A few brief comments about the simulations, of which I’ve done a few more but will probably bring to an end. First, here is a plot I mentioned but didn’t display last time of the bias in stellar mass estimate against the lookback time to the burst. Points are color coded by burst strength.
Bias is stellar mass estimate vs. lookback time to burst (simulations)
There appears to be a weak trend with burst age up to about 1 Gyr, but at all burst ages and strengths there are biases on both sides of zero. It isn’t clear to me what, if anything else, is driving biases in either direction. The one thing I can say for sure is that the models are overconfident in their ability to estimate the stellar mass since the typical 1σ error bar is under 0.02 dex while the scatter is around ±0.1 dex. I actually think 25% uncertainty in stellar mass estimates is optimistic.
I remembered a short while ago that “outshining” is the term of art in the industry for the situation in which light from recent star formation overwhelms that of the older population. This seems to be a fairly major concern in the literature. A full text search of ADS found 722 instances of its use in the astronomical literature with an explosion of usage after 2006. A quick scan of titles suggests perhaps half of the papers are about SFH modeling. Of course the word is often used in other contexts.
As a slightly more stringent test for outshining I ran one more simulation with a more recent and stronger starburst (tb=0.25 Gyr, fb = 1) than the earlier simulations. Even though the light of the burst population dominates the old base population the latter does have some effect of the combined spectrum (in red below, and offset vertically for clarity): it is redder and the line strengths are altered somewhat relative to the burst population.
Synthetic spectra – strong recent starburst. Fluxes are logarithmically scaled. Total flux (red) is vertically offset.
The model actually captures both the ancient and recent star formation history rather well. The mass growth marginal confidence band at old ages covers the input right up to the beginning of the burst build up, and the post-burst SFR is modeled accurately. The total mass in the model slightly exceeds the input: log(M*) = 4.88±0.02 model, 4.84 input. The model specific star formation rate is nearly identical: -9.33±0.08 model, -9.36 input.
Simulation – strong recent starburst
Shortly after starting these simulations I noticed a paper by Suess et al. (2022) describing simulations with a similar objective of testing the ability of a code named PROSPECTOR to recover star formation histories of post-starburst galaxies in the ideal case of inputs matched to the model, i.e. the inputs are used to generate the mock data and then to fit it. I’m not going to say a lot about either the code or paper. IIRC the first published description of the code (Leja et al. 2017) claimed it to be the first to model non-parametric star formation histories in a fully Bayesian framework. As far as I know this is true in the published literature but they only could use a few very broad time bins; the version used in Suess uses 9. I was already using the full time resolution of my adopted SSP model libraries by then.
The 2022 paper only shows a single, no doubt cherry picked example of a fit to mock data. Like mine their model star formation histories fail to cover the inputs for some age ranges. On the other hand their fits to a mock spectrum appear to be rather poor with large systematic errors. In every model run of mine residuals look very much like 0 mean Gaussian white noise with the expected deviance. They appear to show a similar range of deviations from input stellar masses with no significant error in the mean. Another striking similarity is they find a definite floor to late time star formation rates. As I’ve noted many times my models will always include some contribution from very young populations and there seems to be a floor around 10-11.5 /yr in specific star formation rate.
A much more recent paper by the same group (Wang et al. 2025) looked at simulated data from quite different systems, namely ones with bursty star formation on short time scales. Their work was motivated by yet more simulations of galaxy formation in the early universe. I’m again not going to comment much on this paper except to notice that they concluded that “given the correct SFH model, it is indeed possible to infer the SFH by performing SED fitting.” In other words they had to fine tune their prior to get to the right posterior. I’m sure it’s not as tautological as that sentence appears. Anyway, this motivated me to take a brief look at a few multiple burst simulations. The one shown below has two very sharply peaked ones with roughly the same peak SFR but more total mass in the older one. The model has spread out star formation over the entire interval between the input bursts with a slower rise and decay. Once again the maximum likelihood fit obtained with non-negative least squares captures the timing and relative magnitude of the bursts rather well.
Simulation – 2 short starbursts
Recall that my stellar contribution estimates are parametrized as an N-simplex with an implicit Dirichlet prior with concentration parameter α = 1, which is uniform on the simplex. In principle adopting an explicit prior with a concentration parameter < 1 should encourage a more bursty star formation history without favoring any particular ages, and it did (this run used α = 0.25):
Simulation – 2 short starbursts, modified prior
Here are histograms of a few summary quantities I track: the present day stellar mass, specific star formation rate (100 Myr average), and the summed log-likelihood of the fits to the spectra. Both runs underestimated the sSSFR because the recent burst was more spread out in the models.
Two burst simulation: comparing two priors on stellar contributions for sampled stellar mass, SSFR, and log-likelihood of fits
Finally, I did a few runs with two other libraries: EMILES, which has been my base SSP model library for some time, and BPASS with single star evolution and an upper mass limit of 100 M☉. The parameters I used for the star formation history resulted in a gentle late time revival rather than a burst. Both model runs had late time bursts, although the mass added was negligible. The EMILES run has the characteristic jumps at ages where the age intervals change. Although it’s small the BPASS run has the jump at 1.6 Gyr that I noted previously.
Simulation with C3K input and EMILES as test library
As with real data the EMILES models have some systematic errors around the trough around 7000-7300Å, and also in the blue near the Balmer break.
The BPASS models fit the data surprisingly well, despite using completely different sources for stellar atmospheres.
Comparison PP fit with C3K as test library:
The table below summarizes a couple of the quantities I track. The Progeny C3K models that were used to create the inputs recovers them flawlessly. The other two recover the mass (BPASS is low by more than its nominal uncertainty), but are biased on the high side in late time star formation rate estimates.
Stellar mass
sSFR
input
4.78
-9.91
Progeny C3K
4.78 (0.017)
-9.90 (0.054)
EMILES
4.82 (0.012)
-9.62 (0.028)
BPASS
4.67 (0.03)
-9.73 (0.049)
I’m going to get back to real data now using the Progeny generated libraries. The simulations were a useful exercise if for no other reason than to show that timing faded starbursts can’t be done very accurately, at least with full spectrum fitting at visual wavelengths. I did get some ideas for small code improvements, and the idea of stacking star formation rate and mass growth histories seems like a useful visualization tool.
I’ve written a few times about my dissatisfaction with the EMILES based SSP model library that I’ve used for star formation history modeling for some years and my desultory search for a replacement: This post from early 2024 was the most detailed. Unfortunately neither of the two alternatives I tested were quite satisfactory and my hopes for a MaStar based library from the final MaNGA data release haven’t yet materialized nearly a year later. I’ve given some thought to producing my own but I don’t know exactly how to create sets of summed spectra from a collection of isochrones and given IMF, and it wasn’t really something I wanted to learn. It’s also the case that even though MaStar has many more stellar spectra than any other publicly available collection (MILES, which is the basis for most (semi-)empirical libraries contains just 985) it still doesn’t fully span the space of physical parameters, so additional theoretical or empirical inputs will be required.
Somewhat serendipitously since I was traveling at the time and could easily have missed them a pair of papers appeared on arxiv on 23 October describing an R package named “ProGeny” that does precisely what I need: 2410.17697 and 2410.17698 by A. Robotham and S. Bellstedt. The first paper introduces the package and describes the data currently available for generating what they call Stellar Population Libraries (SPL). While it might seem surprising they used R for this1Python is the language of choice for most astronomers these days. the senior author has published several R packages for various astronomy related tasks, so it isn’t actually surprising that given their apparent need for this tool they chose R to implement it. This was a timely publication for me since I’ve about reached the limit of what I want to do with the EMILES library.
Besides the software which is written entirely in R, the authors did a good job of collating the publicly available data for the required inputs of isochrones and stellar atmospheres and packaging them into FITS files that are readable in R with the help of addon packages. Functions within ProGeny take care of reading the files and creating R objects for further processing.
After installing the software and dependencies and downloading the data files (several GB unzipped) I spent a little time browsing the (rather sparse) documentation and the two vignettes that have been published so far and it was then pretty straightforward to create a library with the recommended inputs. Specifically I used the MIST isochrones combined with the following stellar atmospheres: “C3K” for the base, “PHOENIX” extended, “AGB” from Lancon, “TMAP” for hot stars including remnants: see Table 3 of the first paper for descriptions and references. I used a Kroupa IMF with lower and upper mass limits of 0.1 and 100 M☉, which are fairly standard choices and the same as my EMILES based library. The constructed library has 107 age bins in logarithmic intervals of 0.05 dex ranging from log(T) = 5.0 to 10.3, 15 metallicity bins with log(Z/Z☉) ranging from -4 to +.5 with adopted Z☉ = 0.02, and wavelengths from 5.6 Å to 36 mm. Almost all of the data that I use as model inputs is calculated, including of course the spectra and remaining stellar mass at each age and metallicity. The only thing missing is relative g, r, i band fluxes that I use to calculate model intrinsic colors (something I occasionally look at as a sort of proxy for specific star formation rate). This I have existing code for.
These are more age/metallicity combinations than I need or probably can use and definitely a much larger wavelength range than needed for MaNGA data, so I’m experimenting with subsets. For a first pass I created a “small” subset with 42 ages ranging from log(T) = 6 to 10.1 in 0.1 dex increments and 5 metallicities log(Z/Z☉) = {-0.75, -0.25, 0, 0.25, 0.5}. The metallicity range is similar to my EMILES based library but with one more bin, while there are fewer but more evenly spaced age bins. I’ve also created a “large” subset with all 83 age bins between log(T) = 6 and 10.1, and the same 5 metallicities. I didn’t include younger populations for the simple reason that there’s not much evolution in the first Myr, which makes it difficult or impossible to disentangle their contributions. Similar considerations apply at the old end, and in addition there’s the fact that the current consensus age of the universe is 13.8 Gyr (log(T) = 10.14).
I’ve tentatively chosen a wavelength range of 3300-9000Å. The blue end was chosen to cover the shortest rest frame wavelength in MaNGA spectra for redshifts out to z ≈ 0.1. The red limit is more of a judgment call. Night sky lines become problematic at wavelengths as short as ≈ 8000Å, and in addition there’s an artifact called “blowtorch” by the SDSS team that causes an upturn at the very red end in some spectra. The chosen cutoff is just to the red of a set of Calcium triplet absorption lines at 8500-8700Å that are prominent in some spectra.
Below are comparisons of a few model spectra at solar metallicity and decade age intervals. Recall that the 106 and 107 year models are from the Hr-PyPopStar models of Millan-Irigoyen et al. (2021) including continuum emission. Evidently the newly constructed models are rather more luminous and bluer than the PyPopstar models, while closer to the EMILES models especially at ages > 1 Gyr. Possible differences in absorption line strengths could be due to finer wavelength sampling in the ProGeny models. One possibly significant difference is the MIST isochrones track more stages of stellar evolution than the version of BaSTI used for EMILES, including the asymptotic giant branch and stellar remnants. How much these contribute to the light in the relevant wavelength range and at what ages has yet to be investigated by me.
Sample SSP model spectra – ProGeny generated from c3k base models and EMILES + Pypopstar
Modern collections of stellar isochrones generally include a prescription for mass loss and remnant masses in evolving populations. ProGeny calculates these and includes a data table of stellar masses in its SSP model output. The graph below compares the remaining stellar mass (including remnants) with age for the provisional library versus EMILES. I had assigned a relative stellar mass of 1 to the PyPopstar models, while the MIST isochrones indicate about a 10% mass loss by 107 years. At older ages the masses are very similar. This is much closer agreement than the equivalent graph in Figure 12 of paper 1, so the adopted relation shouldn’t be a source of significant differences in present day stellar mass computations.
Stellar mass vs. age – MIST vs. BaSTI isochrones at several metallicities
So far I’ve only run models for two galaxies with rather different properties, the same ones I wrote about in this post: the post-starburst plateifu 10220-3703 (mangaid 1-201936; NED name WISEA J080218.38+323207.8) and the late type spiral plateifu 11018-12704 (mangaid 1-233951; UGC 8162). Since it has taken much longer to prepare this post than I anticipated, I’m only going to discuss the post-starburst for now. The spiral will have to wait for the new year.
I did an initial set of runs with the same model formulation that I’ve used for a few years now and got some rather surprising results, particularly for outlying regions of the galaxy: model star formation histories looked more like an actively star forming galaxy than a passively evolving one, with younger populations and higher recent star formation rates. The models also had relatively high attenuation values with much steeper attenuation curves than are reported in the literature. This is I think a known “degeneracy” between attenuation and stellar age. The tentative solution was simply to tighten the priors on the two attenuation parameters: I set both upper and lower bounds on the steepness parameter δ: -0.5 < δ < 1.2 and also decreased the scale parameters on the priors for both τV and δ (see this post for my initial discussion of the attenuation model and the following one for problems I initially encountered; the parameterization was based on the work of Salim et al. 2018). Plugging into equation 4 of Salim et al. the limits on δ correspond to 1.6 < RV < 8.7, which is still a very large range.
As can be seen from the SFH and mass growth plots below the C3K based models are fairly consistent with EMILES, although with generally higher late time star formation rates. Interestingly, the “big” models also have generally higher late time SFR than the “small” models even though they have the same stellar ingredients with just different time resolution. Both sets of models have gotten rid of the objectionable artificial jumps in star formation rates where the BaSTI models have abrupt changes in age intervals.
One fairly significant difference is that in the EMILES based models the burst appears to be strongly centrally concentrated, fading beyond about 2 kpc from the center. The C3K based models by contrast show a burst throughout. In the center the EMILES models have a complex, multipeaked evolution through the burst, while the C3K models have a fairly smooth rise and decline. Whatever hopes I had that it might be possible to time major events in possible merger scenarios seem to have been misguided., although the age and magnitude of the burst agree in all model runs.
Plateifu 10220-3703 (mangaid 1-201936) Model star formation histories for all binned spectra and 3 distinct SSP model libraries
Plateifu 10220-3703 (mangaid 1-201936) Model mass growth histories for all binned spectra and 3 distinct SSP model libraries
Here are pairwise differences in mean values between the models for some of the summary quantities I track. Some of the differences are fairly large, which just reinforces my longstanding opinion that true uncertainties are much larger than what’s captured in the posteriors of model runs.
Plateifu 10220-3703 (mangaid 1-201936) Pairwise differences in mean SFR density estimates.Plateifu 10220-3703 (mangaid 1-201936) Pairwise differences in mean stellar mass density estimates.Plateifu 10220-3703 (mangaid 1-201936) Pairwise differences in mean SSFR estimates.
And finally, here is a closer look at star formation history models for the two fibers closest to the center:
Plateifu 10220-3703 (mangaid 1-201936) SFH and mass growth history estimates for innermost 2 spectra and 3 SSP libraries
And here are (posterior predictive) fits to the data for the central spectrum with the large C3K based model (L) and EMILES (R). Both of these have some problematic areas, with some stretches of continuum and absorption line strengths “off” a bit. Note that the C3K model does better with the trough around 7200Å. The continuum upturn at the red end can also be seen in C3K model, which suggests I may want to consider truncating the model spectra a few hundred Ångstroms to the blue. Overall though fits to the data are very similar, and there’s little difference between the “large” and “small” C3K subsets.
Plateifu 10220-3703 (mangaid 1-201936) fits to the central spectrum with C3K and EMILES libraries
ProGeny is a useful tool and I hope the authors will be able to maintain it and add new capabilities and data sources. I still have a few things to do before resuming a modeling campaign: most importantly perhaps choosing a final subset of the full library, specifically the number of age and metallicity bins. The execution time of a model run is roughly proportional to the number of stellar contribution parameters. For this data set the average time with the EMILES library (224 SSP model spectra) was 618 sec, 576 sec for the small C3K library (210 spectra), and 1038 sec. for the large C3K library (415 spectra). That’s more time than I’d like to take. Would it be preferable to have a coarser metallicity grid, say log(Z/Z☉) = {-0.75, 0, 0.5} with the full 0.05 dex age spacing or a finer metallicity grid with 0.1 dex age bins? I don’t know: some fake data exercises might be appropriate at this point.
I still have some interest in using the MaStar spectra but there are some technical issues to solve. For one thing the data available on Skyserver are corrected to above the atmosphere but not for galactic extinction and are just apparent flux values rather than absolute ones. They also need to be reduced to rest frame wavelengths. ProGeny’s model spectra have a very wide wavelength range, which I assume is required to make the integrated model flux equal to the bolometric luminosity. Even though I don’t really need wavelengths outside the range of BOSS spectra I would need to extend them somehow anyway. Finally (?) the parameter coverage (temperature, gravity, metallicity) is still not quite complete, especially at for hot stars and very luminous ones so it would still be necessary to supplement the base library.
After a month off I returned to have another look at Millan-Irigoyen et al.’s high resolution “pypopstar” SSP model spectral libraries. First, I couldn’t find a more suitable subset of the full library than I used last time, so I decided just to try augmenting the existing Emiles based library with some younger spectra from pypopstar. Of course I had already done this with models from the 2013 update of BC03, so the plan was to replace those with a slightly finer grained selection at the young end. That raises the question of which ages to select. The youngest age model in the BaSTI isochrone based library is 30Myr (log T = 7.48), and we’re spoiled for choice of models at younger ages than that: there are 53 between log T = 5 and log T = 7.45, far more than necessary. Looking at the graph below, which just plots model spectra for the solar metallicity bin at decadal time invervals there’s very little spectral evolution between 105 and 106 years with the latter being slightly brighter at all relevant wavelengths. This is no surprise since even the most massive stars have main sequence lifetimes ∼106 years. The model spectra continue to get brighter up to around 106.6 years (4 Myr) and then turn around, becoming noticeably fainter and redder by 107 years.
pypopstar solar metallicity model spectra in decadal age increments
I decided to take the log T = 6 models as youngest, discarding the sub Myr ones altogether. This is mostly due to the inability to distinguish them and also just for purposes of visualization. I usually use logarithmically scaled lookback time axes in SFH history plots, and selecting a minimum value of 5 results in too much real estate given to very recent times where usually nothing much is happening.
Without giving this a lot of thought I selected just 3 ages to add: log T = 6, 6.51, and 7. The youngest Emiles model is log T = 7.48, so this gives nearly constant increments around 0.5 dex. This choice gives a reasonably smooth transition from the theoretical spectra to empirical ones, except for maybe the lowest metallicity bin. I also chose the “total” spectra including both stellar and emission continuum light in hopes of better modeling the continuum in star forming galaxies. To merge the high resolution pypopstar models into the library I just used a spline fit to interpolate the model spectra onto the same wavelength grid as Miles. This should (I hope) preserve total flux nearly enough. A more refined treatment would also consider that these still have higher resolution than Miles spectra, which are around 2.5 Å. I didn’t take the time. The merged library therefore has 56 time bins times 4 metallicity bins for a total of 224 model spectra. I retained the same rest frame wavelength range (3464.9 – 8864 Å) as the Emiles subset I’ve been using for several years
The youngest SSP model spectra for the EMILES library augmented with young pypopstar spectra
The obvious next step is to use this library in some models and see how they compare to Emiles. Paging through my samples of spirals with MaNGA observations I picked, for no really good reason, this one:
MaNGA plateifu 8452-12703 (mangaid 1-148068)
Clearly it has star forming regions in its arms as well as a prominent bar and rather red, possibly passively evolving nucleus. After binning to my usual threshold S/N of 5 there were 122 spectra, which were analyzed in the usual way using both Emiles and Emiles + popstar. And here’s the main result of interest, the model star formation histories for all 122 spectra, ordered by distance from the nucleus.
Model star formation histories for MaNGA plateifu 8452-12703 compared.
Red: Emiles + pypopstar
Blue: Emiles + BC03
There’s little or no difference in the model star formation histories for the common components of the libraries. The pypopstar components indicate that the star formation rate continues at relatively constant rates up to recent times. The modest differences at the young end don’t necessarily mean anything. I more or less arbitrarily assigned an age of 10Myr to the BC03 model spectra, which were actually taken from 1Myr models. There’s no real way to tell what the actual effective age of those contributors is — if it’s typically younger than 10Myr the SFR in the youngest bin would be correspondingly higher and a little lower in the next age bin.
Given the similarities in the detailed star formation histories it shouldn’t be much of a surprise that summary quantities are quite similar too. To illustrate a few, here are mean values of the stellar mass surface density:
Model mean values of stellar mass density for MaNGA plateifu 8452-12703 compared — Emiles + pypopstar vs Emiles + BC03
the star formation rate surface density (100 Myr average):
Model mean values of SFR density for MaNGA plateifu 8452-12703 compared — Emiles + pypopstar vs Emiles + BC03
The specific SFR:
Model mean values of SSFR for MaNGA plateifu 8452-12703 compared — Emiles + pypopstar vs Emiles + BC03
The lines with confidence intervals in these plots are from OLS fits taking no account of nominal uncertainties in either sets of variables, and shouldn’t be used to infer any trends. In any case all differences are very small. Finally, here are histograms of all sample values of SFR density for all spectra. Again, these are nearly identical:
Sample distributions of SFR density over all spectra compared — Emiles + pypopstar vs Emiles + BC03
After running multiple sets of models it became apparent that this wasn’t a very stringent test of the usefulness of the proposed library additions because this galaxy has very anemic star formation. In fact it’s one of Masters et al.‘s “passive” red spirals, which I should have recognized. It was also one of the first several dozen galaxies with AGN found in MaNGA, which doesn’t necessarily (but might, along with perhaps the prominent bar) account for the weak star formation. My model runs show “LINER” like emission line ratios in the center, which does point to the presence of a weak AGN.
Briefly now, I picked two more disk galaxies with obvious regions of vigorous star formation and repeated this exercise. To make this short I’m just going to post the star formation histories for all binned spectra.
MaNGA plateifu 8449-3703 (RA 169.299, DEC 23.586)
MaNGA 1-488712, plateifu 8449-3703 — SDSS cutoutModel star formation histories for MaNGA plateifu 8449-3703 compared.
Blue: Emiles + pypopstar
Red: Emiles + BC03
MaNGA plateifu 8318-9101 (RA 196.086 DEC 45.057)
MaNGA 1-259618, plateifu 8318-9101 — SDSS cutout Model star formation histories for MaNGA plateifu 8318-9101 compared.
Blue: Emiles + pypopstar
Red: Emiles + BC03
Spectra in nearby age and metallicity bins are highly corrrelated, which among other things means that adding or subtracting some from the set of “predictors” potentially changes the values inferred for others as well. In these two sets of model runs we do see some differences in the common Emiles portion of the libraries, but they’re quite small and change no qualitative inferences. So my conclusion for now is that adding these theoretical spectra is a reasonable strategy, but one that doesn’t have much apparent impact on model results.
Well that’s probably all for a while. The final MaNGA data release is now promised for December 2021, which should approximately double the number of galaxies and I hope offer some data reduction improvements. There will also be a very large release of stellar spectra that should form the basis for new SSP libraries in the (hopefully) near future.
Back in July a paper by Millan-Irigoyen et al. titled “HY-PYPOPSTAR: high wavelength-resolution stellar populations evolutionary synthesis model” was posted to arxiv, and shortly thereafter data in the form of the promised high resolution spectra were made available at https://www.fractal-es.com/PopStar/#ingredients. Unlike MILES and its variations or BC03 this is a purely theoretical library, with the spectra calculated from model atmospheres instead of using empirical spectra of actual stars.
I looked briefly at one other theoretical library some time ago and concluded (IIRC) that the model spectra had much too blue continua at all ages, making it unsuitable for full spectrum fitting. A brief visual inspection of this library (as well as Figure 8 in the paper) indicates that’s not the case here. One thing that may compromise its usefulness is that although there are 106 age bins in the models they are very irregularly spaced and heavily weighted towards younger ages as shown below.
Age range
Number of spectra
5 ≤ log T < 6
4
6 ≤ log T < 7
34
7 ≤ log T < 8
35
8 ≤ log T < 9
9
9 ≤ log T < 10
15
log T ≥ 10
9
Number of SSP model spectra by age range in HR-pypopstar
At least in the wavelength range of SDSS/MaNGA spectra there is little evolution in spectroscopic properties between 105 and 106 years and even though it speeds up afterwards the effective time resolution of SFH models is still lower than the supplied number of time bins for the next two decades.
Sample young population spectra from hrPypopstar
For a preliminary look at the library’s suitability for full spectrum modeling I selected a 42 time bin subset with all 4 available metallicity bins and Kroupa IMF, truncating the wavelength range to 3400-9000 Å, which is just a little larger than the Emiles subset I use. The time bins were chosen by hand — I was trying to get evenly spaced bins in log time but this proved not to be feasible. The authors produced two sets of libraries for each of 4 IMFs: they did an apparently careful job of counting the number of ionizing photons for several species and calculated sets of SSP models with and without emission continuum. For these trial runs I used both sets of libraries, which I’ll compare below. No code modifications were required because they use the same peculiar but computationally convenient flux units for spectra.
I just ran a few models for the central fiber spectrum of KUG 0859+406 (MaNGA plateifu 8440-6104). First, here is the star formation rate history compared to the most recent Emiles run:
Model star formation histories for central fiber of MaNGA plateifu 8440-6104 (T) Emiles (M) hrPypopstar with emission continuum ( B) hrPypopstar stellar light only
Or, looking at the model mass growth histories:
Model mass growth histories for central fiber of MaNGA plateifu 8440-6104
Red: Emiles
Blue: hrpypopstar including emission continuum
Green: hrpypostar stellar light only
The starburst occurs later and is somewhat weaker in the pypopstar models. Interestingly all models have a late time revival of star formation after a period of quiescence. To get all the graphs to line up I truncated the pypopstar model star formation histories at 10 Myr. Here are the full histories:
Model star formation histories for central fiber of MaNGA plateifu 8440-6104
(T) hrPypopstar with emission continuum
(B) hrPypopstar stellar light only
Emission continuum is significant mostly at ages < 10Myr and this is reflected in some difference in late time model star formation histories. This has little effect on other modeled quantities.
At a glance fits to the galaxy flux data look very similar. Both sets of models have problems in some wavelength ranges and both have some issues with the [N II]+Hα emission complex, probably because the lines don’t quite have gaussian profiles. In terms of summed log-likelihood the Emiles fit is actually almost a factor of 2 better than pypopstar.
Comparison of model fits to data
(L) Emiles
(R) Hrpypopstar
The pypopstar models have larger optical depths of attenuation and steeper attenuation curves than the Emiles models, demonstrating once again the interplay among attenuation, attenuation relationship, and stellar ages:
Model distributions of attenuation parameters τV and δ for runs with Emiles library and hrPypopstar on the central fiber of MaNGA plateifu 8440-6104
Some other modeled quantities are very similar, for example the stellar mass density:
Comparison of model stellar mass density
red: Emiles
blue: hrpypopstar with emission continuum
While the modeled specific star formation rate differs by ~0.4 dex thanks to the more recent starburst in the pypopstar models:
Comparison of model specific star rate (sSFR)
red: Emiles
blue: hrpypopstar with emission continuum
I still haven’t decided exactly what to do with these interesting SSP model libraries. I will probably take a more systematic look at extracting a subset of time bins that evolve at a consistent rate by some measure. This will certainly require many fewer than the published 106 bins. What may be more promising is to graft some young age SSPs onto my existing Emiles library. The 4 published metallicity bins are pretty closely matched to the Emiles subset I use, and 4 or 5 SSP’s would fill out the ages up to the youngest (30 Myr) in the BaSTI isochrones. I already use unevolved BC03 models for this purpose. Using the models that include continuum emission would also solve the problem of how to model that in starforming galaxies (but not galaxies with strong AGN emission unfortunately).
This paper (arxiv ID 2103.16070) is pretty old by now, having been posted on arxiv back in early April. The basic premise of the work is mildly interesting: the author searched MaNGA for galaxies that would meet conventional criteria for post-starburst (aka K+A etc.) spectra if observed at a redshift high enough that the entire galaxy would be covered by a single fiber like the original SDSS spectroscopes. Somewhat surprisingly, he found just 9 that met his selection criteria in the DR15 sample of ~4500 galaxies.
I have to say the paper itself is forgettable, but a manageably sized sample of MaNGA data that’s complete by some criterion is worth a look, and I have a long-standing interest in post-starburst galaxies in particular. So, I ran my current SFH modeling code on all 9 — by the way this was completed some time ago. It’s just taken me a while to get around to generating some graphics and sitting down to write.
The author only measured a few observable quantities: Hδ equivalent width and the 4000Å break index Dn(4000), along with Hα emission equivalent width and (normalized) fluxes. I long ago validated my own absorption line measurements of SDSS single fiber spectra against the MPA-JHU measurement pipeline, which was the gold standard for several years (but last run on DR8). My measurements and uncertainty estimates are in excellent agreement with theirs, so I have a fair amount of confidence in them. Emission line fluxes also agree with published measurements with considerably more scatter. My emission line equivalent widths on the other hand are completely unchecked. So, one of my tasks was to compare my equivalent width measurements with Wu’s. I did not attempt to exactly reproduce his work – I binned spatially using my usual Voronoi partitioning approach whereas Wu binned in elliptical annuli. With that difference in mind the next two plots should be compared to his Figures 4 and 5.
