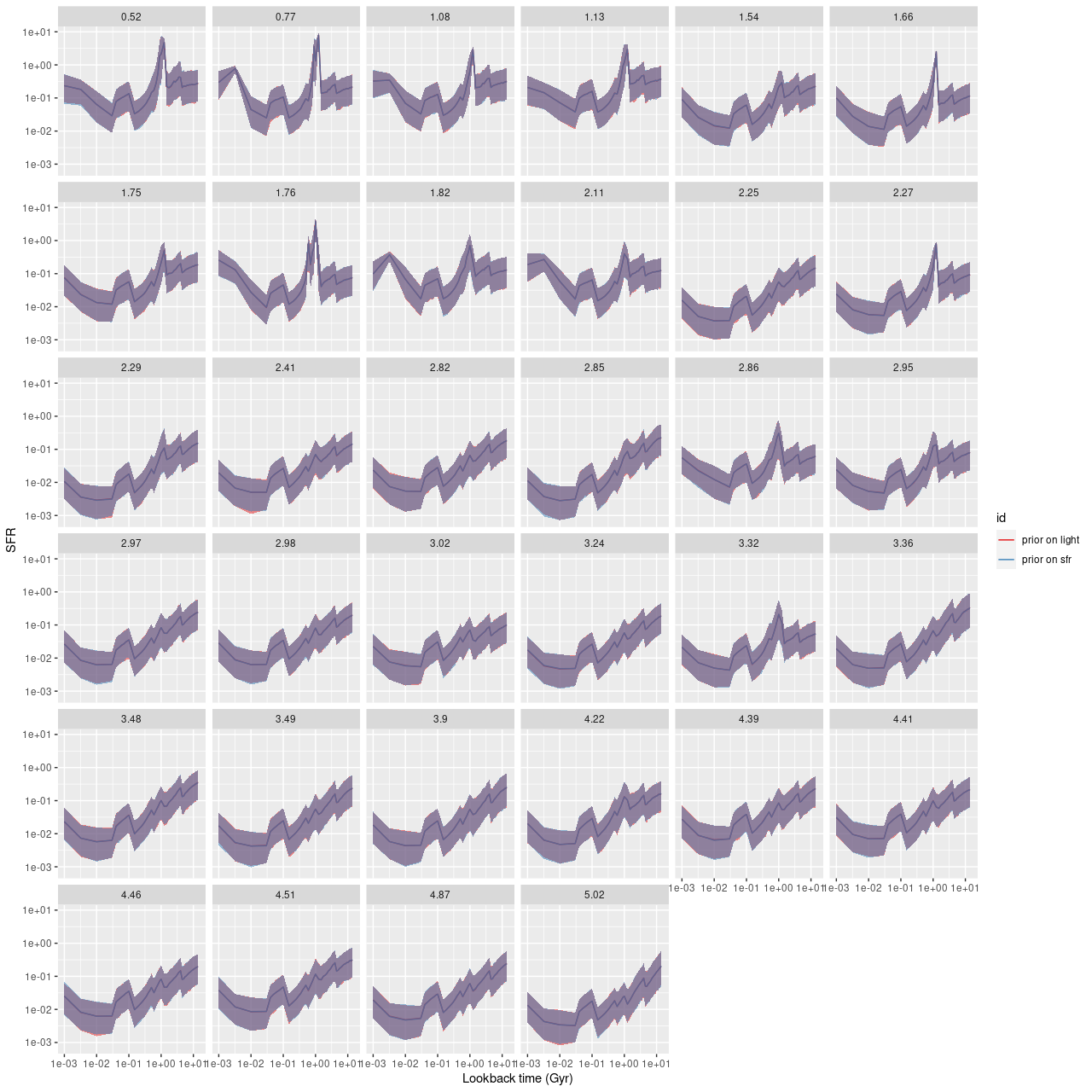
One thing I’ve wondered about for a while is the extent that priors on SSP model contributions affect modeled star formation histories. Previous experience suggests not much at all unless the prior is highly constraining. To be a little more specific in my current workflow I normalize the SSP model spectra to have average flux values of 1 in (approximately) the V band, and also adjust the galaxy fluxes in the same way. In the Stan model the stellar contribution parameters are declared as a simplex, that is a vector with non-zero elements summing to 1. That makes the parameter values the fractional contributions to the (unreddened) galaxy flux at V. My current working code doesn’t provide an explicit prior for the stellar parameters, but they have an implicit proper prior of a uniform distribution on the appropriate dimensional simplex. More technically the prior is a Dirichlet distribution with all concentration parameters equal to 1. Note the marginal distributions aren’t uniform, but they are all the same. One implication of that is that a typical draw from the prior1Stan doesn’t sample from the prior even for initialization, but of course the prior influences the posterior through Bayes’ rule. will have jumps in the star formation rate at exactly the times where the width of the age bins jump, a problem that I’ve noted several times before.
A possible solution to this problem is simply to alter the prior to encourage smoothly varying star formation rate rather than smoothly varying light contributions. It turns out I’ve been feeding my Stan code the data I need to do that: the initial mass in a given model SSP is inversely proportional to the normalization factor applied to the spectrum, and the star formation rate is just the mass divided by the time interval assigned to the SSP. Both of those quantities are passed as data to the Stan model even though they weren’t used in any way previously. I added just 3 lines to the code to change the prior on the stellar contributions. In the “transfored data” section
If I did this right the prior is completely agnostic to any star formation history, whereas the previous implicit prior was completely agnostic to any run of light contributions.
The modified code compiled without complaint and there’s no discernible difference in either execution time or convergence diagnostics.
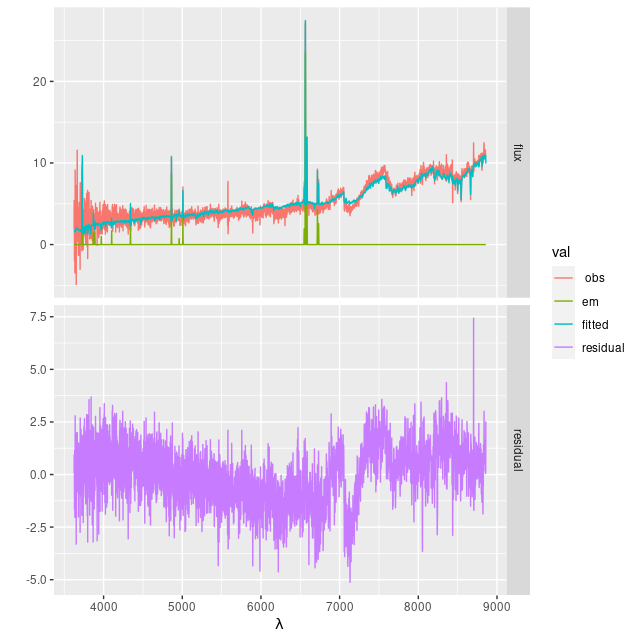
I’ve only run this on one set of galaxy data, from MaNGA plateifu 8565-3703 (mangaid 1-92735). This is one of Schawinski’s “blue early type galaxies,” chosen mostly because the data were binned to just 34 spectra so a complete set of model runs only took a few hours. And, as seen below the other things that don’t change are the modeled star formation histories.
