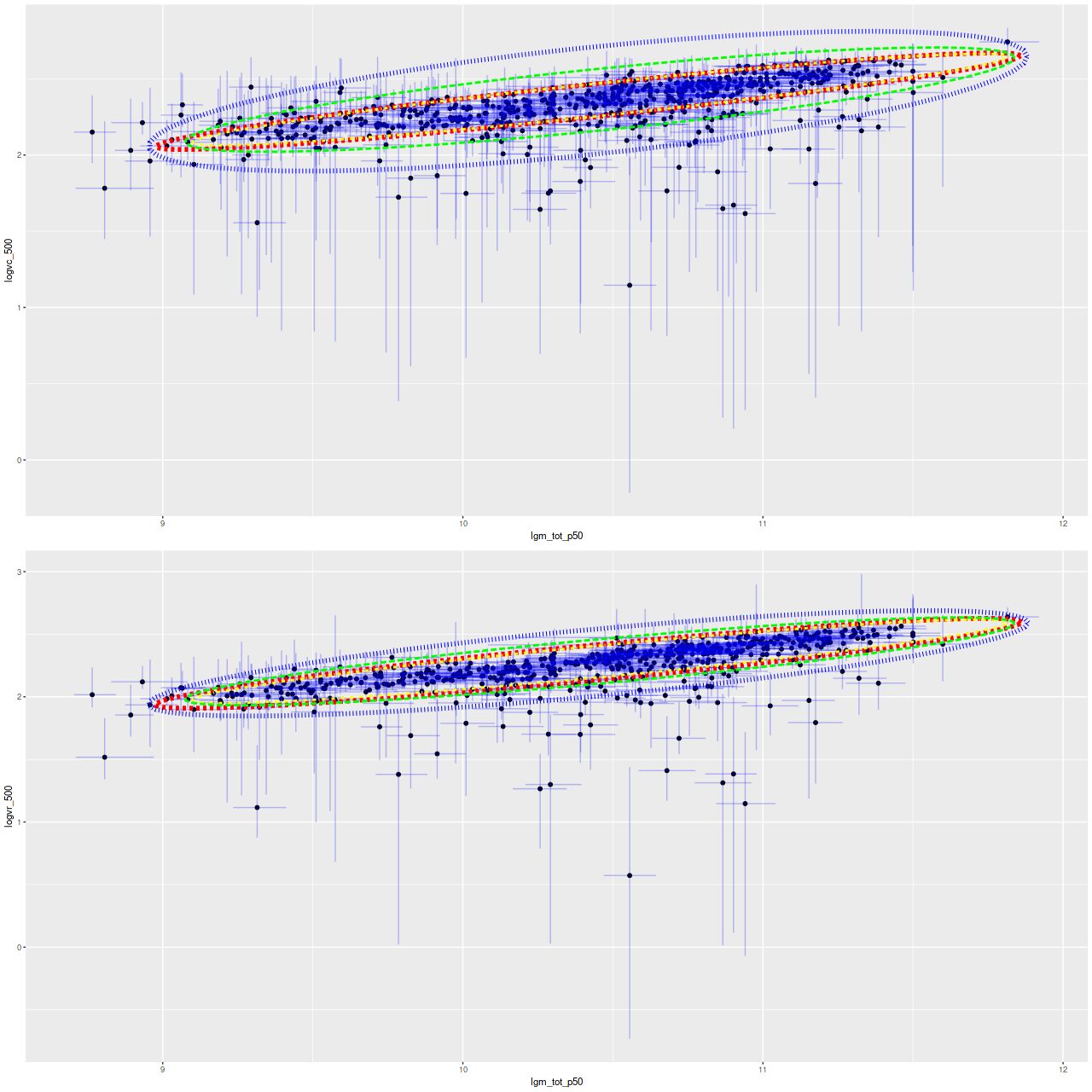
Now here is something of a surprise: below are the model results for the full sample compared to the trimmed one. The red and yellow ellipses are the estimated intrinsic relations using the full and trimmed samples, while green and blue are for repeated measurements. The estimated intrinsic relationships are nearly identical despite the many outliers. So, even though this model wasn’t formulated to be “robust” as the term is usually understood in statistics in practice it is, at least as regards to the important inferences in this application.
Joint distribution of stellar mass and velocity by “Extreme deconvolution” (complete sample). Inner ellipse: 95% joint confidence region for the intrinsic relationship. Outer ellipse: 95% confidence ellipse for new data. Top: Asymptotic circular velocity v_c. Bottom: Circular velocity at 1.5 r_eff.
Finally the slope, that is the exponent in the stellar mass Tully-Fisher relationship \(M^* \sim V_{rot}^\gamma\) is estimated as the (inverse of) slope of the major axis of the inner ellipses in the above plots. The posterior mean and 95% marginal confidence intervals for the two velocity measures and both samples are:
v_c (subset 1) \(4.81^{+0.28}_{-0.25}\)
v_c (all) \(4.81^{+0.28}_{-0.25}\)
v_r (subset 1) \(4.36^{+0.23}_{-0.20}\)
v_r (all) \(4.33^{+0.23}_{-0.21}\)
Does this suggest some tension with the value of 4 determined by McGaugh et al. (2000)? Not necessarily. For one thing this is properly an estimate of the stellar mass – velocity relationship, not the baryonic one. Generally lower stellar mass galaxies will have higher gas fractions than high stellar mass ones, so a proper accounting for that would shift the slope towards lower values. Also, and as can be seen here, both the choice of fiducial velocity and analysis method matter. This has been discussed recently in some detail by Lelli et al. (2019)1These two papers have two authors in common..
Next time, back to star formation history modeling.
Last time I left off with the remark that while most of the sample of disk galaxies clearly exhibits a tight relationship between circular velocity and stellar mass, there are some apparent outliers as well. While some “cosmic variance” is expected most of the apparent outliers are due to model failures, which have several possible causes:
Violation of the physical assumptions of the model, namely that the stars and gas are rotating (together) in the plane of a thin disk that’s moderately inclined to our line of sight (see my original post on this topic).
Errors in the photometry. I use two photometric quantities (specifically nsa_elpetro_ba and nsa_elpetro_phi) from the MaNGA DRPALL catalog to set priors for the kinematic parameters cos_i and phi(cosine of the disk inclination and angle to receding side) and also to initialize the sampler. Since proper and in practice fairly informative priors are required for these parameters errors here will propagate into the models, sometimes in ways that are fatal. I’ll look in more detail at some examples below.
Bad velocity data.
Not enough data.
Sampler convergence failures with no obvious cause.
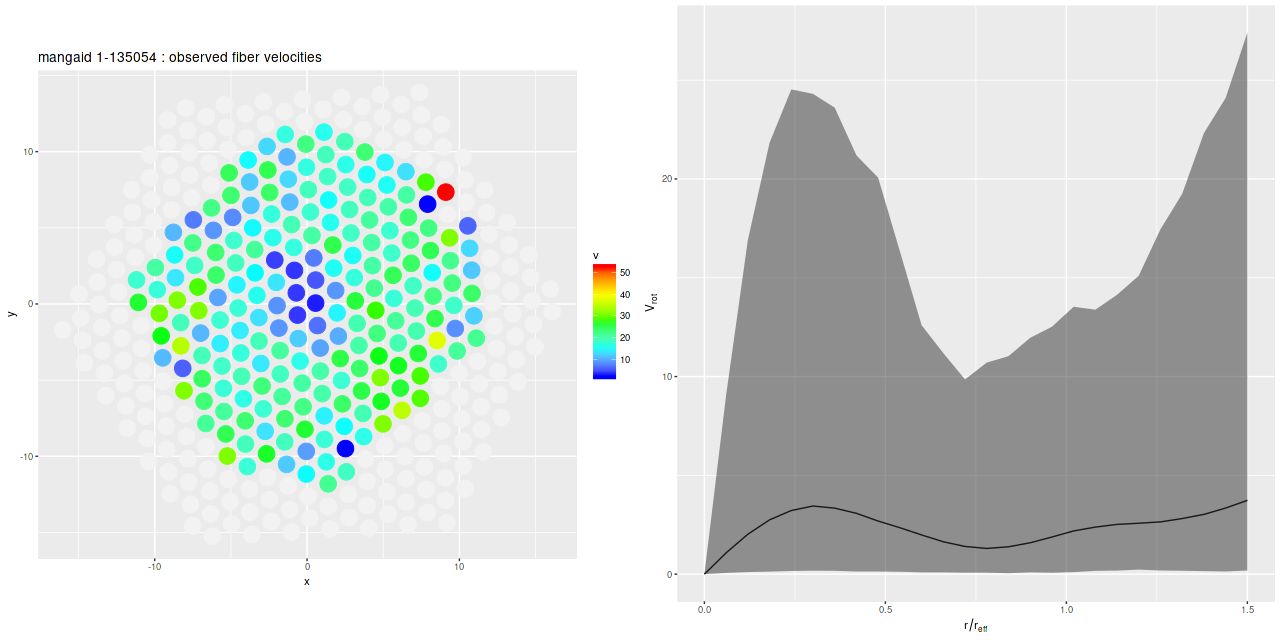
The first two bullet points are closely related: most of the failures to satisfy the physical assumptions are directly related to errors in the photometric decompositions. One fairly common failure was galaxies that were too nearly face on to obtain reliable rotation curves. As an example here is the galaxy with the lowest estimated rotation velocity in the sample, mangaid 1-135054 (plateifu 8550-12703):
Mangaid 1-135054 (plateifu 8550-12703). (L) Measured velocity field and (R) posterior predictive estimate of circular velocity with 95% confidence band.
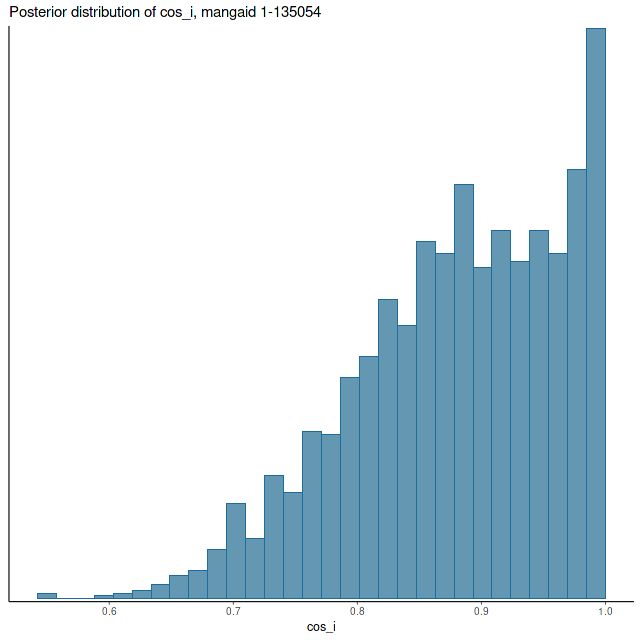
Besides showing no sign of rotation the velocity field hints at possible large scale, low velocity outflow in the central region. There are also a few apparent outliers, although these had little effect on model results. Fortunately the model output gives us plenty of clues that the results shouldn’t be trusted. The median circular velocity estimate is unrealistically low with very large posterior uncertainty (above right), while the posterior marginal density for cos_ihas a mode near 1 and also very large uncertainty (below).
Mangaid 1-135054 (plateifu 8550-12703). Posterior distribution of cosine of disk inclination.
Zooming out a bit on SDSS imaging gives a likely explanation for the peculiar velocity field. The elliptical galaxy just to the NW has nearly the same redshift (the velocity difference is ∼75 km/sec) and is almost certainly interacting with our target.
MaNGA target and companion; credit SDSS
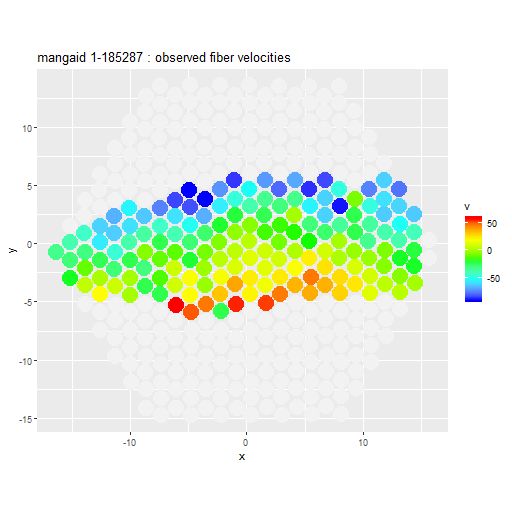
A key assumption in using photometric properties as proxies for kinematic quantities is that disk galaxies have intrinsically circular surface brightness profiles. This is never quite the case in practice and sometimes morphological features like strong bars can make this assumption catastrophically wrong. Here was perhaps the most extreme example in DR14:
mangaid 1-185287 (plateifu 8252-12704). SDSS thumbnail with IFU overlay
mangaid 1-185287 (plateifu 8252-12704) Measured velocity field from stacked RSS spectra
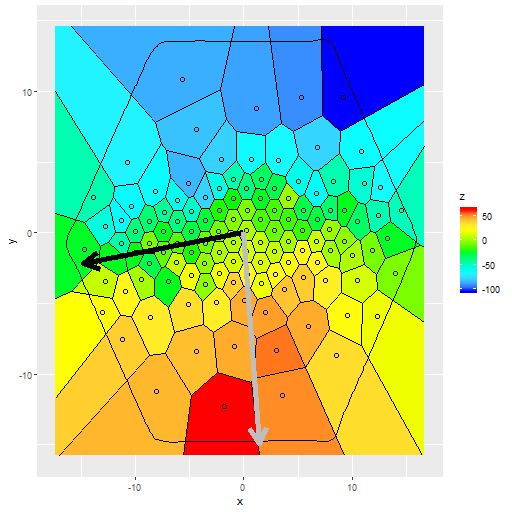
The photometric major axis angle was estimated to be 98.4o, that is just south of east, while the position angle of the maximum recession velocity is close to due south. When I first examined this velocity field I had a hard time reconciling it with rotation in a thin disk. This was before I learned how to do Voronoi binning though. The image below shows the binned velocity field (with a target S/N of 6.25). This shows that the relative velocity does increase on a roughly north to south line, indicating that this is indeed a rotating disk galaxy.
mangaid 1-185287 (plateifu 8252-12704) Measured velocity field from binned RSS spectra. Black arrow indicates major axis position angle from photometry. Gray arrow: position angle of receding side from velocity model with prior guess of 180o
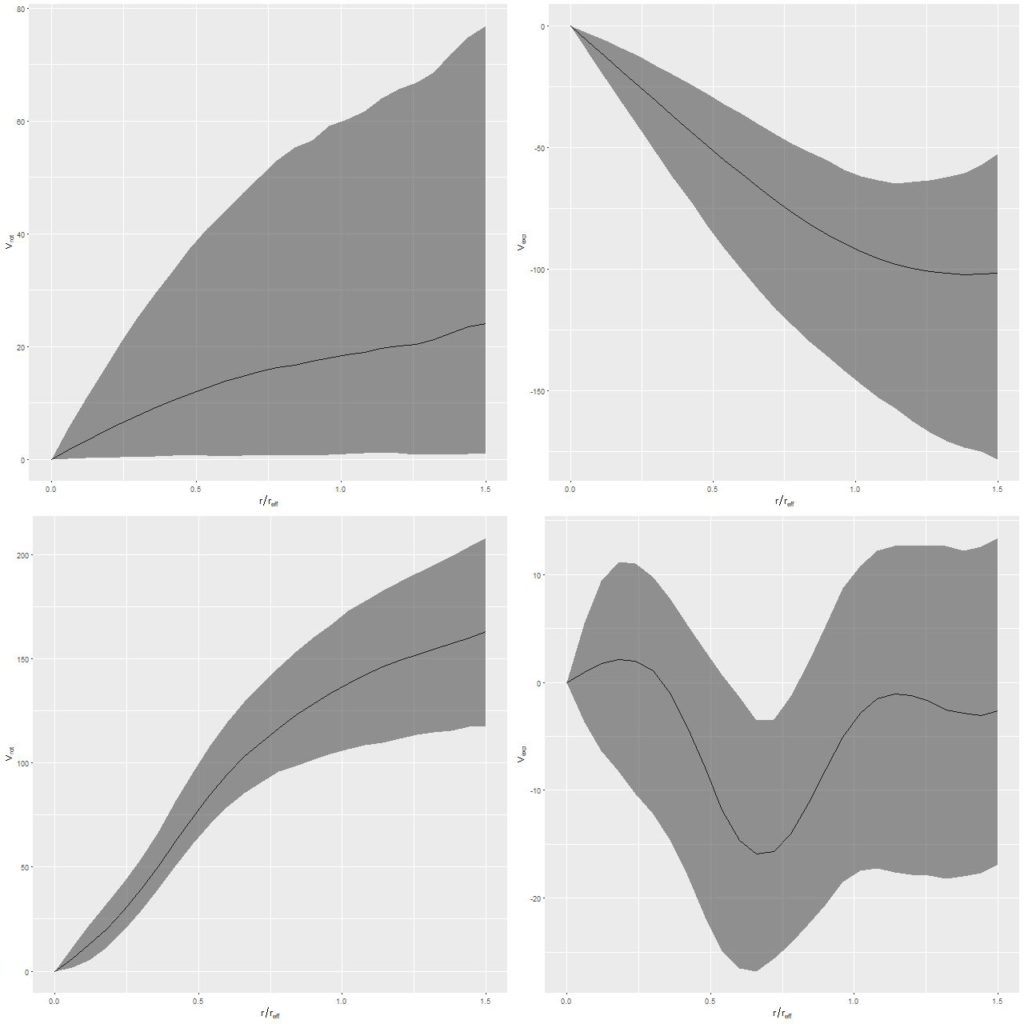
I mentioned in an earlier post that without a proper prior on the kinematic position angle phi these models are inherently multi-modal (in fact they are infinitely modal and therefore would have improper posteriors). The solution to that of course is to have a proper prior. But if the prior is seriously in error the posterior estimates for the components of the velocity will end up scrambled as can be seen in the top row of the graph below, which shows the posterior distributions of the circular and “expansion” velocities1Remember that the photometric position angle is determined modulo π while the direction to the maximum recession velocity is measured modulo 2π. We don’t care about a π radian error in the prior though because that just flips the signs of the velocity components, which causes no sampling issues and is trivially fixable in the generated quantities block. It’s smaller errors that cause problems.