The first two graphs show the radial trends (relative to the effective radii per the NASA/SLOAN catalog) in the Lick HδA and Dn(4000) indexes. These both show very similar trends to Wu’s measurements although with more scatter. This is expected because fewer spectra go into each point in general — from the text it appears Wu binned several separate measurements for each displayed point. Also, I made no attempt to deproject distances. One feature of the Hδ versus radius plot that’s a little different is the trend generally flattens out beyond ∼1 effective radius, while Wu shows a roughly linear trend out to 1.5 Re. This might just be a visible effect of me displaying the trends out to larger radii.
Radial trends of Lick HδA and Dn4000 for 9 MaNGA “post-starburst” galaxies from Wu (2021) – arxiv 2103.16070
The Hα emission line measurements are similarly in broad agreement. Like Wu, I find that there are two distinct trends in emission: either moderately strong centrally with a rapid decline or weak throughout with a relatively flat trend. One galaxy (with MaNGA plateifu 9876-12701) has no detectable emission. I haven’t looked in detail at emission line ratios to compare to Wu’s Figure 7, but there’s general agreement that some residual star formation is present in some of the sample and weak AGN or ionization by hot evolved stars in others.
Radial trends of Lick Hα equivalent width and luminosity density for 9 MaNGA “post-starburst” galaxies from Wu (2021) – arxiv 2103.16070
A fairly common failing of this literature (IMO) is the use of proxies for recent star formation but not attempting actually to model star formation histories. There are plenty of publicly available tools for that available now, so there’s really no reason not to perform such modeling exercises. Wu did do some toy evolutionary modeling and posted a graph of trajectories through the Hα emission – Hδ absorption plane, which can scarcely unambiguously constrain star formation histories. Of course much of my hobby time is spent generating fine grained model star formation histories, so let’s take a look at a few selected results.
First, here are maps of the modeled fraction of the current stellar mass in stars of ages between 0.1 and 1 Gyr, very roughly the age range that produces a post-starbursty spectrum. Six of the galaxies have more or less strongly centrally concentrated intermediate age populations, which is generally what’s expected especially in the major merger pathway to a post-starburst interval. I’ll discuss this a little further below.
Maps of fractional stellar mass in intermediate age populations for 9 MaNGA “post-starburst” galaxies from Wu (2021) – arxiv 2103.16070
In more detail here are summed mass growth histories for the sample, that is all modeled star formation histories for a given observation are summed to produce a single global estimate. I’ve shown total masses here. Because of the pointing strategy MaNGA uses the fiber positions overlap to produce a 100% filling factor, so simply summing overestimates masses by about 0.2dex according to a calculation I performed some time ago. The present day masses in the plot below actually agree pretty well with the values listed in Table 1 of the paper, with an average difference of ~0.1 dex (this is probably because at least some of the light falls outside the IFU footprint in most of these galaxies, offsetting some of the overcounted mass).
Integrated mass growth histories for 9 MaNGA “post-starburst” galaxies from Wu (2021) – arxiv 2103.16070
Somewhat surprisingly several of these galaxies show little evidence of an actual burst of star formation in the recent past, at least at the global level. Some of these could simply have had star formation truncated recently, which can produce a poststarburst spectral signature for a time. Overall intermediate age stars contribute ~ 6-20% of the present day stellar mass, with the two largest contributions in the low mass galaxies in the bottom row of the plot.
There are some other oddities in this small sample. At least 3 galaxies are dwarf ellipticals or perhaps dwarf irregulars (in the case of plateifu 9876-12701), and two others have stellar masses under ~5 x 109 M⊙. Two of the low mass galaxies are in or near the Coma cluster, which suggests environmental effects as the probable cause of quenching. Another possible issue with the low mass galaxies is the infamous “age-metallicity degeneracy,” which refers to the fact that old, low metallicity populations “look like” younger, more metal rich ones by many measures. The Balmer lines in particular fade more slowly with age in lower metallicity populations, and the 4000Å break also becomes metallicity sensitive (smaller at low metallicities) at older ages.
There is only one clear merger remnant in the sample (with plateifu 8440-6104, which I will get to in a moment). One other galaxy (plateifu 8458-6102) is located in a compact group that appears (in Legacy survey imaging) to be embedded in a cloud of extragalactic light. Finally, two galaxies in this sample have been cataloged as K+A based on SDSS spectra — 8080-3702 and 9494-3701, while two others in the catalog of Melnick and dePropris (2013) are not.
SDSS thumbnails of the sample
The one clear merger remnant in the sample is an old friend of mine, and in fact I wrote three lengthy posts about this one back in 2018. In perusing those posts I noticed that the current set of model runs have a slightly weaker and more recent burst than the earlier runs. Also a double peak in the earlier runs has gone away in these, which means my early speculation that it might be possible to time crucial events in a merger from the detailed SFH model was too optimistic. On the other hand the model burst strength in the earlier runs was uncomfortably large, indicating an exceptionally gas rich merger and efficient processing of gas into stars. The current runs have a more reasonable ~10% of mass in the burst. So, I will look into those earlier runs and try to figure out what changed. Fortunately I’m a data hoarder and R is self-archiving to some extent.
KUG 0839+406, one of 9 “post-starburst” galaxies in Wu (2021)
The idea of looking at the integrated properties of IFU data to pick a post-starburst sample seems reasonable, but this sample appears to me to be both incomplete and possibly with some false positives. When DR17 is finally released I plan to try to develop my own criteria. As I’ve already shown using SDSS spectra alone to select a sample is doomed to produce lots of false positives.
I should finally mention one other paper pursuing a similar idea by Greene et al. (2021) showed up on arxiv recently. The authors lost me when they used the phrase “carefully curated” in their introduction, which was otherwise pretty well written up to that point. Maybe I’ll take another look anyway.
Well that was simple enough. I made a simple indexing error in the R data preprocessing code that resulted in a one pixel offset between the template and galaxy spectra, which effectively resulted in shifting the elements of the convolution kernel by one bin. I had wanted to look at a rotating galaxy to perform some diagnostic tests, but once I figured out my error this turned out to be a pretty good validation exercise. So I decided to make a new post. The galaxy I’m looking at is NGC 4949, another member of the sample of passively evolving Coma cluster galaxies of Smith et al. It appears to me to be an S0 and is a rapid rotator:
NGC 4949 – SDSS imageNGC 4949 – radial velocity map
These projected velocities are computed as part of my normal workflow. I may in a future post explain in more detail how they’re derived, but basically they are calculated by finding the best redshift offset from the system redshift (taken from the NSA catalog which is usually the SDSS spectroscopic redshift) to match the features of a linear combination of empirically derived eigenspectra to the given galaxy spectrum.
First exercise: find the line of sight velocity distribution after adjusting to the rest frame in each spectrum. This was the originally intended use of these models. This galaxy has fairly low velocity dispersion of ~100 km/sec. so I used a convolution kernel size of just 11 elements with 6 eigenspectra in each fit. Here is a summary of the LOSVD distribution for the central spectrum. This is much better. The kernel estimates are symmetrical and peak on average at the central element. The mean velocity offset is ≈ 9.5 km/sec, which is much closer to 0 than in the previous runs. I will look briefly at velocity dispersions at the end of the post: this one is actually quite close to the one I estimate with a single component gaussian fit (116 km/sec vs 110).
Estimated LOSVD of central spectrum of NGC 4949
Next, here are the posterior mean velocity offsets for all 86 spectra in the Voronoi binned data, plotted against the peculiar velocity calculated as outlined above. The overall average of the mean velocity offsets is 4.6 km/sec. The reason for the apparent tilt in the relationship still needs investigation.
Mean velocity offset vs. peculiar velocity. All NGC 4949 spectra.
Exercise 2: calculate the LOSVD with wavelengths adjusted to the overall system redshift as taken from the NSA catalog, that is no adjustment is made for peculiar redshifts due to rotation. For this exercise I increased the kernel size to 17 elements. This is actually a little more than needed since the projected rotation velocities range over ≈ ± 100 km/sec. First, here is the radial velocity map:
Radial velocity map from Bayesian LOSVD model with no peculiar redshifts assigned.
Here’s a scatterplot of the velocity offsets against peculiar velocities from my normal workflow. Again there’s a slight tilt away from a slope of 1 evident. The residual standard error around the simple regression line is 6.4 km/sec and the intercept is 4 km/sec, which are consistent with the results from the first set of LOSVD models.
Velocity offsets from Bayesian LOSVD models vs. peculiar velocities
Exercise 3: calculate redshift offsets using a set of (for this exercise, 6) eigenspectra from the SSP templates. Here is a scatterplot of the results plotted against the redshift offsets from my usual empirically derived eigenspectra. Why the odd little jumps? I’m not completely sure, but my current code does an initial grid search to try to isolate the global maximum likelihood, which is then found with a general purpose nonlinear minimizer. The default grid size is 10-4, about the size of the gaps. Perhaps it’s time to revisit my search strategy.
Redshift offsets from a set of SSP derived eigenspectra vs. the same routine using my usual set of empirically derived eigenspectra.
Final topic for now: I mentioned in the last post that posterior velocity dispersions (measured by the standard deviation of the LOSVD) were only weakly correlated with the stellar velocity dispersions that I calculate as part of my standard workflow. With the correction to my code the correlation while still weak has greatly improved, but the dispersions are generally higher:
Velocity dispersion form Bayesian LOSVD models vs. stellar velocity dispersion from maximum likelihood fits.
A similar trend is seen when I plot the velocity dispersions from the LOSVD models with correction only for the system redshift and a wider convolution kernel (exercise 2 above) with the fully corrected model runs (exercise 1):
These results hint that the diffuse prior on the convolution kernel is responsible for the different results. As part of the maximum likelihood fitting process I estimate the standard deviation of the stellar velocity distribution assuming it to be a single component gaussian. While the distribution of kernel values in the first graph look pretty symmetrical the tails are on average heavier than a gaussian. This can be seen too in the LOSVD models with the larger convolution kernel of exercise 2. The tails have non-negligible values all the way out to the ends:
Now, what I’m really interested in are model star formation histories. I’ve been using pre-convolved SSP model templates from the beginning along with phony emission line spectra with gaussian profiles with some apparent success. My plan right now is to continue that program with these non-parametric LOSVD’s. The convolutions could be carried out with posterior means of the kernel values or by drawing samples. Repeated runs could be used to estimate how much variation is affected by uncertainty in the kernel.
How to handle emission lines is another problem. For now stepping back to a simpler model (no emission, no dust) would be reasonable for this Coma sample.
This paper by J. Falcón-Barroso and M. Martig that showed up on arxiv back in November interested me for a couple reasons. First, this was one of the first research papers I’ve seen to make use of the Stan language or indeed any implementation of Hamiltonian Monte Carlo. What was even more interesting was they were doing exactly something I experimented with a few years ago, namely estimating the elements of convolution kernels for non-parametric description of galaxy stellar kinematics. And in fact their Stan code posted on github has comment lines linking to a thread on discourse.mc-stan.org I initiated where I asked about doing discrete convolution by direct multiplication and summation.
The idea I was pursuing at the time was to use sets of eigenspectra from a principal components decomposition of SSP model spectra as the bases for fitting convolved model spectra, with the expectation being that considerable dimensionality reduction could be achieved by using just the leading PC’s, which would in turn speed up model fitting. In fact this was certainly the case, although at the time I perhaps overestimated the number of components needed 1I mentioned in that thread that by one criterion — now forgotten — I would need 42, which is about an 80% reduction from the 216 spectra in the EMILES subset I use but still more than I expected. and I found the execution time to be disappointingly large. Another thing I had in mind was that I wanted to constrain emission line kinematics as well, and I couldn’t quite see how to do that in the same modeling framework. So, I soon turned away from this approach and instead tried to constrain both kinematics and star formation histories using the full SSP library and what I dubbed a partially parametric approach to kinematic modeling, using a convolution kernel for the stellar component and Gauss-Hermite polynomials for emission lines. This works, more or less, but it’s prohibitively computationally intensive, taking an order of magnitude or more longer to run than the models with preconvolved spectral templates. Consequently I’ve run this model fewer than a handful of times and only on a small number of spectra with complicated kinematics.
Falcón-Barroso and Martig started with exactly the same idea that I was pursuing of radically reducing the dimensionality of input spectral templates through the use of principal components. They added a few refinements to their models. They include additive Legendre polynomials in their spectral fits, and they also “regularize” the convolution kernels with informative priors of various kinds. Adding polynomials is fairly common in the spectrum fitting industry, although I haven’t tried it myself. There is only a short segment in the red that is sometimes poorly fit with the EMILES library, and that would seem to be difficult to correct with low order polynomials. What does affect the continuum over the entire wavelength range and could potentially cause a severe template matching issue is dust reddening, and this would seem to be more suitable for correction with multiplicative polynomials or simply with the modified Calzetti relation that I’ve been using for some time.
I’m also a little ambivalent about regularizing the convolution kernel. I’m mostly interested in the kinematics for the sake of matching the effective SSP model spectral resolution to that of the spectra being modeled for star formation histores, and not so much in the kinematics as such.
I decided to take another look at my old code, which somewhat to my surprise I couldn’t find stored locally. Fortunately I had posted the complete code on that discourse.mc-stan thread, so I just copied it from there and made a few small modifications. I want to keep things simple for now, so I did not add any polynomial or attenuation corrections and I am not trying to model emission lines. I also didn’t incorporate priors to regularize the elements of the convolution kernel. Without an explicit prior there will be an implicit one of a maximally diffuse dirichlet. I happen to have a sample of MaNGA spectra that are well suited for a simple kinematic analysis — 33 Coma cluster galaxies from a sample of Smith, Lucey, and Carter (2012) that were selected to be passively evolving based on weak Hα emission, which virtually guarantees overall weak emission. Passively evolving early type galaxies also tend to be nearly dust free, making it reasonable not to model it.
I’ve already run SFH models for all of these galaxies, so for each spectrum in a galaxy I adjust the wavelengths to rest frame using the system redshift and redshift offsets that were calculated in the previous round. I then regrid the SSP library (as usual the 216 component EMILES subset) templates to the galaxy rest frame and extract the region where there is coverage of both the galaxy spectrum and the templates. I then standardize the spectra (that is subtract the means and divide by the standard deviations) and calculate the principal components using R’s svd() function. I again rescale the eigenvectors to unit variance and select the number I want to use in the models. I initially did this by choosing a threshold for the cumulative sum of the eigenvalues as a fraction of the sum of all. I think instead I should use the square of the eigenvalues since that will make the choice based on the fraction of variance in the selected eigenvectors. With the former criterion a threshold of 0.95 will result in selecting 8 eigenspectra, 0.975 results in 13 (perhaps ± 1). In fact as few as 2 or 3 might be adequate as noted by Falcón-Barroso and Martig. The picture below of three eigenspectra from one model run illustrates why. The first two look remarkably like real galaxy spectra, with the first looking like that of an old passively evolving population, while the second has very prominent Balmer absorption lines and a bluer continuum characteristic of a younger population. After that the eigenspectra become increasingly un-spectrum like, although familiar features are still recognizable but often with sign flips.
First three eigenspectra from a principal components decomposition of an SSP model spectrum library
The number of elements in the convolution kernel is also chosen at run time. With logarithmic wavelength binning each wavelength bin has constant velocity width — for SDSS and MaNGA spectra of 69.1 km/sec. If a typical galaxy has velocity dispersion around 150 km/sec. and we want the kernel to be ≈ ±3 σ wide then we need 13 elements, which I chose as the default. Keep in mind that I’ve already estimated redshift offsets from the system value for each spectrum, so a priori I expected the mean velocity to be near 0. If peculiar velocities have to be estimated the convolution kernel would need to be much larger. Also in giant ellipticals and other fairly rare cases the velocity dispersion could be much larger as we’ll see below.
Lets look at a few examples. I’ve only run models so far for three galaxies with a total of 434 spectra. One of these (SDSS J125643.51+270205.1) appears disky and is a rapid rotator. The most interesting kinematically is NGC 4889, a cD galaxy at the center of the cluster. The third is SDSS J125831.59+274024.5, a fairly typical elliptical and slow rotator. These plots contain 3 panels. The left shows the marginal posterior distribution of the convolution kernels, displayed as “violin” plots. The second and third are histograms of the mean and standard deviation of the velocities. For now I’m just going to show results for the central spectrum in each galaxy. These are fairly representative although the distributions in each velocity bin get more diffuse farther out as the signal/noise of the spectra decrease. I set the kernel size to the default for the two lower mass galaxies. The cD has much higher velocity dispersion of as much as ~450 km/sec within the area of the IFU, so I selected a kernel size of 39 (± 1320 km/sec) for those model runs. The kernel appears to be fairly symmetrical for the rotating galaxy (top panes), while the two ellipticals show some evidence of multiple kinematic components. Whether these are real or statistical noise remains to be seen.
Distribution of kernel, velocity offset, and velocity dispersion. Central spectrum of MaNGA plateifu 8931-1902Distribution of kernel, velocity offset, and velocity dispersion. Central spectrum of MaNGA plateifu 8933-6101Distribution of kernel, velocity offset, and velocity dispersion. Central MaNGA spectrum of NGC 4889 (plateifu 8479-12701)
There are a couple surprises: the velocity dispersions summarized as the standard deviations of the weighted velocities are at best weakly correlated and generally larger than the values estimated in the preliminary fits that I perform as part of the SFH modeling process. More concerning perhaps is the mean velocity offset averages around -50 km/sec. This is fairly consistent across all three galaxies examined so far. Although this is less than one wavelength bin it is larger than the estimated uncertainties and therefore needs explanation.
Distribution of mean velocity offsets from estimated redshifts for 434 spectra in 3 MaNGA galaxies.
Some tasks ahead: Figure out this systematic. Look at regularization of the kernel. Run models for the remaining 30 galaxies in the sample. Look at the effect on SFH models.
A while back I came across a paper by Fraser-McKelvie et al. (2020, arxiv id 2009.07859) that used Galaxy Zoo classifications to select a sample of barred spiral galaxies with MaNGA observations. This was a followup to a paper by Peterken et al. (2020, arxiv id 2005.03012) that also used Galaxy Zoo classifications to select a parent sample of spiral galaxies (barred and otherwise). There’s nothing new about using GZ classifications for sample selection of course, although these papers are somewhat notable for going farther down the decision tree than usual. What was new to me though when I decided to get my own samples is the SDSS CasJobs database now has a table named mangaGalaxyZoo containing GZ classifications for (I guess) all MaNGA galaxies. The classifications come from the Galaxy Zoo 2 database supplemented with some followup campaigns to fill in the gaps in GZ2. Besides greater completeness than the zoo2* database tables that can also be queried in CasJobs this table contains the newer vote fraction debiasing procedure described in Hart et al. (2016). It’s also much faster to query because it’s indexed on mangaid. When I put together the sample of MaNGA disk galaxies that I’ve posted about several times I took a somewhat indirect approach of looking for SDSS spectroscopic objects close to IFU centers and joining those with classifications in the zoo2MainSpecz table. The query I wrote took about 3 1/2 hours to execute, whereas the ones shown below required no more than a second.
Pasted below are the complete SQL queries, and below the fold are lists of the positions and plateifu IDs of the samples suitable for copying and pasting into the SDSS image list tool. These queries run in the DR16 “context” produced 287 and 272 hits respectively, with 285 unique galaxies in the barred sample and 263 uniques in the non-barred. These numbers are a little different than in the two papers referenced at the top. Fraser-McKelvie ended up with 245 galaxies in their barred sample — most of the difference appears to be due to me selecting from both the primary and secondary MaNGA samples, while they only used the “Primary+” sample (which presumably include the primary and “color enhanced” subsamples). I also did not make any exclusions based on the drp3qual value although I did record it. The total sample size of 548 galaxies is considerably smaller than the parent sample from Peterken, which was either 795 or 798 depending on which paper you consult. The main reason for that is probably that Peterken’s parent sample includes all bar classifications while I excluded galaxies with debiased f_bar levels > 0.2 in my bar-less sample. My barred fraction of around 52% is closer to guesstimates in the literature.
Both samples contain at least a few false positives, as is usual, but there are only one or two gross misclassifications. One that was especially obvious in the barred sample was this early type galaxy, which clearly has neither a bar or spiral structure and at least qualitatively has a brightness profile more characteristic of an elliptical. Oddly, the zoo2MainSpecZ entry for this object has a completely different set of classifications — the debiased vote fraction for “smooth” was 84%, so most volunteers agreed with me. This suggests maybe a misidentification in the mangaGalaxyZoo data.
Besides this really obvious case I found a few with apparent inner rings or lenses, and a few galaxies in both samples appear to me to be lenticulars with no clear spiral structure. The first of the two below again has a completely different set of classifications in zoo2MainSpecZ than in the MaNGA table.
Again, not a barred spiral.
Lenticular?
Although I didn’t venture to count them a fair number of galaxies in the non-barred sample do appear to have short and varyingly obvious bars. Of course the query didn’t exclude objects with some bar votes — presumably higher purity could be achieved by lowering the threshold for exclusion. And again, there are a few lenticulars in the spiral sample. As my sadly departed friend Jean Tate often commented the galaxy zoo decision tree doesn’t lend itself very well to identifying lenticulars.
IC 2227. Maybe a short bar?UGC 10381. Classified as S0/a in RC3
Unfortunately I have nothing useful to say about Fraser-Mckelvie’s main research topic, which was to decide if, and perhaps why, barred spirals have lower star formation rates than otherwise similar non-barred ones. 500+ galaxies are far more than I can analyze with my computing resources. Perhaps a really high purity sample would be manageable. I may post an individual example or two anyway. The MaNGA view of grand design spirals in particular can be quite striking.
select into gzbars
m.mangaid,
m.plateifu,
m.plate,
m.objra,
m.objdec,
m.ifura,
m.ifudec,
m.mngtarg1,
m.drp3qual,
m.nsa_z,
m.nsa_zdist,
m.nsa_elpetro_mass,
m.nsa_elpetro_phi,
m.nsa_elpetro_ba,
m.nsa_elpetro_th50_r,
m.nsa_sersic_n,
gz.survey,
gz.t01_smooth_or_features_count as count_features,
gz.t01_smooth_or_features_a02_features_or_disk_debiased as f_disk,
gz.t03_bar_count as count_bar,
gz.t03_bar_a06_bar_debiased as f_bar,
gz.t04_spiral_count as count_spiral,
gz.t04_spiral_a08_spiral_debiased as f_spiral,
gz.t06_odd_count as count_odd,
gz.t06_odd_a15_no_debiased as f_notodd
from mangaDrpAll m
join mangaGalaxyZoo gz on gz.mangaid = m.mangaid
where
m.mngtarg2=0 and
gz.t04_spiral_count >= 20 and
gz.t03_bar_count >= 20 and
gz.t01_smooth_or_features_a02_features_or_disk_debiased > 0.43 and
gz.t03_bar_a06_bar_debiased >= 0.5 and
gz.t04_spiral_a08_spiral_debiased > 0.8 and
gz.t06_odd_a15_no_debiased > 0.5 and
m.nsa_elpetro_ba >= 0.5 and
m.mngtarg1 >= 1024 and
m.mngtarg1 < 8192
order by m.plateifu
select into gzspirals
m.mangaid,
m.plateifu,
m.plate,
m.objra,
m.objdec,
m.ifura,
m.ifudec,
m.mngtarg1,
m.drp3qual,
m.nsa_z,
m.nsa_zdist,
m.nsa_elpetro_mass,
m.nsa_elpetro_phi,
m.nsa_elpetro_ba,
m.nsa_elpetro_th50_r,
m.nsa_sersic_n,
gz.survey,
gz.t01_smooth_or_features_count as count_features,
gz.t01_smooth_or_features_a02_features_or_disk_debiased as f_disk,
gz.t03_bar_count as count_bar,
gz.t03_bar_a06_bar_debiased as f_bar,
gz.t04_spiral_count as count_spiral,
gz.t04_spiral_a08_spiral_debiased as f_spiral,
gz.t06_odd_count as count_odd,
gz.t06_odd_a15_no_debiased as f_notodd
from mangaDrpAll m
join mangaGalaxyZoo gz on gz.mangaid = m.mangaid
where
m.mngtarg2=0 and
gz.t04_spiral_count >= 20 and
gz.t03_bar_count >= 20 and
gz.t01_smooth_or_features_a02_features_or_disk_debiased > 0.43 and
gz.t03_bar_a06_bar_debiased <= 0.2 and
gz.t04_spiral_a08_spiral_debiased > 0.8 and
gz.t06_odd_a15_no_debiased > 0.5 and
m.nsa_elpetro_ba >= 0.5 and
m.mngtarg1 >= 1024 and
m.mngtarg1 < 8192
order by m.plateifu
There was a bit of controversy that played out earlier this year on arxiv and the pages of MNRAS on a subject of interest to me, namely full spectrum modeling of (simulated) galaxy SEDs. It began with a paper by Ge et al. (arxiv article ID 1805.03972) comparing outputs of STARLIGHT and pPXF, two popular full spectrum fitting codes, on very simple one and two component synthetic spectra with varying ages, reddening, and S/N. They found significant biases in mass to light ratios and other derived quantities in STARLIGHT output in some cases — primarily ones with a young population and large reddening — that oddly got worse with increasing S/N, while pPXF generally had smaller biases that improved with increasing S/N. They also obtained poor fits to the data in the cases with the most biased outputs, and noted multiple order of magnitude differences in execution time.
Not surprisingly this was soon followed with a heated rebuttal by cid Fernandes, the primary author and maintainer of STARLIGHT. This was first posted on arxiv with the title “Rebutting fake news on full spectral fitting” (article ID 1807.10423). The published version with the more temperate title “On tests of full spectral fitting algorithms” appeared in the November 2018 MNRAS (and is apparently not paywalled, although Ge et al. is).
As I read it there were three main threads to the rebuttal:
A single, “hitherto deemed unimportant” line of code was responsible for the poor performance at large input reddening values. The offending line apparently limits the initialization of reddening values to what would normally be reasonable for realistic galaxy spectra.
But, even without modifying the code good results could have been achieved by modifying configuration files.
And anyway the worst performance was for an unrealistic edge case that wouldn’t be encountered in real work.
The one problem I have with this is that STARLIGHT is not open source at present, and without the source code the otherwise trivial issue isn’t easily discoverable, let alone fixable. As for the other points it should have been fairly obvious that getting poor results when the ingredients used to fit a data set are exactly the ones used to generate the data is a sure sign of convergence failure.
Actually though this post isn’t about these papers or directly about these two codes. It wasn’t clear to me why Ge et al. wrote the paper they did or why editors and referees considered it publishable in MNRAS — while fake data exercises are a necessary part of software validation there wasn’t any larger scientific purpose to their work. But I did like the idea of looking at an unrealistic edge case for reasons that I hope will become obvious. What I’m going to examine is even simpler: I construct a mock spectrum as a linear combination of two SSP model spectra from the EMILES library, perturb it with random noise, and fit it with a subset of EMILES using three different fitting methods. Neither convolution with a line of sight velocity distribution nor reddening is done, and these aren’t modeled in the fits. The fitting methods I use are
non-negative least squares using the R package nnls, which implements Lawson & Hanson’s 1974 algorithm. This is a crucial part of both my code for maximum likelihood estimation of star formation histories and pPXF, which uses the implementation (probably based on the same FORTRAN code) in scipy.optimize.
A Stan model that’s a simplified version of the one I use for Bayesian SFH modeling.
STARLIGHT uses a Monte Carlo based optimization scheme, and I thought it would be interesting to compare the methods I use regularly to a state of the art approach to Monte Carlo optimization. To that end I chose the “differential evolution” algorithm implemented in the package RcppDEoptim. I should emphasize at the outset that this is a very different algorithm than the one in STARLIGHT and none of the results I present here have any direct relevance to it.
I didn’t think it was worth the effort to version control this or create a Github project, but I did upload all code and data needed to reproduce the graphics in this post to my dropbox account. I don’t necessarily recommend running this because it’s quite time consuming, but if you want to try it just download the entire folder and after starting R set the working directory to toynn and type source("toynnscript.r", echo=TRUE). Then go away and come back in 12 hours or so.