Plateifu 8565-3703 (mangaid 1-92735). Star formation history models with two distinct priors on stellar contributions.
I need to do some more validation exercises, but it appears my long ago conclusion that the choice of prior on the star formation history has little effect was correct. The data dominates the model outcome through the likelihood.
Update
Since I hit publish a few days ago I realized two things. First, the weights I applied to the stellar contributions to “encourage” a smoothly varying star formation rate were inverted. What I should have used was:
The second thing I realized is this makes no difference at all given the form of the prior. The transformation simply maps a point on the simplex to another point on the simplex that has exactly the same probability density since by construction the prior is uniform on the simplex.
So, it should have been expected, and it’s a good thing that it in fact happened that the model runs produced the same results. What happens if I use the following prior, with the weights supplying the parameters for the Dirichlet?
target += dirichlet_lupdf(b_st_s | norm_sfr);
This failed to sample almost always. I’m not entirely sure why, but I suspect this turns a problem with relatively simple geometry at least with regards to the prior to one with a complex and troublesome geometry.
This little experiment actually told me nothing about the effect of priors on model star formation histories. Two of the priors are actually the same, and the third fails for reasons that aren’t completely clear. I may experiment with different forms of prior. I’m still, of course, looking for a new SSP model library.
For a few years now I’ve been using a library of SSP1Simple Stellar Population model spectra based on the EMILES models of Vazdekis et al. supplemented with some young stellar populations taken from the “HR-pypopstar” models described in Irigoyen et al. (2021) and retrieved from fractal-es.com/PopStar. As I’ve mentioned several times there are a few issues with the models. First, the abrupt changes in time intervals of the BaSTI isochrone based models produce sharp jumps in model star formation rate estimates at several lookback times. This is because my star formation history models “want” to produce smoothly varying contribution estimates, which lead to abrupt jumps in rates when the time interval decreases.
Another possible issue is there are multiple sources of data used for the SSP model spectra. Besides the pypostar models for young populations the older population spectra use MILES stellar spectra for wavelengths up to 7410Å, with spectra from another source grafted on for longer wavelengths within the relevant range for SDSS. This wavelength happens to fall on a wide absorption feature (I believe mostly due to TiO) that’s prominent in older populations, and this region is often fit rather poorly by the models. Although there are other possible reasons for this I’ve long suspected that it might be due to different flux calibrations of the two data sources. Ideally I’d like to have single, homogeneous data source covering the full wavelength range of SDSS spectra.
That ideal data source may exist in the SDSS MaStar stellar spectrum library, which is a large collection of stellar spectra observed as part of the MaNGA project. Since the observations used the same BOSS spectroscopes they have the same wavelength coverage, spectral resolution, and flux calibration as the MaNGA galaxy spectra. So far I’ve found 2 MaStar based SSP model libraries. First is one described originally in Maraston et al. (2020) with data available at https://www.icg.port.ac.uk/mastar/. This was based on the preliminary (DR15) data release and has a minimum age of 300Myr, which is unsuitable for my purposes. An updated version with sufficiently young models is described in Nanni et al. (2022, 2023, 2024). That version has not yet been published as of the date of this post.
A more immediately usable set of models were described in Sanchez et al. (2022) and retrieved from http://ifs.astroscu.unam.mx/pyPipe3D/templates/. These are based on the 2019 update of the venerable Bruzual and Charlot (2003; BC03) models, with MaStar spectra substituting for MILES+IndoUS in the relevant wavelength range. The spectra were taken from the initial (DR15) data release and an update is promised to be forthcoming.
The linked directory contains a large number of FITS files containing subsets of the full data set(s) — both the CB19 and MaStar based models are included. Since I wanted to select my own subset I downloaded the presumed full data sets in files named “MaStar_CB19.all_1_5.fits.gz” and “MaStar_CB19.all_1_5.fits.gz.” These contain model spectra and some other data for 210 irregularly spaced ages (not 220 as stated in the paper) and 16 metallicities. Very young ages are over-represented — there are 23 under 1 Myr and another 55 between 1 and 10 Myr. Beyond 3 Gyr the interval between models is fixed at 0.25 Gyr. For a preliminary evaluation I chose 47 ages from 1 Myr to 14 Gyr and 5 metallicities ranging from somewhat subsolar (Z = 0.004) to the highest available (Z = 0.06). I used the model spectra as given with wavelengths from 3625-9998.5Å at 1.5Å spacing. I built libraries for both the CB19 and MaStar based spectra, but will only discuss the latter for now.
I also decided to reevaluate the most recent release of the “BPASS” evolution models of Stanway and Eldridge (2018) with data retrieved from links at https://bpass.auckland.ac.nz/9.html. These are purely theoretical models including predictions for spectra, and are unique in attempting to account for binary star evolution. I had looked at a much earlier version and decided that the model continua were much too blue to be useful for full spectrum fitting. This appears to be no longer much of an issue.
Again, there are a large number of files in the data directory with different choices of IMF and upper mass limits. For a first look I chose the file bpass_v2.2.1_imf135_300.tar.gz, which corresponds to a Kroupa IMF with upper mass limit of 300 M☉2which may have been a mistake since the upper mass limit in all the other libraries I’ve tried is 100M☉. Models are available for 11 metallicities, and again I chose 5 with values ranging from Z=0.004 to Z=0.04 (the highest available). The available ages are in equal logarithmic intervals from 106 all the way up to 1011 years with a spacing of 0.1 dex. I just chose all available ages for log(T) = 6 to 10.1, for a total of 42. According to the documentation ages are meant to represent the middle of each time interval. So far I’ve adopted the convention that ages represent the beginning of each time interval of width equal to the time to the next younger age, so for consistency I add 0.05 dex to each model age. I extracted the model spectra in the wavelength range 3500-9499Å, which are tabulated at 1Å intervals.
For a preliminary evaluation I calculated models for just two MaNGA galaxies. Plateifu 10220-3703 (mangaid 1-201936; NED name WISEA J080218.38+323207.8) is a post-starburst taken from the compilation of Melnick and dePropris — one of 8 in the final MaNGA release. The other is a late type spiral, plateifu 11018-12704 (mangaid 1-233951; UGC 8162). This was a more or less random choice drawn from a sample that was intended to be a high purity selection of MaNGA face on spirals based on Galaxy Zoo classifications and NSA axis ratios. These two span the range of galaxy types that I’m likely to want to examine in the near future.
2MASX J08021836+3232078 – MaNGA plateifu 10220-3703 (mangaid 1-201936)UGC 8162 – MaNGA plateifu 11018-12704 (mangaid 1-233951)
I’m just going to look at a few results of model runs. Execution times, convergence diagnostics, and fits to the data as measured by summed log-likelihoods were all similar so there’s no strong reason to favor one library based on those criteria.