The obvious solution to a bad prior is to correct it2Using the data you’re trying to model to establish a prior is, technically, cheating (the polite term is “Empirical Bayes”), but this seems a relatively benign use of the data., which is easy enough. The bottom row shows the results of re-running the model with a prior phicentered on 180o and the same data. Now both the circular and expansion velocity curves are at least plausible. The posterior mean of phiis ≈185o, which is very close to correct as can be seen in the binned velocity field shown above.
mangaid 1-185287 (plateifu 8252-12704) Top row: model rotation (L) and expansion (R) velocities with prior for major axis angle taken from photometry (phi = 98.4). Bottom row: same but with prior phi = 180o.
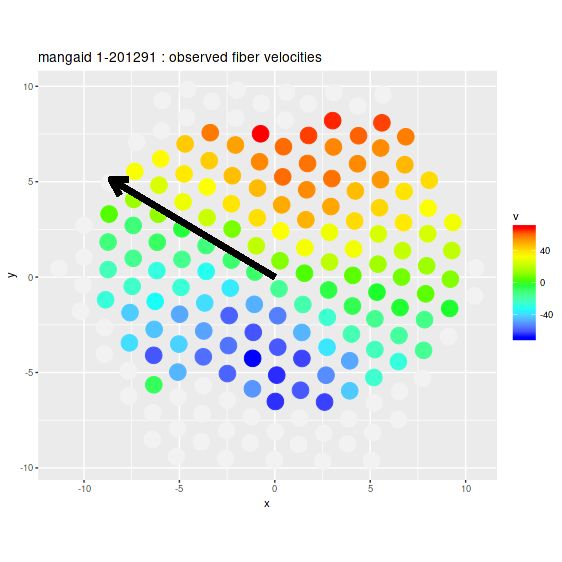
One more example. Bars were the most common cause of misleading photometric decompositions, but not the only one. Some galaxies are just asymmetrical. Here is the one that had the largest offset between the photometric and kinematic position angles:
And the velocity field (again this agrees well with the Marvin measurements of the data cube):
mangaid 1-201291 (plateifu 8145-6103). Velocity field from stacked RSS spectra with major axis angle from nsa_elpetro_phi
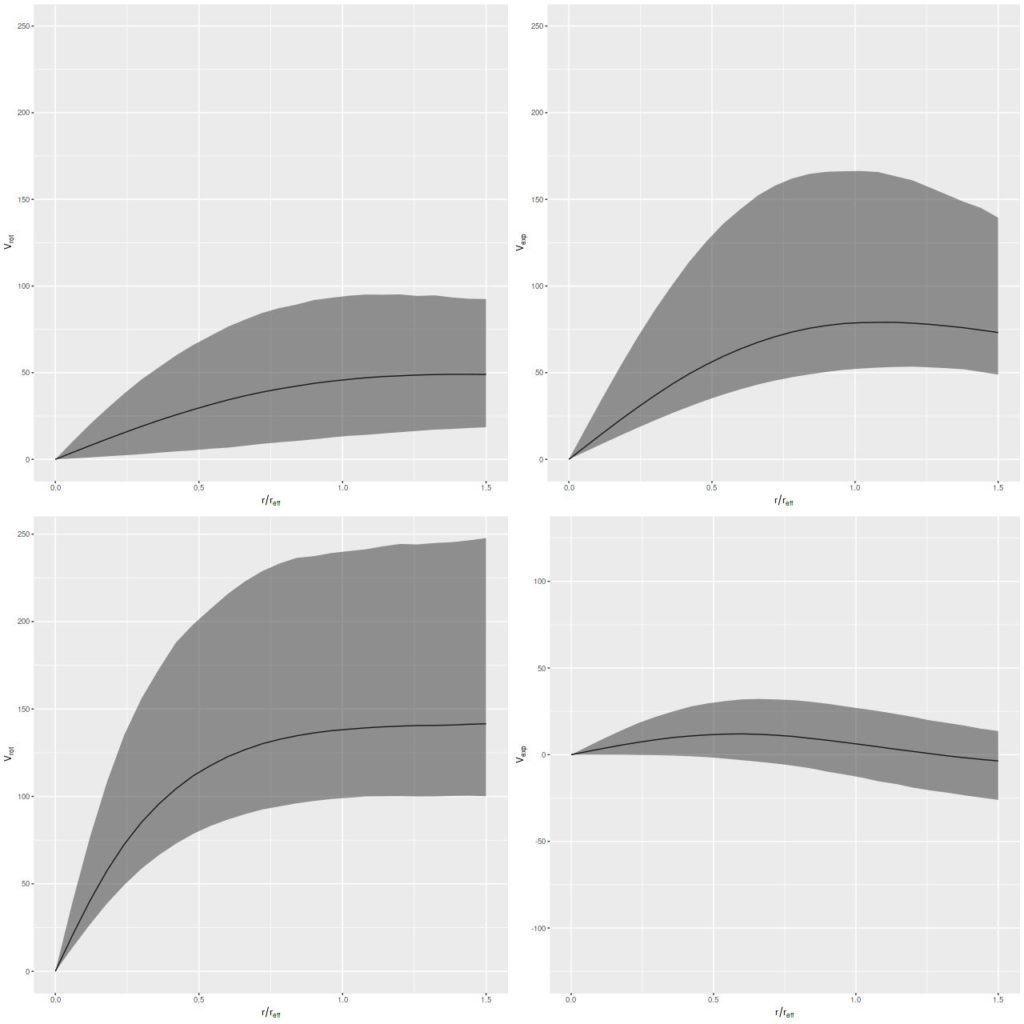
This time the velocity field looks unremarkable, but again because of the prior the estimated circular and expansion velocities are scrambled together. And once again also, changing the prior to be centered on the approximate actual position angle of the receding side produces reasonable estimates for both:
mangaid 1-201291 (plateifu 8145-6103). Top: Posterior predictive distributions of circular and expansion velocity with prior on `phi` from photometry. Bottom: Same with prior centered on -10o
Next up, I’ll take a more holistic look at final sample selection, and maybe get to results.
As I mentioned in the previous two posts SDSS Data Release 15 went public back in December and a query for “normal” disk galaxies as judged by Galaxy Zoo 2 classifiers returned 588 hits. I’ve finally run the GP velocity models on all of the new data and made a second run on around 40 that were contaminated by foreground stars or neighboring galaxies. So far I haven’t found an alternative to selecting these by eye and doing the masking manually, so that’s an error prone process. The month+ long gap between postings by the way was due to travel — my computer wasn’t grinding away on these models for all that time. As I mentioned last post the sampling properties including execution time of the GP model with arctangent mean function are usually quite favorable using Stan. The median wall time for these runs was about a minute, with a range from 25 to 1600 seconds. All model runs used 500 warmup iterations and 500 post-warmup with 4 chains run in parallel. This is more than enough for inference.
Before I discuss the results I’ll show them. As I did for the first pass at this way back in July I retrieved stellar mass and uncertainty estimates made by the MPA-JHU group from CasJobs; all but a handful also have mass estimates from the Wisconsin group. I may look at those later but don’t anticipate any very significant differences.
There are now at least two plausible choices for reference circular velocities: the velocity at a fiducial radius, and again I choose 1.5 effective radii since the MaNGA IFUs are meant to cover out to that radius in the primary sample. The other obvious choice is the asymptotic velocity vc in the arctangent mean function. This seems in principle to be the better choice since it estimates the circular velocity in the flat part of the rotation curve, but it might be a considerable extrapolation from the actual data in some cases.
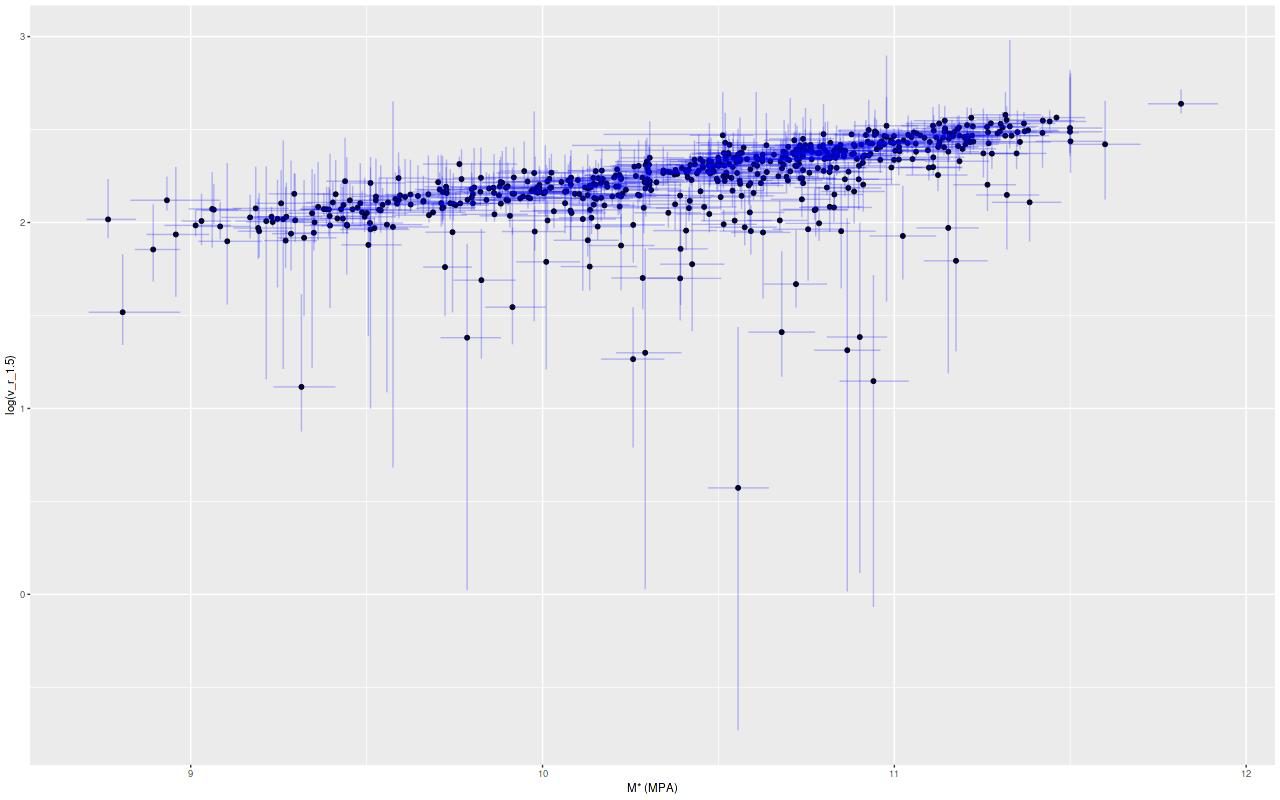
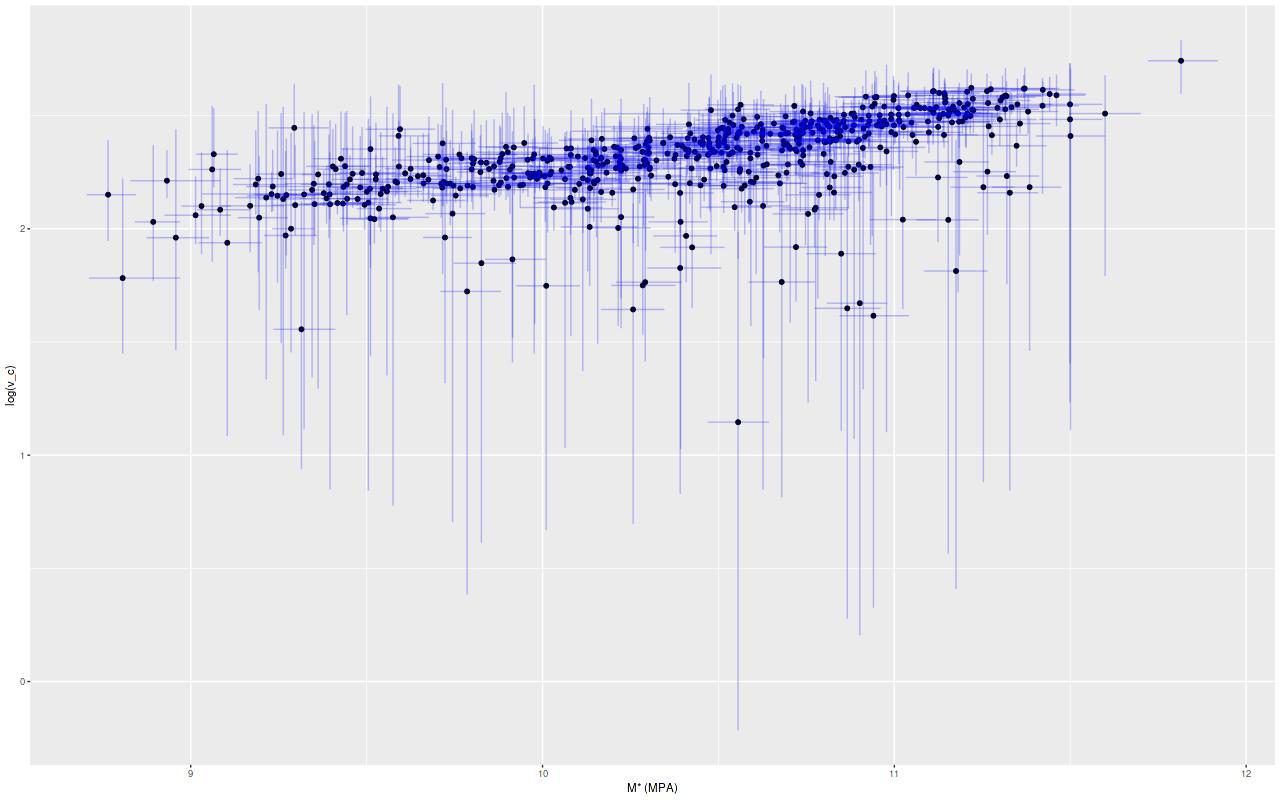
Both sets of results are shown below for all model runs that ran to completion (N=582). Plotted are the median, 2.5, and 97.5 percentiles (≈ ± 2σ) of posterior predictions for the log-circular velocity at 1.5reff (top graph) and the same quantiles of the posteriors of the parameter v_c (bottom graph). These are plotted against the median, 16, and 84 percentiles (≈ ± 1σ) of the total stellar mass estimates per the MPA group.
Estimated rotation velocity at 1.5 effective radii vs. stellar mass estimate from MPA-JHU models
Estimated asymptotic rotation velocity against stellar mass from MPA-JHU models. Vertical error bars mark the 2.5 and 97.5 percentiles of the model posteriors of (log) velocity in km/sec. Horizontal error bars mark the 16 and 84 percentiles model posteriors of (log) stellar mass.