Let’s look at the script. The first few lines load the libraries I need and set some options for rstan:
## libraries we'll need
require(rstan)
require(nnls)
require(RcppDE)
require(ggplot2)
require(bayesplot)
require(gridExtra)
source("toynnutils.r")
## set a few options
ncores <- min(parallel::detectCores(), 4)
options(mc.cores = ncores)
rstan_options(auto_write = TRUE)
set.seed(654321L)
Stan can run multiple chains in parallel on any multi-core architecture and defaults to 4 chains, so the line that starts with ncores <- will be used to tell Stan to use the smaller of the number of cores detected or 4. I set and reset the random number seed several times in this script for exact reproducibility. Next I set up the fake data:
## load emiles ssp library and extract parts we need
load("emiles.sub1.rda")
X <- as.matrix(emiles.sub1[, 110:163])
X <- scale(X, center=FALSE)
mstar <- mstar.emiles[109:162]
ages <- ages.emiles
lambda <- emiles.sub1[,1]
rm(emiles.sub1, mstar.emiles, ages.emiles, Z.emiles, gri.emiles)
nr <- nrow(X)
nv <- ncol(X)
beta_act <- numeric(nv)
beta_act[22] <- 0.3
beta_act[50] <- 1 - beta_act[22]
sdev <- 0.02
y_act <- as.vector(X %*% beta_act)
y <- y_act + rnorm(nr, sd=sdev)
dT <- diff(c(0, 10^(ages-9)))
stan_dat <- list(N=nr, M=nv, X=X, y=y, dT=dT, sdev=sdev)
The subset of the EMILES library provided here has 4 metallicity bins and 6000 wavelength points between about 3465 and 8864Å. I extract the solar metallicity model spectra, and although it’s overkill for this exercise I retain all 6000 wavelength points. The two nonzero components are 1 and 12Gyr old SSPs. I add IID gaussian random noise to the model spectrum with a standard deviation that will be treated as known. Real modern spectroscopic data always comes with an error estimate for each flux measurement, and these are typically treated as accurate in SED modeling.
The script runs the Stan model next, so let’s look at the Stan code:
There are just two lines in the model block: one to specify a prior and one for the likelihood. The prior was copied directly from my “real” Stan model for SFH modeling. It sets the scale parameter to be proportional to the width of the age bin each SSP model covers, and since the parameter values are proportional to the mass born in each age bin this will make a typical draw from the prior have a roughly constant star formation rate over cosmic history. Unfortunately I rescale the data in a different way for this exercise and the prior is doing something different, but no matter for now. Continuing with the script:
## in the stan call set open_progress to FALSE if using rstudio
## max_treedepth = 13 should make convergence warnings go away
## this will take a while...
system.time(stanfit <- stan(file="simplenn.stan", data=stan_dat, chains=4, iter=1000, warmup=500,
seed=54321L, cores=ncores,
open_progress=TRUE, control=list(max_treedepth=13)))
I set the number of warmup and total iterations to half the rstan defaults, which is plenty. Stan gets to stationary distributions for all parameters remarkably quickly. In the comments I optimistically guess that all convergence warnings will go away. Actually there was a warning that “17 transitions exceeded (sic) the maximum treedepth.” In this case the warnings don’t actually point to any convergence issues. BTW this took about 1 1/4 hours on a 2018 vintage PC built around Intel’s second most powerful consumer CPU as of late 2017.
In the paper that introduced pPXFCappellari and Ensellem (2004) had the important insight that non-negative least squares produces the maximum likelihood estimator for the stellar contributions in SED fitting (in astronomers’ parlance it minimizes χ2). Solving NNLS problems is important in a number of disciplines and many algorithms exist, several of which are implemented in various R packages. It turns out though that an old one published by Lawson and Hanson works pretty well for the type of data used in SED modeling. A remarkable feature of NNLS is that it tends to return sparse (or parsimonious as I put it in an earlier post) parameter estimates. In fact with real data I find that it always returns sparse solutions for the stellar components. Getting back to the script the last major computational efforts involve repeated calls to nnls and a smaller number of simulations using DEoptim (which is much slower):