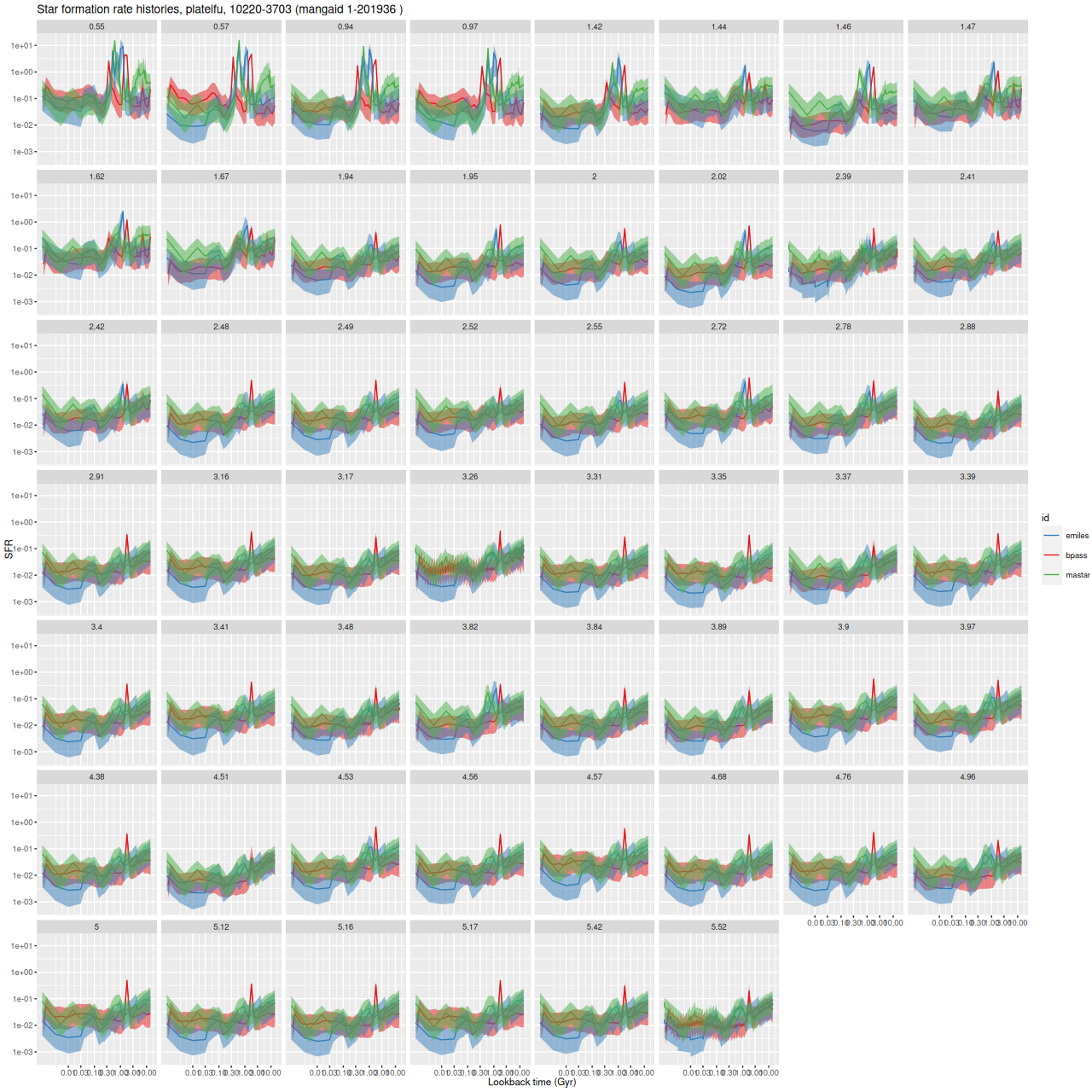
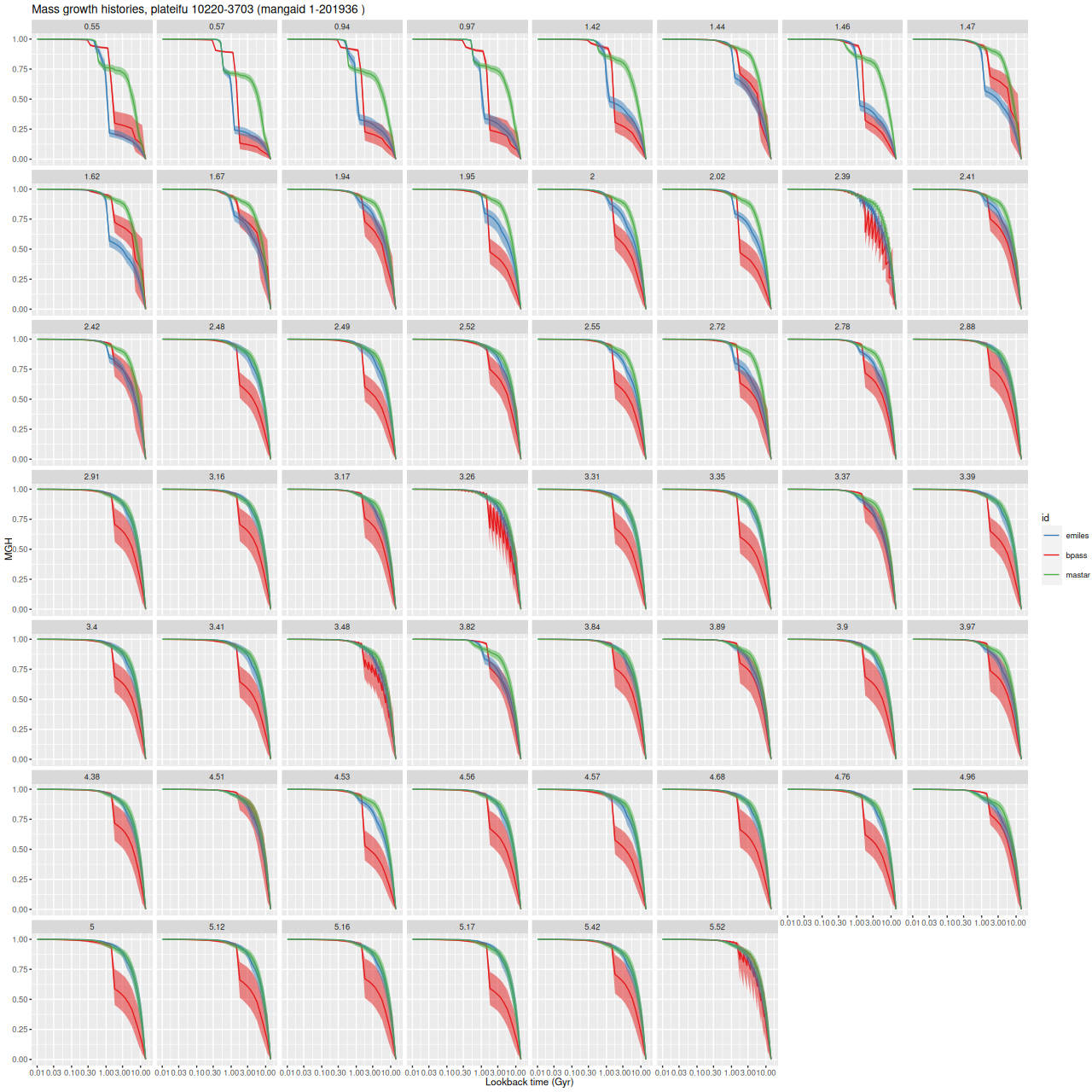
Turning first to the post-starburst galaxy 2MASX J08021836+3232078, here are model star formation rate histories for all binned spectra and all three tested SSP libraries. The ribbons denoting the marginal 95% credible intervals of SFR mostly overlap3note these are log-log plots that span 4 orders of magnitude in star formation rate, which is encouraging, but the model mass growth histories are rather different as seen below4as something of an aside several panels show a strange zigzag pattern. This is a rendering issue with the graphics software rather than a sampling problem. Note in particular that the mass growth histories by construction are monotonic.