Evidently most of the sample follows a tight linear relationship with either measure of circular velocity, but there are some apparent outliers as well. I’m feeling a bit blocked right now, so I’ll end the post here. Next time I’ll look at some of the causes of model failure, what to do about them, and get to the results.
When I first began modeling disk galaxy rotation curves using low order polynomials for the circular velocity I noticed two rather frequent systematics in the model residuals:
Lobe like areas symmetrically located around the nucleus with approximately equal and opposite signs. Sometimes these are co-located with bar ends but a bar is not always obvious.
A contrast of a few 10’s of kilometers/sec between spiral arms and interarm regions. This is rather common in grand design spirals.
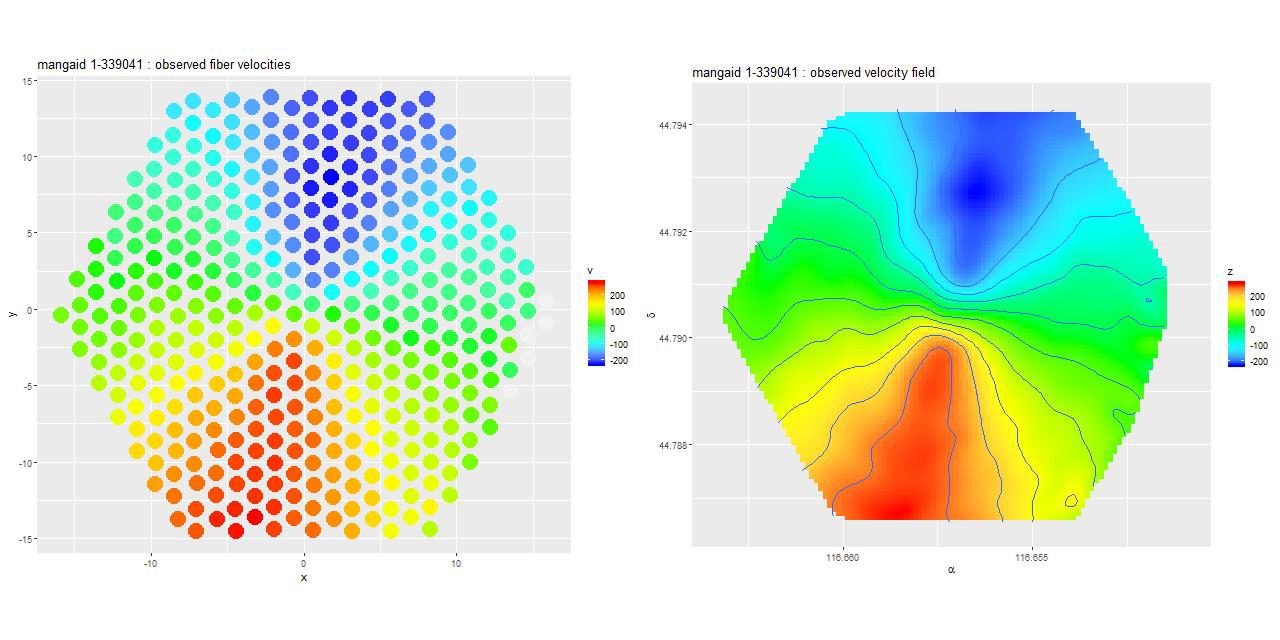
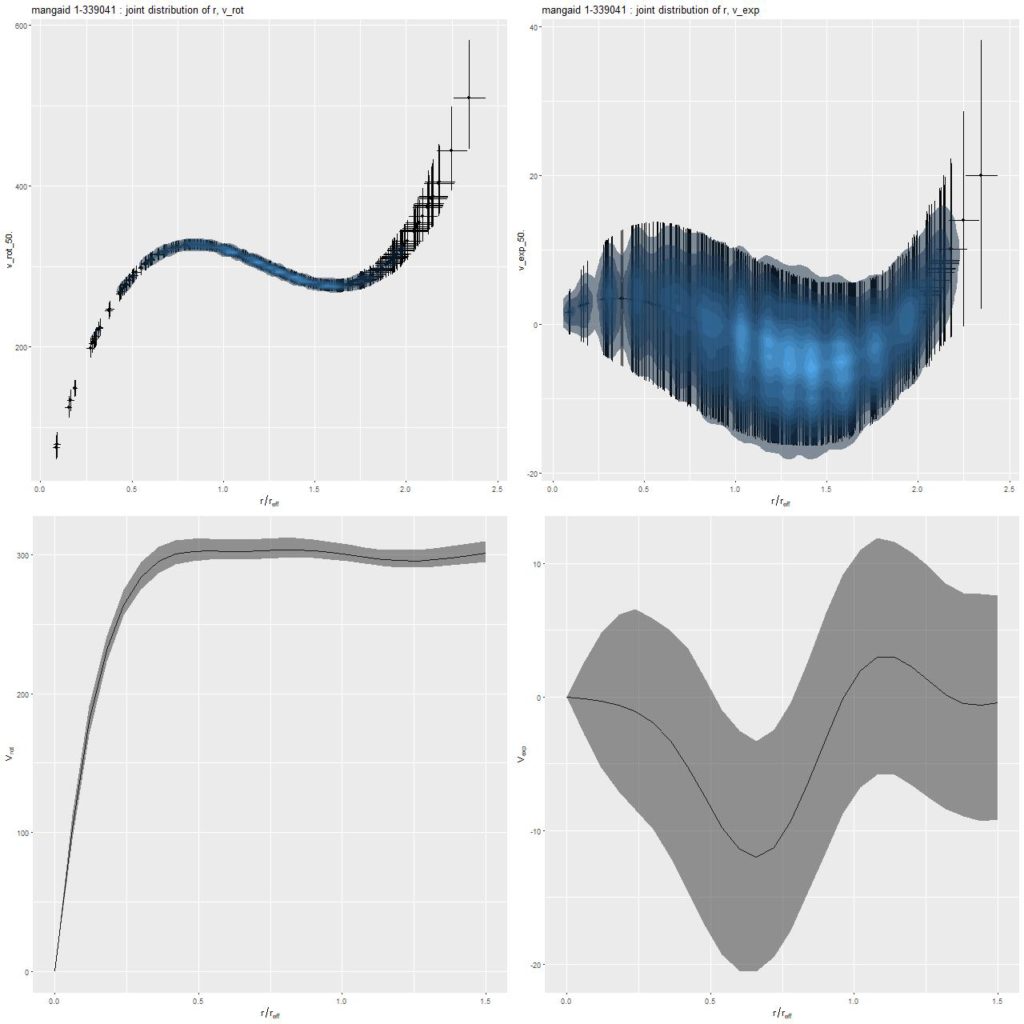
Here’s a particularly dramatic example of symmetrical lobes in mangaid 1-339041 (plateifu 8138-12704), IAU name SDSS J074637.70+444725.8. First, here are the measured line of sight velocities for the fiber spectra:
(L) Velocity field measured from stacked RSS file
(R) Interpolated velocity field
mangaid 1-339041 (plateifu 8138-12704)
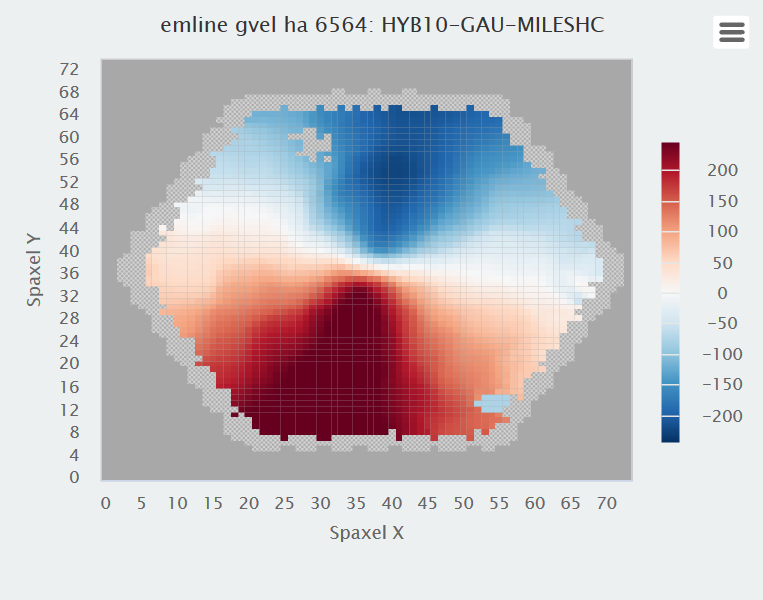
The left plot shows the actual measurements from the stacked RSS file. The right is just an interpolated version of the left. Since value added data is now available it’s worth comparing this to output from “Marvin“. For reference here is the Hα velocity map:
Hα velocity map from MaNGA DAP
It’s hard to tell in any detail, but these look similar enough and the stellar velocity field as measured by the DAP also looks similar.
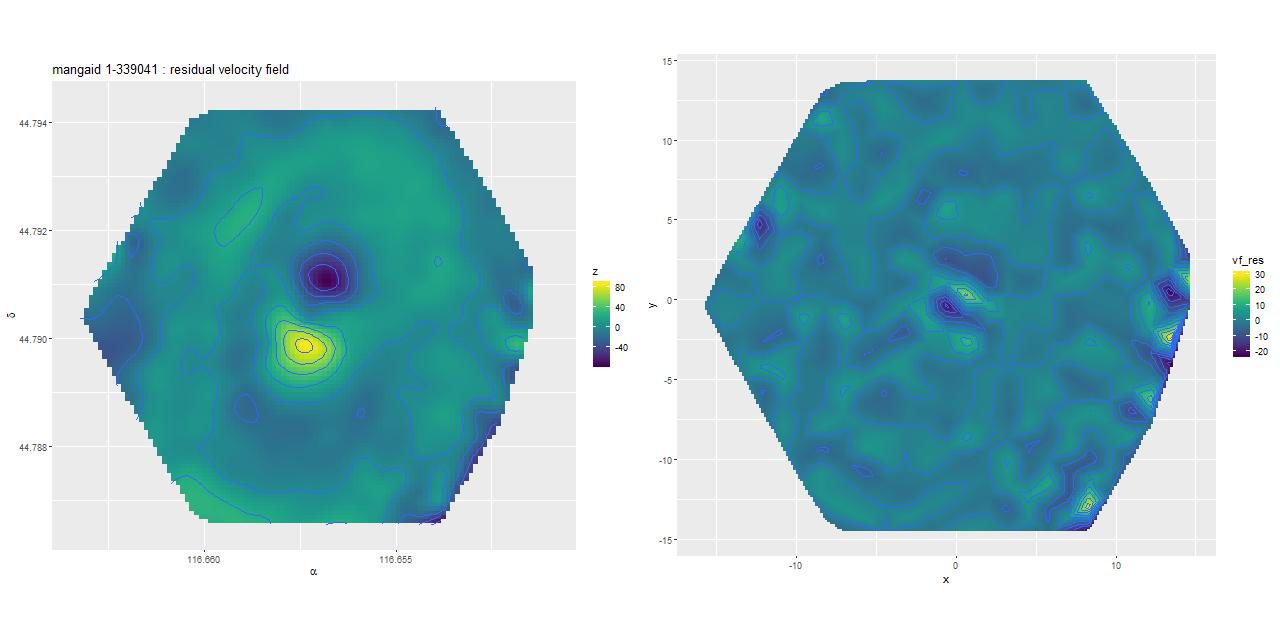
Next, here are the mean residuals from the posterior predictive fits shown as interpolated maps derived from the fits at the observed positions. As promised the left hand map from the low order polynomial fit has prominent lobes situated on either side of the nucleus and a more subtle contrast between spiral arms and interarm regions. The right hand map from the GP model appears to be largely free of systematic patterns. Why the difference?
Mean residuals from models:
(L) Polynomial rotation curve model
(R) GP model with atan mean function
In this case the arctangent mean function I introduced in the last post worked very well, with the estimated circular velocity rising quickly to an asymptotic value of ∼300km/s. The low order polynomial representation is necessarily constrained by the possible shapes of a low order polynomial (in this case cubic), resulting in a shallower initial slope and a first local maximum farther out than in the GP model. The lobed residuals in the polynomial model are therefore seen to be due to an inner disk that’s rotating more rapidly than can be modeled (and not due to a kinematically distinct component or to streaming material).
Rotation and “expansion” velocity curves
(T) polynomial model
(B) GP model with atan mean function
As a brief morphological note, GZ2 classifiers thought this was a normal looking disk galaxy by an overwhelming majority. It’s hard to say they were wrong based on the SDSS imaging, but the deeper and wider legacy survey thumbnail clearly shows the outer disk to be disturbed, presumably by the edge on disk galaxy to the north — the relative velocities are ∼340km/sec, so they are likely in close proximity.
Plateifu 8138-12704 IFU footprint
As time allows I may take a closer look at model diagnostics available in Stan or some more examples. Longer term I plan to take another look at the Baryonic Tully-Fisher relationship for the larger sample available in DR15.
I haven’t had a lot of time for this hobby lately and won’t for another month or so, but I haven’t been completely inactive. When I first started modeling disk galaxy rotation curves with Gaussian processes I used a low order polynomial for the mean function. This was an admitted hack, and not a very good one at that. It’s not uncommon in the rotation curve modeling industry to adopt a functional form for the circular velocity. Sometimes it’s physically motivated (usually based on a bulge/disk/dark matter halo model), sometimes it’s purely phenomenological. With a bit of digging in the literature I found a particularly simple form in Courteau (1997):
Making this the mean function for the GP model involves just a few simple changes to the Stan code I outlined in that post. We only need two parameters for the curve, and the parameter block now looks like:
parameters {
real phi;
real<lower=0., upper=1.> cos_i; // cosine disk inclination
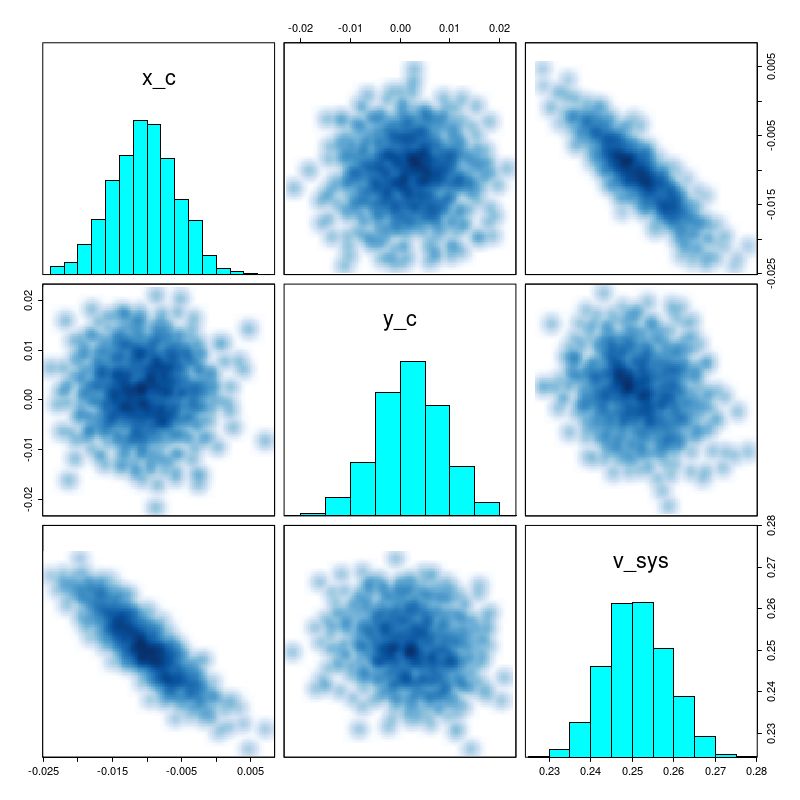
real x_c; //kinematic centers
real y_c;
real v_sys; //system velocity offset (should be small)
This model turned out to have very nice sampling properties using Stan’s version of NUTS, and convergence is fast enough in terms of both number of iterations and walltime to make it easily feasible to model a large sample.