## simulate lots of nnls fits
system.time(nnfits <- sim_nn(X, y_act, sdev=sdev, N=2000))
## nnls likes to produce sparse solutions, but not so sparse as the input in this case
qplot(nnfits$simdat$nnzero,geom='histogram',binwidth=1) +
geom_vline(xintercept=median(nnfits$simdat$nnzero)) +
xlab("# components")+ggtitle("# components in NNLS fits")
table(nnfits$simdat$nnzero)
## simulate not so many calls to DEoptim. This also takes a while...
system.time(defits <- sim_de(X, y_act, sdev=sdev, N=100))
x11()
qplot(defits$simdat$deltall,geom='histogram',bins=10) +
xlab(expression(paste(delta~"log likelihood"))) +
ggtitle("fractional difference in log likelihood between DE fit and NNLS")
The function sim_nn is in the file toynnutils.r. This just generates N randomly perturbed sets of the observation vector y, fits them using nnls, and returns some information about the fits (in Windows the CPU time estimates will be not very accurate):
sim_nn <- function(X, y_act, sdev=0.02, N=1000, seed=12345L) {
require(nnls)
set.seed(seed)
nnzero <- numeric(N)
ctime <- numeric(N)
ll <- numeric(N)
nr <- length(y_act)
nv <- ncol(X)
B <- matrix(0, N, nv)
res <- matrix(0, N, nr)
for (i in 1:N) {
y <- y_act + rnorm(nr, sd=sdev)
ctime[i] <- system.time(nnsol <- nnls(X,y))[1]
B[i,] <- nnsol$x
nnzero[i] <- nnsol$nsetp
ll[i] <- sum(dnorm(residuals(nnsol), sd=sdev, log=TRUE))
res[i, ] <- residuals(nnsol)/sdev
}
list(simdat=data.frame(ctime=ctime, nnzero=nnzero, ll=ll), B_nn=B, res_nn=res)
}
The first ggplot2 call in the script produces this histogram of the number of non-negative components of the nnls fits. As expected and consistent with typical real data nnls always returns sparse fits, although almost never quite so sparse as the input. The call to table() returns
Number of nonzero parameter estimates in NNLS fits
Perhaps the most interesting result of these simulations are the distributions of parameter estimates — these show 50 (thick lines) and 90% (thin lines) intervals, with median values marked by symbols:
Parameter estimates from different fitting methods: (L) posterior distribution from Stan (M) NNLS (R) DEoptim
What’s most striking to me at least is how different the posterior marginal distributions from Stan (left panel) are from the maximum likelihood fits (middle). Star formation is much more extended in time in the Stan model, with both “bursts” replaced with broad ramps up and decays. The Monte Carlo optimization results look superficially similar to the Stan posterior, but as I’ll show soon there are different causes for their behavior.
Let’s take a closer look at the distributions of some of the parameter values. This is called a pairs, or sometimes corner, plot — it displays the marginal distribution of each selected parameter along the diagonal and fills out the remaining rows and columns with the joint distributions of pairs of parameters. For this plot I just selected the two non-zero inputs and the surrounding age bins. The top rows are the Stan posterior, the bottom the nnls fits from the 2000 sample simulation.
Pairs plot for selected parameters: (T) Posterior draws from Stan model (B) NNLS estimates
In frequentist statistics a confidence interval is a statement about the behavior of the estimator for a parameter under repeated experiments with the same conditions. It’s not a statement about the parameter itself, which is forever unknowable. A Bayesian confidence interval (to the fussy, credible interval) on the other hand is a statement about the parameter itself.
I’m unaware of any formula for confidence intervals of nnls coefficient estimates, but the simulation we performed gives good numerical estimates of the distribution of parameter values, and these are clearly significantly different from the posterior distributions from Stan. So, not only is there a difference in interpretation between frequentist and Bayesian confidence intervals in this case the values obtained are significantly different as well.
Mass growth histories have become a popular tool for visualizing SFH models, so for fun I created mock histories for the three methods tested here. These show medians and 95% confidence bands. The input MGH just falls within the 95% confidence band of the nnls fits, although the median has more extended mass growth.