Comparison of model star formation rate histories from 3 different SSP model libraries – all binned spectra, MaNGA plateifu 10220-3703.Comparison of model mass growth histories from 3 different SSP model libraries – all binned spectra, MaNGA plateifu 10220-3703.
Both the EMILES and BPASS models have a strong, centrally concentrated quenched starburst with two peaks, but with slightly different timing. The MaStar based models on the other hand show a long period of quiet evolution with a later and weaker starburst in the central region. A very peculiar feature of the BPASS models is a spike in SFR in almost every model run at logT = 9.2 (1.6 Gyr). A little more on this below.
There are some fairly large differences in summary quantities I track. The average stellar mass density is 0.14 ± 0.05 dex larger in the MaStar based models than EMILES, while it’s 0.12 ± 0.05 dex smaller in the BPASS models. The (100 Myr average) star formation rate density is 0.3 ± 0.1 dex larger in the MaStar models and 0.09 ± 0.16 dex larger in the BPASS models. The BPASS models have greater optical depths of dust attenuation (by 0.14 on average) and redder attenuation curves (<δ> ≈ 0.5). This may indicate that the BPASS spectra still have bluer continua than EMILES.
Turning to the spiral, here are the same two sets of plots for UGC 8162. Again the model SFR histories overlap and all three indicate roughly constant star formation over cosmic history with perhaps even slightly increasing in the outskirts. Close examination of the mass growth histories show the MaStar based models favor slightly faster early time growth than the other two.
Comparison of model star formation rate histories from 3 different SSP model libraries – all binned spectra, MaNGA plateifu 11018-12704.Comparison of model mass growth histories from 3 different SSP model libraries – all binned spectra, MaNGA plateifu 11018-12704.
Although less obvious many of the BPASS model runs have a distinct spike in SFR at the same 1.6 Gyr as in the post-starburst models. In some of the spectra it’s strong enough to contribute significantly to the present day stellar mass. A few other peculiarities are harder to see. The MaStar models invariably have an upturn in SFR at the youngest age (1 Myr), while the BPASS models invariably have a sharp downturn at the youngest age.
There are similar offsets in stellar mass densities to the post-starburst, by 0.12 and -0.14 ± 0.03 in MaStar and BPASS respectively. The mean star formation rate densities are 0.25 ± 0.05 larger in MaSTar but 0.18 ± 0.07 dex lower in BPASS models.
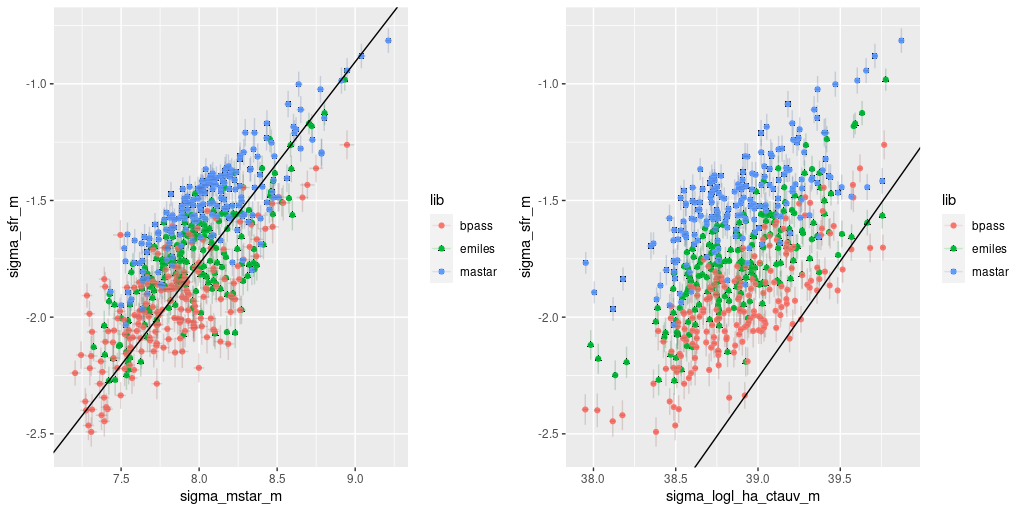
For a quick look at how these model differences affect some key relationships, below are plots of the mean (and standard deviations) of SFR density against stellar mass density (L) and SFR density vs. Hα luminosity density (corrected for estimated stellar attenuation only) (R) for UGC 8162. The straight lines are my estimate of the “star forming main sequence”, and on the right the Calzetti calibration. As expected the models straddle the “spatially resolved star forming main sequence” that I estimated previously5data for this galaxy was recently downloaded and the model results did not contribute to my estimate.. Note that since the BPASS model estimates of both SFR and stellar mass are offset by similar amounts from the EMILES based models the points are just shifted downward along essentially the same relationship. The MaStar based models appear slightly offset to higher SFR values at a given stellar mass density. On the right, there’s a fairly clear stratification. The Hα luminosity estimates are nearly identical for all 3 sets of model runs, so we see the differences in SFR density estimates.