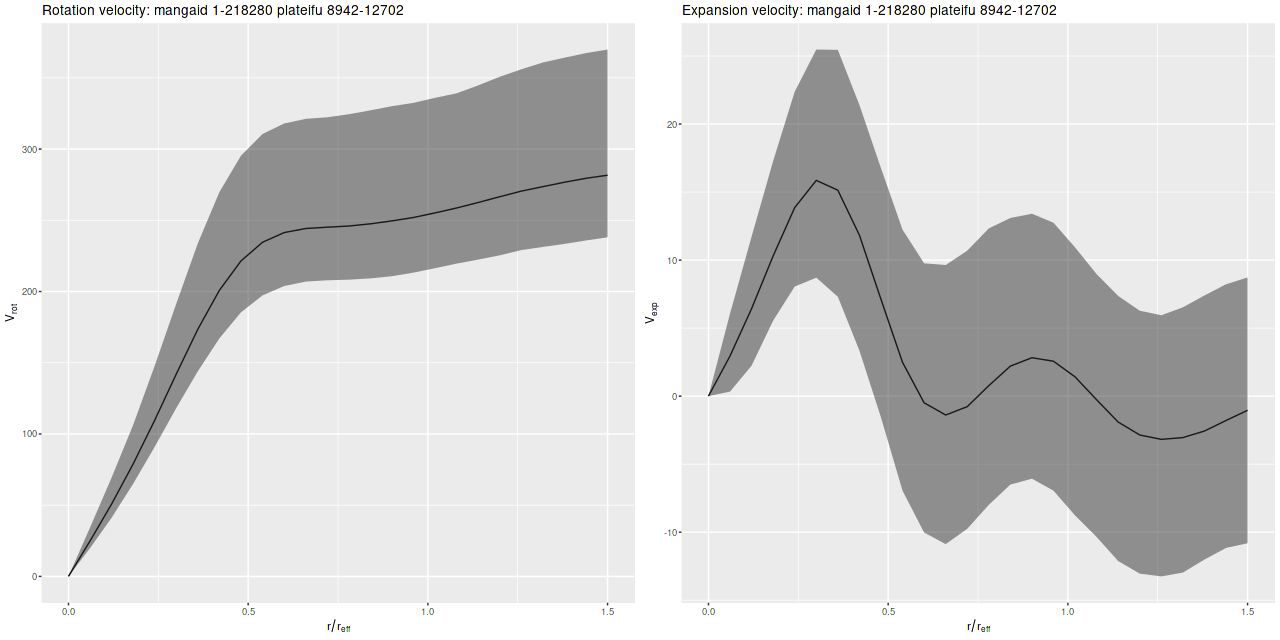
Since I’ve been using this as a running example here are posterior circular and expansion velocity estimates for plateifu 8942-12702 (mangaid 1-218280):
Circular and Expansion velocities, mangaid 1-218280 estimated by GP model with atan mean function
These curves are shaped just slightly differently from the ones I posted in July, but the confidence bounds are somewhat tighter. Whether this is actually due to better inference remains to be seen.
Second topic: SDSS Data release 15 went public in December as promised. I haven’t had time to dig into it much, but I did rerun the query I used to get a sample of high confidence disk galaxies based on GZ2 classifications. Run in the DR15 context that query got 588 hits, an increase of 229 from DR14 and still about 13% of the entire MaNGA galaxy sample excluding ancillary targets that aren’t also part of the main samples.
I downloaded the RSS files and have done a first pass at rotation curve modeling of the 229 new galaxies. Unfortunately I won’t have time to actually analyze what I have until, most likely, March. To conclude for now here is the kinematically most interesting example I saw from the new to DR15 sample. GZ2 classifiers called this a normal disk galaxy by a large majority
SDSS J114526.10+495244.5
legacy survey cutout
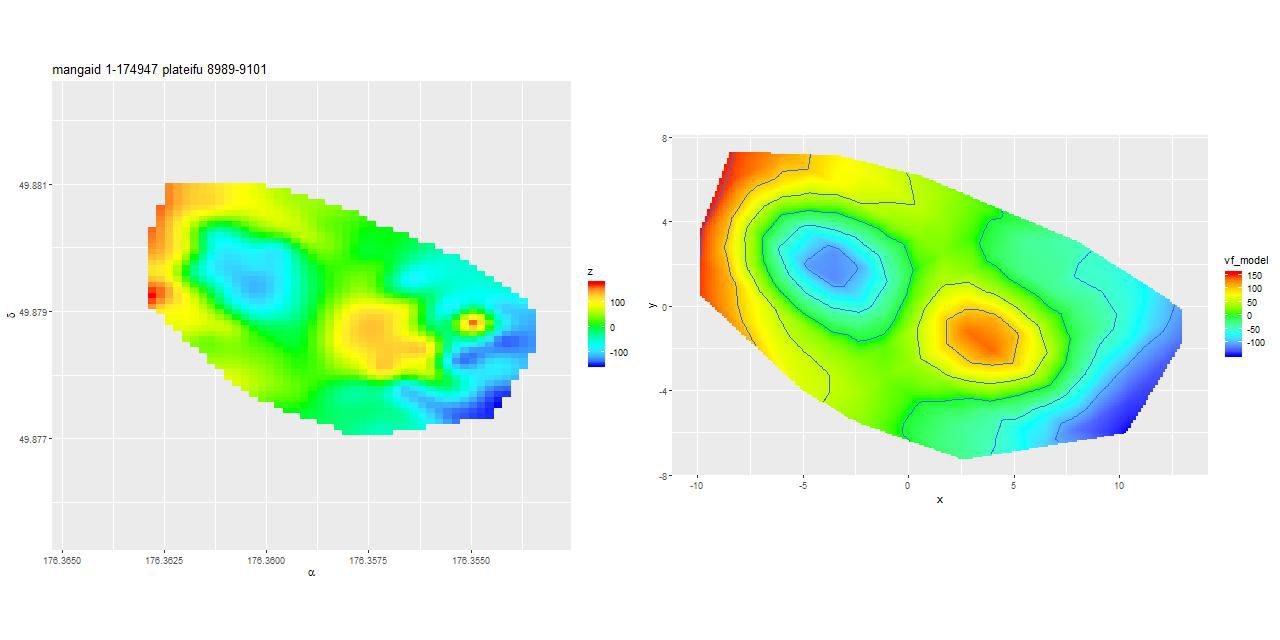
and were about evenly divided on whether it has a bar. And here is its velocity field measured from the stacked RSS file on the left, with the modeled velocity field on the right. The left graph is interpolated to the same resolution as the data cubes.
Interpolated velocity field and GP based model, mangaid 1-174947 (plateifu 8989-9101)
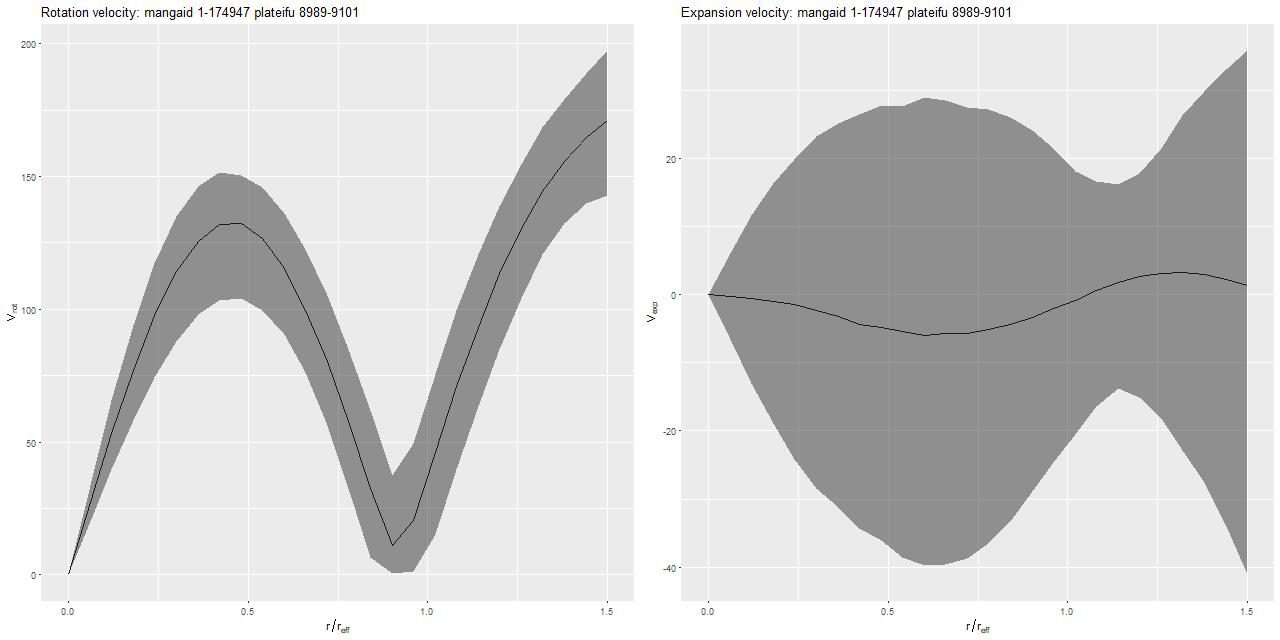
This is an incomplete map because of the signal/noise threshold I set, but it’s apparent that the outer disk is counter-rotating relative to the inner disk. This is confirmed for the stellar velocity field in the SDSS DAP, while the ionized gas rotates in the same sense as the outer disk throughout. Keep in mind that I measure blended velocities that in any given case could be dominated either by stellar light or ionized gas — in this galaxy the emission lines are very weak, so I measured the stellar velocity field. The GP based model does a good job of fitting the data, but the rotation curve isn’t exactly the standard shape:
Modeled circular and expansion velocity
One thing this demonstrates is the versatility of the gaussian process model with a simple mean function (even if it’s wrong).
A paper showed up on arxiv in early August titled “An early-type galaxy with an inner star-forming disk” by Li et al. (article id 1808.01730) that describes a system observed by MaNGA that’s rather similar to the one I have been writing about in recent posts, namely an apparent post-merger ETG with ongoing star formation. The paper is a little light on details, but it’s refreshingly short and not technically demanding. Unfortunately their discovery claim is incorrect: this galaxy was identified as a star forming elliptical in Helmboldt (2007), who also measured its HI mass to be 5.4±0.5 × \(10^8 \mathsf{M}_{\odot}\), about 5% of its baryonic mass.
Of course I did my own analysis which I’ll summarize in this post, also filling in some details missing from the paper. The first step in my analysis is to compute a velocity field (actually what I compute are redshift offsets, but these are easily converted to line of sight velocities). One of the first things I noticed is that while this is qualitatively similar to the one published by Li et al. (and shown twice!), the rotating inner component has nearly 3 times the maximum rotation velocity as their stellar velocity map.
Velocity field estimated from RSS data
So, naturally concerned that there was an error in my processing of the RSS data I downloaded the data cube and ran my code on that, getting the velocity field shown below on the left, which is evidently nearly identical.
Recall that my redshift offset measurement routine does template matching very similar to the SDSS spectro pipeline, using for templates a set of eigenspectra from a principal components analysis of a largish set of SDSS single fiber spectra from a high galactic latitude sample. These naturally encode information about both emission and absorption lines, with the code returning a single blended estimate. This works fine when ionized gas and stars are kinematically tightly coupled, but not so well when they’re not. Suspecting that emission lines were dominating the velocity estimates in the inner regions, as something of a one-off experiment I masked the area around emission lines in the galaxy spectra and reran the routine, getting the velocity field on the right.
Now this agrees in some detail with the stellar velocity field published by Li et al. (visual differences are mostly due to different color palettes). So an interesting first result is that not only is there a rotating, kinematically decoupled core but the stars and ionized gas within the core are decoupled from each other. This would seem to point to a recent injection of fresh cold gas.
Unfortunately they only published the stellar velocity field even though the official data analysis pipeline calculates separate ones for stars and gas, so I won’t be able to verify this result until value added kinematic data is made available.
(L) Velocity field estimated for data cube
(R) Stellar velocity field
For reference here is the spectrum from the central fiber. Wavelengths are vacuum rest frame and fluxes are corrected for foreground galactic extinction.
Central fiber spectrum, plateifu 8335-6101
As with the previous galaxy I did two sets of star formation history models. The first set a low S/N threshold for binning spectra and used an 81 SSP model subset of EMILES for fitting. For the second run I bin to a considerably higher target S/N and fit with the larger 216 SSP model set with the full BaSTI time resolution. The second data set has 25 coadded spectra with mean S/N per pixel ranging from 18-60.
For a quick comparison of the two sets of runs here are model mass growth histories summed over all spectra. Both indicate that a very substantial burst of star formation occurred beginning ~1.25Gyr ago (curiously, this is the same time as the initial burst in the galaxy KUG 0859+406 that I previously wrote about — part 1, part 2, part3). The present day stellar mass is just under \(1 times 10^{10} mathsf{M}_{odot}\), in agreement with the value cited by Li et al.
Summed model mass growth histories, emiles subset and “full” emiles
I find that ongoing star formation is largely confined to the KDC, in agreement with Li et al., so after running the models for the 25 bins I partitioned them into a core set and an outer set, with the core set comprising the bins within about 4×2″ (1.5 x 0.75 kpc semi-major and semi-minor axes) of the nucleus as shown below.
Stellar mass density for binned data, showing outlines of bins and core region
The summed star formation history models are shown below. As with my previous subject there was a galaxy wide burst of star formation ~1Gyr ago, but unlike it star formation declined monotonically after that, with no more recent secondary burst. The ongoing star formation in the central region is seen to be a relatively recent (last ~100Myr) uptick. This leads me to a slightly different interpretation of the data — the authors suggest that we are seeing the late stages of a gas rich major merger. I would say rather that the merger was completed ~1Gyr ago and that gas has recently been recaptured. This is consistent with simulations that show in the absence of AGN feedback star formation can proceed for some time after a merger. It’s also consistent with the observed reservoir of neutral hydrogen, which is sufficient to fuel star formation at the current level for another ~1Gyr.
(L) Model Star formation history, inner core
(R) Star formation history, outside core
Here are some additional results of the analysis of the 25 binned spectra. All of these agree with Li et al. where comparable results are displayed.
First, the Hδ absorption line index vs. 4000Å break strength index Dn(4000):
Lick HδA vs. Dn(4000)
Contour lines are my measurements of a sample of ~20K single fiber SDSS spectra. As with many quantities there is a distinct bimodality in this distribution, with star forming galaxies at upper left and passively evolving, mostly early type galaxies at bottom right. If star formation were to stop today there would be no K+A phase in this galaxy. A 1Gyr population has already passed its peak Balmer line strength, so if there was a K+A phase it was in the past.
Turning to emission lines, here are the 3 BPT diagnostic diagrams that are most commonly used with SDSS spectra. The curved lines are the starforming/something else demarcation lines of Kewley et al. 2006. In spatially resolved spectroscopy these lines seem not so useful. I find, in agreement with Li et al., that many of the spectra have “composite” line ratios, but except for the central fiber these are mostly near the edge or outside the KDC. The bottom right panel below shows the trend with radius of the [S II]/Hα line ratio (the other two show similar but weaker trends). This trend is the opposite of what we’d expect if an AGN were the ionizing source. Shocks or hot evolved stars are more likely.
Emission line diagnostic (BPT) plots
TL: [N II]/Hα vs [O III]/Hβ
TR: [O I]6300/Hα
BL: [S II]/Hα
BR: trend of [S II]/Hα with radius
I estimate a 100Myr average star formation rate from the SFH models. The log of the star formation rate density (in \(\mathsf{M}_{\odot}/\mathsf{yr/kpc}^2\)) is plotted against log stellar mass density (in \(\mathsf{M}_{\odot}/\mathsf{kpc}^2\)) below (the line is the estimate of the SF main sequence of Renzini and Peng 2015). Again in agreement with Li et al. the areas of highest SFR lie near the SF main sequence, while the outskirts of the IFU footprint fall below it. log SFR density vs. log stellar mass density
The radial trend of star formation rate is shown below on the left. On the right is my estimate of SFR density plotted against Hα luminosity density along with the calibration of Moustakis et al. Hα is corrected for attenuation using the Balmer decrement.
(L) log SFR density vs. radius
(R) log SFR density vs. attenuation corrected log Hα luminosity density
By the way my models directly estimate dust attenuation of the stellar light, typically assuming a Calzetti attenuation curve. A comparison with attenuation estimated with the Balmer decrement is shown below. To anyone familiar with SDSS spectra it’s not too surprising that estimates from the Balmer decrement have a huge amount of scatter due mostly to the fact that Hβ emission line strength is often poorly constrained. Despite that there is a clear positive correlation between these two estimates. I will probably examine this relationship in more detail in a future post, perhaps based on more favorable data.