Model “mass growth histories” from simple two component input
Turning next to fits to the data let’s look first at the overall fits measured by summed log-likelihood. Remember that the nnls solution is the maximum likelihood estimator and therefore neither of the other fitting methods can exceed its log-likelihood for any given realization of the data.
Here’s the posterior log-likelihood from the Stan model run. The vertical line to the right is for the nnls fit. The Stan fit average falls short of the maximum likelihood by about 0.1%. We’ll examine why in more detail next post.
log likelihood of posterior fits
I only ran 100 simulations of the “differential evolution” optimizer because it takes rather a long time (average ~450 sec. per data realization on my PC). The output log-likelihood consistently falls about 1% short of the nnls solution:
fractional δ log likelihood between DEoptim and NNLS fits for 100 data realizations
This shows the progress of the optimizer for a single data realization. Progress is rapid at first, but it slows down as it gets close to the optimum and can stall out for many iterations. This algorithm has a hard time getting to a sparse solution.
Progress of DEoptim fits (difference in log likelihood with NNLS fit)
Next let’s look at detailed fits to the data. The top pane shows the unperturbed spectrum (black points) and a 95% confidence band for the posterior predictive fit (green ribbon) from the Stan model. What’s that? Simple: take parameter draws from the posterior and generate new data according to the model. This is done with the following lines in the generated quantities block of the Stan code:
It turns out that the 95% confidence band covers 100% of the true, unperturbed, spectral values and 95% of the perturbed ones, which indicates a successful model.
The remaining panes show several sets of normalized residuals. The first surprised me a bit at first: this shows the residuals (observed – model) of the Stan model posterior. The “points” in this plot are actually error bars — it turns out the range of residuals at any wavelength is rather small (I naively expected that residuals at each point would vary randomly around 0). The residuals from the posterior predictive fits shown in the next panel do show this behavior. This and the remaining panels display median values as points and 95% confidence bands.
The 4th pane shows the errors in the posterior predictive fits, that is the original unperturbed data minus the posterior predictive values. There are hints of systematics here: a bit of curvature at the red and blue ends of the spectrum and a few absorption lines are slightly misfit.
The final two are residuals from the simulated nnls and Monte Carlo optimization fits. The nnls fits have exactly the expected statistical behavior while the latter clearly struggles to fit the data. This is because the overly extended star formation histories reached in the number of iterations allotted result in stellar temperature distributions that aren’t quite right, affecting both the continuum and many absorption features.
Fits to data: T) input spectrum and posterior predictive fit from Stan model 2) Residuals from Stan model posterior 3) Residuals from posterior predictive fits 4) Errors from posterior predictive fits 5) Residuals from NNLS fits 6) Residuals from DEoptim fits
Finally, here is a comparison of the distribution of the residuals in the Stan fit to the same data realization fit by nnls, the colored bands being the former. These show kernel smoothed density estimates on the left and empirical CDF on the right.
Comparison of distribution of residuals in Stan model fit with nnls fit
It’s sometimes suggested in the SFH modeling literature to get parameter uncertainty estimates by randomly perturbing data and refitting it. This is a computationally viable strategy with a competent non-negative least squares solver, but as we saw above this is likely to produce very different estimates than a proper Bayesian analysis.