MaNGA plateifu 11018-12740
Model results from 3 SSP libraries
(L) SFR density vs. stellar mass density
(R) SFR density vs. Hα luminosity density corrected for stellar attenuation
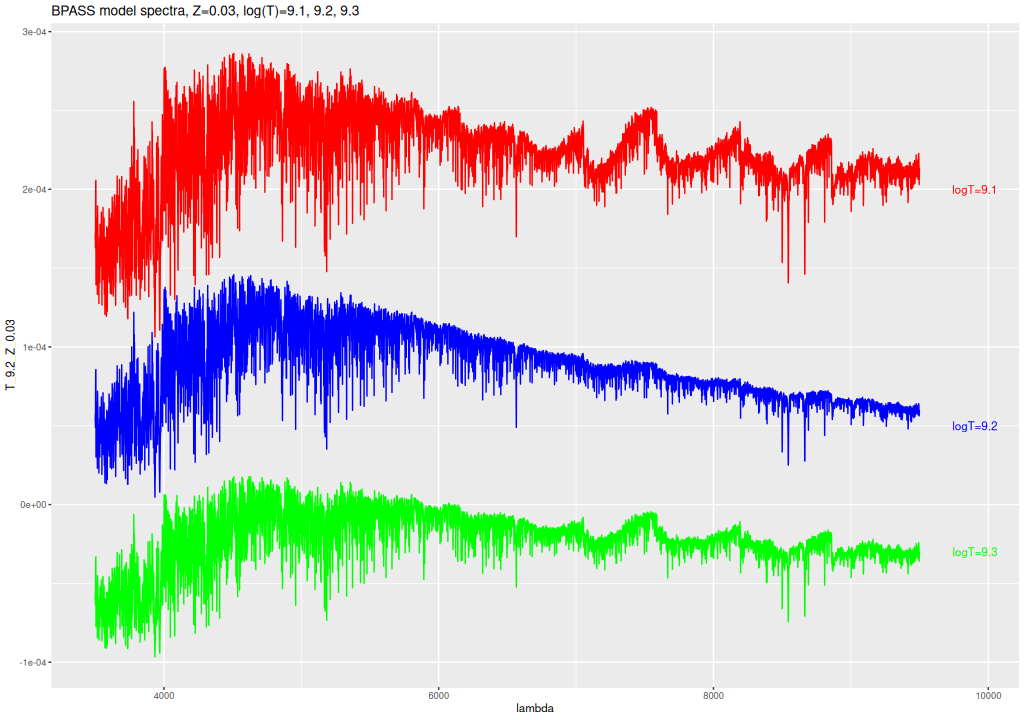
I don’t really have an explanation for the 1.6 Gyr spike in the BPASS models. It’s happening in the two super-solar metallicity bins, which track with the others for both younger and older ages. One possible clue is in their spectra. The broad absorption features in the red are considerably deeper at both younger and older ages6spectra are offset vertically for clarity.. Whether there’s a physical reason for this and why it would affect the models as seen is unknown to me.
BPASS SSP model spectra for Z=0.03, T=1.25, 1.6, and 2 Gyr
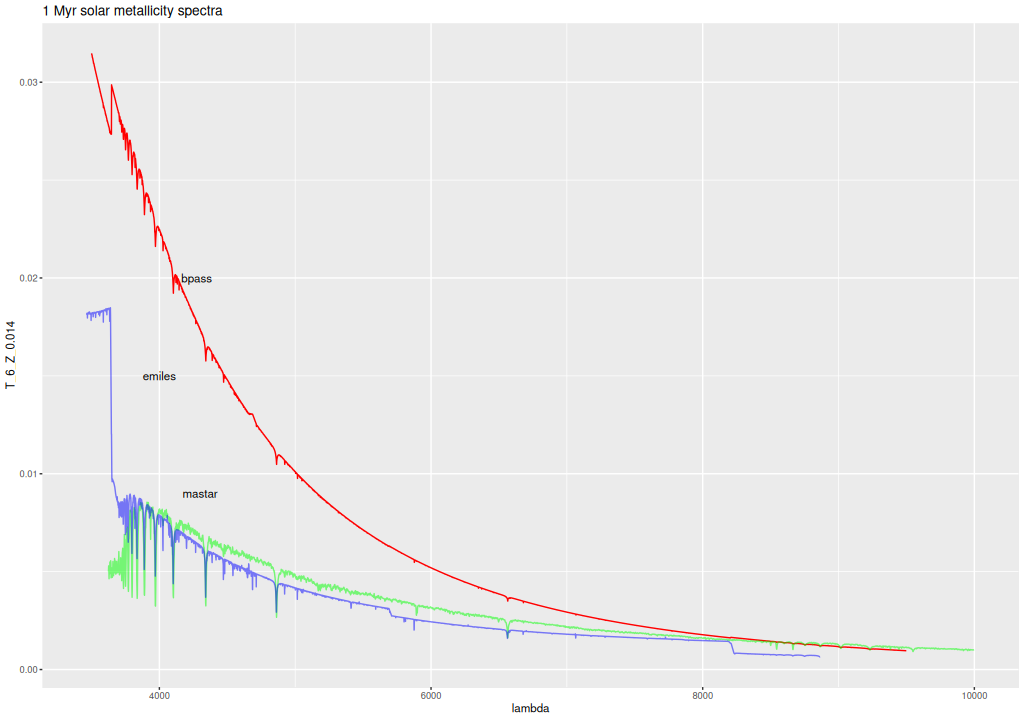
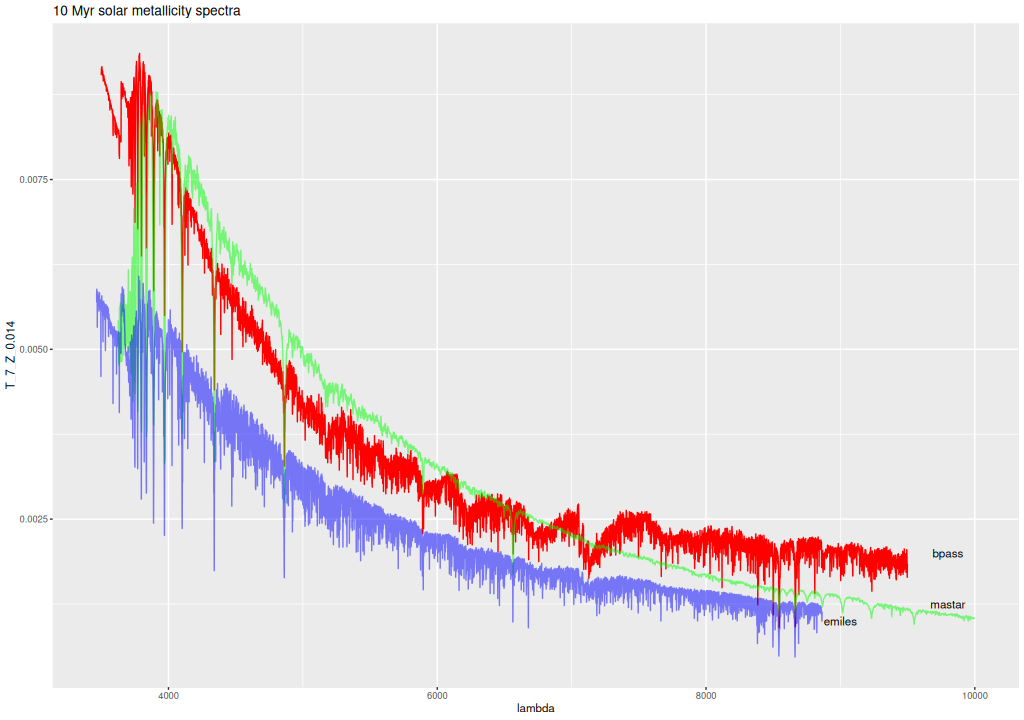
There are some notable differences among the libraries at young ages at well. Below are plotted the 1 and 10 Myr spectra at solar metallicity for the 3 libraries. The “EMILES” spectra recall are from the theoretical PyPopstar models with continuum emission included. The BPASS model is considerably more luminous and bluer at 1Myr than the other two and evolves more rapidly at young ages. Is this because I chose the models with 300 M☉ upper mass limit? I should find out.