τV estimated from Balmer decrement vs SFH model estimates
Finally, trend with radius of the metallicity 12+log(O/H) estimated with the strong line O3N2 method. As with the post merger galaxy in the previous posts there is a hint of a weak negative gradient. Overall the gas phase metallicity is around solar or just a little below. This is somewhat lower than my other post merger example, which is not unexpected given an approximately factor of 4 difference in stellar masses.
Metallicity 12+log(O/H) vs radius, estimated by O3N2 index
Automating the processing of rotation curve models for the sample I described in the previous post was a relatively straightforward exercise. I just wrote a short script to load the galaxy data, estimate the velocity field, and run the Stan model for the entire sample. I use the MaNGA catalog values of nsa_elpetro_ph and nsa_elpetro_ba as proxies for the major axis position angle and cosine of inclination. Recall from a few posts back that these are used both to set priors for the corresponding model parameters and to initialize the sampler. There’s a small problem in that the photometric major axis is defined modulo \(\pi\) while the kinematic position angle is measured modulo \(2 \pi\). A 180o error here just causes the signs of the polynomial coefficients for rotation velocity to flip, which is easily corrected in post-processing.
I also use the catalog value nsa_elpetro_th50_r as the estimate of the effective radius, rescaling the input coordinates by dividing by 1.5reff. To save future processing (and also as insurance against power outages, etc.) all of the relevant input data and model fits are saved to an R binary data file for each galaxy. This all took some days for this sample, with the most time consuming operation being the calculation of the velocity fields.
Not all of the model runs were successful. Foreground stars and galaxy overlaps can cause catastrophic errors in the velocity offset measurements, and just one such error can seriously skew the rotation curve model. For these cases I manually masked the offending spectra and reran the models. There were three other sources of model failure: a single case of a bulge dominated galaxy, galaxies that were too nearly face on to reliably measure rotation, and galaxies with large kinematic misalignments (that is where the direction of maximum recession velocity is significantly offset from the photometric major axis). I will discuss these cases and what I did about them in more detail in a later post. For now it suffices to say I ended up with 331 galaxies with satisfactory rotation curve estimates.
With rotation curves in hand I decided as a simple project to try to replicate the Baryonic Tully Fisher relation. In its original form (Tully and Fisher 1977) the TFR is a relationship between circular velocity measured at some fiducial radius and luminosity, and as such it constitutes a tertiary distance indicator. Since stellar mass follows light (more or less) it makes sense that a similar relationship should hold between circular velocity and mass, and in due course this was found to be the case by McGaugh et al. (2000) who found \(M_b \sim V_c^4\) over a 5 decade range in baryonic (that is stellar plus gas) mass.
I retrieved stellar masses from the MPA-JHU (and also Wisconsin) pipeline using the following query:
select into gz2diskmass
gz.mangaid,
gz.plateifu,
gz.specObjID,
ge.lgm_tot_p16,
ge.lgm_tot_p50,
ge.lgm_tot_p84,
w.mstellar_median,
w.mstellar_err
from mydb.gz2disks gz
left outer join galSpecExtra ge on ge.specObjID = gz.specObjID
left outer join stellarMassPCAWiscBC03 w on w.specObjID = gz.specObjID
The MPA stellar mass estimates were from a Bayesian analysis, and several quantiles of the posterior are tabulated. I use the median as the best estimate of the central value and the 16th and 84th percentiles as \(\pm 1\sigma\).
We need a single estimate of circular velocity. Since I scaled the coordinates by 1/(1.5Reff) the sum of the polynomial coefficients conveniently estimates the circular velocity at 1.5Reff, so that’s what I used. And here’s what I got (this is a log-log plot):
Stellar mass vs. rotation velocity at 1.5Reff for 331 disk galaxies
So, most points do follow a fairly tight linear relationship, but some measurements have very large error bars, and there are perhaps some outliers. The obvious choice to quantify the relationship, namely a simple linear regression with measurement error in both variables is also the wrong choice, I think. The reason is it’s not clear what the predictor should be, which suggests that we should be modeling the joint distribution rather than a conditional distribution of one variable given the other. To do that I turn to what astronomers call “extreme deconvolution” (Bovy, Hogg, and Roweis 2009, 2010). This is another latent variable model where the observed values are assumed drawn from some distribution with unknown (latent) mean and known variances, and the latent variables are in turn modeled as being drawn from a joint distribution with mean and variance parameters to be estimated. Bovy et al. allowed the joint distribution to be a multiple component mixture. I wrote my own version in Stan, and for simplicity just allow a single component for now. The full code is listed at the end of this post. Another simplification I make is modeling the measurement errors as Gaussian, which is clearly not the case for at least some measurements since some error bars are asymmetric — the plotted error bars mark the 16th and 84th percentiles of log stellar mass (\(\approx \pm 1 \sigma\)) and 2.5th and 97.5th percentiles of log circular velocity (\(\approx \pm 1.96 \sigma\)). If I had more accurate distribution functions it would be straightforward to adjust the model. This should be feasible for the velocities at least since the rotation model outputs can be recovered and the empirical posteriors examined. The stellar mass estimates would be more difficult with only a few quantiles tabulated. But, forging ahead, here is the important result:
Stellar masses vs. rotation velocity with 95% confidence ellipses for “extreme deconvolution” estimate of relationship and pp distribution
The skinny ellipse is a 95% confidence bound for the XD estimate of the intrinsic relationship. The fat ellipse is a 95% confidence ellipse for the posterior predictive distribution, which is obtained by generating new simulated observations from the full model. So there are two interesting results here. First, the inferred intrinsic relationship shows remarkably little “cosmic scatter,” consistent with a nearly perfect correlation between the unobserved true stellar mass and circular velocity. Second, it’s not at all clear that the apparent outliers are actually discrepant given the measurement error model.
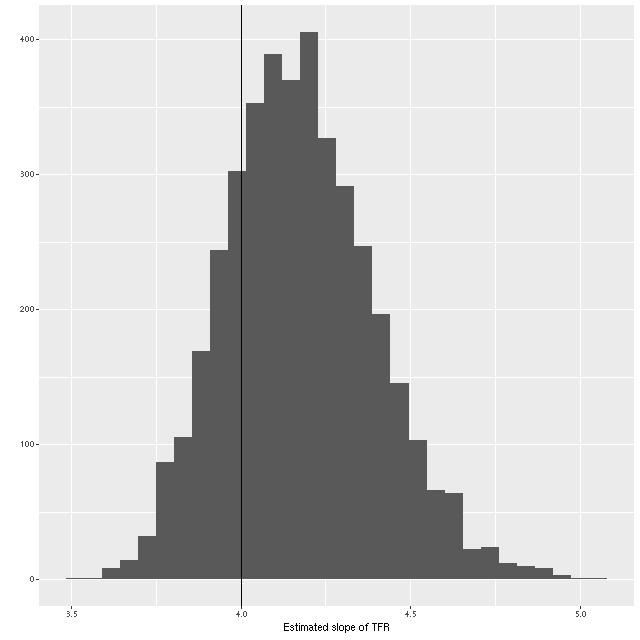
What about the slope of the relation? We can estimate that from the elements of eigenvectors of the eigendecomposition of the variance matrix, which I calculate in the generated quantities block of the Stan model. A histogram of the result is shown below. Although a slightly higher slope is favored, the McGaugh et al. value of 4 is well within the 95% confidence band.
Estimate of the slope of the TFR
As a check on my model I compared my results to the implementation of the Bovy et al. algorithm in the Python module astroML that accompanies the book “Statistics, Data Mining, and Machine Learning in Astronomy” by Ivezic et al. (2014).
Here is my estimate of the mean of the posterior means of the intrinsic distribution (which isn’t especially interesting) and the posterior variance matrix:
I also tried multicomponent mixtures in XDGMM and found no evidence that more than one is needed. In particular it doesn’t favor a different relation at the low mass end or any higher variance components to cover the apparent outliers.
One reason to use Gaussian process regression is that it models spatial covariance. Unfortunately the single covariance function currently offered in Stan is isotropic, so it’s not quite what we’d like for these models where correlations sometimes are spatially oriented.
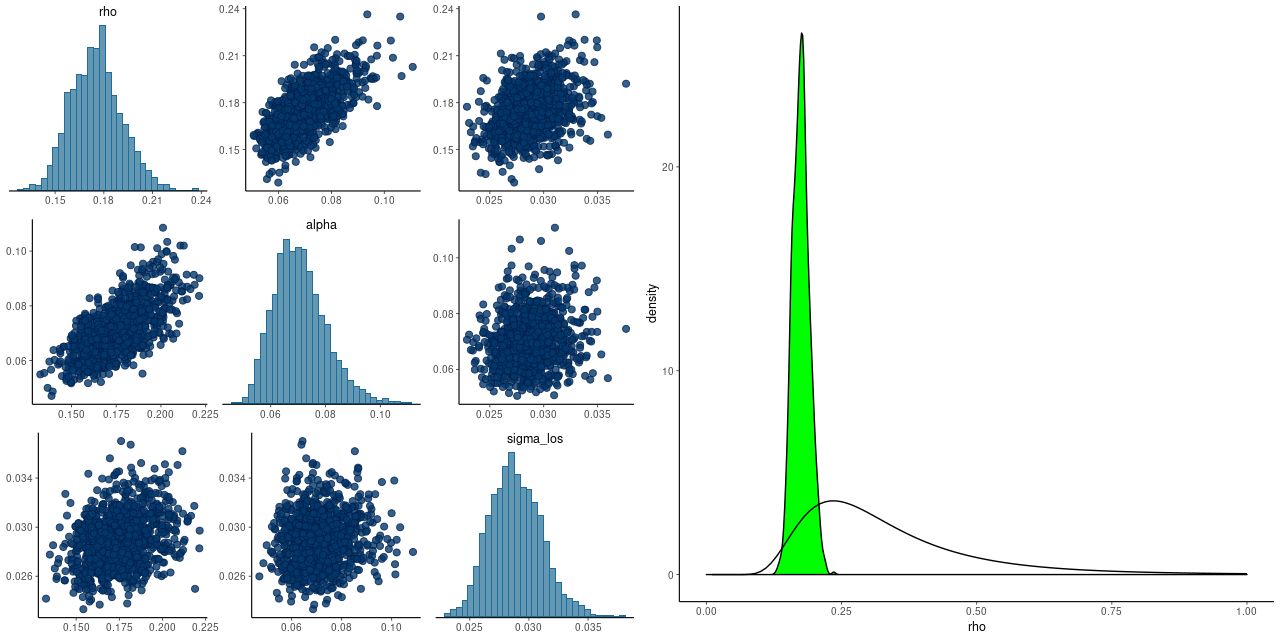
The “exponentiated quadratic” covariance offered by Stan has two parameters, one of which is a magnitude and one a scale length. When these are modeled as part of the inference problem they are only weakly identified, which often leads to convergence issues. Betancourt discusses this at some length in his case study and suggests a way to form a principled informative prior for the scale length ρ when meaningful bounds can be placed on its value. That’s definitely the case here: the minimum possible scale length for spatial correlations is the fiber diameter of 2″. The maximum is the scale of the data itself. Since I scale the input positions to have a maximum radius around 1 the maximum rescaled scale length is 1. I adopted his code for estimating the parameters of the inverse gamma prior without modification. As the graph below shows, this works rather well. The posteriors of the scale length rho and magnitude alpha are correlated, but there’s no indication of pathology. There is also an iid component of noise in the variance model and it is uncorrelated with the other two parameters. The right pane shows the kernel smoothed posterior density of rho and the prior density. Evidently the data are informative in this case, since the posterior is considerably tighter than the prior. The unscaled median value of rho is 2.8″, perhaps coincidentally a little larger than the typical MaNGA PSF diameter. If this value continues to hold for more data sets it might be possible to fix rho, which could speed sampling a bit.
I am not the first to use GP models for IFU data — González-Gaitán et al. (2018) applied essentially similar models to a variety of data estimated from CALIFA data cubes. Unfortunately full Bayesian inference on data cubes is quite out of reach with any computing resources I have access to. The model in the last post took 6900 seconds wall time for 1000 iterations for each of 4 chains run in parallel, with just 380 data points. This was on a desktop PC with 4th generation Intel I7. A current generation Intel I9 based PC runs the same model in about half the time.
The simple polynomial model for rotation velocities that I wrote about in the last two posts seems to work well, but there are some indications of model misspecification. The relatively large expansion velocities imply large scale noncircular motions which are unexpected in an undisturbed disk galaxy (although the bar may play a role in this one), but also may indicate a problem with the model. There is also some spatial structure in the residuals, falsifying the initial assumption that residuals are iid. Since smoothing splines proved to be intractable I turned to Gaussian Process (GP) regression for a more flexible model representation. These are commonly used for interpolation and Stan offers support for them, although it’s somewhat limited in the current version (2.17.x).
I know little about the theory or practical implementation of GP’s, so I will not review the Stan code in detail. The current version of the model code is at <https://github.com/mlpeck/vrot_stanmodels/blob/master/vrot_gp.stan>. Much of the code was borrowed from tutorial introductions by Rob Trangucci and Michael Betancourt. In particular the function gp_pred_rng() was taken directly from the former with minimal modification.
There were several complications I had to deal with. First, given a vector of variates y and predictors x the gaussian process model looks something like
that is the GP is defined in terms of a mean function and a covariance function. Almost every pedagogical introduction to GP’s that I’ve encountered immediately sets the mean function to 0. Now, my prior for the rotation velocity definitely excludes 0 (except at r=0), so I had to retain a mean function. In order to get calculating I again just use a low order polynomial for the rotation velocity. The code for this in the model block is
The last line looks like the previous model except that I’ve dropped the expansion velocity term because I do expect it to be small and distributed around 0. Also I replaced the calculation of the polynomial with a matrix multiplication of a basis matrix of polynomial values with the vector of coefficients. For some unknown reason this is slightly more efficient in this model but slightly less efficient in the earlier one.
A second small complication is that just about every pedagogical introduction I’ve seen presents examples in 1D, but the covariates in this problem are 2D. That turned out to be a small issue, but it did take some trial and error to find a usable data representation and there is considerable copying between data types. For example there is an N x 2 matrix Xhat which is defined as the result of a matrix multiplication. Another variable declared as row_vector[2] xyhat[N]; is required for the covariance matrix calculation and contains exactly the same values. All of this is done in the transformed parameters block.
The main objective of a gaussian process regression is to predict values of the variate at new values of the covariates. That is the purpose of the generated quantities block, with most of the work performed by the user defined function gp_pred_rng() that I borrowed. This function can be seen to implement equations 2.23-2.24 in the book “Gaussian Processes for Machine Learning” by Rasmussen and Williams 2006 (the link goes to the book website, and the electronic edition of the book is a free download). Those equations were derived for the case of a 0 mean function, but that’s not what we have here. In an attempt to fit my model into the mathematical framework outlined there I subtract the systematic part of the rotation model from the latent line of sight velocities to feed a quantity with 0 prior mean to the second argument to the posterior predictive function:
Yet another complication is that the positions in the plane of the disk are effectively parameters too. I don’t know if the posterior predictive part of the model is correctly specified given these complications, but I went ahead with it anyway.
The positions I want predictions for are for equally spaced angles in a set of concentric rings. The R code to set this up is (this could have been done in the transformed data block in Stan):
These are then used to reconstruct the model velocity field and the difference between the posterior predictive field and the systematic portion of the model:
for (n in 1:N_r) {
v_model[((n-1)*N_r+1):(n*N_r)] = vrot_pred[n+1] * cos(theta_pred[((n-1)*N_r+1):(n*N_r)]) +
vexp_pred[n+1] * sin(theta_pred[((n-1)*N_r+1):(n*N_r)]);
}
v_res = v_pred - v_model;
Besides some uncertainty about whether the posterior predictive inference is specified properly there is one very important problem with this model: the gradient computation, which tends to be the most computationally intensive part of HMC, is about 2 orders of magnitude slower than for the simple polynomial model discussed in the previous posts. The wall time isn’t proportionately this much larger because fewer “leapfrog” steps are typically needed per iteration and the target acceptance rate can be set to a lower value. This still makes analysis of data cubes quite out of reach, and as yet I have only analyzed a small number of galaxies’ RSS based data sets.