A paper showed up on arxiv in early August titled “An early-type galaxy with an inner star-forming disk” by Li et al. (article id 1808.01730) that describes a system observed by MaNGA that’s rather similar to the one I have been writing about in recent posts, namely an apparent post-merger ETG with ongoing star formation. The paper is a little light on details, but it’s refreshingly short and not technically demanding. Unfortunately their discovery claim is incorrect: this galaxy was identified as a star forming elliptical in Helmboldt (2007), who also measured its HI mass to be 5.4±0.5 × \(10^8 \mathsf{M}_{\odot}\), about 5% of its baryonic mass.
Of course I did my own analysis which I’ll summarize in this post, also filling in some details missing from the paper. The first step in my analysis is to compute a velocity field (actually what I compute are redshift offsets, but these are easily converted to line of sight velocities). One of the first things I noticed is that while this is qualitatively similar to the one published by Li et al. (and shown twice!), the rotating inner component has nearly 3 times the maximum rotation velocity as their stellar velocity map.
Velocity field estimated from RSS data
So, naturally concerned that there was an error in my processing of the RSS data I downloaded the data cube and ran my code on that, getting the velocity field shown below on the left, which is evidently nearly identical.
Recall that my redshift offset measurement routine does template matching very similar to the SDSS spectro pipeline, using for templates a set of eigenspectra from a principal components analysis of a largish set of SDSS single fiber spectra from a high galactic latitude sample. These naturally encode information about both emission and absorption lines, with the code returning a single blended estimate. This works fine when ionized gas and stars are kinematically tightly coupled, but not so well when they’re not. Suspecting that emission lines were dominating the velocity estimates in the inner regions, as something of a one-off experiment I masked the area around emission lines in the galaxy spectra and reran the routine, getting the velocity field on the right.
Now this agrees in some detail with the stellar velocity field published by Li et al. (visual differences are mostly due to different color palettes). So an interesting first result is that not only is there a rotating, kinematically decoupled core but the stars and ionized gas within the core are decoupled from each other. This would seem to point to a recent injection of fresh cold gas.
Unfortunately they only published the stellar velocity field even though the official data analysis pipeline calculates separate ones for stars and gas, so I won’t be able to verify this result until value added kinematic data is made available.
(L) Velocity field estimated for data cube
(R) Stellar velocity field
For reference here is the spectrum from the central fiber. Wavelengths are vacuum rest frame and fluxes are corrected for foreground galactic extinction.
Central fiber spectrum, plateifu 8335-6101
As with the previous galaxy I did two sets of star formation history models. The first set a low S/N threshold for binning spectra and used an 81 SSP model subset of EMILES for fitting. For the second run I bin to a considerably higher target S/N and fit with the larger 216 SSP model set with the full BaSTI time resolution. The second data set has 25 coadded spectra with mean S/N per pixel ranging from 18-60.
For a quick comparison of the two sets of runs here are model mass growth histories summed over all spectra. Both indicate that a very substantial burst of star formation occurred beginning ~1.25Gyr ago (curiously, this is the same time as the initial burst in the galaxy KUG 0859+406 that I previously wrote about — part 1, part 2, part3). The present day stellar mass is just under \(1 times 10^{10} mathsf{M}_{odot}\), in agreement with the value cited by Li et al.
Summed model mass growth histories, emiles subset and “full” emiles
I find that ongoing star formation is largely confined to the KDC, in agreement with Li et al., so after running the models for the 25 bins I partitioned them into a core set and an outer set, with the core set comprising the bins within about 4×2″ (1.5 x 0.75 kpc semi-major and semi-minor axes) of the nucleus as shown below.
Stellar mass density for binned data, showing outlines of bins and core region