BPASS, EMILES, and MaStar solar metallicity model spectra at 1MyrBPASS, EMILES, and MaStar solar metallicity model spectra at 10 Myr
To conclude for now I haven’t quite decided what to replace my existing EMILES models with, if anything. I’m still optimistic that an MaStar based library is the way to go, but the version published by Sanchez et al. isn’t quite ready for production use. I may consider developing my own library although it’s outside the scope of my interests.
When I was doing my initial fits to the M31 MaNGA spectra I noted two that I initially thought were contaminated by foreground stars, and therefore I masked them to prevent further analysis. One of the two, in MaNGA plateifu 9677-12701 (mangaid 52-8) is a certain foreground star and won’t be discussed further. The other, in plateifu 9678-12703 (mangaid 52-23), turns out to be a luminous red supergiant that’s a genuine resident of M31. This is confirmed by two nearly contemporaneous catalogs of M31 red supergiants: the one by Ren et al. (2021) that I noted previously and Massey et al. (2021), which I stumbled upon more recently.
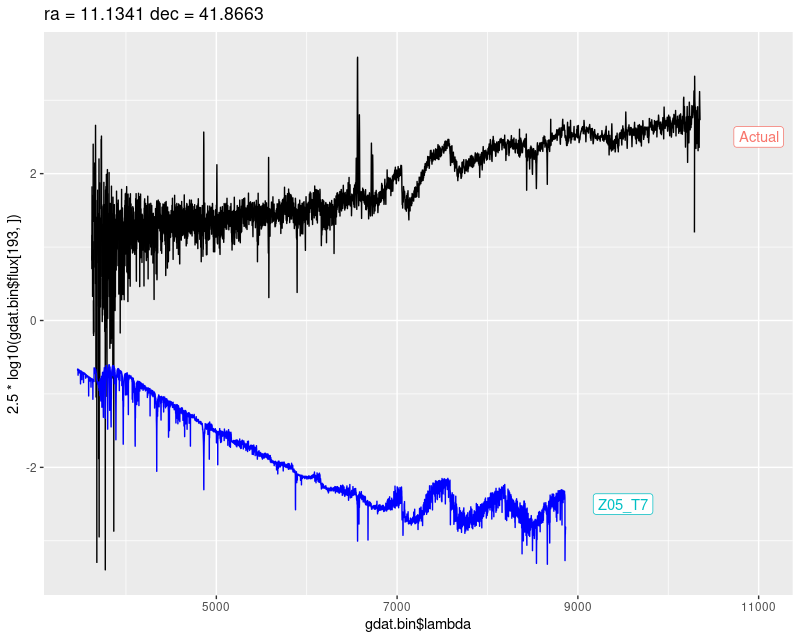
In fact there are two comparably bright red supergiants in this IFU. One that’s about 9″ north of the masked one probably should have been masked by whatever criteria I used, but it’s likely I failed to notice the fit to the data since I don’t have the patience to look at every spectrum and data fit that pops up. So, here is the spectrum, displayed in (negative) magnitudes with arbitrary zero point. The blue spectrum is the closest match in my SSP library, a 10 Myr old population with the highest metallicity I used (2.5 Z☉. This is one of the theoretical spectra from PyPopstar). This sorta looks right except it’s much too blue. The solution to that is, of course, to add some reddening through dust attenuation.
plateifu 9678-12703 (M31 10 kpc ring)
Spectrum contaminated with red supergiant and closest match SSP model spectrum
The maximum likelihood (non-negative weighted least squares) fit did just that, with only a single stellar contributor and a very high dust attenuation of τV = 3.0. This still doesn’t quite work: the residuals are rather strongly sloped in the blue and the details of the absorption features in the red aren’t quite right.
plateifu 9678-12703 – NNLS fit to spectrum contaminated with red supergiant
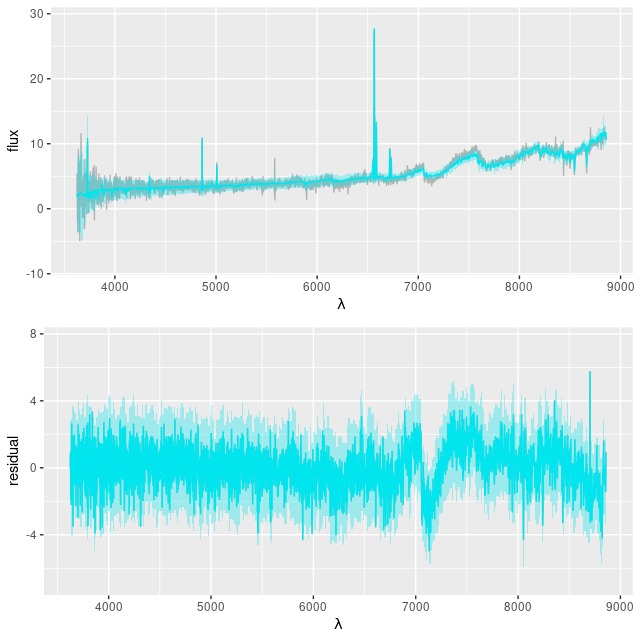
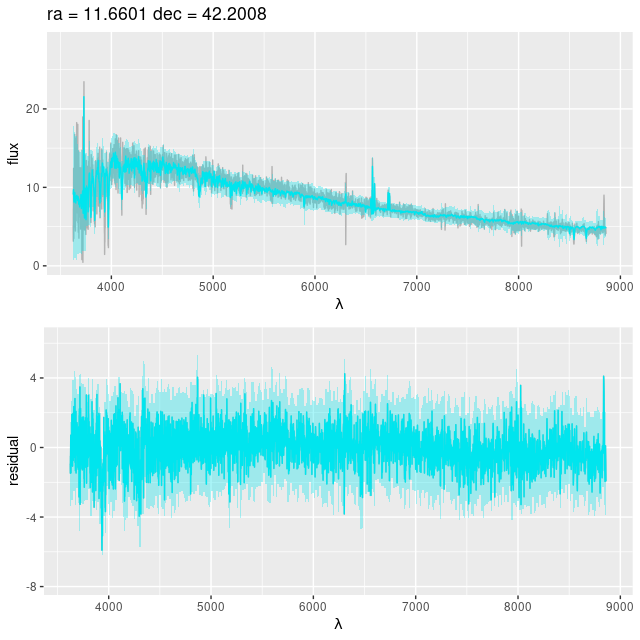
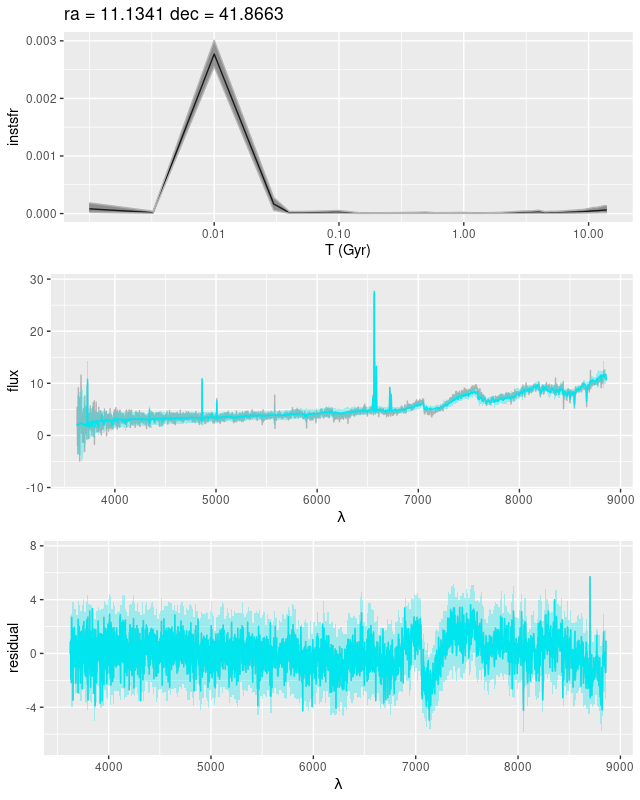
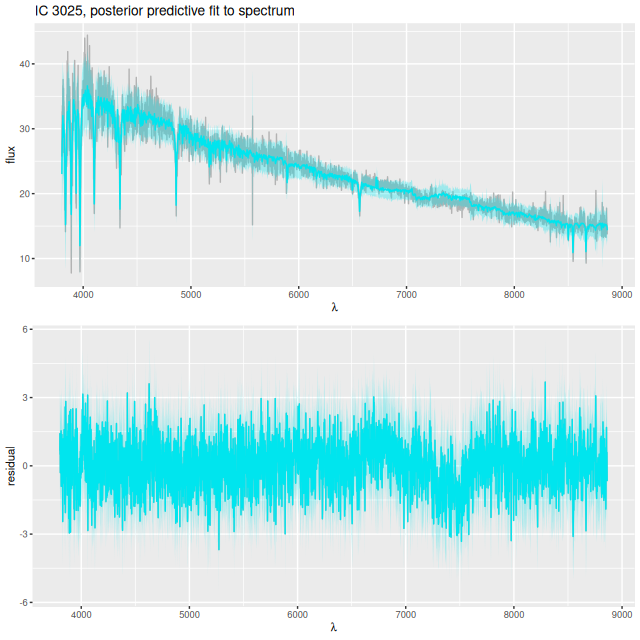