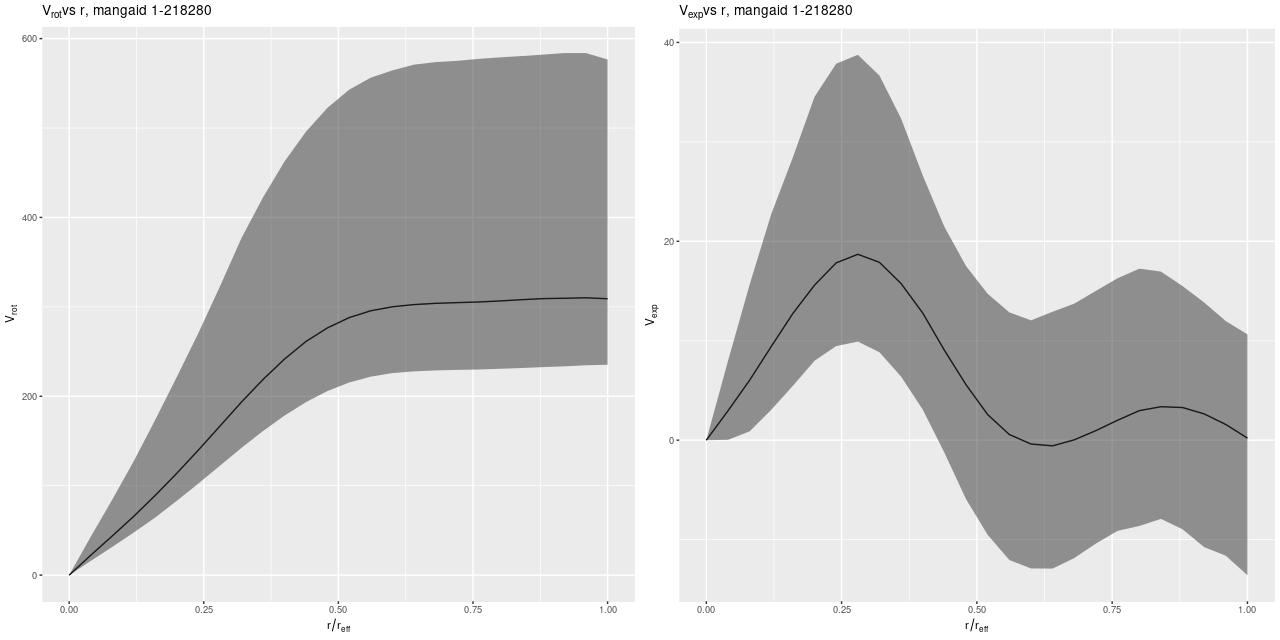
Here are some results for the sample data set from plateifu 8942-12702. This galaxy is too big for its IFU — the cataloged effective radius is 16.2″, which is about the radius of the IFU footprint. Therefore I set the maximum radius for predicted values to 1reff.
The most important model outputs are the posterior predictive distributions for the rotational and expansion velocities:
V_rot, V_exp, Gaussian process model
The rotational velocity is broadly similar to the polynomial model, but it has a very long plateau (the earlier model was beginning to turn over by 1 reff) and much larger uncertainty intervals. The expansion velocity curve displays completely different behavior from the polynomial model (note that the vertical scales of these two graphs are different). The mean predicted value is under 20 km/sec everywhere, and 0 is excluded only out to a radius around 6.5″, which is roughly the half length of the bar.
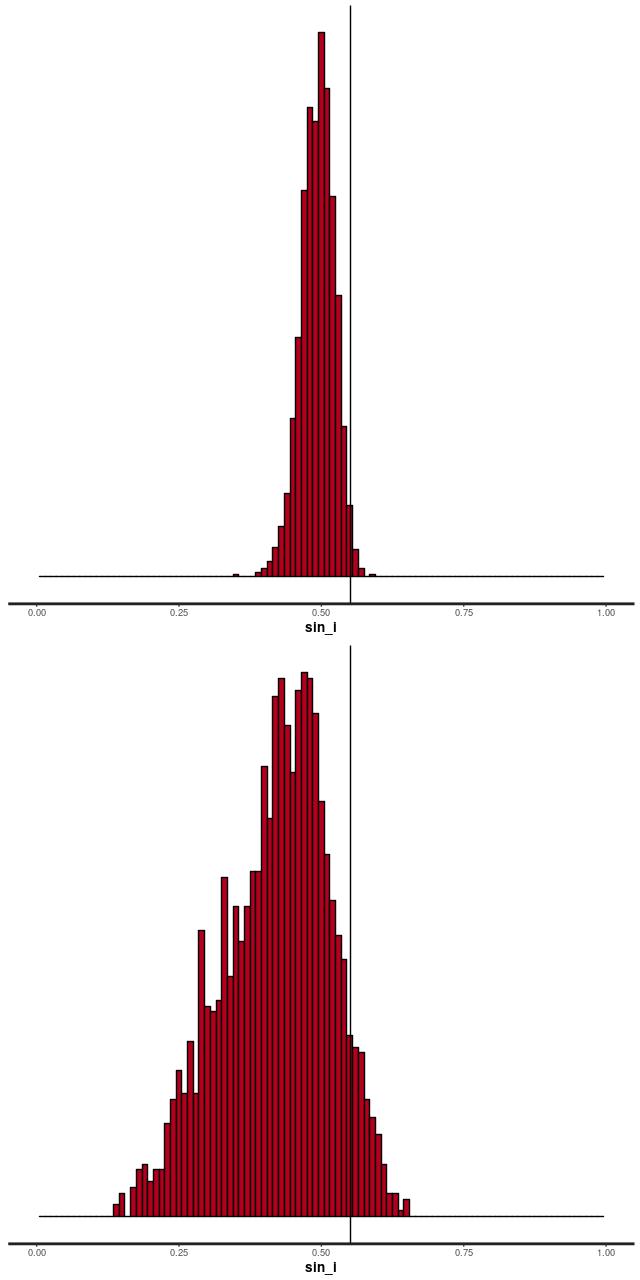
The reason for the broad credible intervals for the rotation velocity in the GP model compared to the polynomial model can be seen by comparing the posteriors of the sine of the inclination angle. The GP model’s is much broader and has a long tail towards very low inclinations. This results in a long tail of very high deprojected rotational velocities. Both models favor lower inclinations than the photometric estimate shown as a vertical line.
Posteriors of sin_i for polynomial and GP models
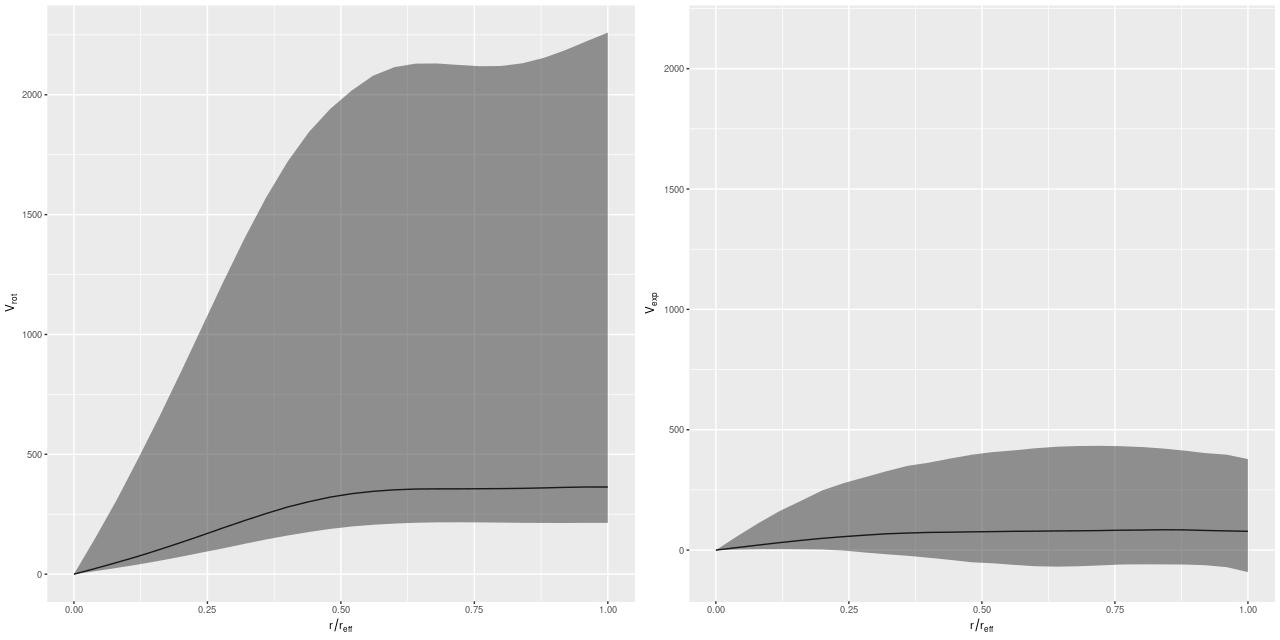
I’m going to leave off with one more graph. I was curious if it was really necessary to have a model for the rotation velocity, so I implemented the common pedagogical case of assuming the prior mean function is 0 (actually a constant to allow for an overall system velocity). Here are the resulting posterior predictive estimates of the rotation and expansion velocities:
V_rot, V_exp for GP model with constant prior mean
Conclusion: it is. There are several other indications of massive model failure, but these are sufficient I think.
In a future post (maybe not the next one) I’ll discuss an application that could actually produce publishable research.
I’m going to take a selective look at some of the Stan code for this model, then show some results for the RSS derived data set. The complete stan file is at <https://github.com/mlpeck/vrot_stanmodels/blob/master/vrot.stan>. By the way development is far from frozen on this little side project, so this code may change in the future or I may add new models. I’ll try to keep things properly version controlled and my github repository in sync with my local copy.
Stan programs are organized into named blocks that declare and sometimes operate on different types of variables. There are seven distinct blocks that may be present — I use 6 of them in this program. The functions block in this program just defines a function that returns the values of the polynomial representing the rotational and expansion velocities. The data block is also straightforward:
data {
int<lower=1> order; //order for polynomial representation of velocities
int<lower=1> N;
vector[N] x;
vector[N] y;
vector[N] v; //measured los velocity
vector[N] dv; //error estimate on v
real phi0;
real<lower=0.> sd_phi0;
real si0;
real<lower=0.> sd_si0;
real<lower=0.> sd_kc0;
real<lower=0.> r_norm;
real<lower=0.> v_norm;
int<lower=1> N_r; //number of points to fill in
vector[N_r] r_post;
}
The basic data inputs are the cartesian coordinates of the fiber positions as offsets from the IFU center, the measured radial velocities, and the estimated uncertainties of the velocities. I also pass the polynomial order for the velocity representations and sample size as data, along with several quantities that are used for setting priors.
The parameters block is where the model parameters are declared, that is the variables we want to make probabilistic statements about. This should be mostly self documenting given the discussion in the previous post, but I sprinkle in some C++ style comments. I will get to the length N vector parameter v_los shortly.
parameters {
real phi;
real<lower=0., upper=1.> sin_i; // sine disk inclination
real x_c; //kinematic centers
real y_c;
real v_sys; //system velocity offset (should be small)
vector[N] v_los; //latent "real" los velocity
vector[order] c_rot;
vector[order] c_exp;
real<lower=0.> sigma_los;
}
In this program the transformed parameters block mostly performs the matrix manipulations I wrote about in the last post. These can involve both parameters and data. A few of the declarations here improve efficiency in minor but useful ways recommended in the Stan help forums by members of the development team. For example the statement real sin_phi = sin(phi); saves recalculating the sine further down.
I try to be consistent about setting priors first in the model block and using proper priors that are more or less informative depending on what I actually know. In this case some of these are hard coded and some are passed to Stan as data and can be set by the user. I find it necessary to supply fairly informative priors for the orientation and inclination angles. For the latter it’s because of the weak identifiability of the inclination. For the former it’s to prevent mode hopping.
Stan’s developers recommend that parameters should be approximately unit scaled, and this usually entails rescaling the data. In this case we have both natural velocity and length scales. Typical peculiar velocities are on the order of no more than a few hundreds of km/sec., so I scale them to units of 100 km/sec. The MaNGA primary sample is intended to have each galaxy observed out to 1.5Reff, where Reff is the (r band) half light radius, so the maximum observed radius should typically be ∼1.5Reff. Therefore I typically divide all position measurements by that amount with the effective radius taken from nsa_elpetro_th50_r in drpcat. Other catalog values that I use as inputs to the model are nsa_elpetro_phi for the orientation angle and nsa_elpetro_ba for the cosine of the inclination. These are used as the central values of the priors and also to initialize the sampler.
Once I solved the problem of parametrizing angles the next source of pathologies I encountered was a tendency towards multimodal kinematic centers. This usually manifests as one or more chains being displaced from the others rather than mode hopping within a chain, although that can happen too. In the typical case the extra modes would place the center in an adjacent fiber to the one closest to the IFU center, but sometimes much larger jumps happen. Although I wouldn’t necessarily rule out the possibility of actual multimodality when it happens it has a severe effect on convergence diagnostics and on most other model parameters. I therefore found it necessary to place a tighter prior on the kinematic centers than I would have liked based solely on prior knowledge: the default prior puts about 95% of the prior mass within the radius of the central fiber. This could overconstrain the kinematic center in some cases, particularly low mass galaxies with weak central concentration.
A very common situation with astronomical data is to have quantities measured with error with an accompaying uncertainty estimate for each measurement. My code for estimating redshift offsets kicks out an uncertainty estimate, so this is no exception. I take a standard approach to modeling this: the unknown “true” line of sight velocity is treated as a latent variable, with the measured velocity generated from a distribution having mean equal to the latent variable and standard deviation the estimated uncertainty. In this case the distribution is assumed to be Gaussian. The latent variable is then treated as the response variable in the model. Since I had no particular expectations about what the residuals from the model should look like I fell back on the statistician’s standard assumption that they are independent and identically distributed gaussians with standard deviation to be estimated as part of the model.
Having a latent parameter for every measurement seems extravagant, but in fact it causes no issues at all except for a slight performance penalty. With the distributional assumptions I made the latent variables can be marginalized out and posteriors for the remaining parameters will be the same within typical Monte Carlo variability. The main performance difference seems to arise from slower adaptation in the latent variables version.
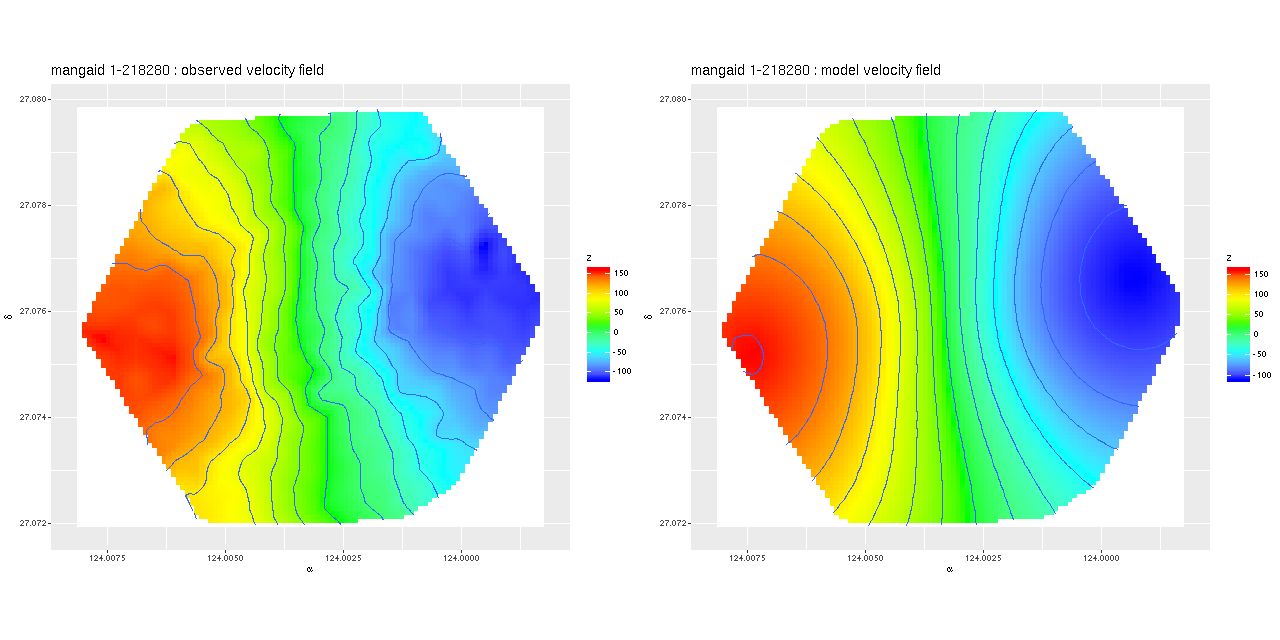
Finally, some results from the observation with plateifu 8942-12702 (mangaid 1-218280). First, the measured velocity field and the posterior mean model. The observations came from the same data shown in the previous post interpolated onto a finer grid.