The summed star formation history models are shown below. As with my previous subject there was a galaxy wide burst of star formation ~1Gyr ago, but unlike it star formation declined monotonically after that, with no more recent secondary burst. The ongoing star formation in the central region is seen to be a relatively recent (last ~100Myr) uptick. This leads me to a slightly different interpretation of the data — the authors suggest that we are seeing the late stages of a gas rich major merger. I would say rather that the merger was completed ~1Gyr ago and that gas has recently been recaptured. This is consistent with simulations that show in the absence of AGN feedback star formation can proceed for some time after a merger. It’s also consistent with the observed reservoir of neutral hydrogen, which is sufficient to fuel star formation at the current level for another ~1Gyr.
(L) Model Star formation history, inner core
(R) Star formation history, outside core
Here are some additional results of the analysis of the 25 binned spectra. All of these agree with Li et al. where comparable results are displayed.
First, the Hδ absorption line index vs. 4000Å break strength index Dn(4000):
Lick HδA vs. Dn(4000)
Contour lines are my measurements of a sample of ~20K single fiber SDSS spectra. As with many quantities there is a distinct bimodality in this distribution, with star forming galaxies at upper left and passively evolving, mostly early type galaxies at bottom right. If star formation were to stop today there would be no K+A phase in this galaxy. A 1Gyr population has already passed its peak Balmer line strength, so if there was a K+A phase it was in the past.
Turning to emission lines, here are the 3 BPT diagnostic diagrams that are most commonly used with SDSS spectra. The curved lines are the starforming/something else demarcation lines of Kewley et al. 2006. In spatially resolved spectroscopy these lines seem not so useful. I find, in agreement with Li et al., that many of the spectra have “composite” line ratios, but except for the central fiber these are mostly near the edge or outside the KDC. The bottom right panel below shows the trend with radius of the [S II]/Hα line ratio (the other two show similar but weaker trends). This trend is the opposite of what we’d expect if an AGN were the ionizing source. Shocks or hot evolved stars are more likely.
Emission line diagnostic (BPT) plots
TL: [N II]/Hα vs [O III]/Hβ
TR: [O I]6300/Hα
BL: [S II]/Hα
BR: trend of [S II]/Hα with radius
I estimate a 100Myr average star formation rate from the SFH models. The log of the star formation rate density (in \(\mathsf{M}_{\odot}/\mathsf{yr/kpc}^2\)) is plotted against log stellar mass density (in \(\mathsf{M}_{\odot}/\mathsf{kpc}^2\)) below (the line is the estimate of the SF main sequence of Renzini and Peng 2015). Again in agreement with Li et al. the areas of highest SFR lie near the SF main sequence, while the outskirts of the IFU footprint fall below it. log SFR density vs. log stellar mass density
The radial trend of star formation rate is shown below on the left. On the right is my estimate of SFR density plotted against Hα luminosity density along with the calibration of Moustakis et al. Hα is corrected for attenuation using the Balmer decrement.
(L) log SFR density vs. radius
(R) log SFR density vs. attenuation corrected log Hα luminosity density
By the way my models directly estimate dust attenuation of the stellar light, typically assuming a Calzetti attenuation curve. A comparison with attenuation estimated with the Balmer decrement is shown below. To anyone familiar with SDSS spectra it’s not too surprising that estimates from the Balmer decrement have a huge amount of scatter due mostly to the fact that Hβ emission line strength is often poorly constrained. Despite that there is a clear positive correlation between these two estimates. I will probably examine this relationship in more detail in a future post, perhaps based on more favorable data.
τV estimated from Balmer decrement vs SFH model estimates