I still use a Calzetti attenuation relation in my NNLS fits. The Bayesian fits using Stan have the more flexible attenuation prescription that I described back in this post, and that helped considerably with the continuum as seen in the plot below. The absorption features in the red still aren’t fit well. The model has an even more extreme attenuation estimate with a much “grayer” than Calzetti slope, with τV = 4.38 ± 0.05 and δ = -0.33 ± 0.011see the link above for the meaning of these parameters.
9678-12703 – posterior predictive fit to spectrum
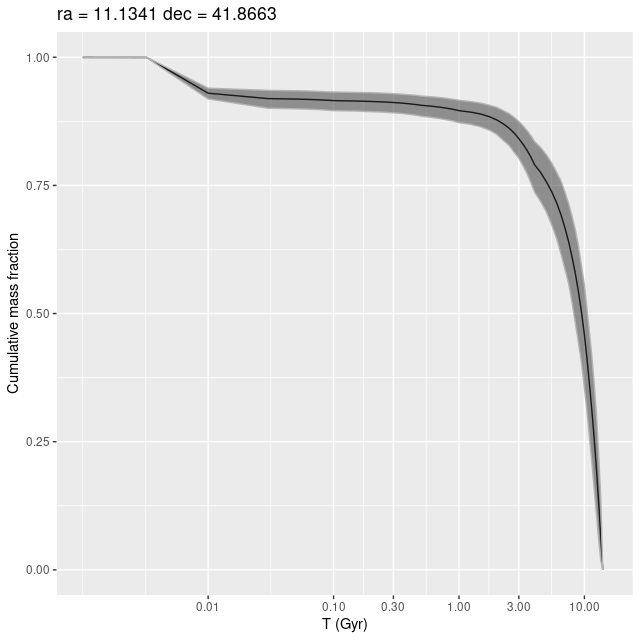
The model star formation history (displayed as a mass growth history below) isn’t completely implausible. The presence of a very luminous evolved star indicates the region is at least some Myr old, and a rapid onset and decline of star formation is typical for star forming regions in mature spirals. The recent episode of star formation added about 7% to the present day stellar mass, while at least 60% was in place by 8 Gyr ago (per the model).
plateifu 9678-12703 (M31 10 kpc ring)
Model mass growth history for a region containing a bright red supergiant
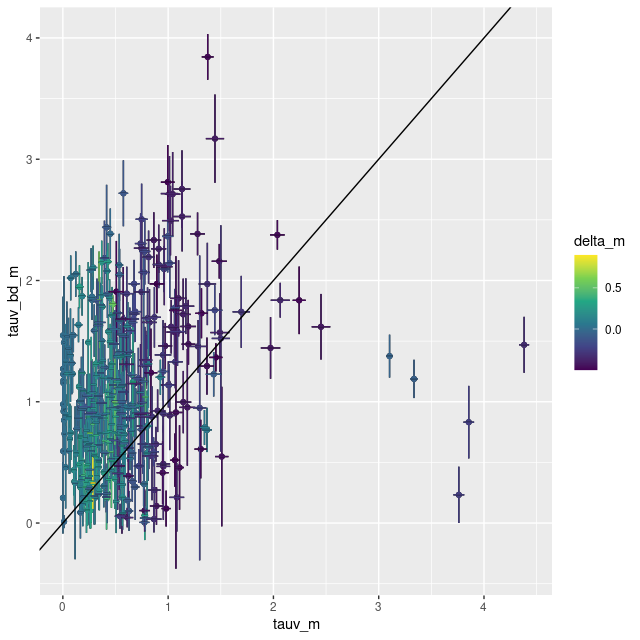
Nevertheless I consider the model results to be highly suspect, mainly based on the very large optical depth. Massey estimates the attenuation for the red supergiant to be AV ≈ 1.18, although this is apparently based on a formula rather than a direct empirical estimate. But another piece of evidence that’s close to a smoking gun is an estimate based on the Balmer decrement of emission. Despite the lack of apparent ionizing sources outside the bright H II regions in the west there is widespread diffuse emission in this region with star-forming like line ratios. The estimated optical depth derived from the Balmer decrement for this region is τV, bd = 1.47 ± 0.23 (1σ), reasonably consistent with the Massey estimate and with the values derived for the rest of the IFU.
How widespread a problem is this? Below I plot the Balmer decrement derived optical depths against the stellar based estimates for all spectra in M31 MaNGA with star forming emission line ratios, about 11% of the entire sample. The 5 most extreme outliers are in this IFU in the regions surrounding the two bright red supergiants (the masked spectrum would also be in this region of the plot). The same 5 regions are also extreme outliers in the SFR vs. stellar mass and SFR vs. Hα plots that I showed early on. So, even though there are many cataloged supergiants in the study region these two appear to be uniquely bright and to have had the largest impact on model results.