Measured and model velocity field – mangaid 1-218280
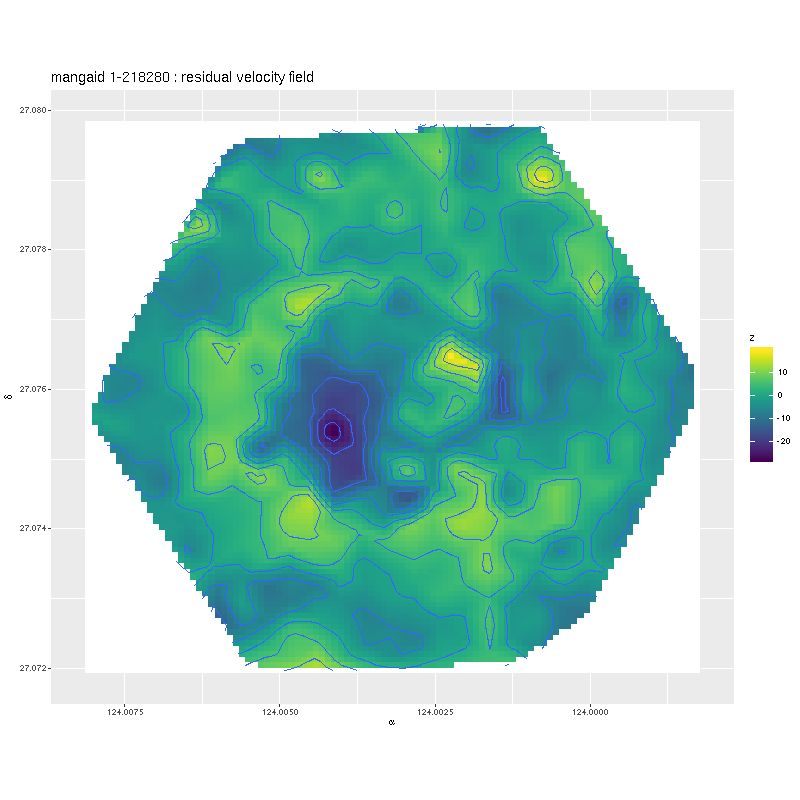
The model seems not too bad except for missing some high spatial frequency details. The residuals may be revealing (again this is the posterior mean difference between observations and model):
residual velocity field
There is a strong hint of structure here, with a ridge of positive residuals that appears to follow the inner spiral arms at least part of the way around. There are also two regions of larger than normal residuals on opposite sides of the nucleus and with opposite signs. In this case they appear to be at or near the ends of the bar. This is a common feature of these maps — I will show another example or two later.
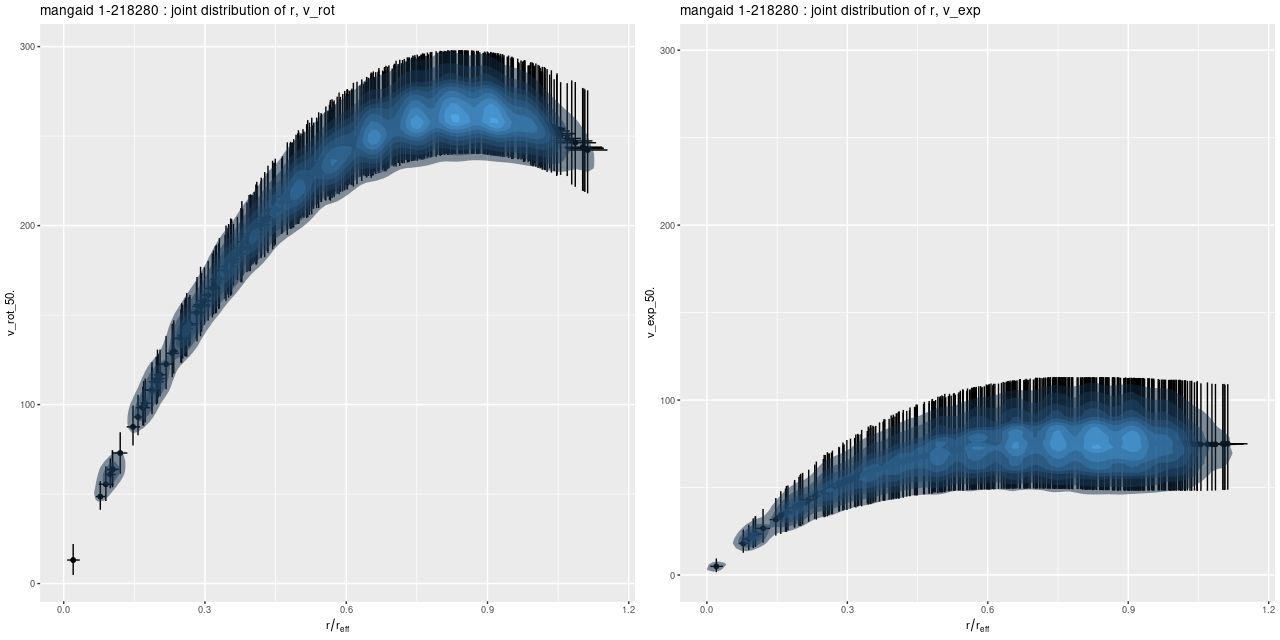
Next are the joint posterior distributions of \(v_{rot}\) with radius r and \(v_{exp}\) with r. Error bars are 95% credible intervals.
Joint posteriors of v_rot, r and v_exp, r
The rotation curve seems not unrealistic given the limited expressiveness of the polynomial model. The initial rise is slow compared to typical examples in the literature, but this is probably attributable to the limited spatial resolution of the data. The peak value is completely reasonable for a fairly massive spiral. The expansion velocity on the other hand is surprising. It should be small, but it’s not especially so. Nowhere do the error bars include 0.
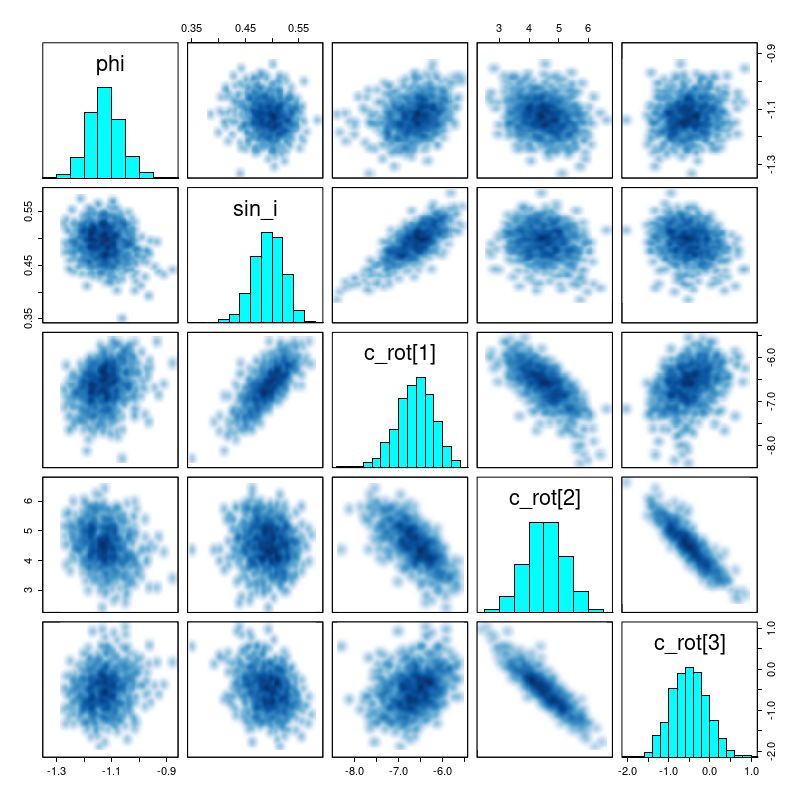
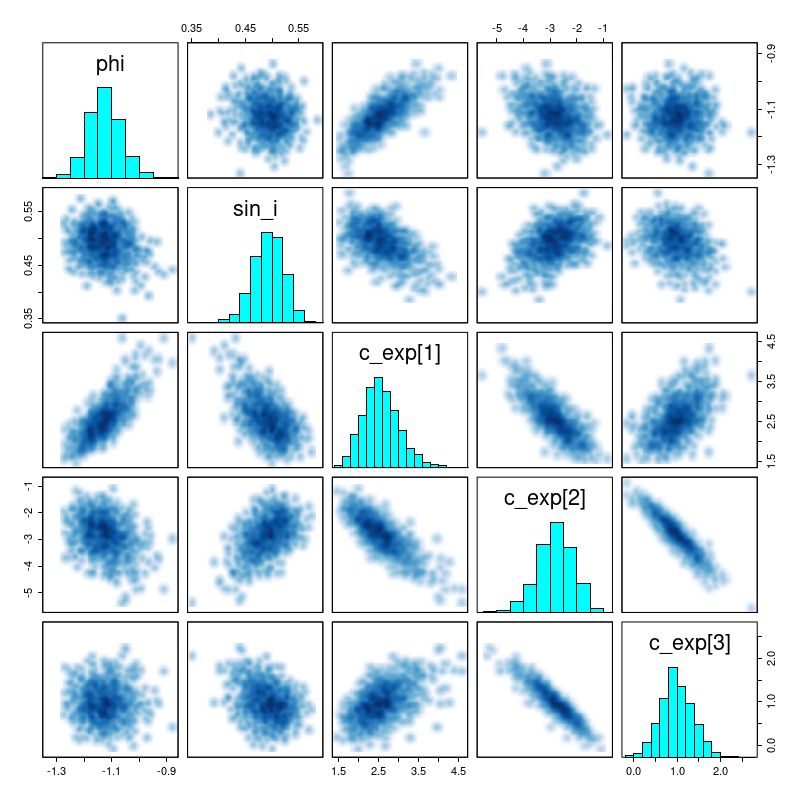
There are a number of graphical tools that are useful for assessing MCMC model performance. Here are some pairs plots of the main model parameters:
Pairs plot of posteriors of phi, sin_i, and c_rot
Pairs plot of posteriors of phi, sin_i, and c_exp
Pairs plot of x_c, y_c, v_sys
There are several significant correlations here, none of which are really surprising. The polynomial coefficients are strongly correlated. The inclination angle is strongly correlated with rotation velocity and slightly less, but still significantly correlated with expansion velocity. The orientation angle is slightly correlated with rotation velocity but strongly correlated with expansion. The estimated system velocity is strongly correlated with the x position of the kinematic center but not y — this is because the rotation axis is nearly vertical in this case. The relatively high value of v_sys (posterior mean of 25 km/sec) is a bit of a surprise since the SDSS spectrum appeared to be well centered on the nucleus and with an accurate redshift measurement. Nevertheless the value appears to be robust.
Stan is quite aggressive with warnings about convergence issues, and it reported none for this model run. No graphical or quantitative diagnostics indicated any problems. Nevertheless there are several indicators of possible model misspecification.
Signs of structure in residual maps are interesting because they indicate perturbations of the velocity field as small as ∼10 km/sec by spiral structure or bars may be detectable. But it also indicates the assumption of iid residuals is false.
It’s hard to tell from visual inspection if the symmetrically disposed velocity residuals near the nucleus are due to rotating rings of material or streaming motions, but in any case a low order polynomial can’t be fit to them. I will show more dramatic examples of this in a future post.
Large scale expansion (or contraction) shouldn’t be seen in a disk galaxy, but the estimated expansion velocity is rather high in this case. Perturbations by the rather prominent bar would indicate that a model with a \(2 \theta\) angular dependence should be explored.