Finally, trend with radius of the metallicity 12+log(O/H) estimated with the strong line O3N2 method. As with the post merger galaxy in the previous posts there is a hint of a weak negative gradient. Overall the gas phase metallicity is around solar or just a little below. This is somewhat lower than my other post merger example, which is not unexpected given an approximately factor of 4 difference in stellar masses.
Metallicity 12+log(O/H) vs radius, estimated by O3N2 index

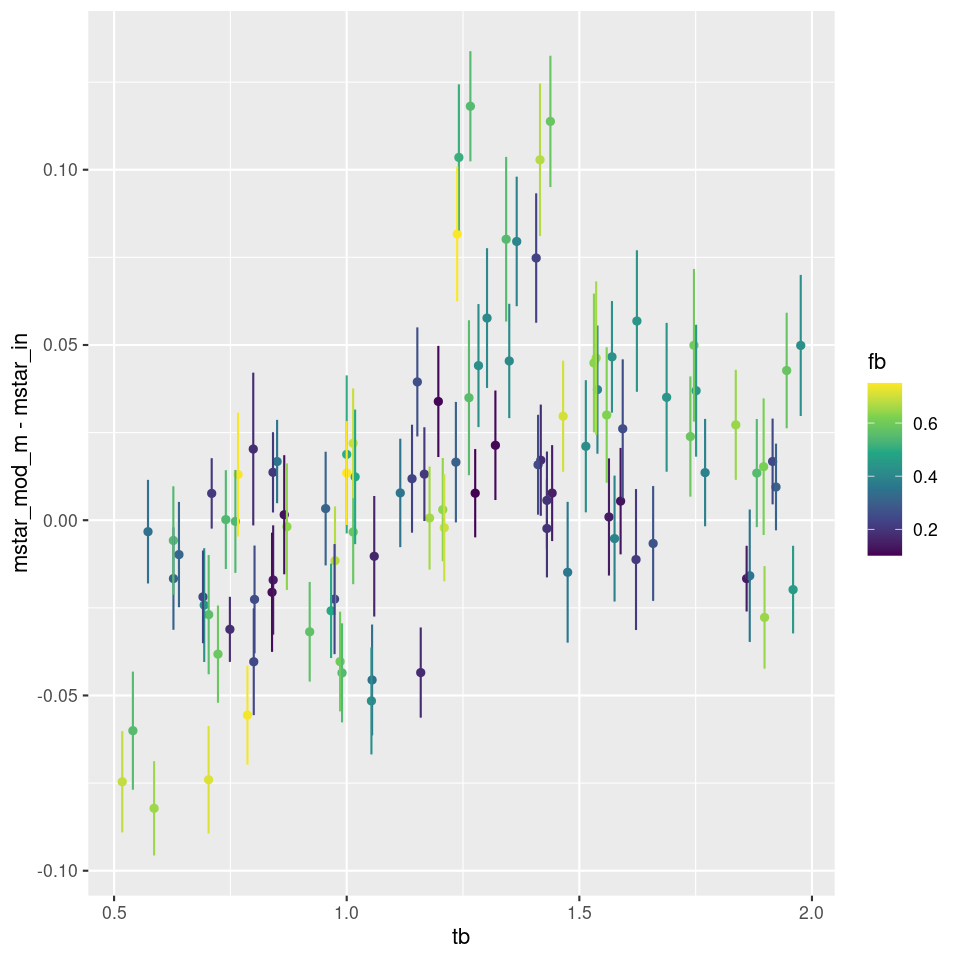
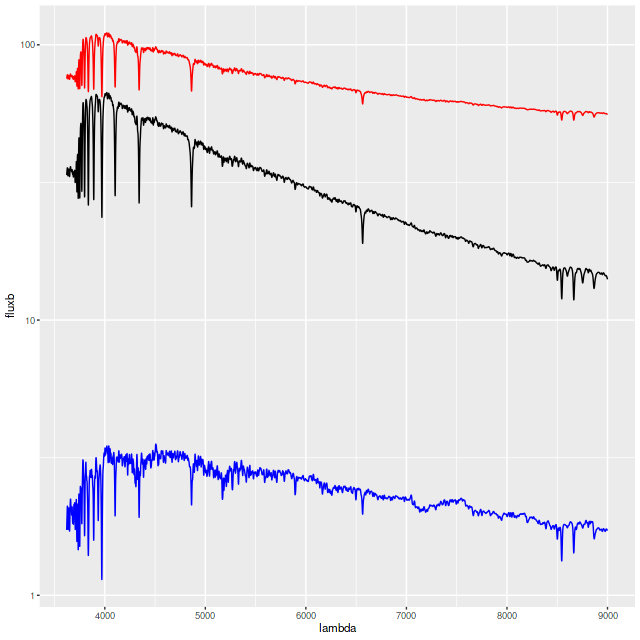
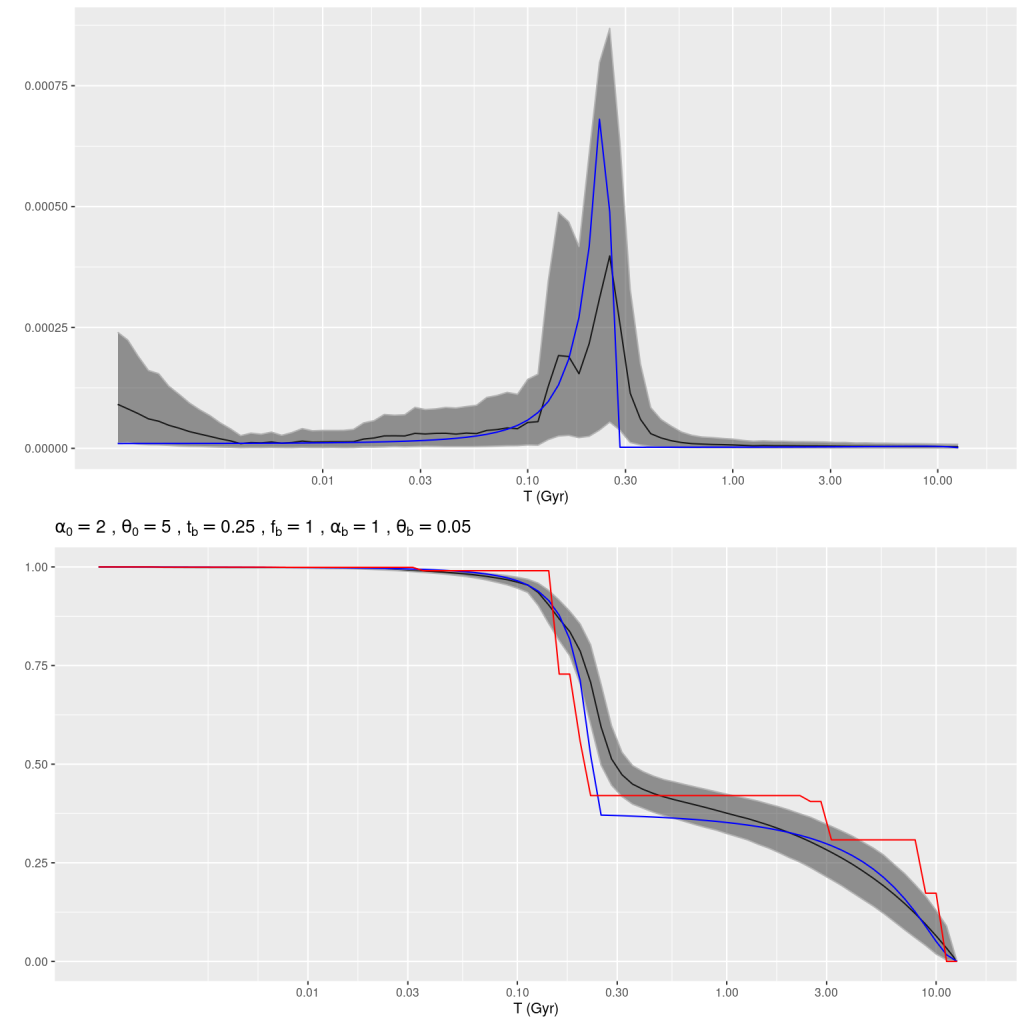
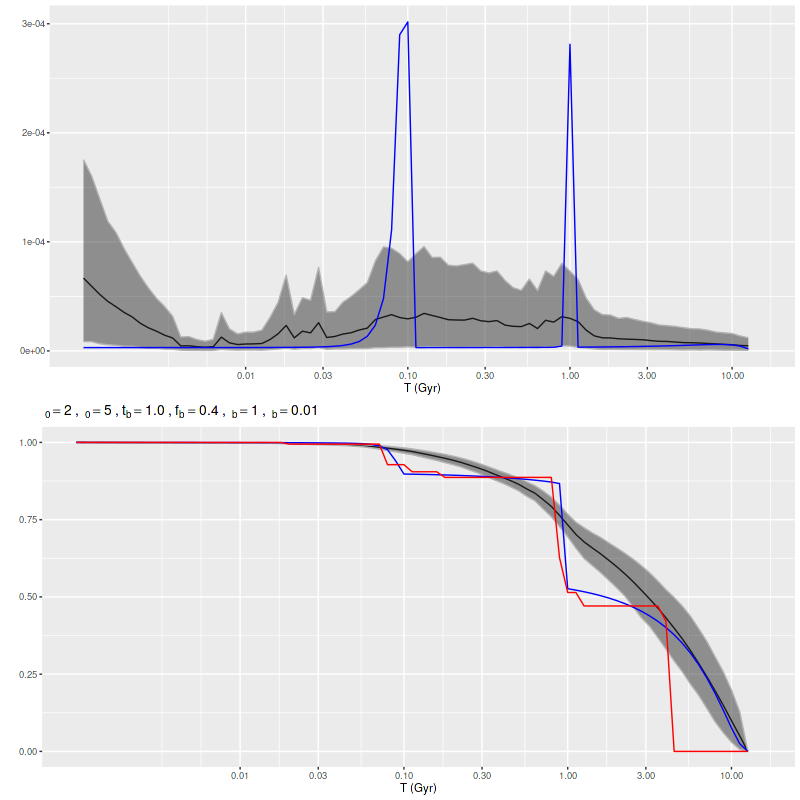
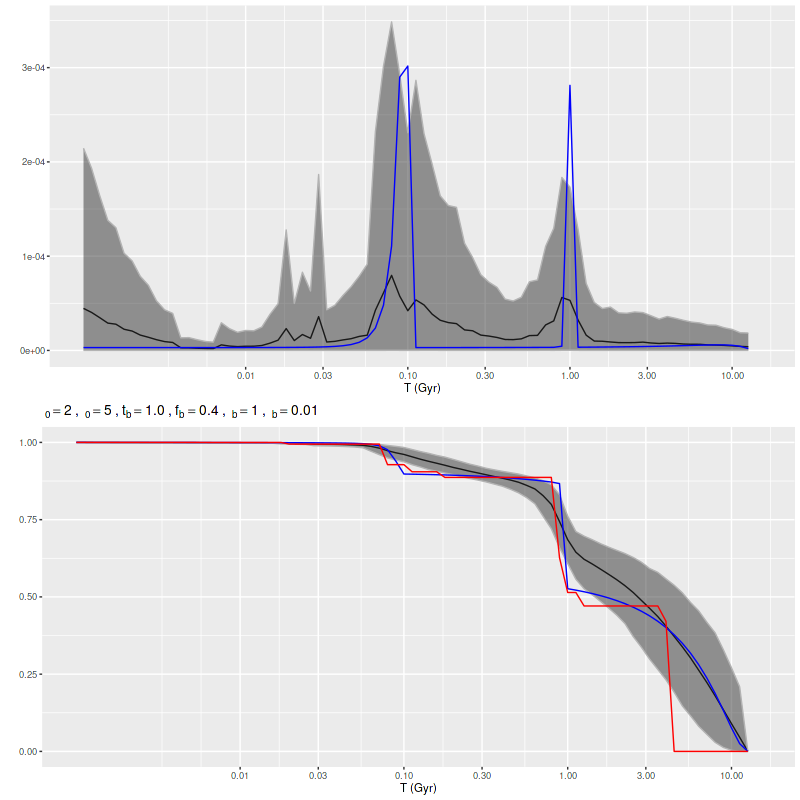
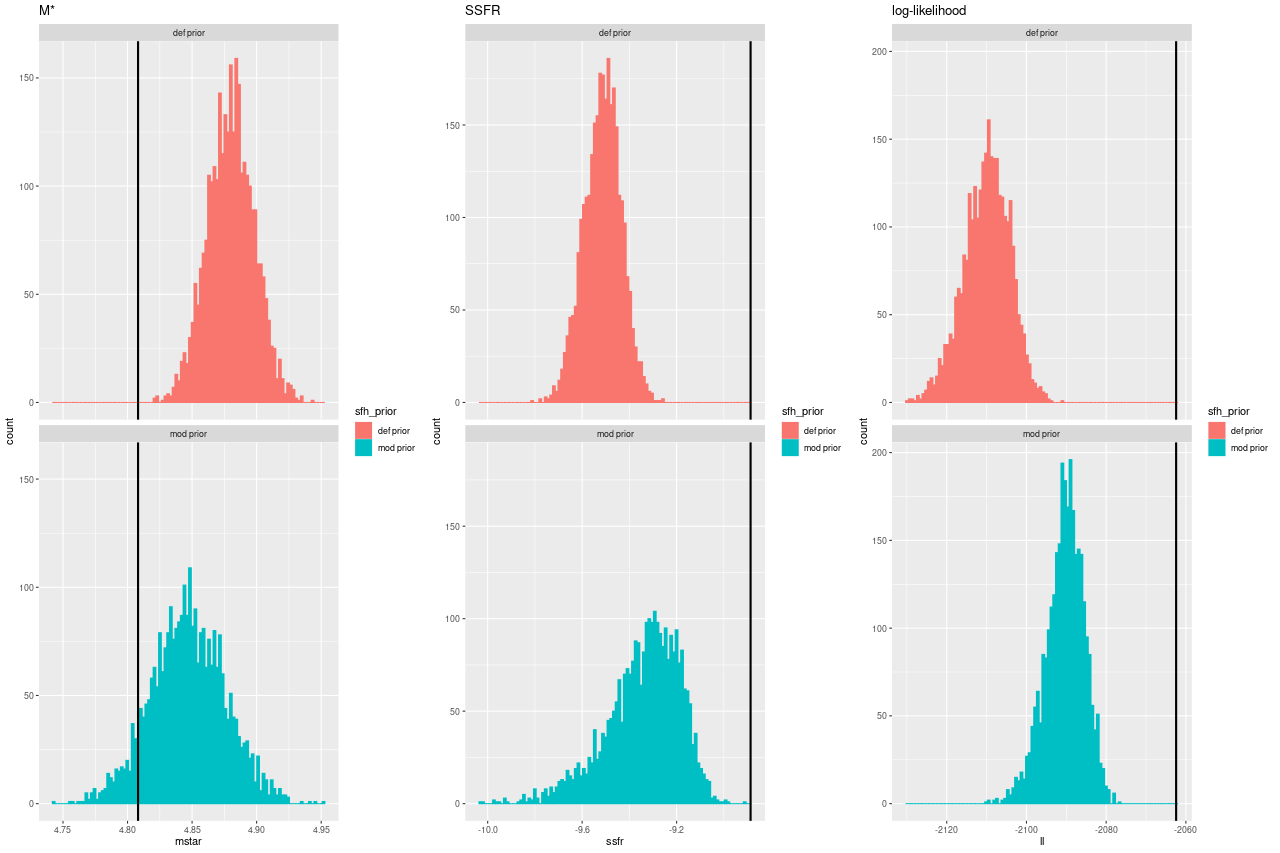
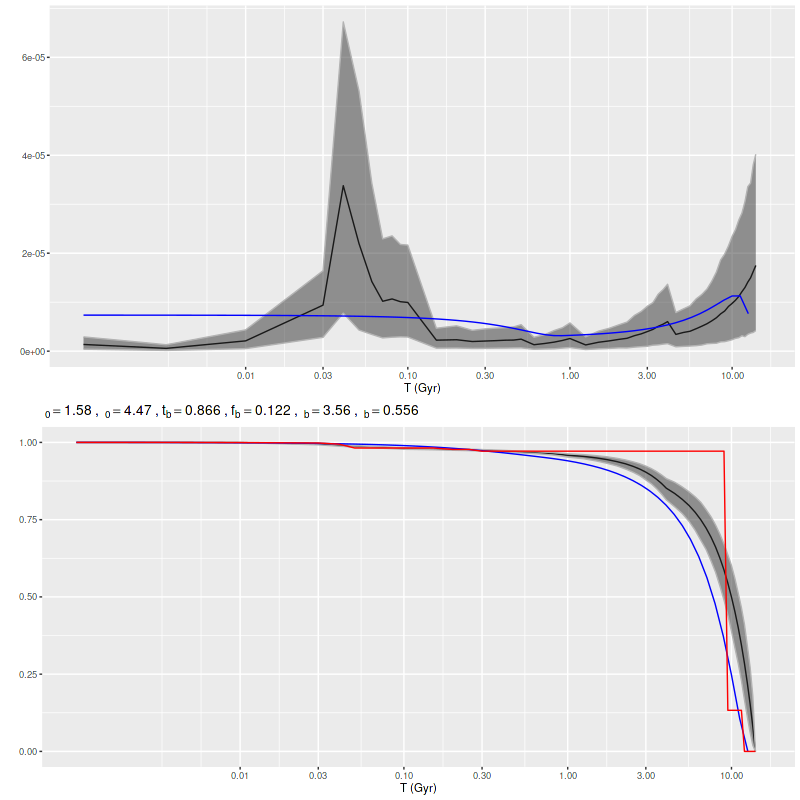
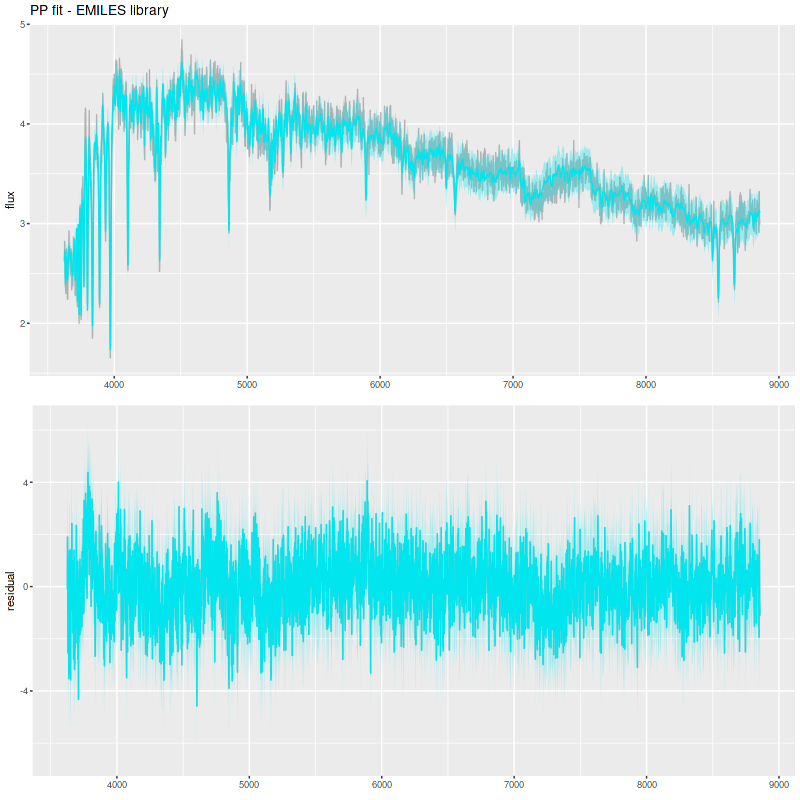
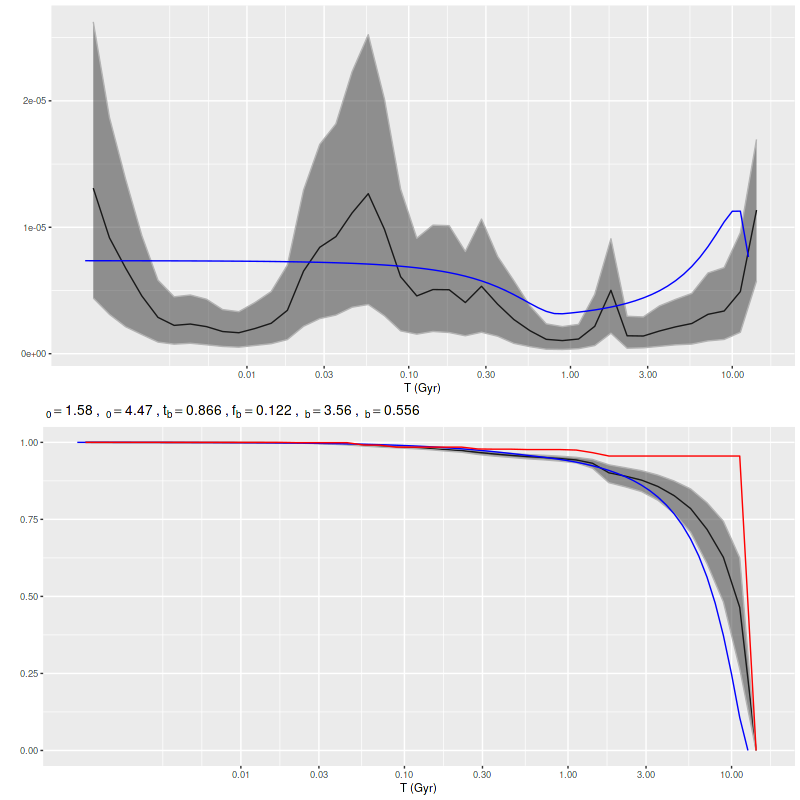
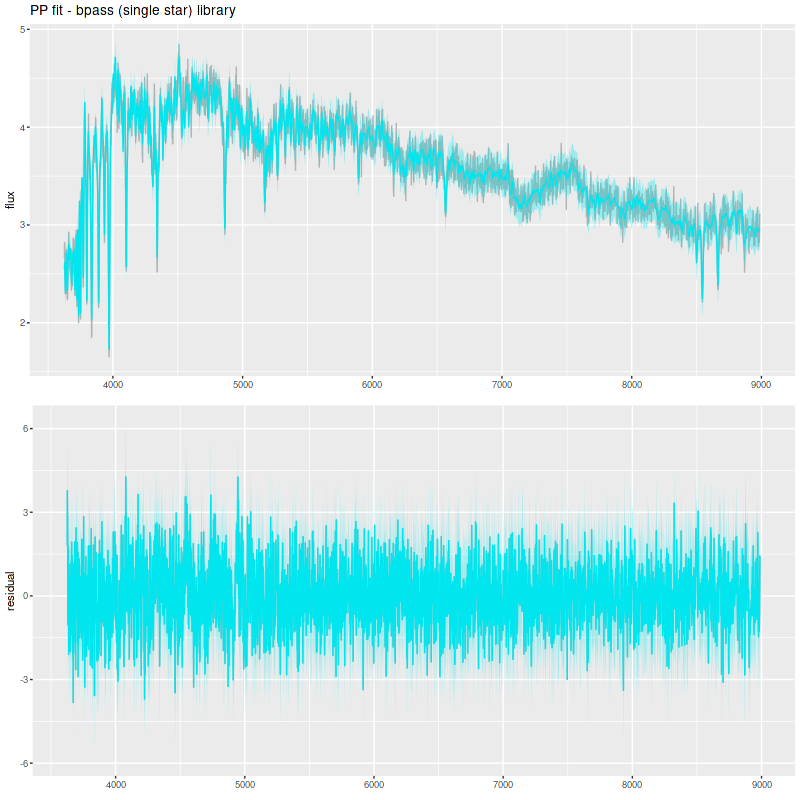
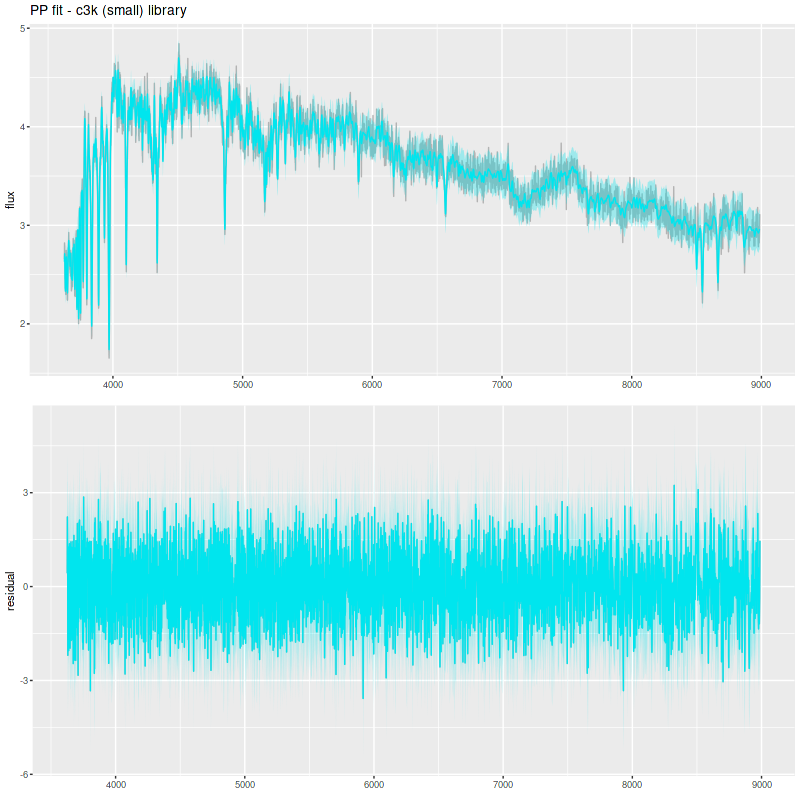
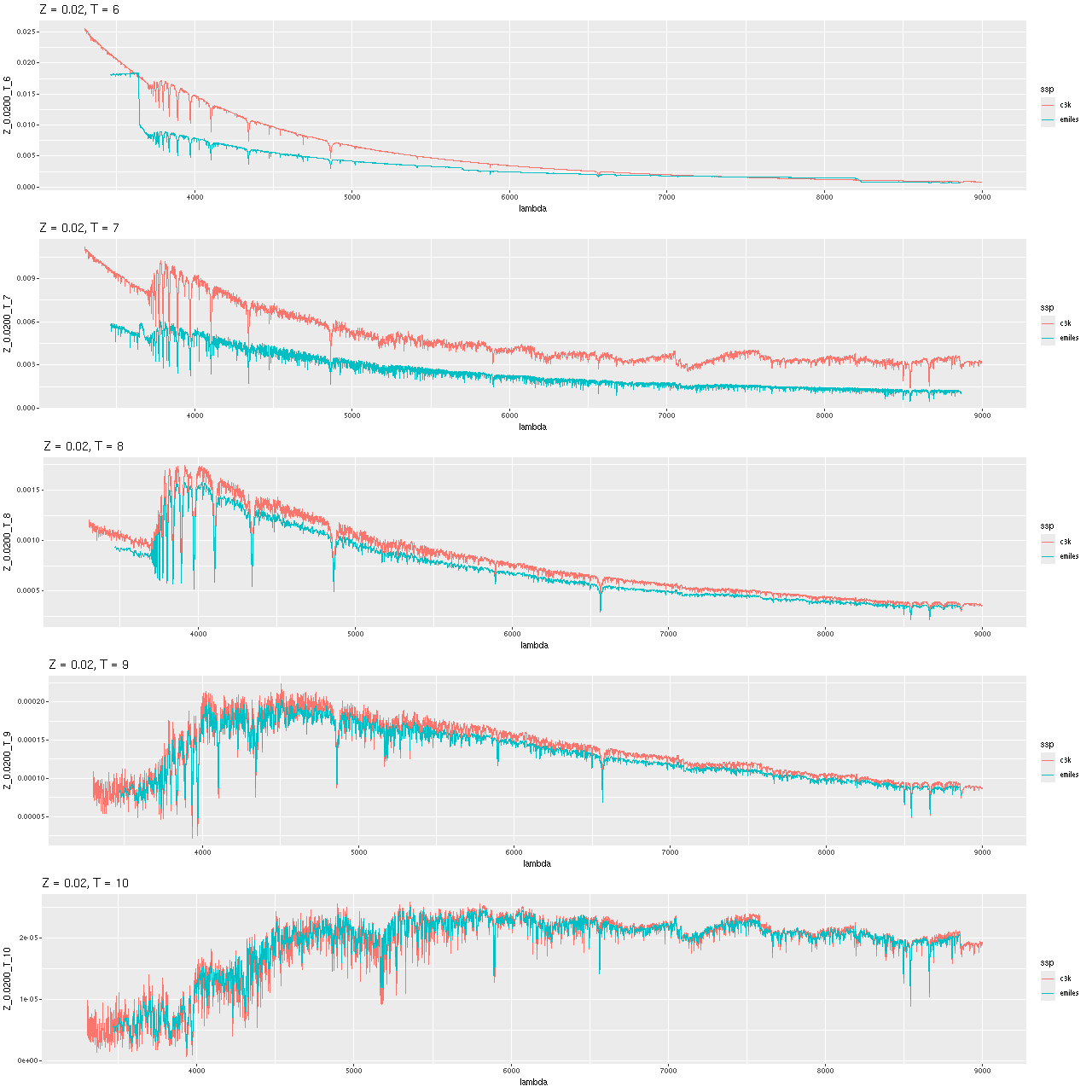
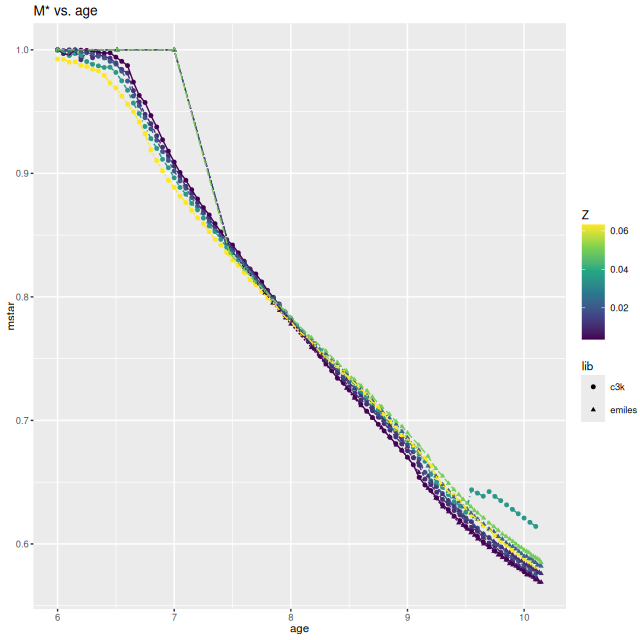
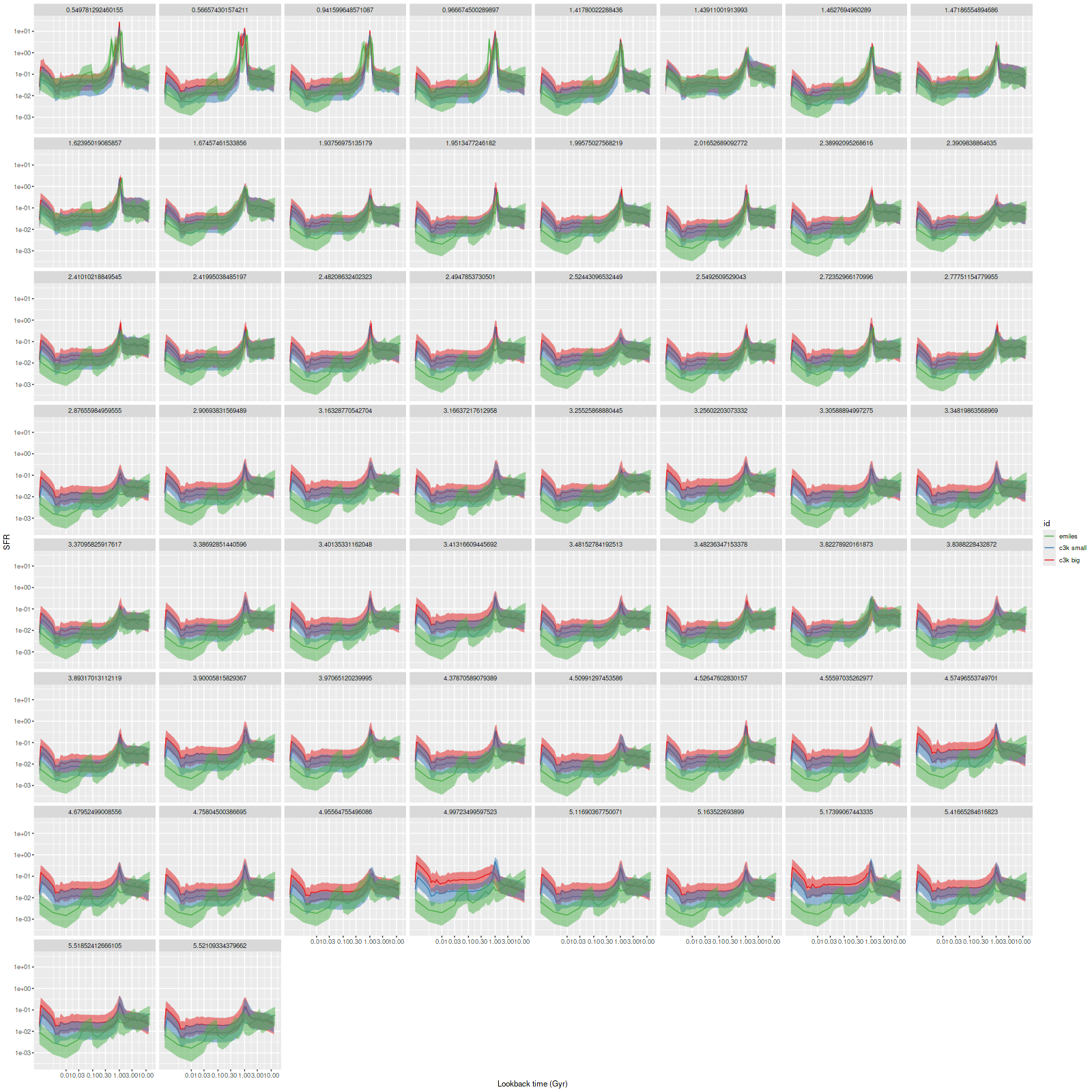

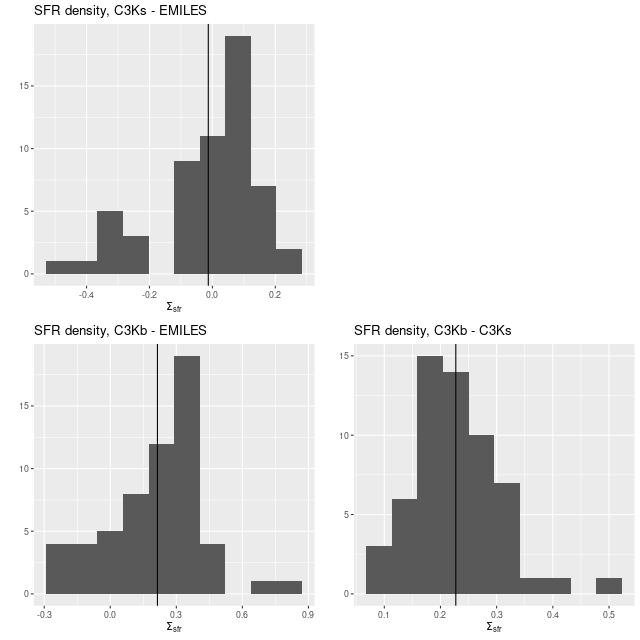
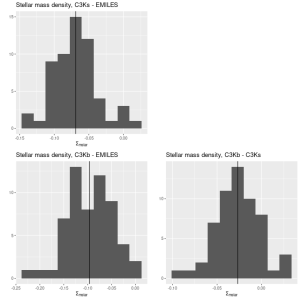
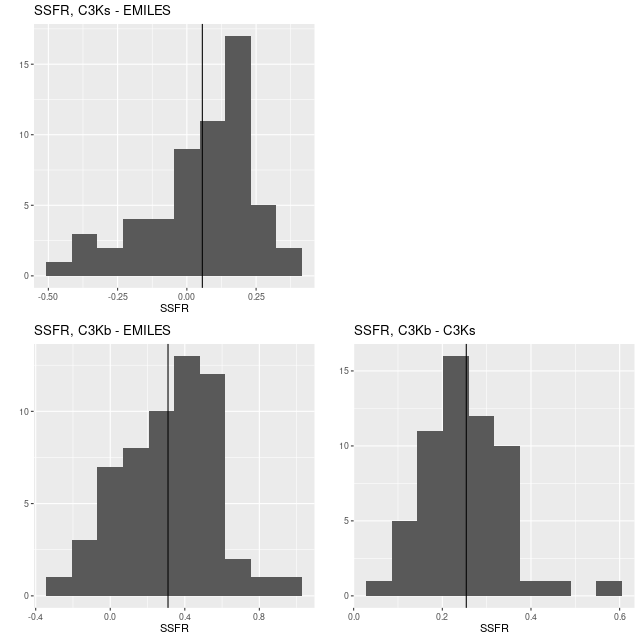
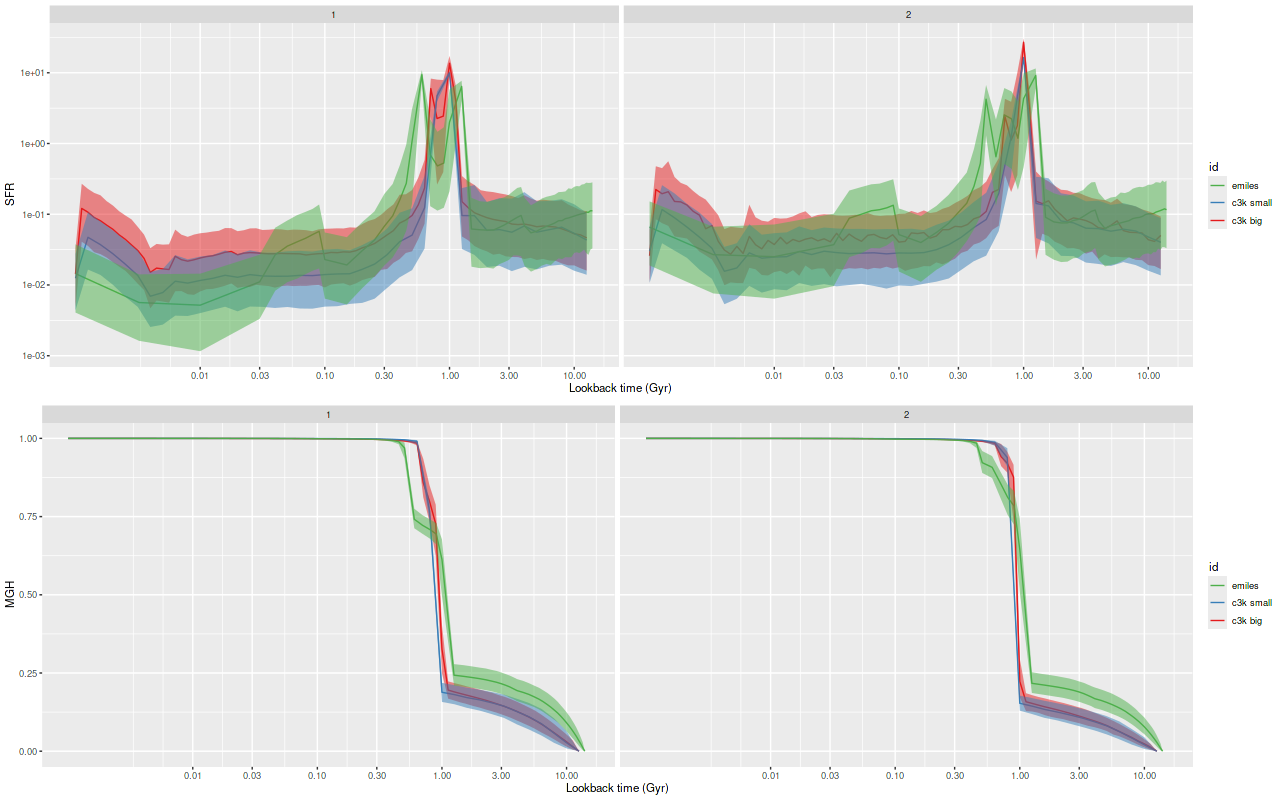
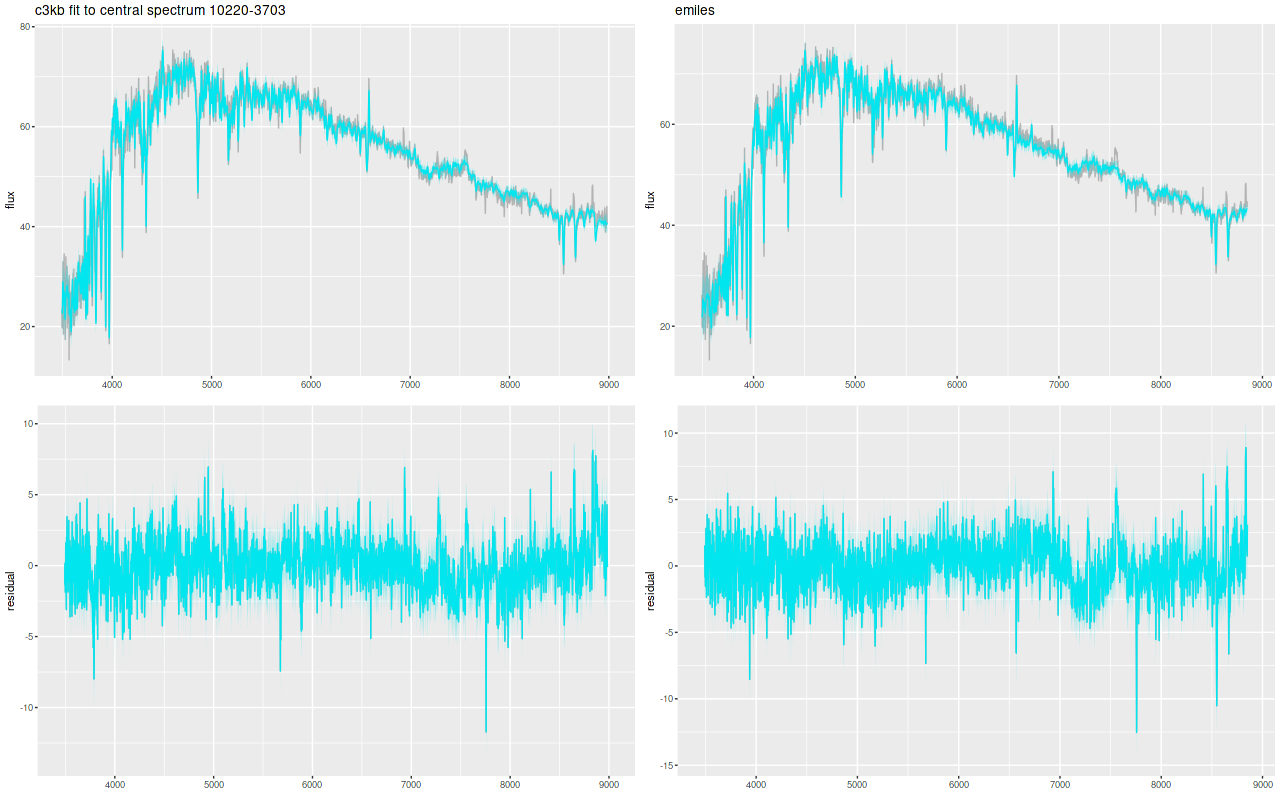
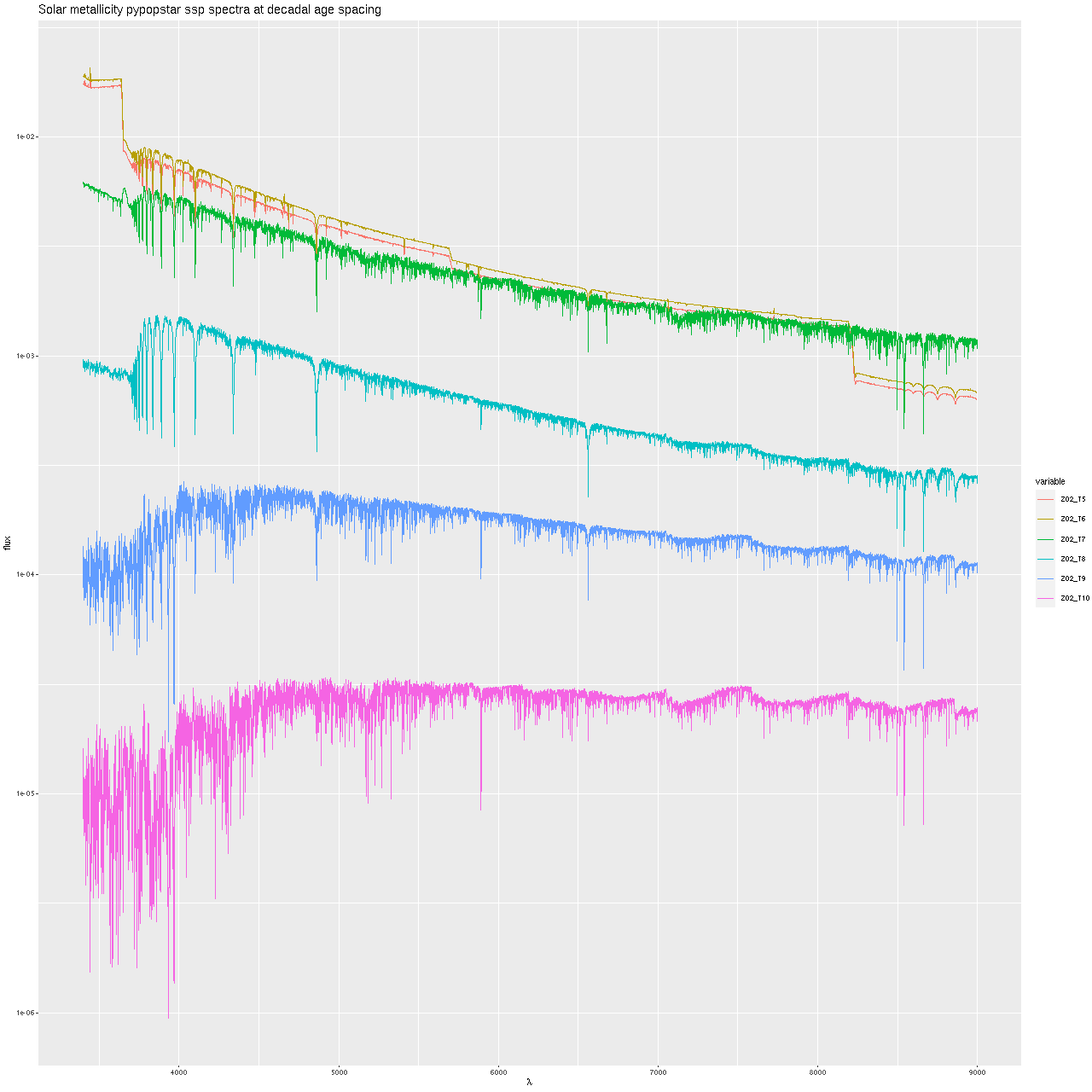
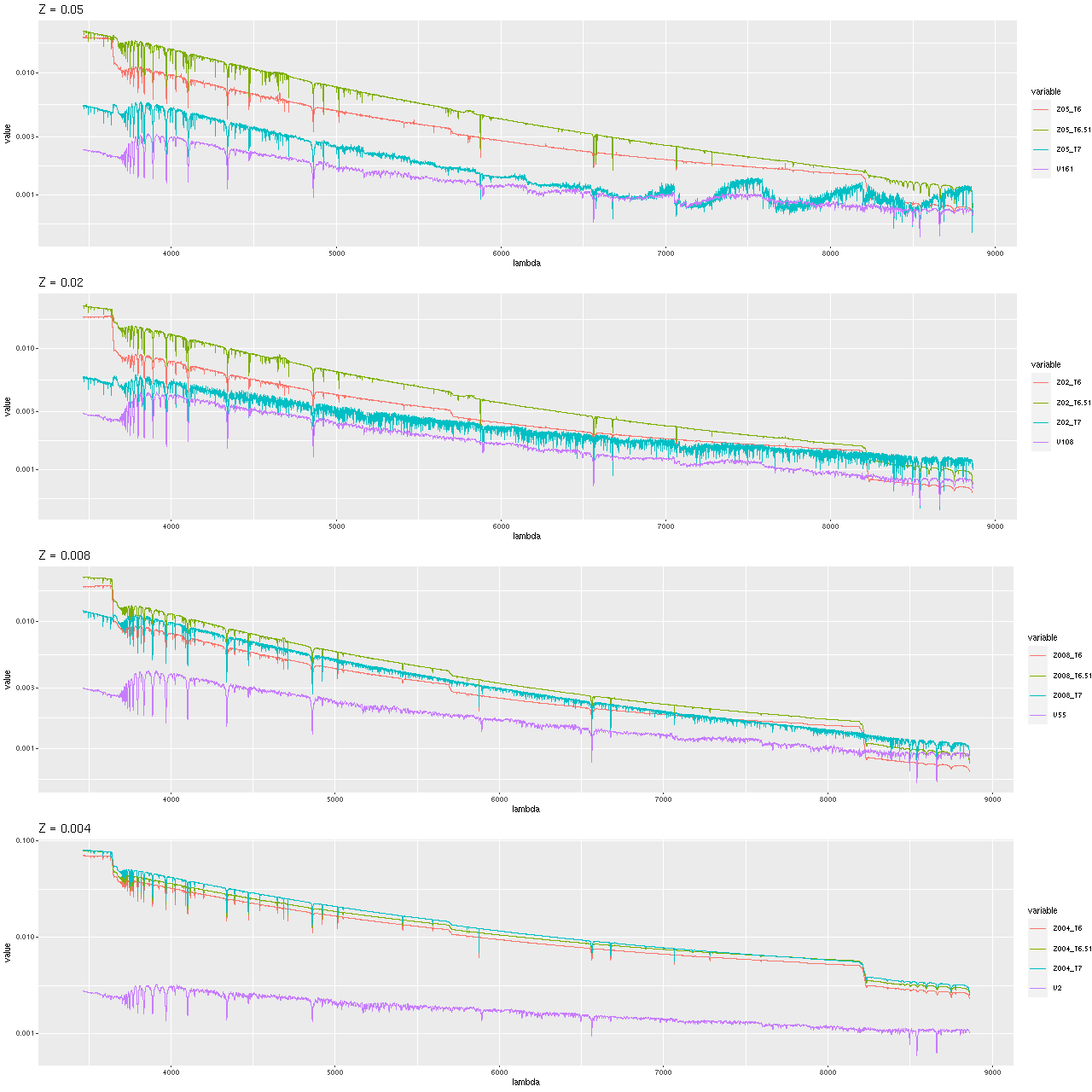


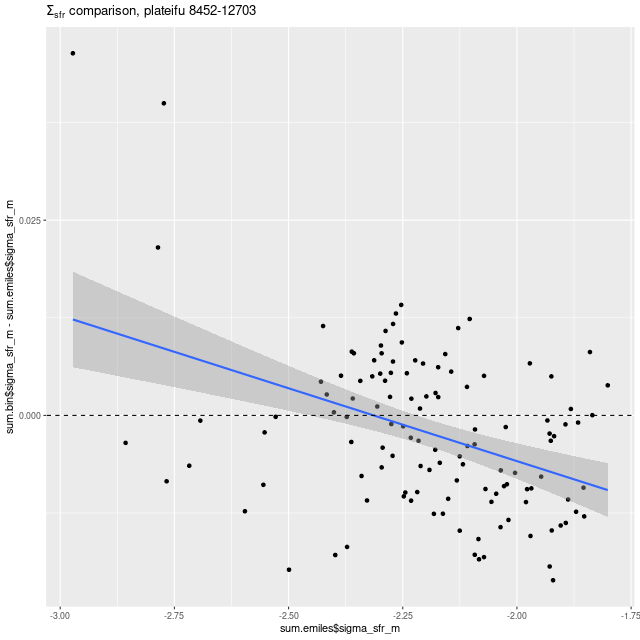
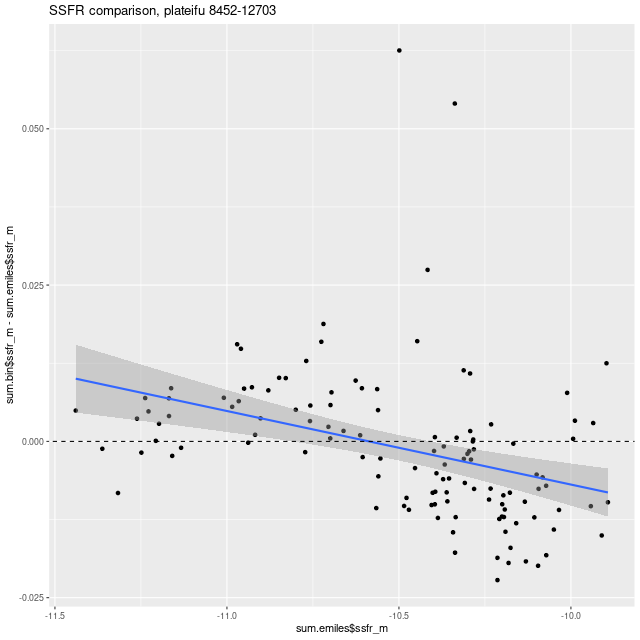
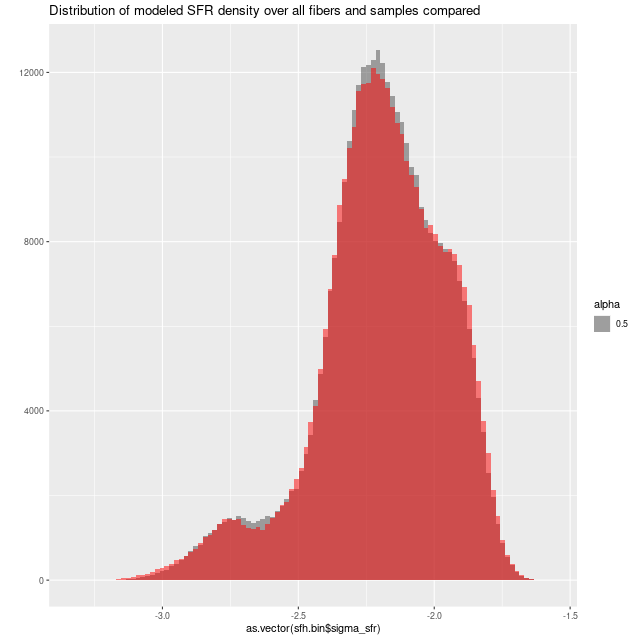

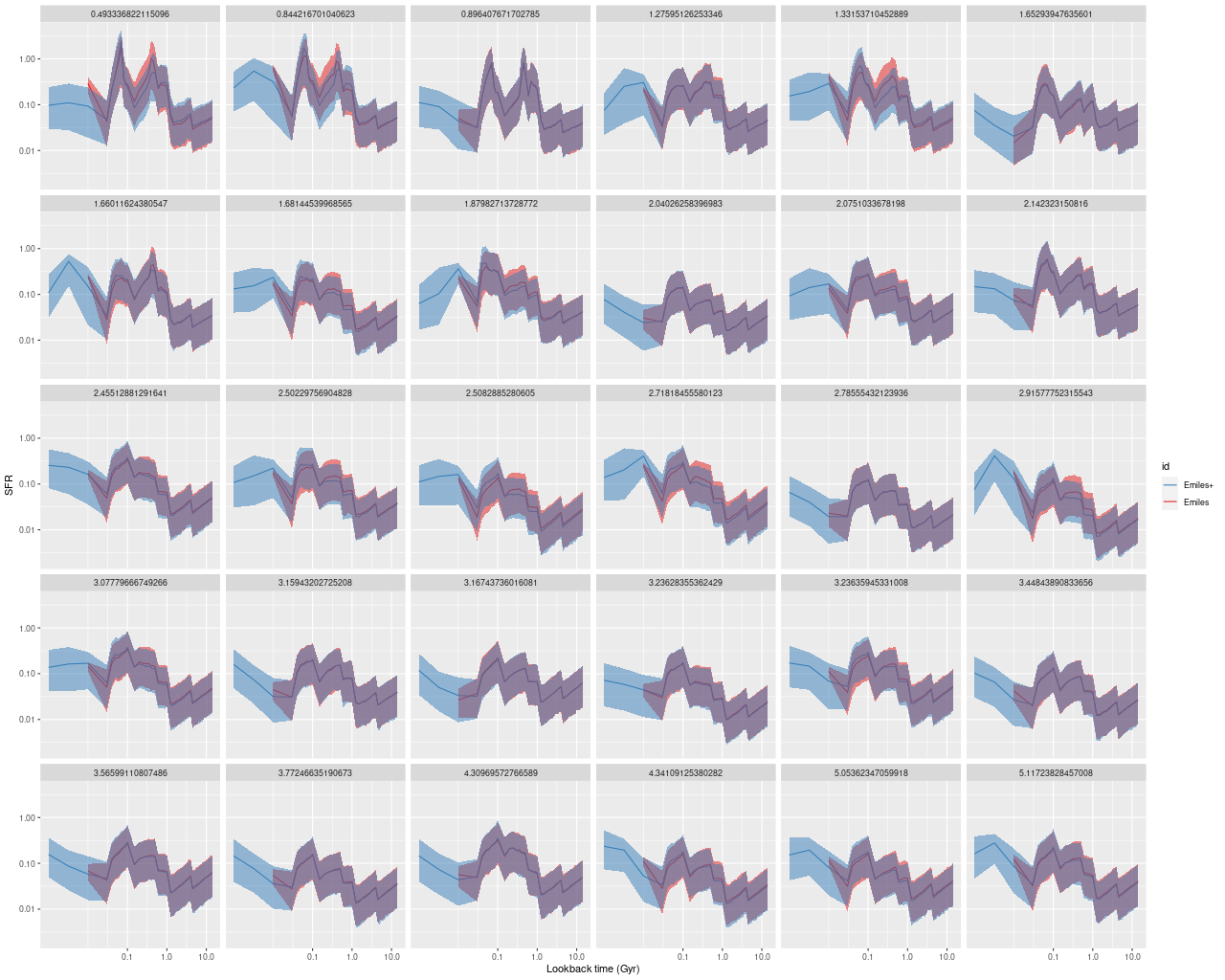


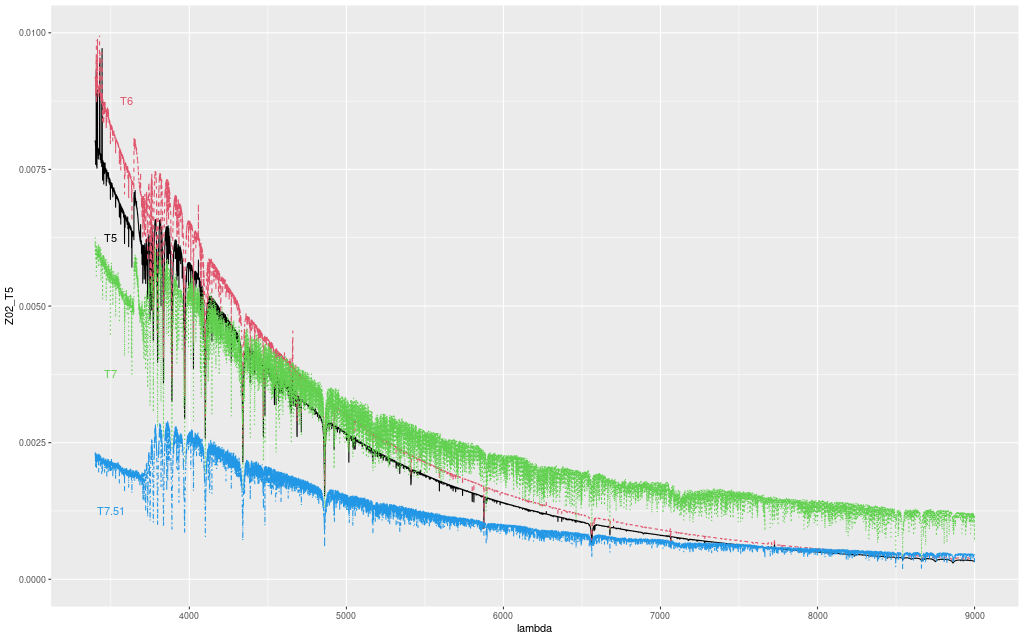
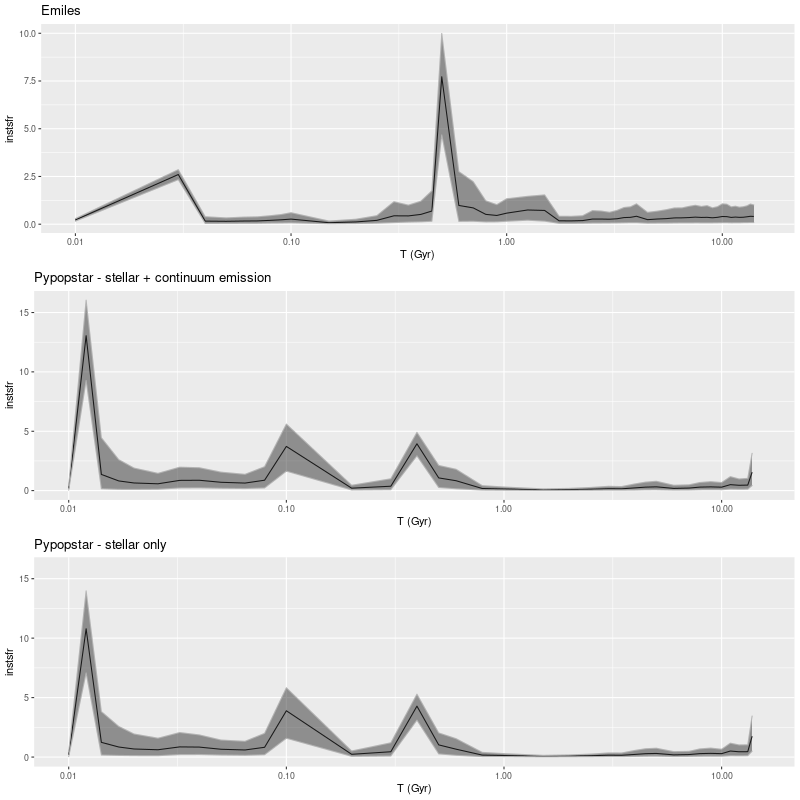
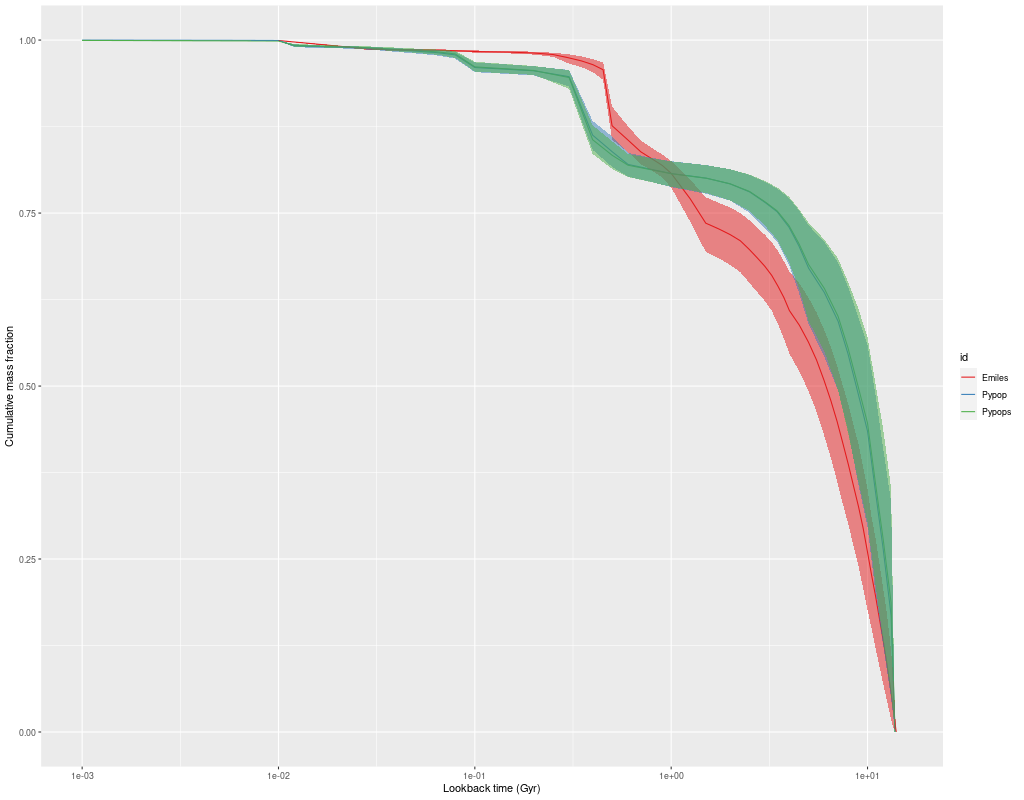
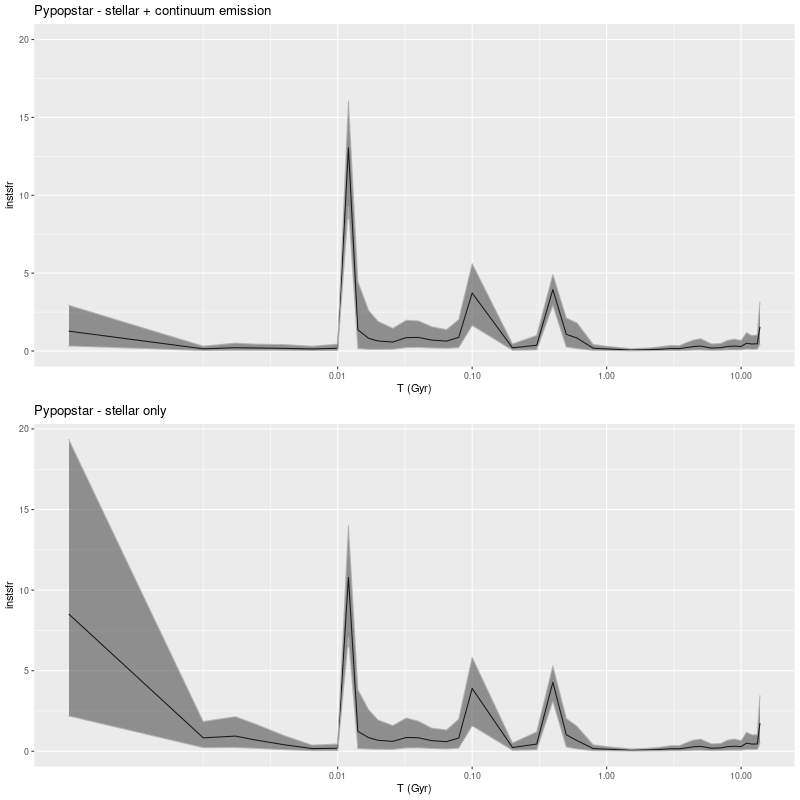
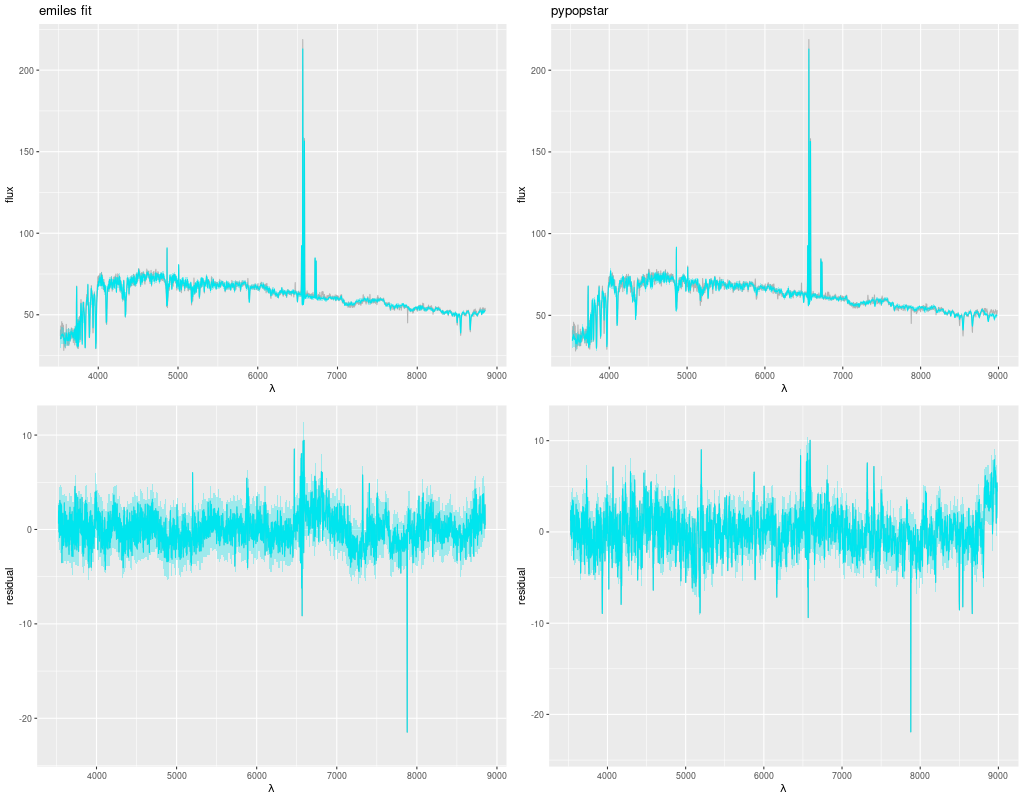
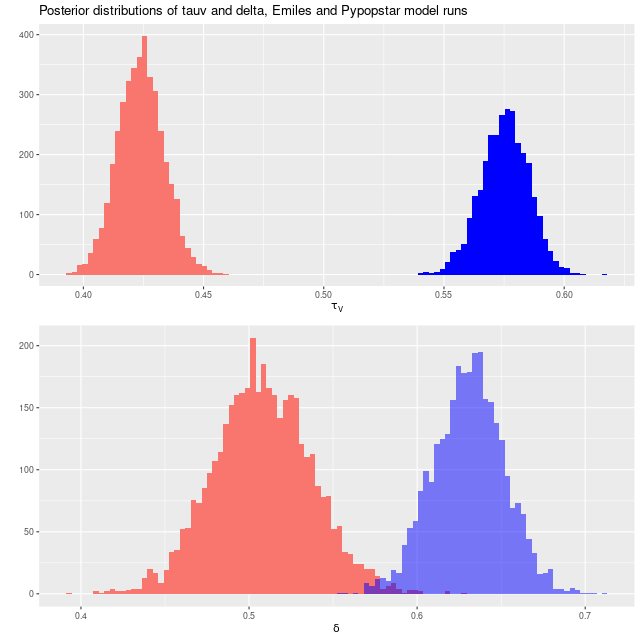
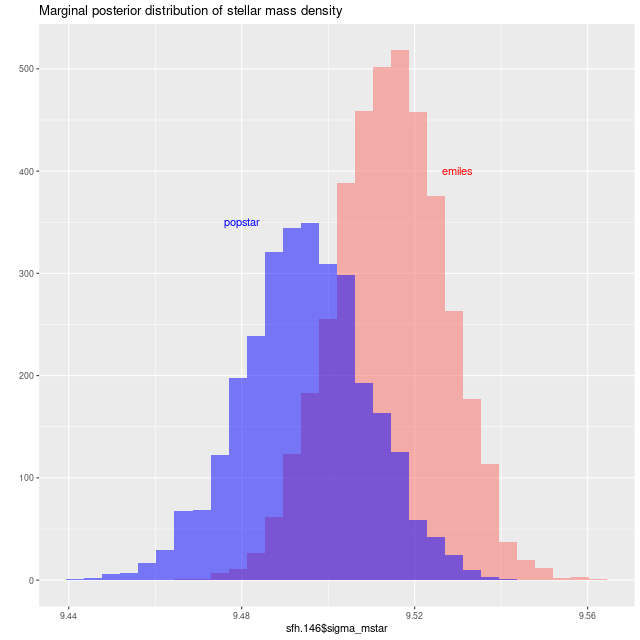
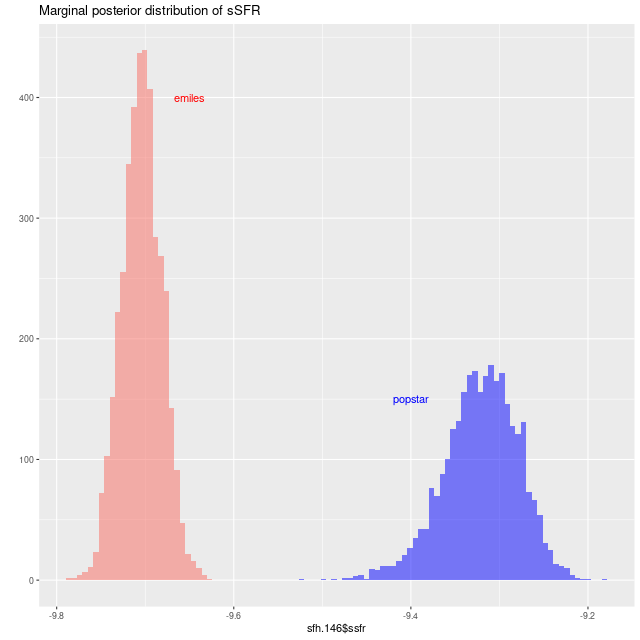
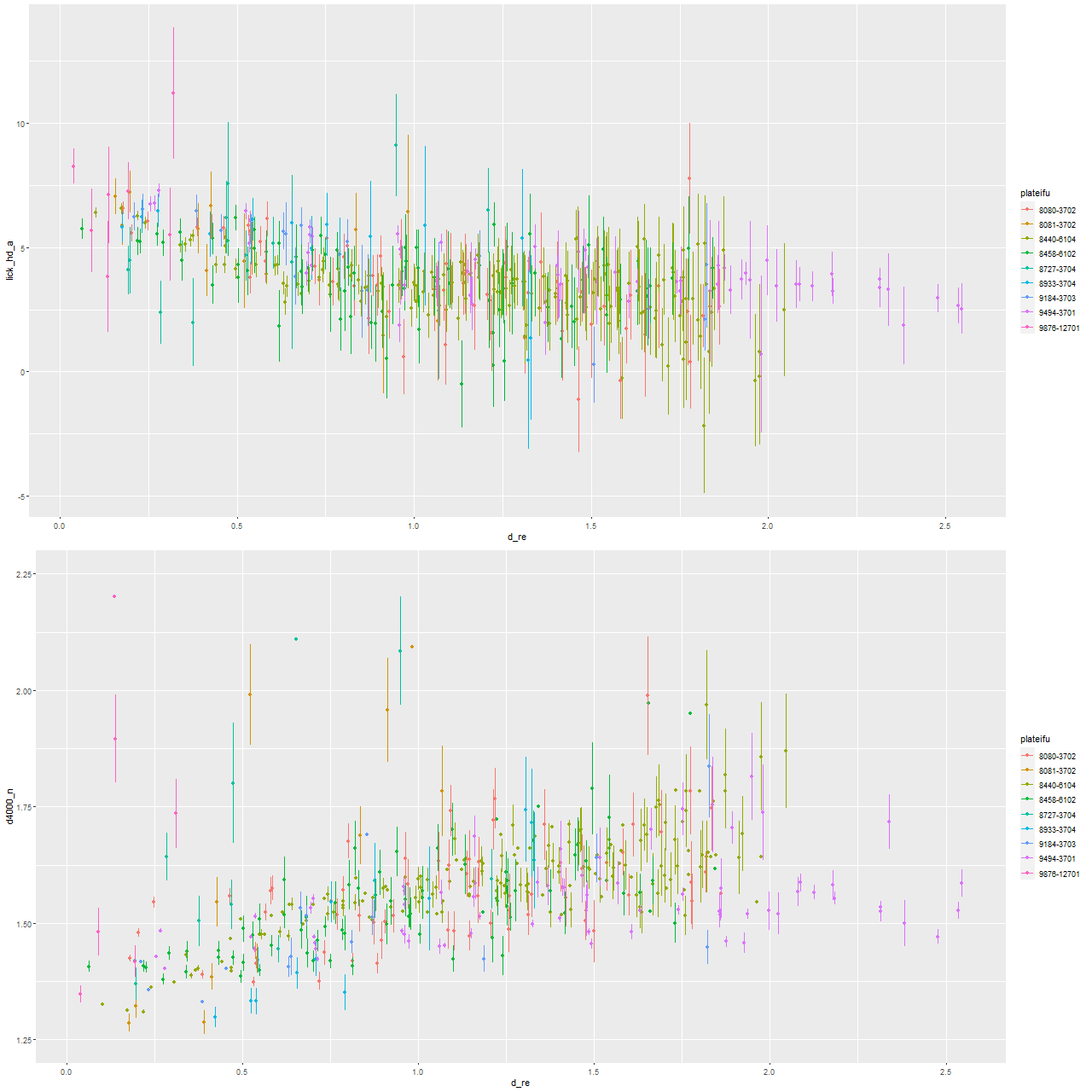
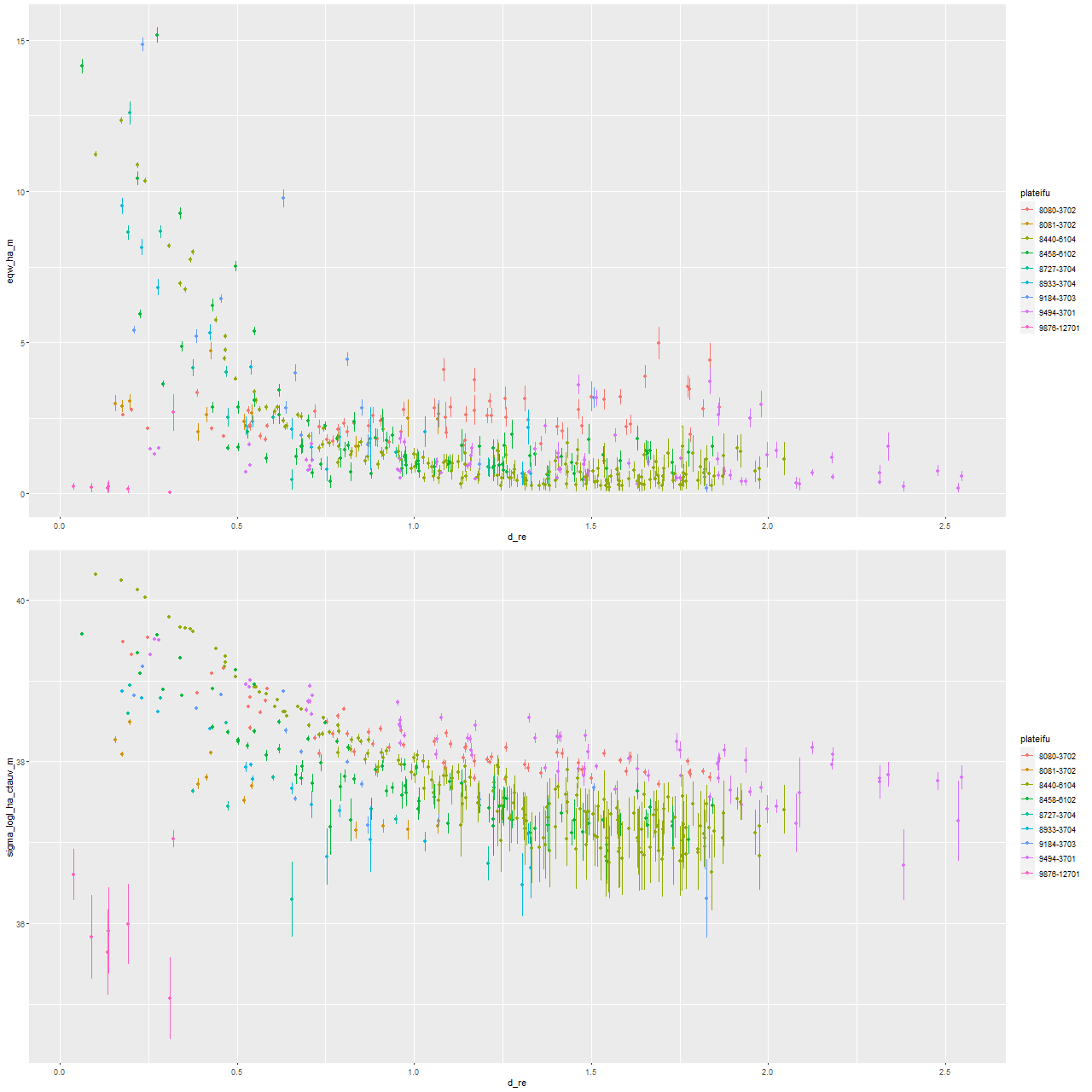
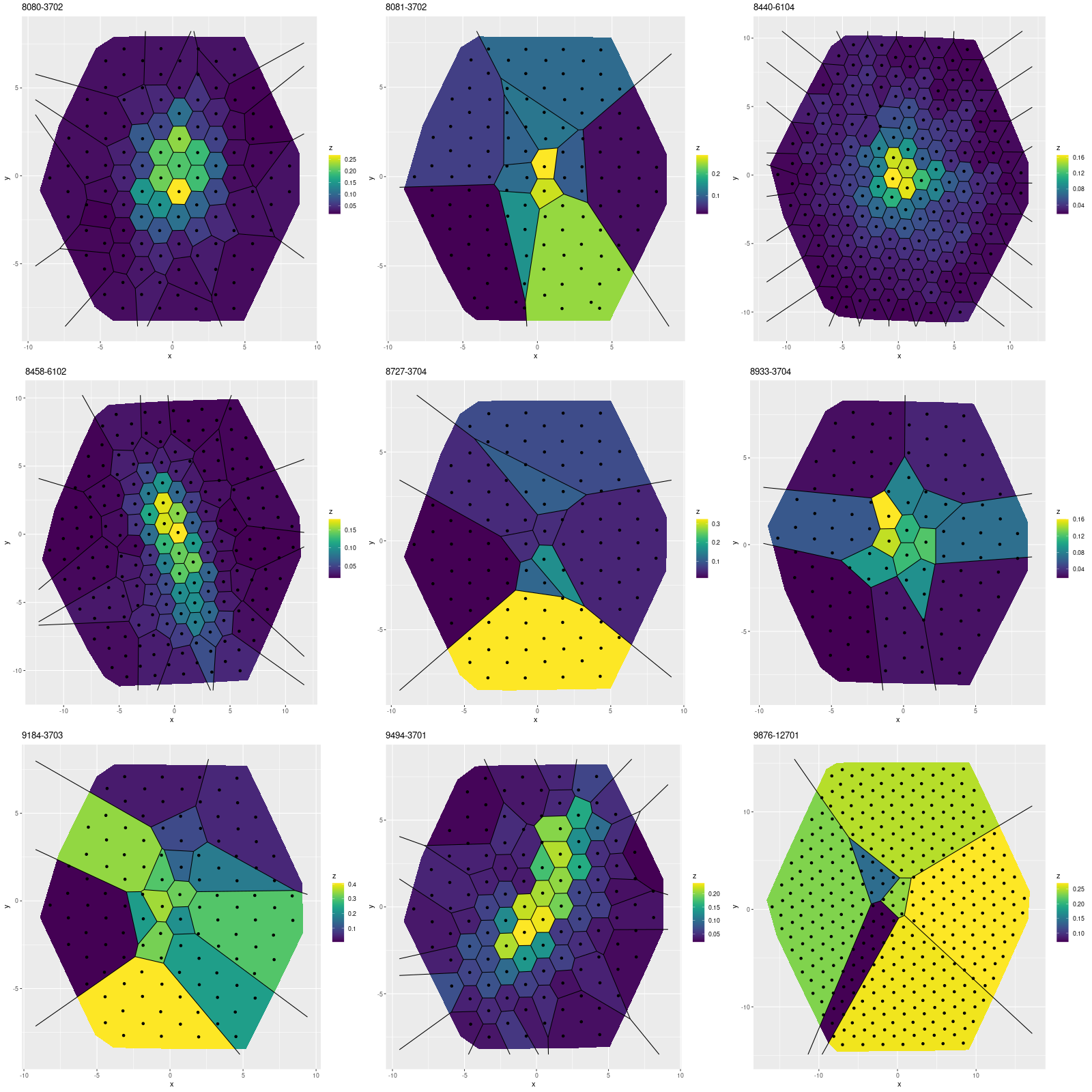
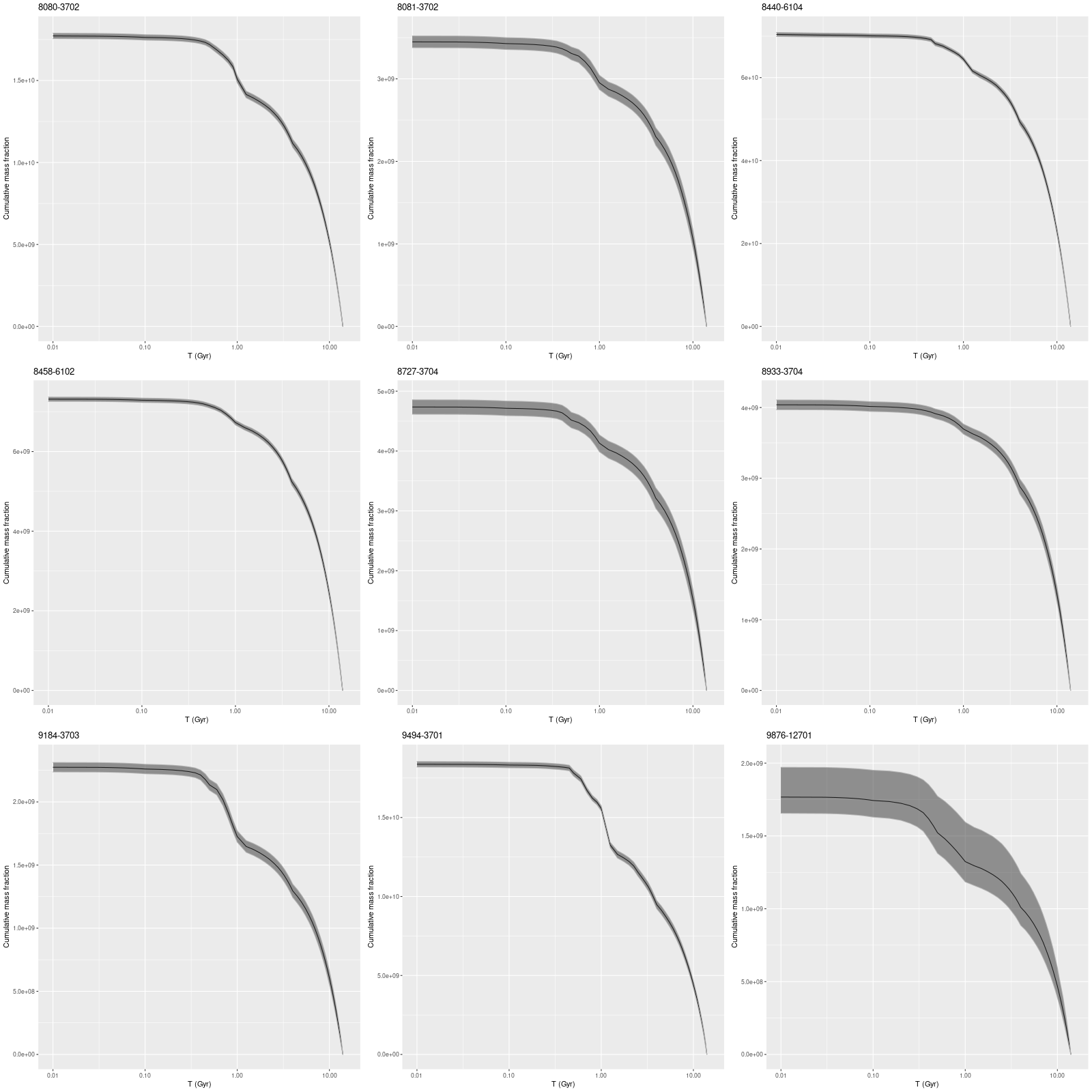

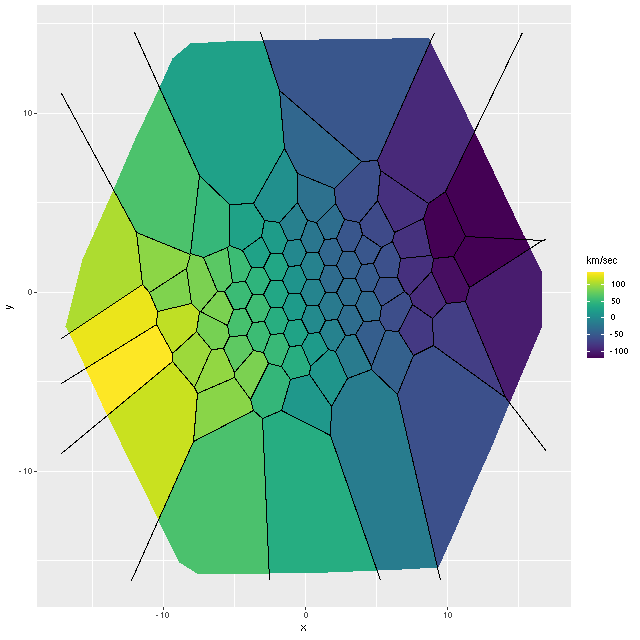
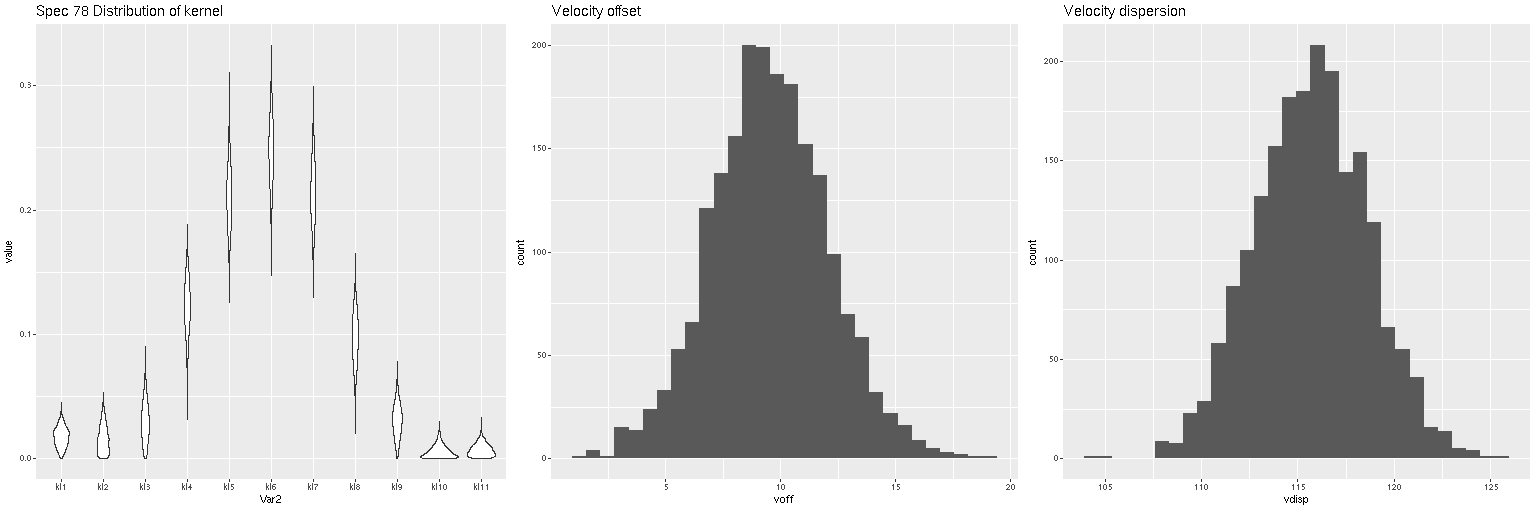
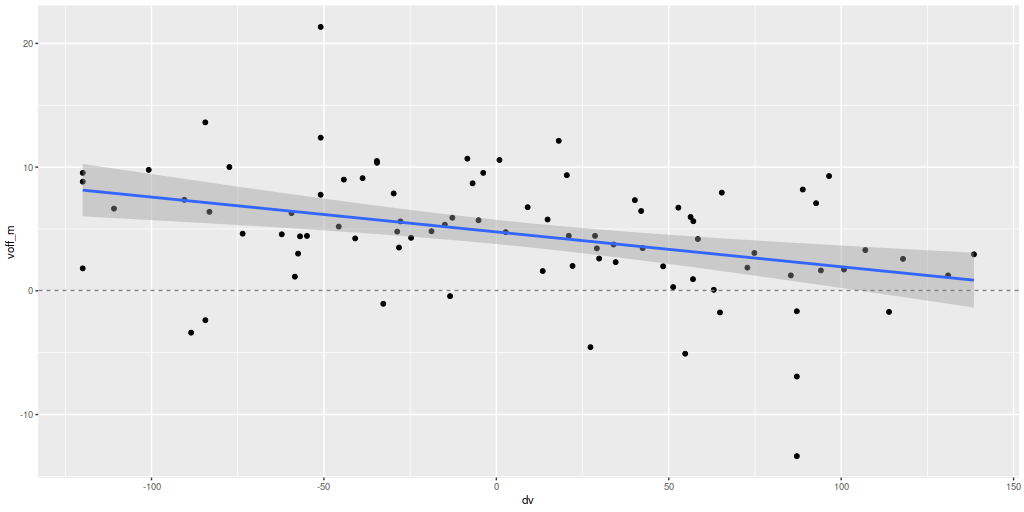
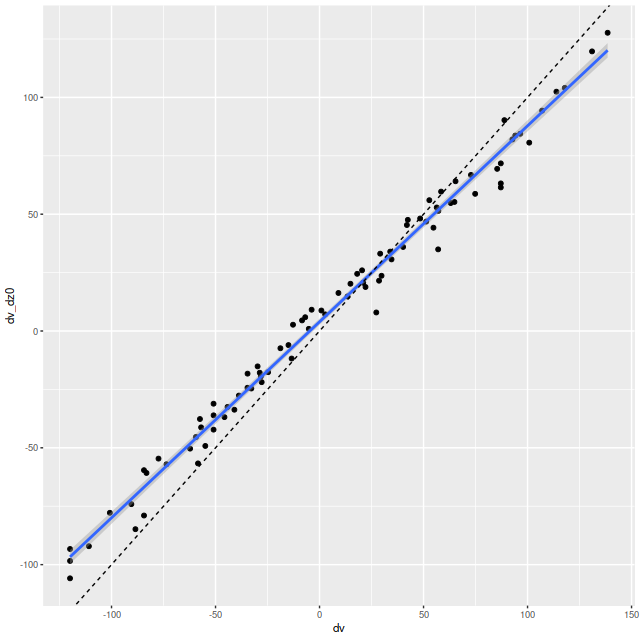
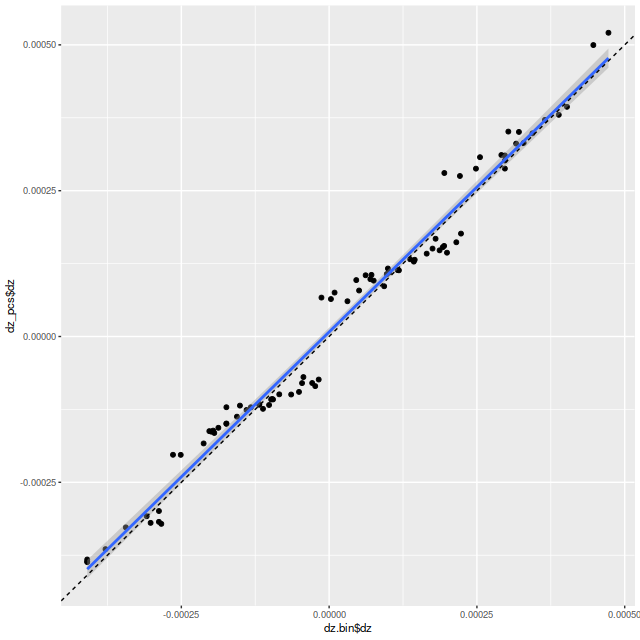
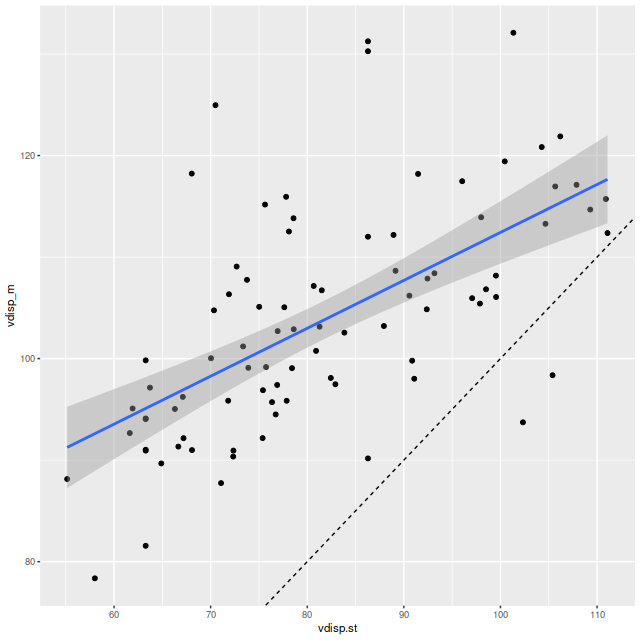
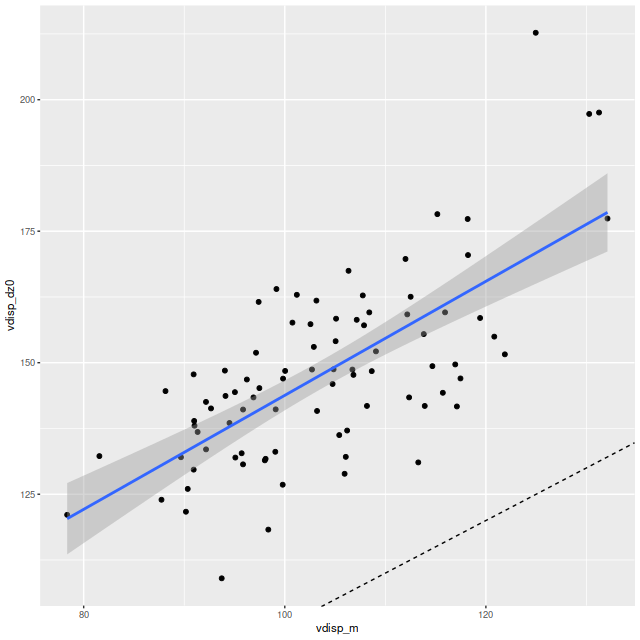
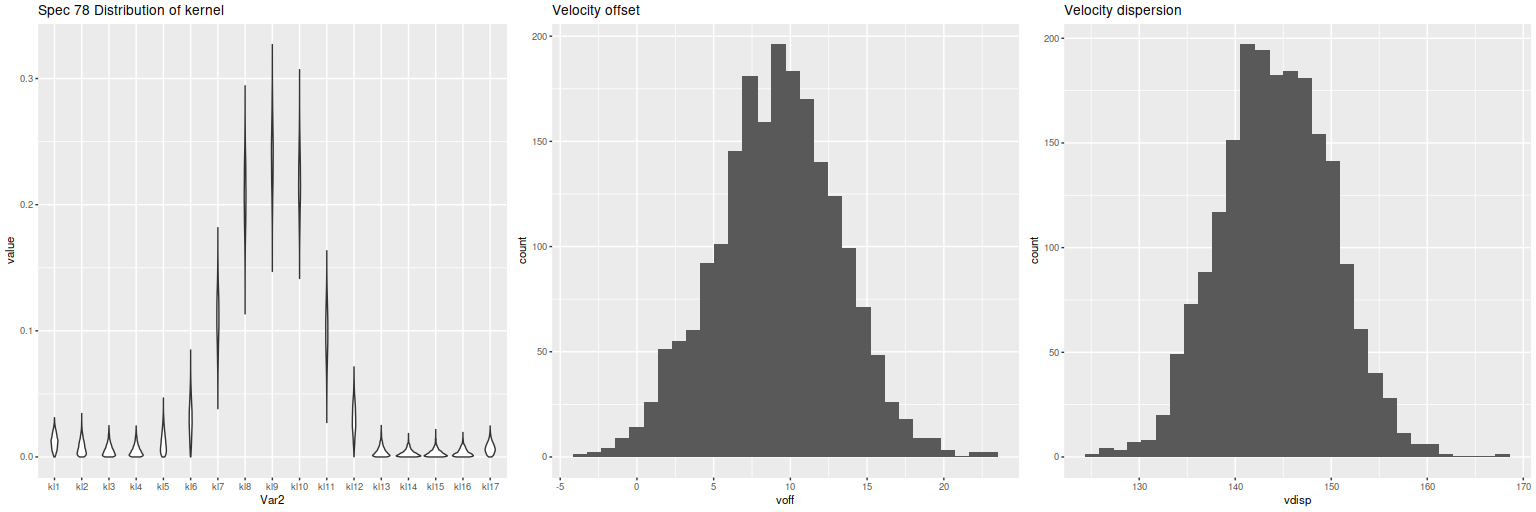
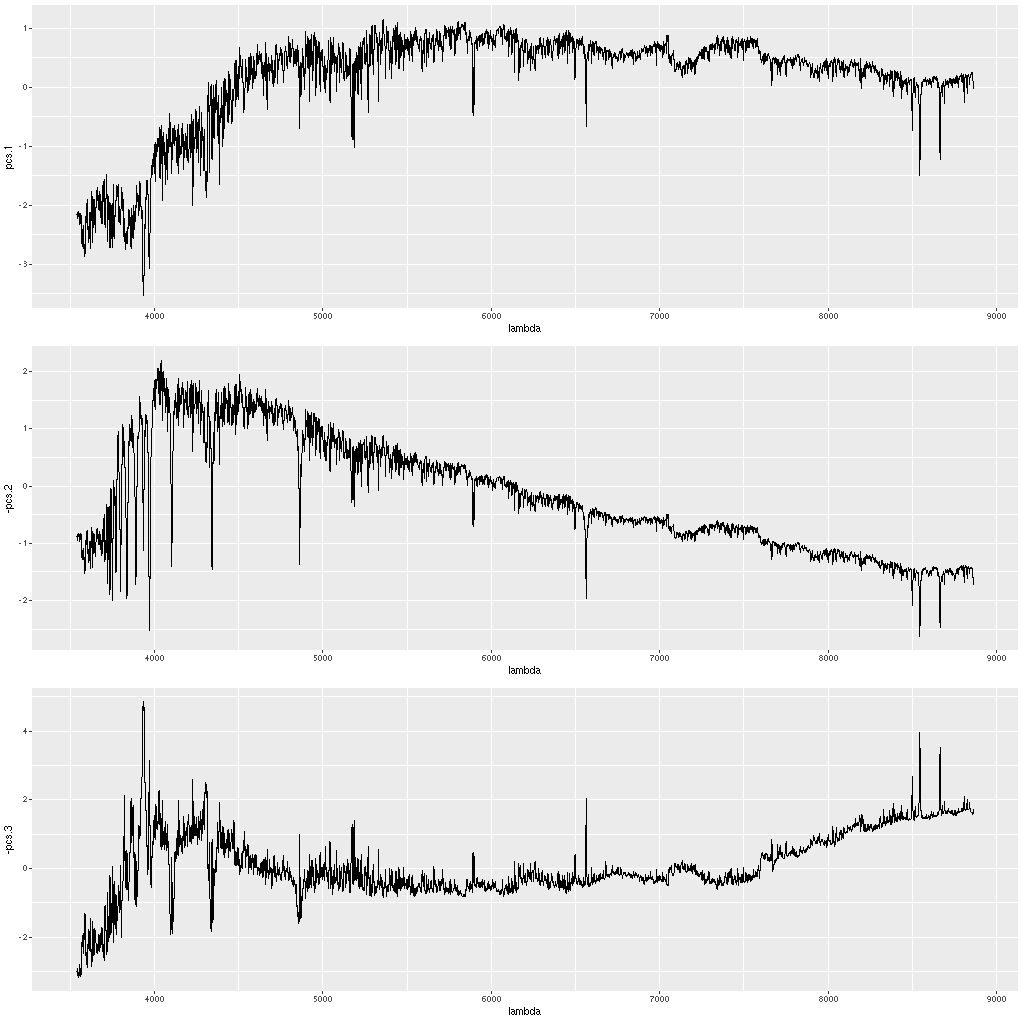
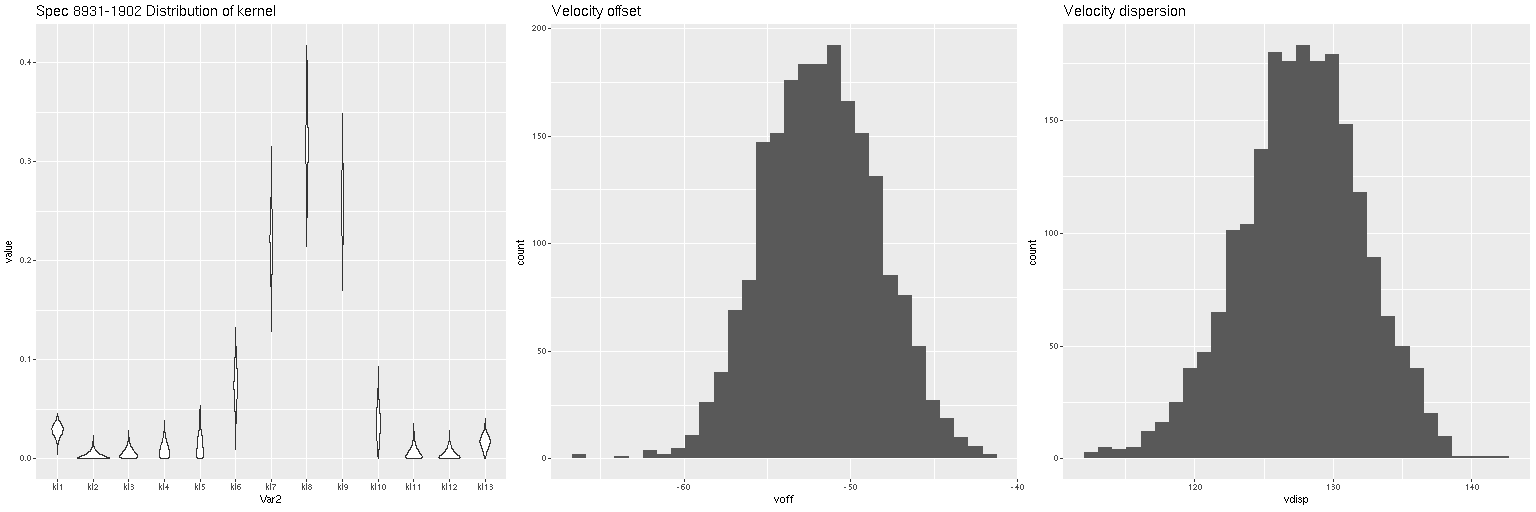
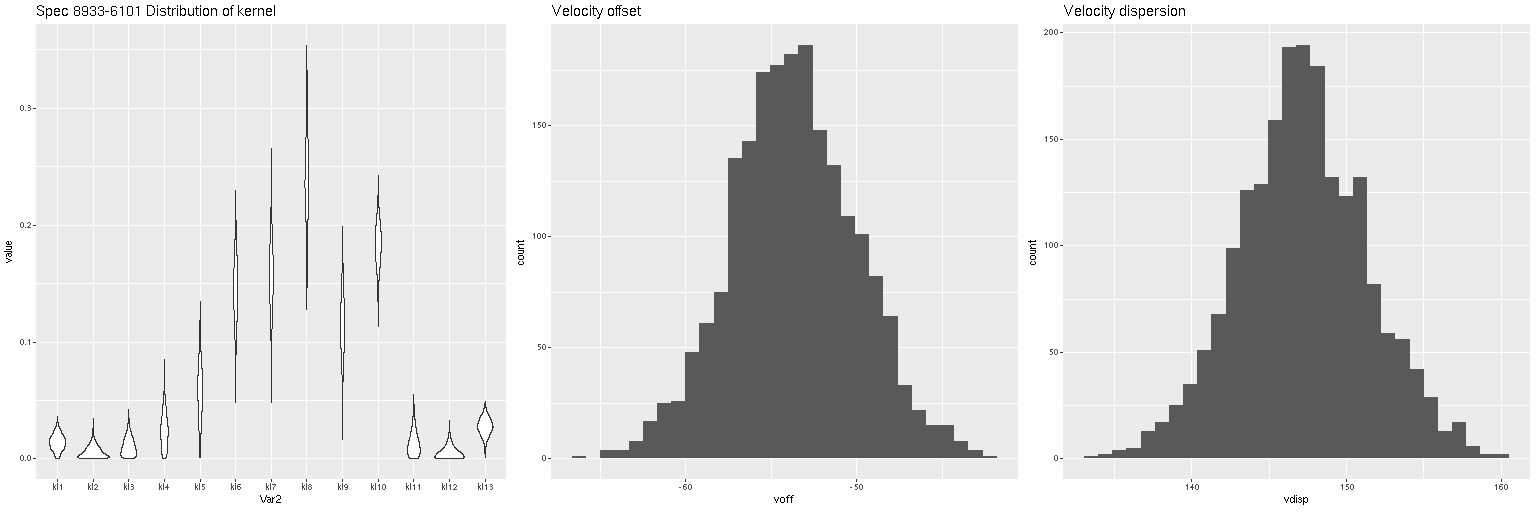
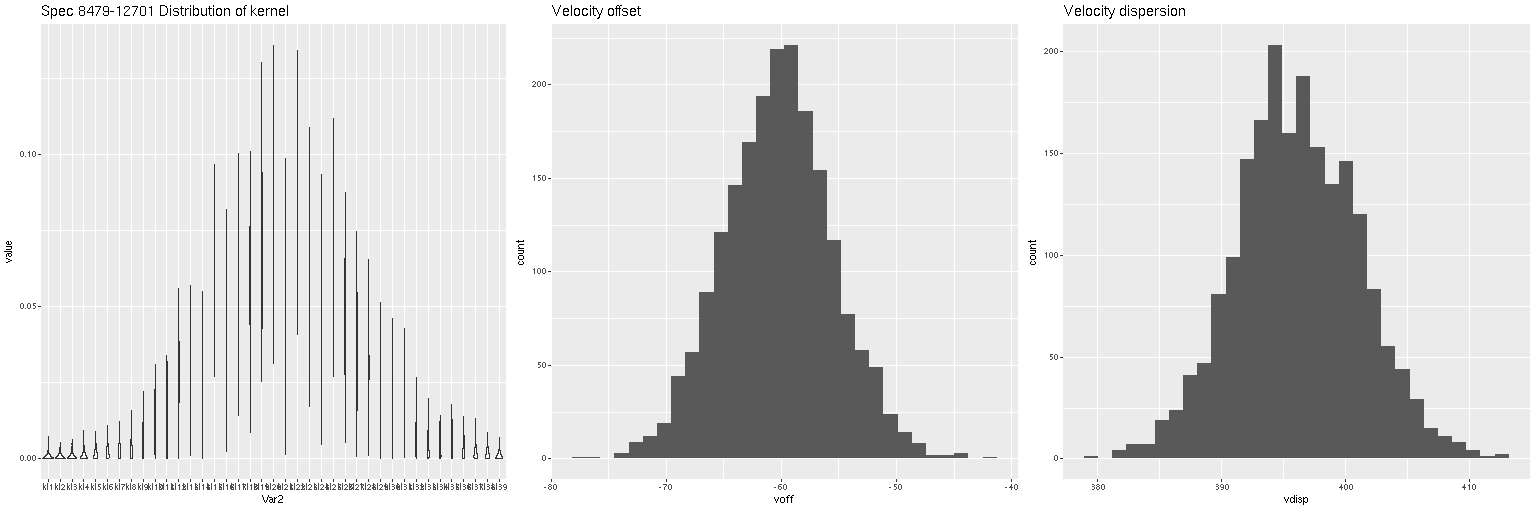
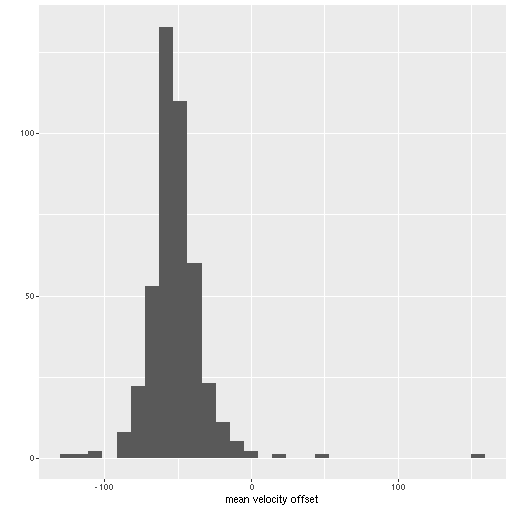
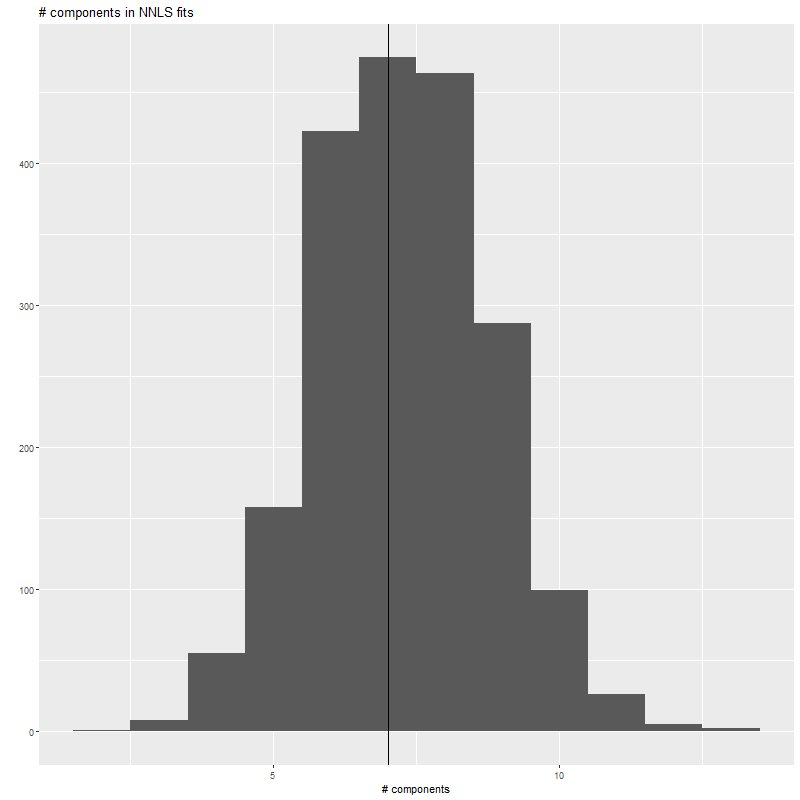
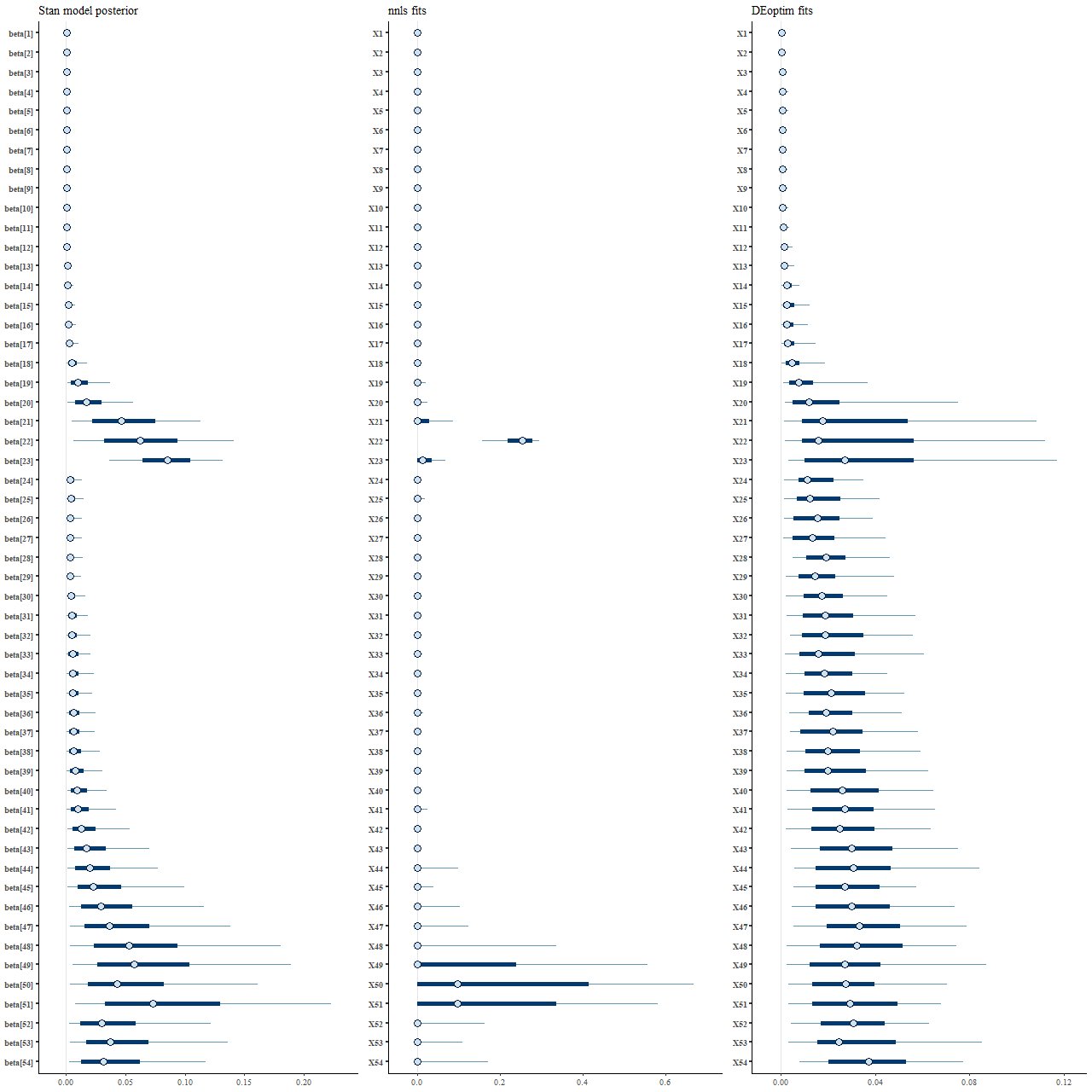
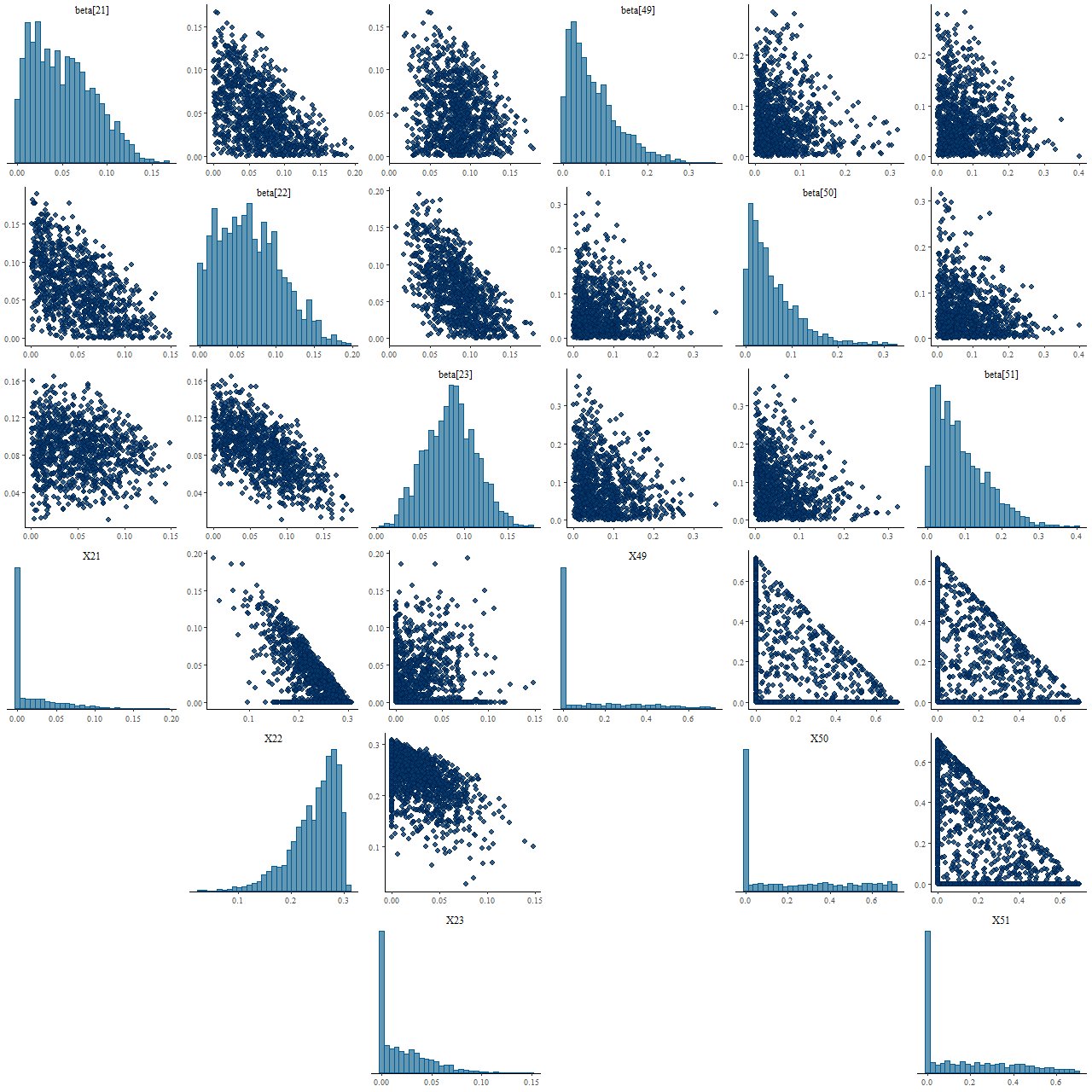
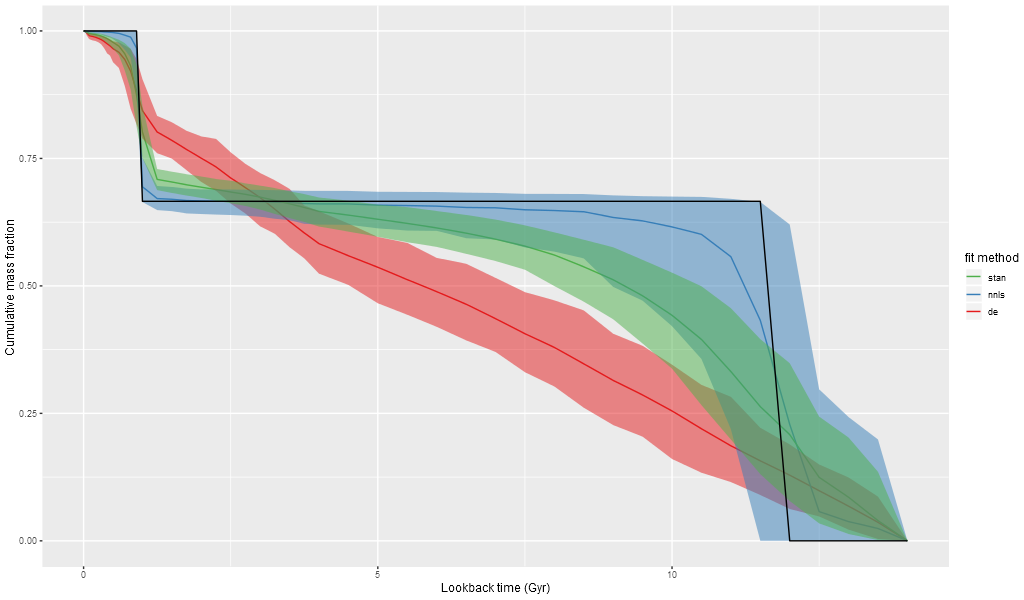
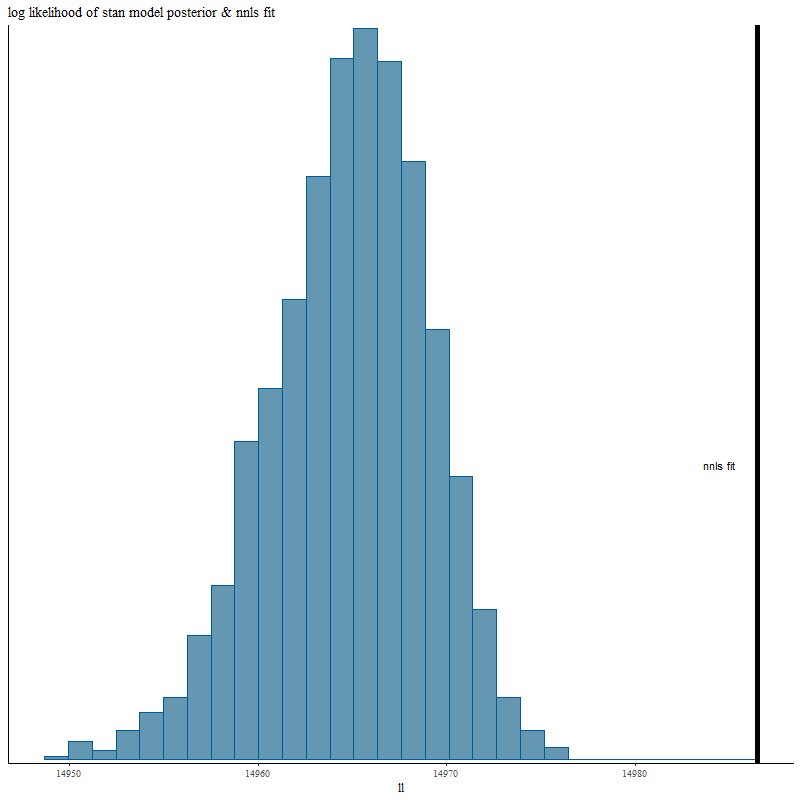
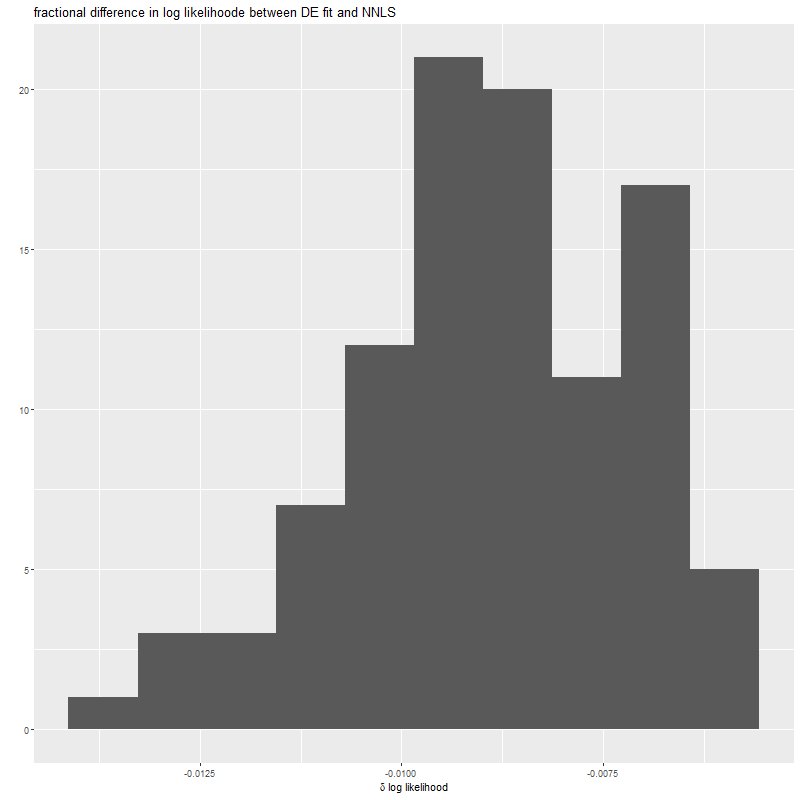
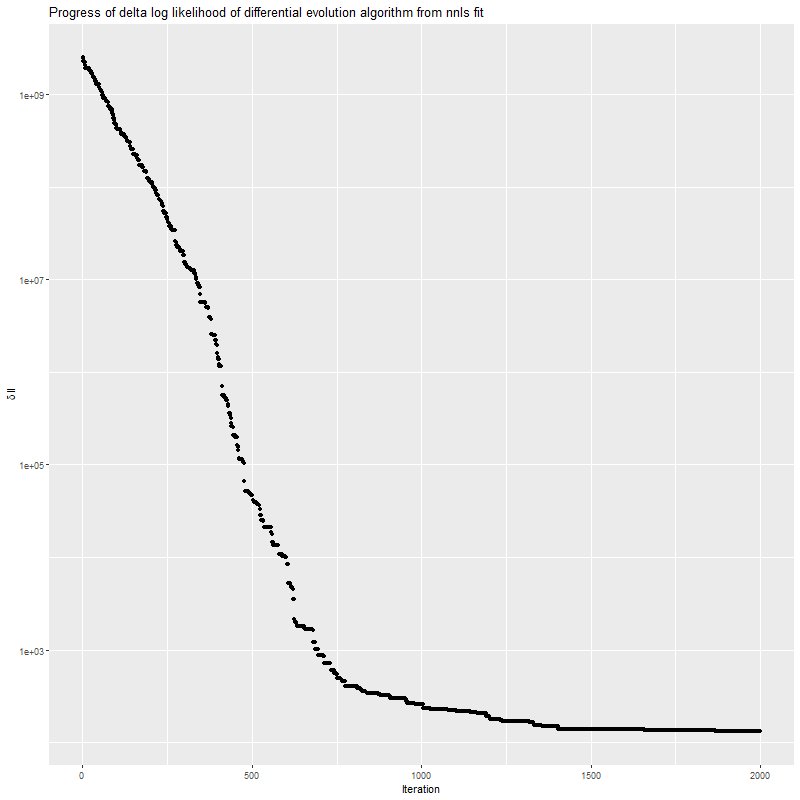
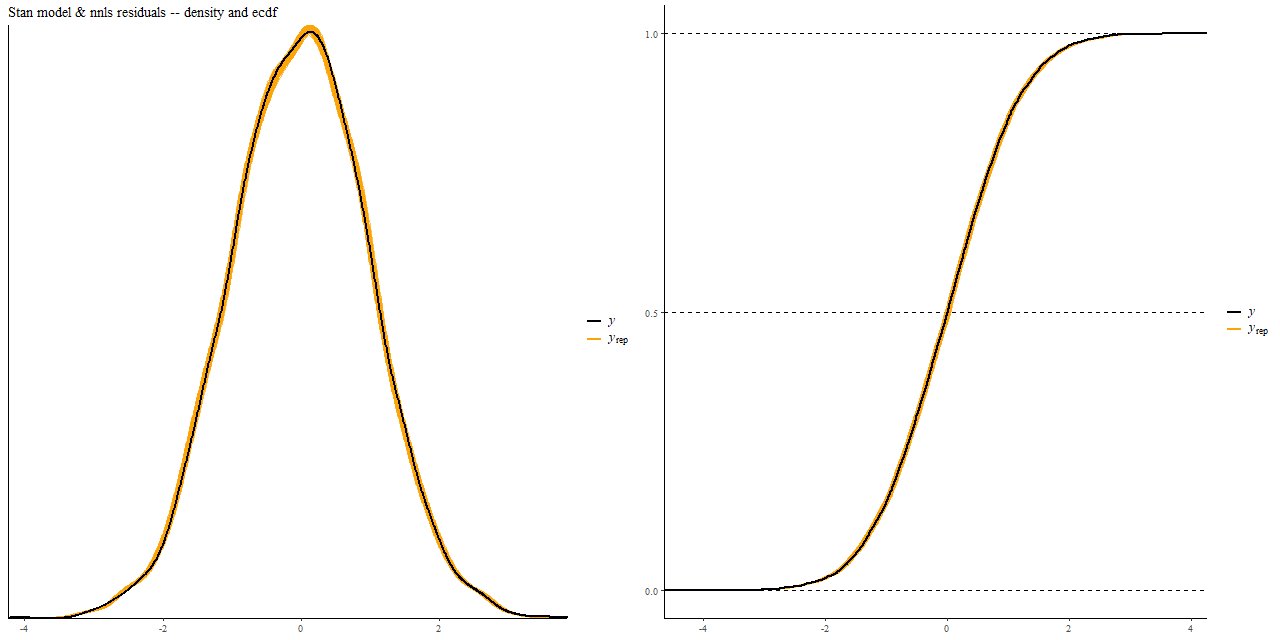
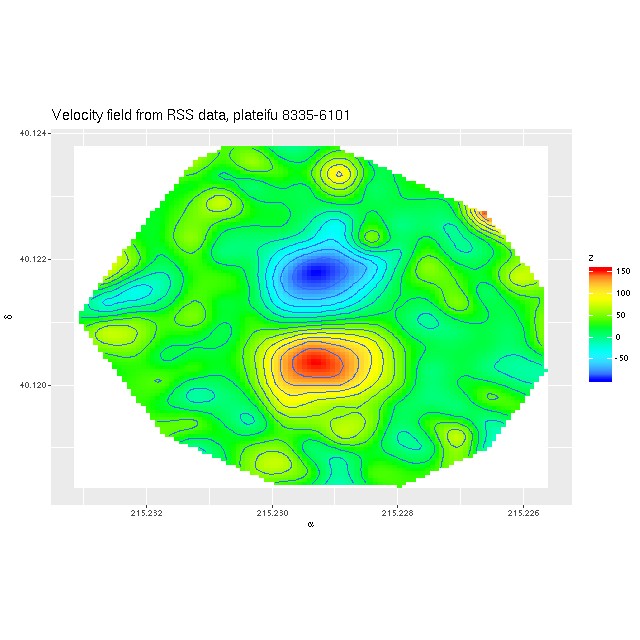 Velocity field estimated from RSS data
Velocity field estimated from RSS data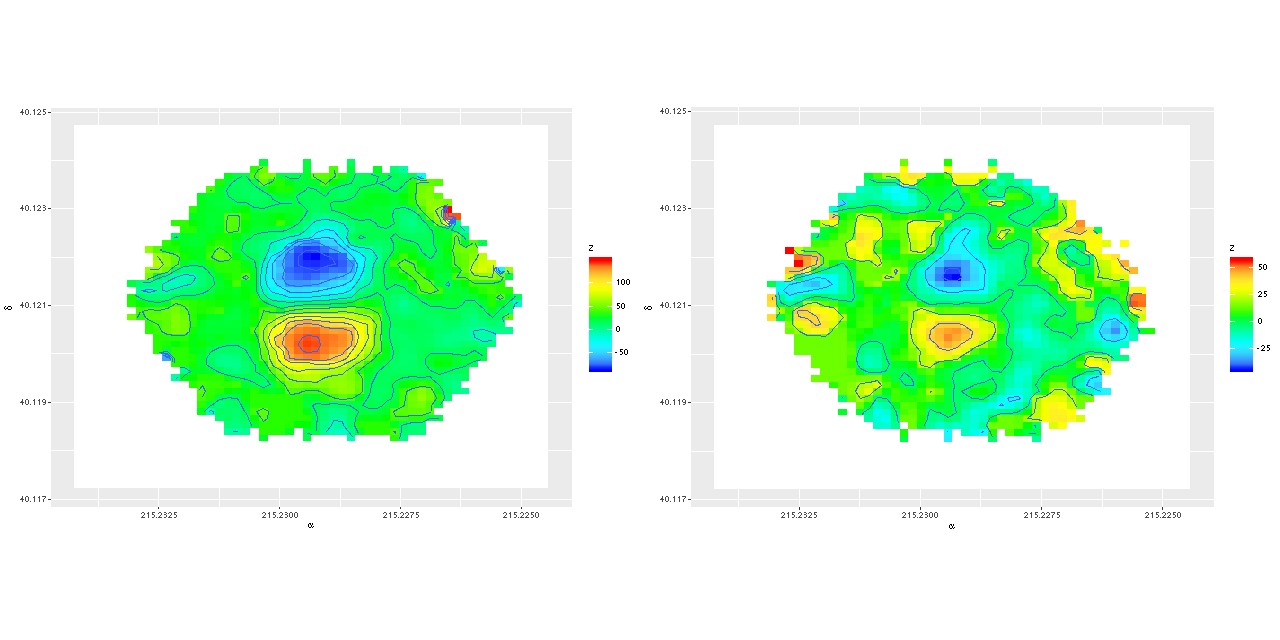 (L) Velocity field estimated for data cube
(L) Velocity field estimated for data cube Central fiber spectrum, plateifu 8335-6101
Central fiber spectrum, plateifu 8335-6101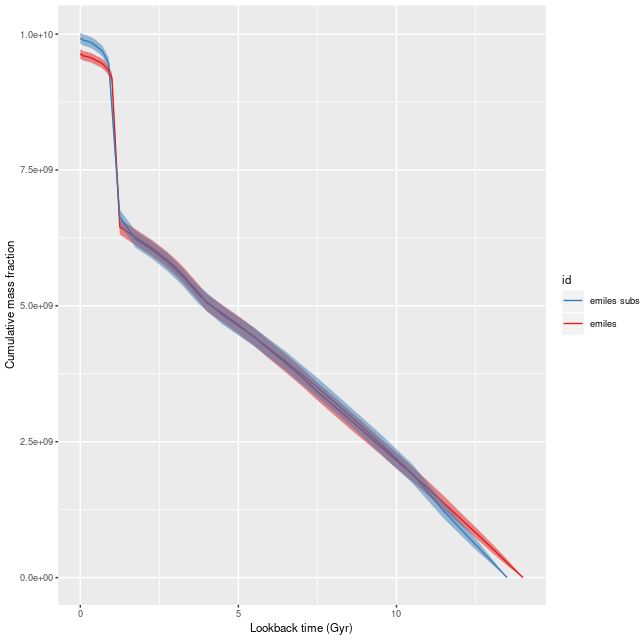 Summed model mass growth histories, emiles subset and “full” emiles
Summed model mass growth histories, emiles subset and “full” emiles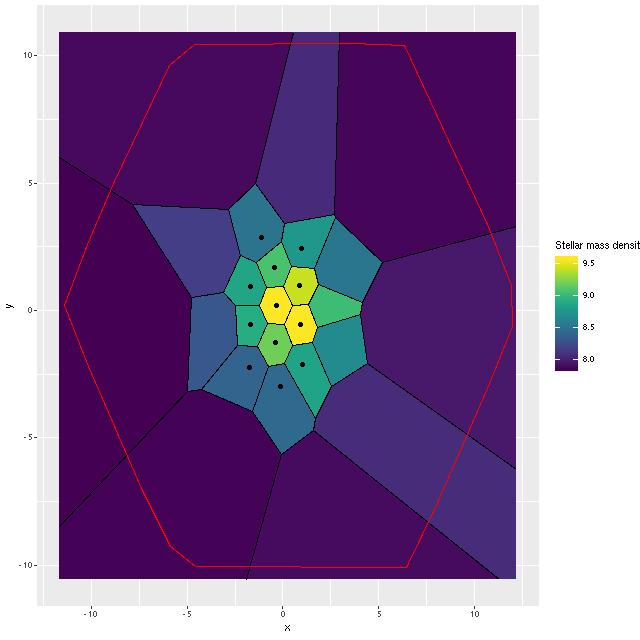 Stellar mass density for binned data, showing outlines of bins and core region
Stellar mass density for binned data, showing outlines of bins and core region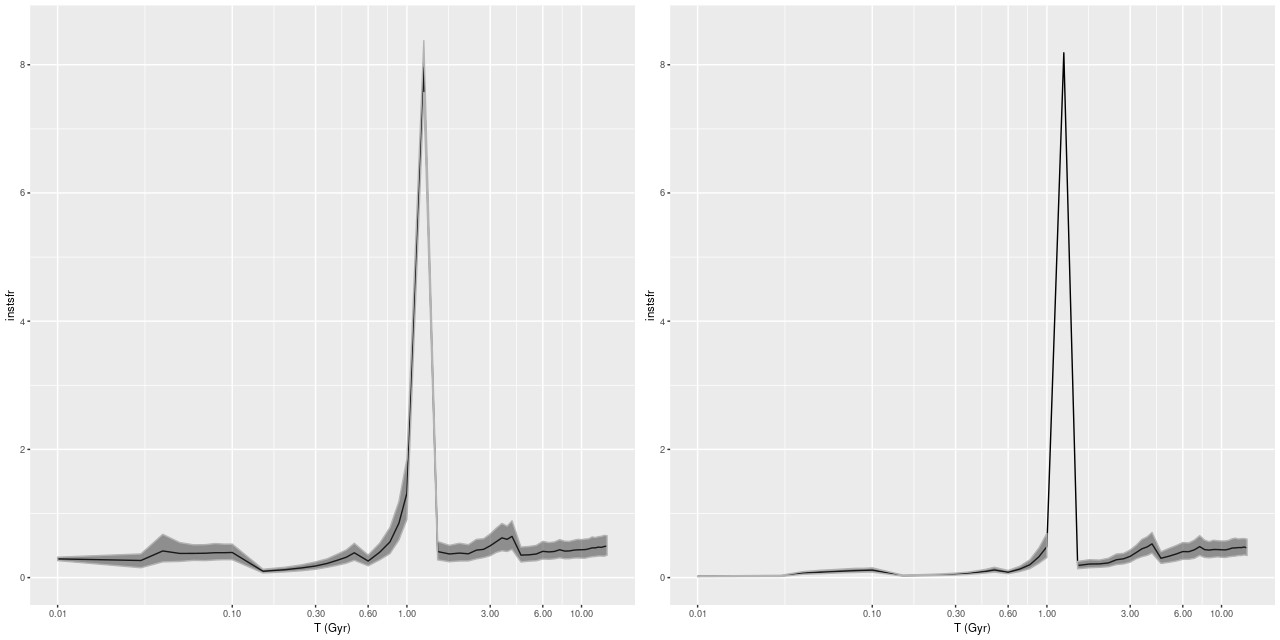 (L) Model Star formation history, inner core
(L) Model Star formation history, inner core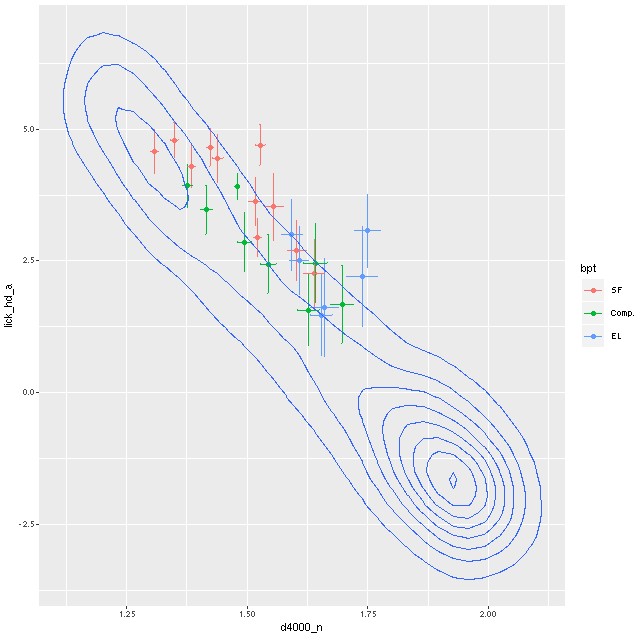 Lick HδA vs. Dn(4000)
Lick HδA vs. Dn(4000)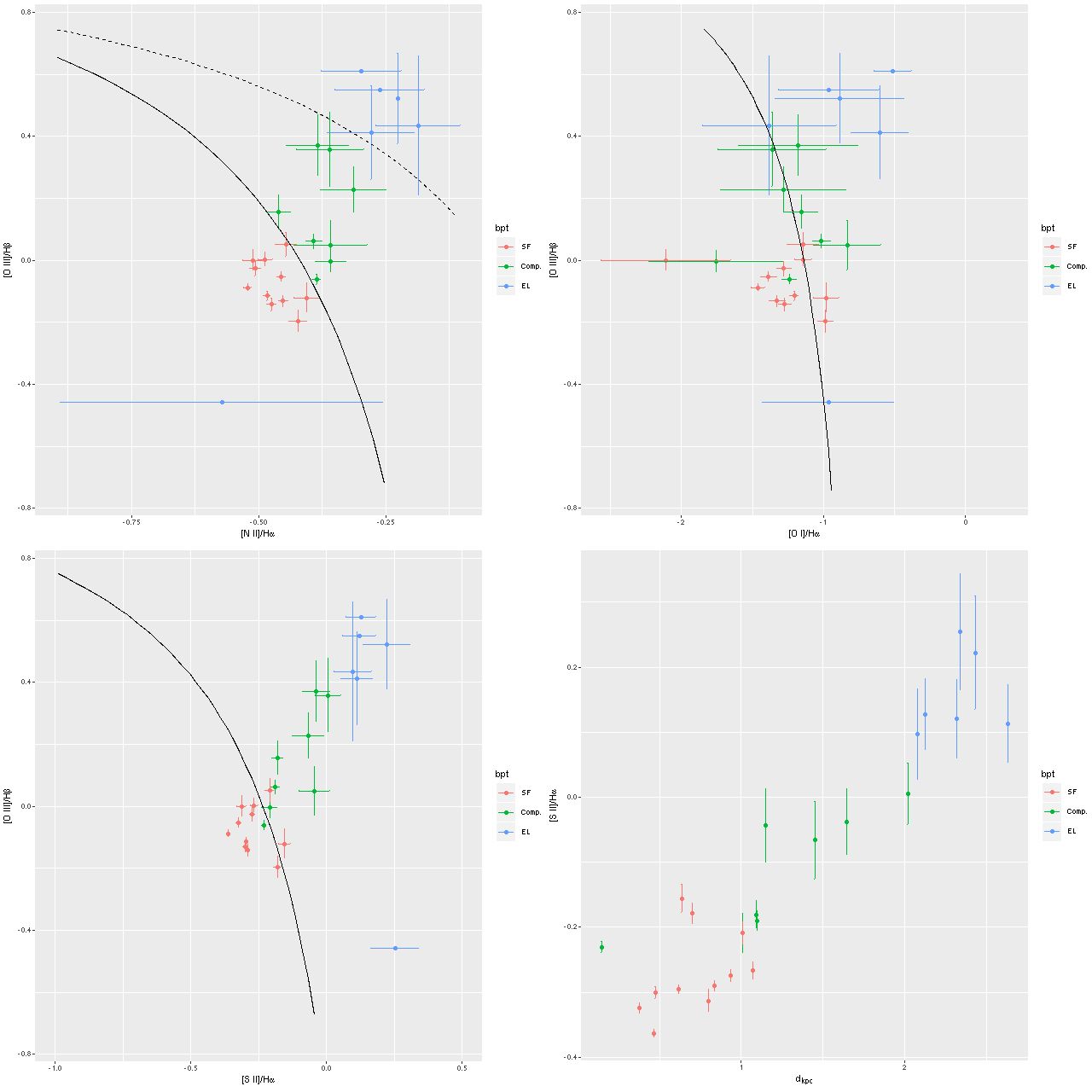 Emission line diagnostic (BPT) plots
Emission line diagnostic (BPT) plots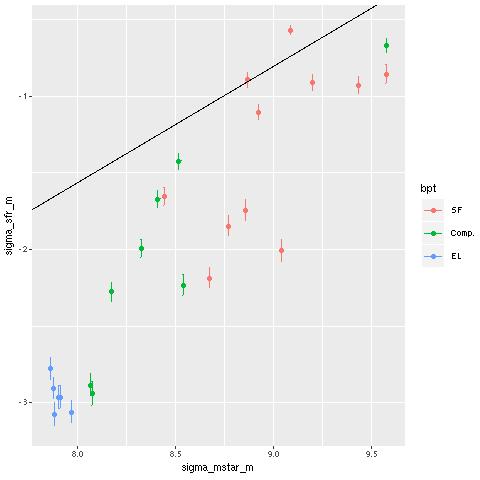 log SFR density vs. log stellar mass density
log SFR density vs. log stellar mass density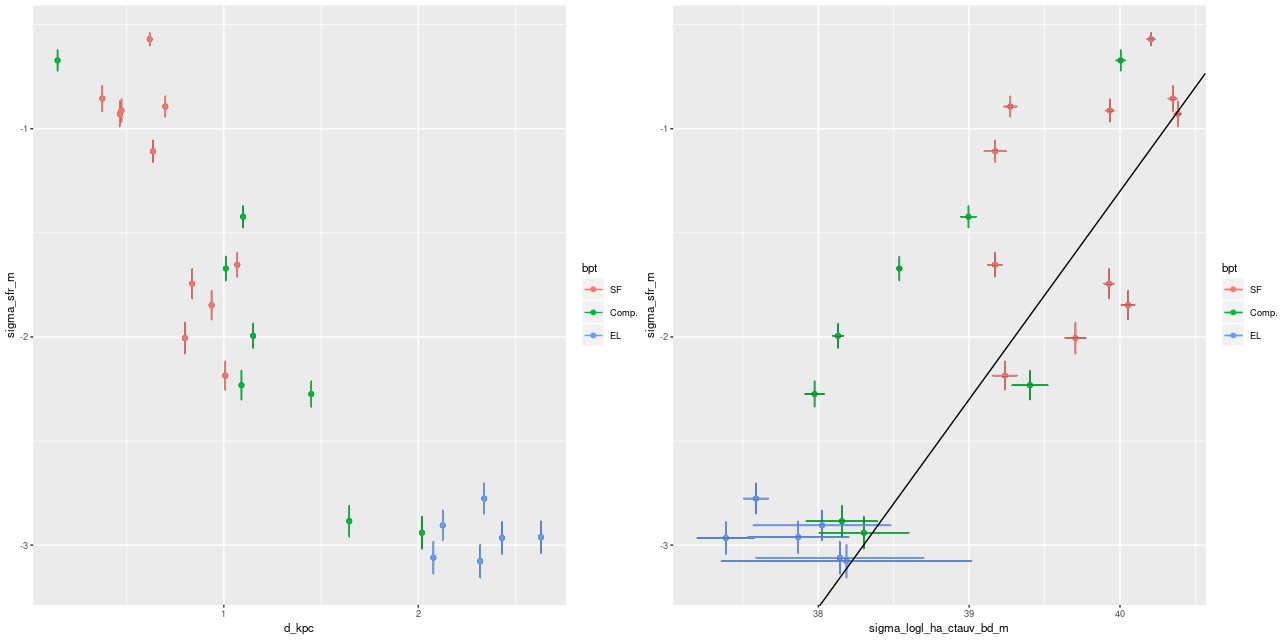 (L) log SFR density vs. radius
(L) log SFR density vs. radius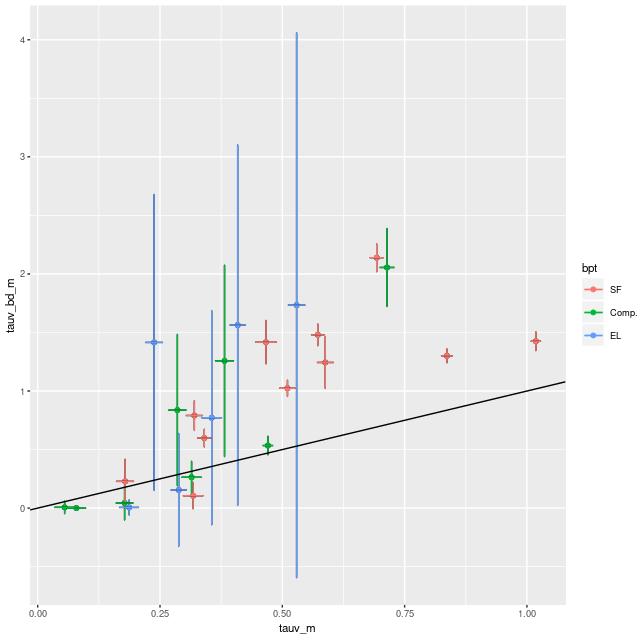 τV estimated from Balmer decrement vs SFH model estimates
τV estimated from Balmer decrement vs SFH model estimates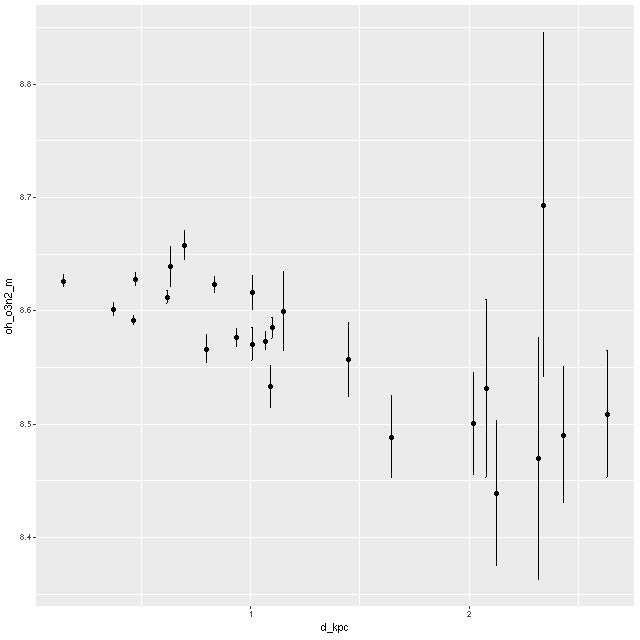 Metallicity 12+log(O/H) vs radius, estimated by O3N2 index
Metallicity 12+log(O/H) vs radius, estimated by O3N2 index