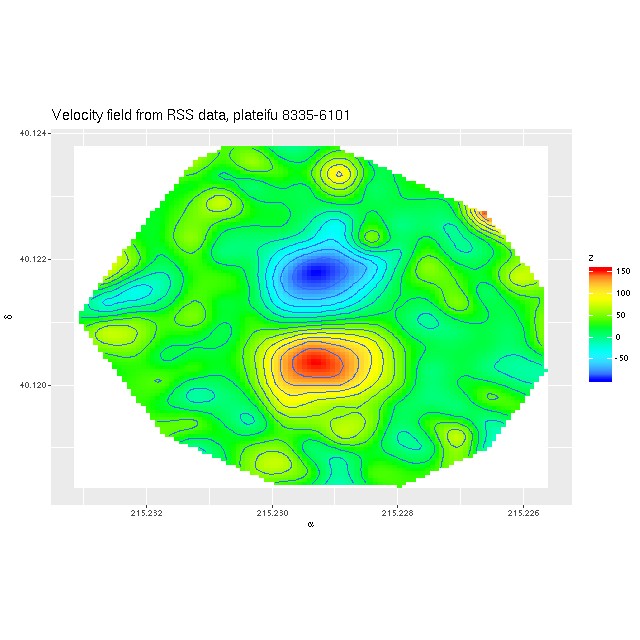 Velocity field estimated from RSS data
Velocity field estimated from RSS data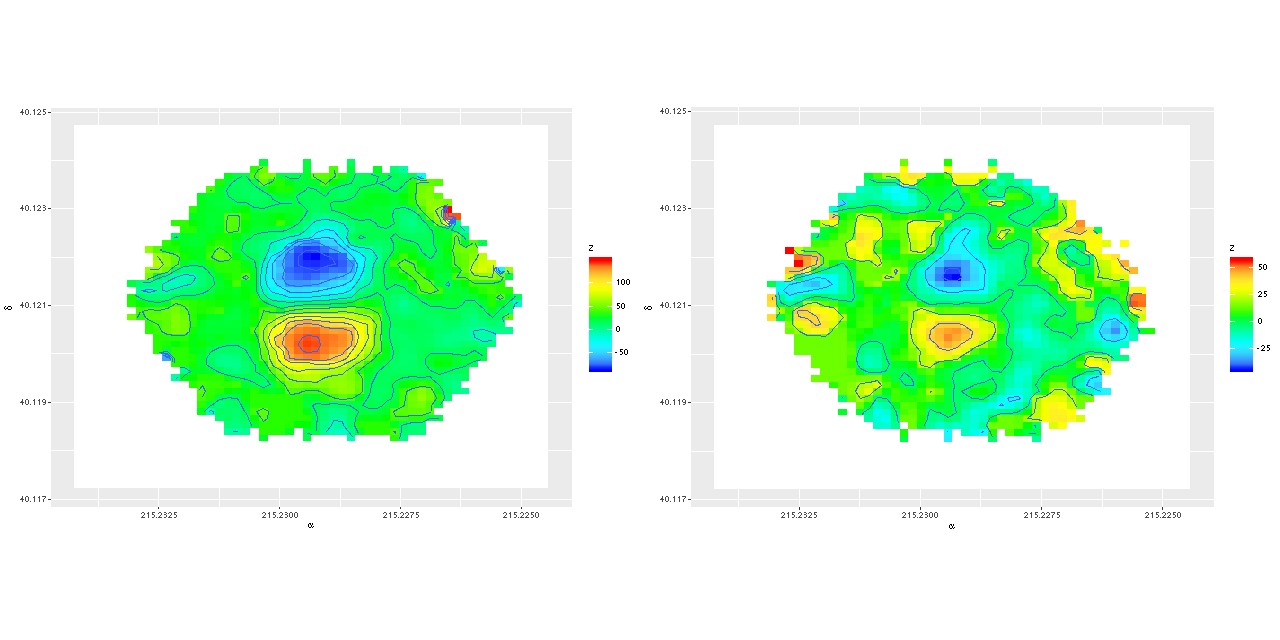 (L) Velocity field estimated for data cube
(L) Velocity field estimated for data cube Central fiber spectrum, plateifu 8335-6101
Central fiber spectrum, plateifu 8335-6101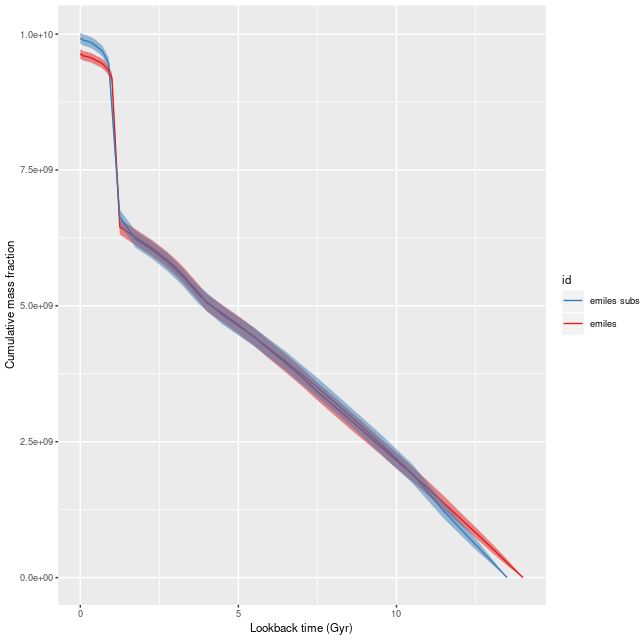 Summed model mass growth histories, emiles subset and “full” emiles
Summed model mass growth histories, emiles subset and “full” emiles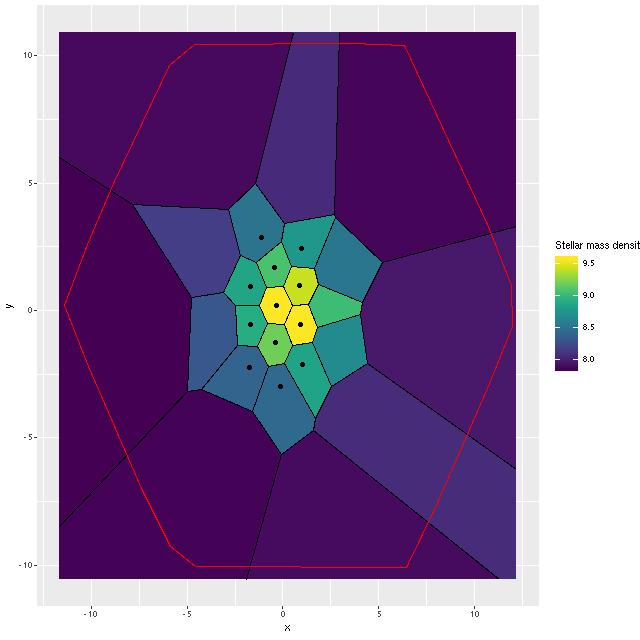 Stellar mass density for binned data, showing outlines of bins and core region
Stellar mass density for binned data, showing outlines of bins and core region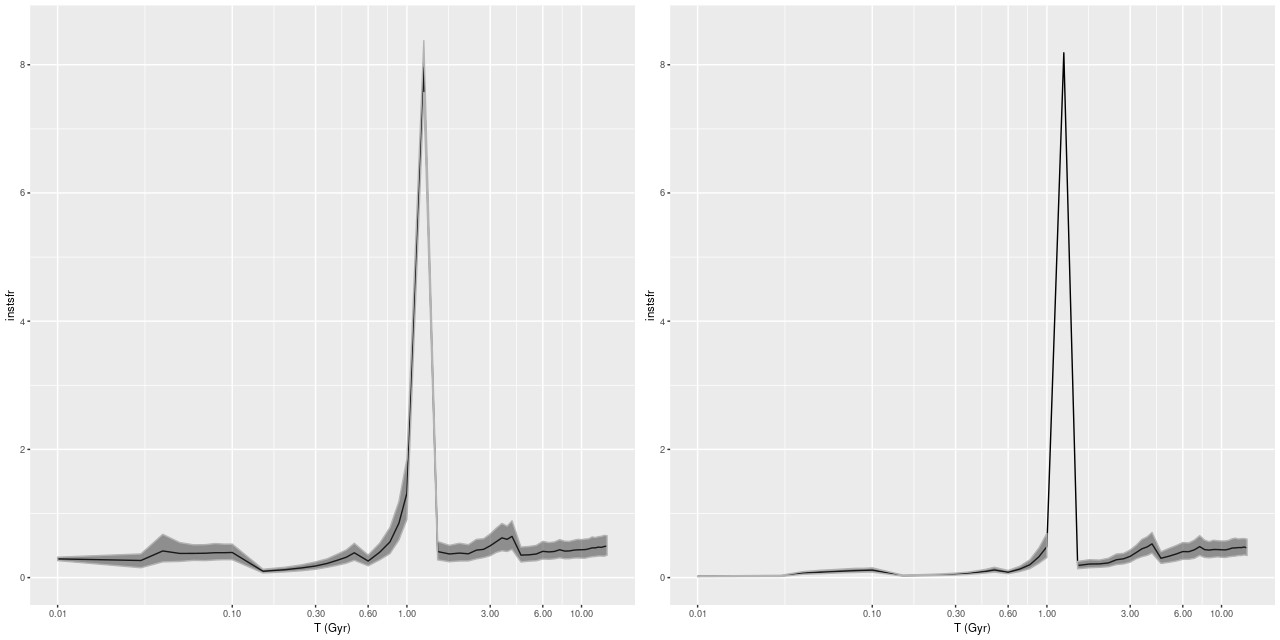 (L) Model Star formation history, inner core
(L) Model Star formation history, inner core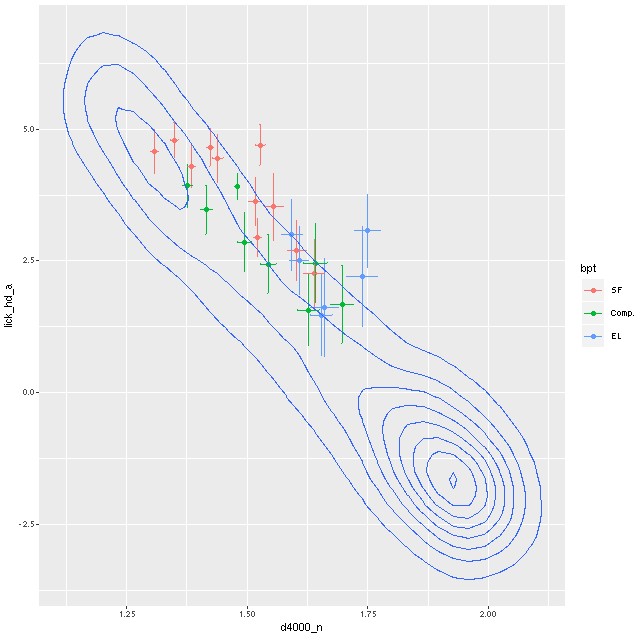 Lick HδA vs. Dn(4000)
Lick HδA vs. Dn(4000)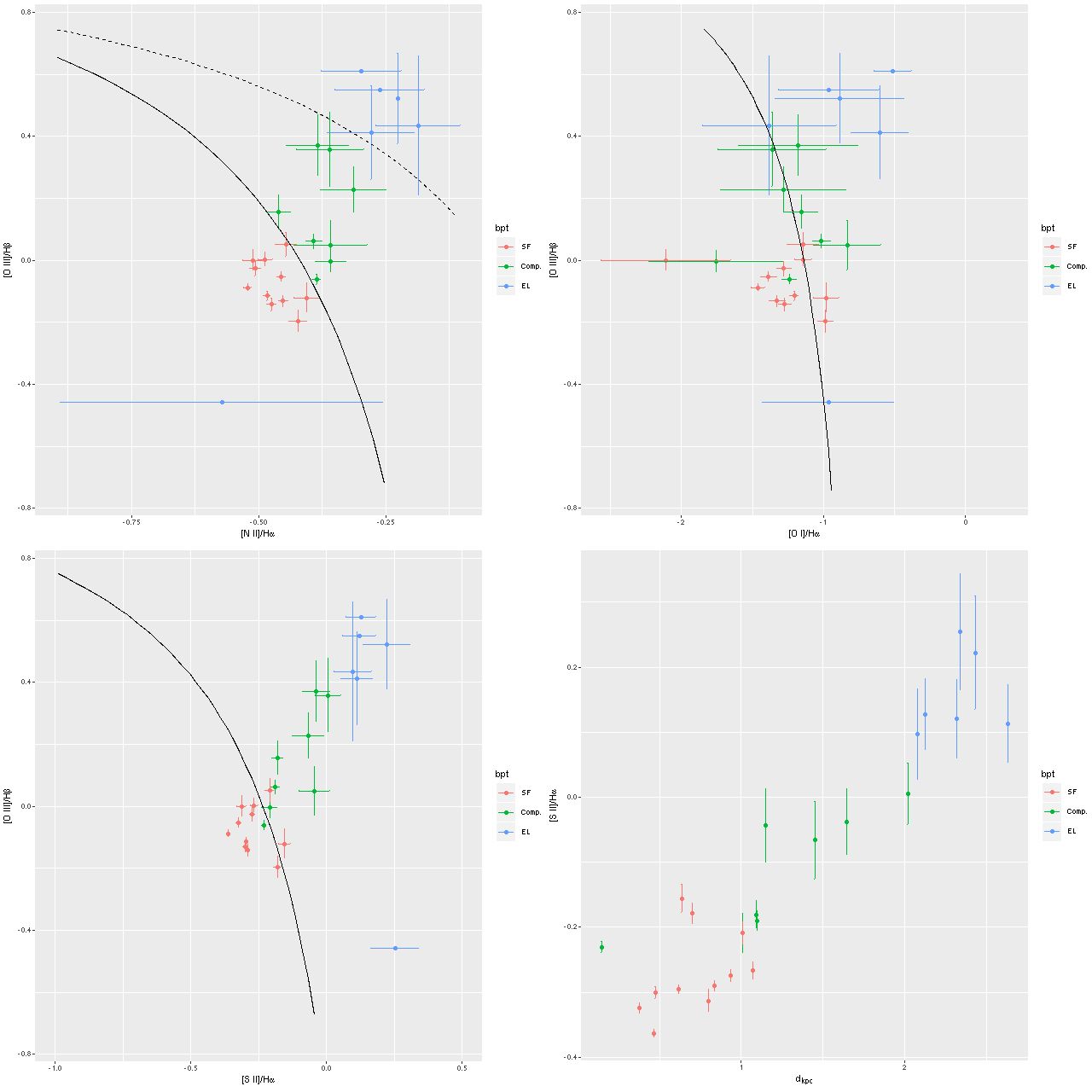 Emission line diagnostic (BPT) plots
Emission line diagnostic (BPT) plots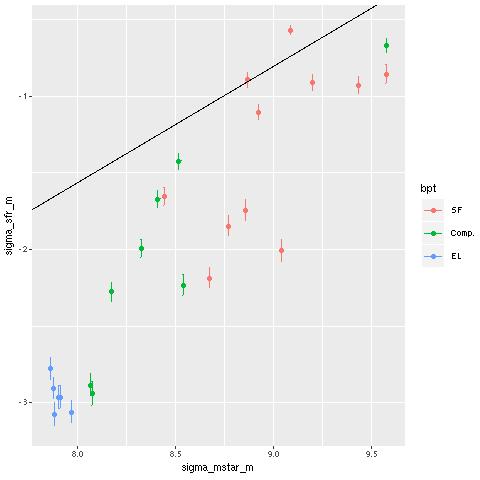 log SFR density vs. log stellar mass density
log SFR density vs. log stellar mass density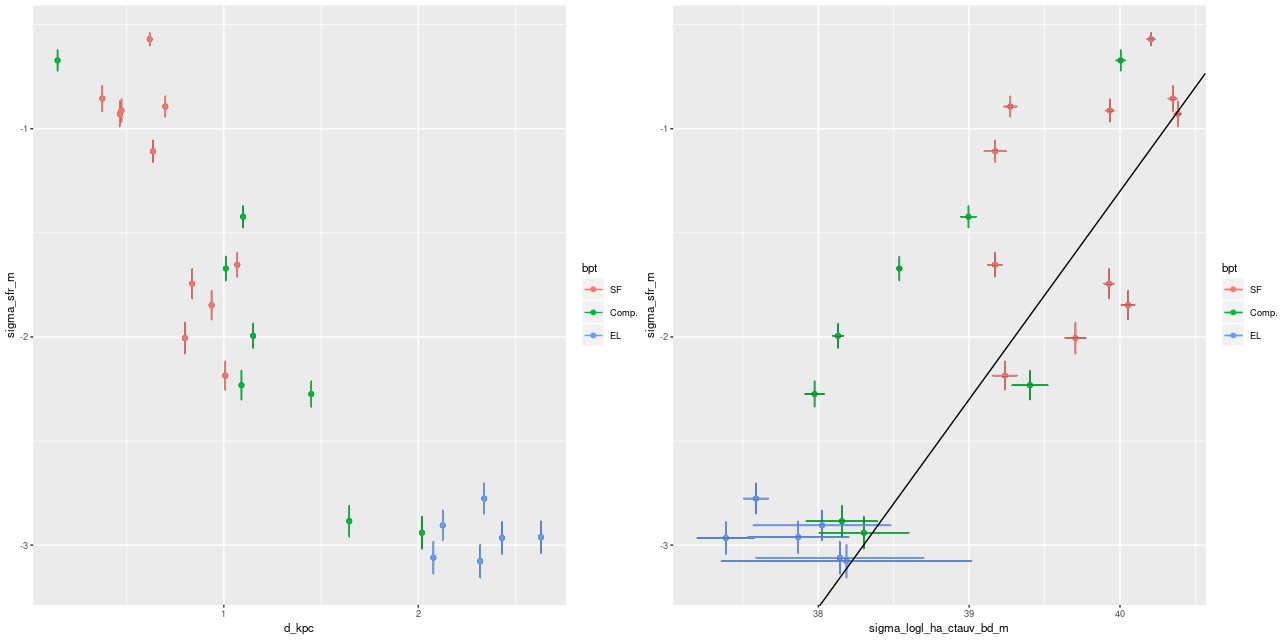 (L) log SFR density vs. radius
(L) log SFR density vs. radius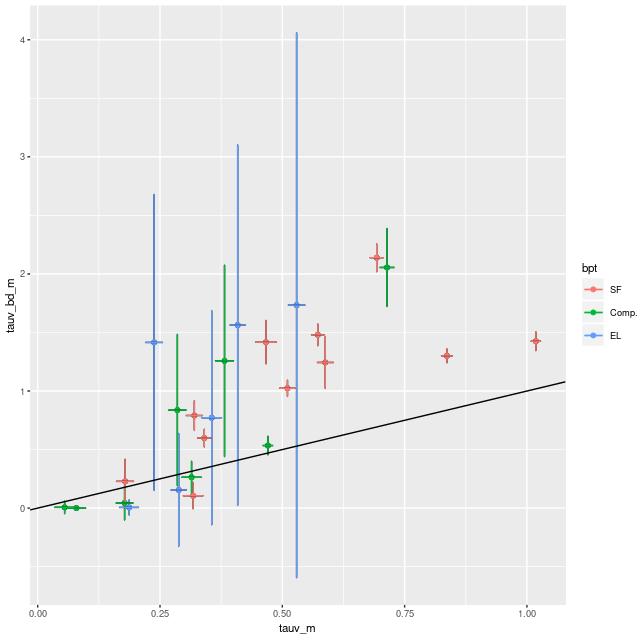 τV estimated from Balmer decrement vs SFH model estimates
τV estimated from Balmer decrement vs SFH model estimates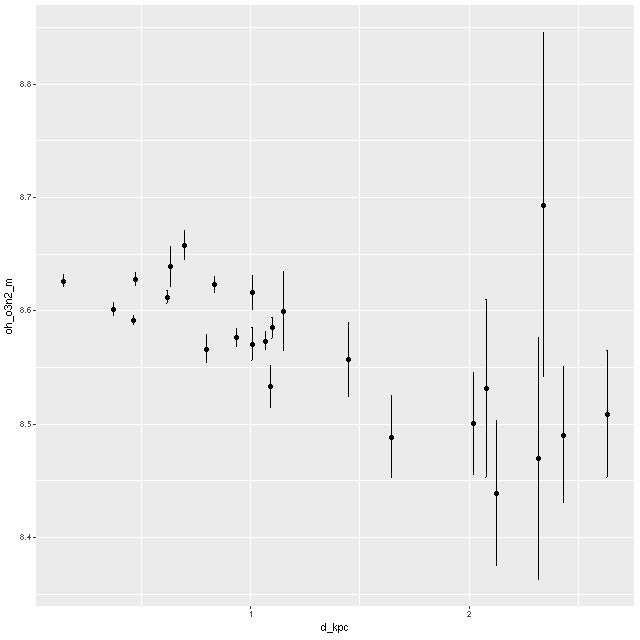 Metallicity 12+log(O/H) vs radius, estimated by O3N2 index
Metallicity 12+log(O/H) vs radius, estimated by O3N2 index