M31 MaNGA – Optical depth off attenuation estimated from Balmer decrement vs. model values of τV
Of course there are hotter bright stars in the study area and these could affect results in different and possibly unexpected ways. For example the outermost IFU contains one bright star that GAIA estimates has a surface temperature of 5500 C, which would make it a G supergiant if it’s in M31. I noted in the last post that the model star formation history for that region looks like a post starburst with an age around 800 Myr. This is, I think, several galactic rotation periods, and stars born that long ago should have dispersed by now unless they’re gravitationally bound. There’s no sign of a star cluster there nor is there a cataloged one nearby, so it seems likely to me that the “starburst” is an artifact. As I noted in the last post though the fit to the data is quite good.
These examples illustrate an issue that’s fairly well known, which is that using simple stellar populations as building blocks of low mass stellar systems are potentially affected by so-called “stochastic” effects, which simply means that the distribution of stellar masses can vary randomly from what’s assumed in the SSP models. Specifically, in M31 there are individual stars luminous enough to affect spectra. One possible solution might be to add some stellar spectra to the library. I might give that a try some day.
I’m going away and won’t be writing for a while. I’m hoping to acquire or build a SSP model library based on SDSS MaStar spectra yet this year. This is a much larger collection of stellar spectra than has been previously available and it has the advantage of having the same flux calibration and (approximately) spectral resolution as the SDSS galaxy spectra. I also plan to return to my study of post-starburst galaxies.
On to the final batch, which I don’t think is going to be very interesting.
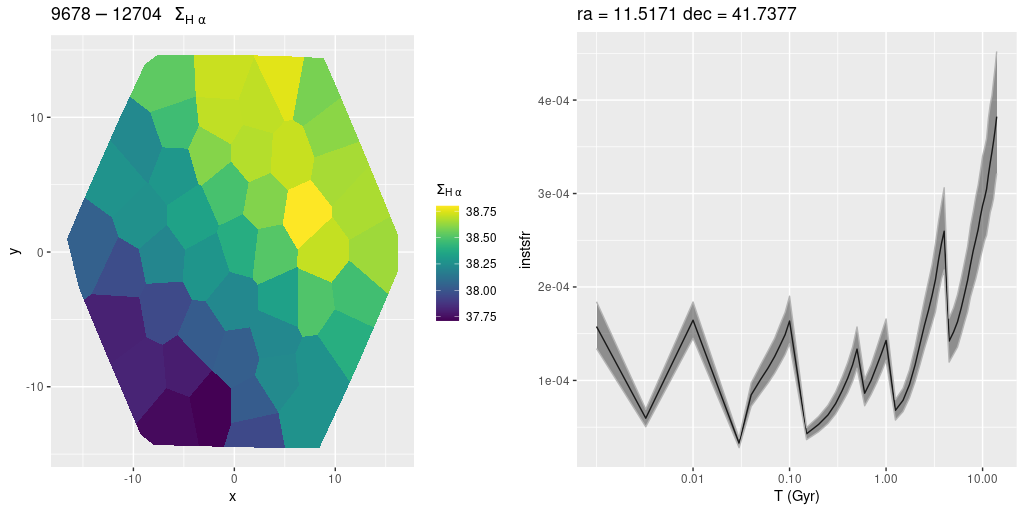
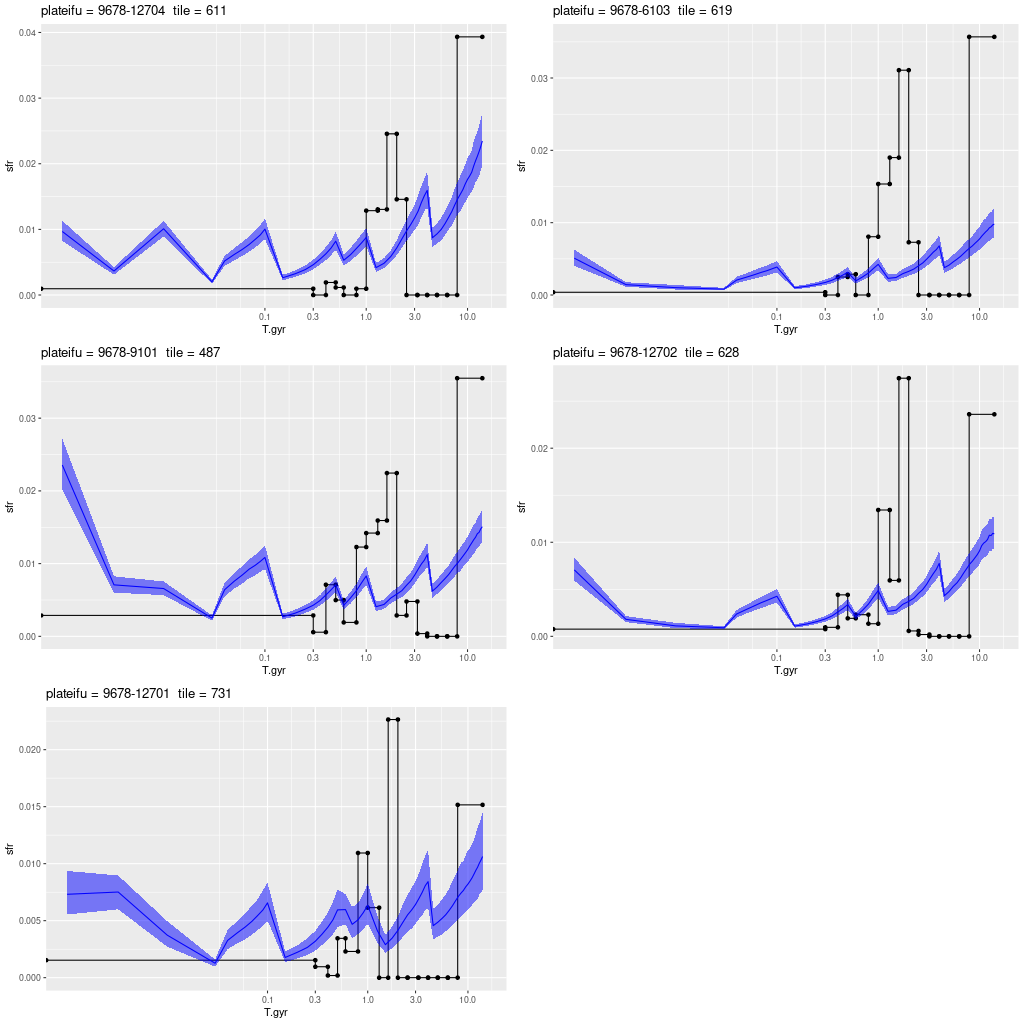
plateifu 9678-12704 (mangaid 52-22)
If my calculations reported in the last post are correct this is well in the outer disk at a distance of about 15.4 kpc from the nucleus. Other than that there’s nothing much to say about it. There are no cataloged objects of interest in the IFU footprint. There is diffuse emission with a fairly strong gradient decreasing from northwest to southeast, which is basically moving outward in the disk. There may be low level ongoing star formation.
plateifu 9678-12704 (M31 outer)
(L) Hα luminosity density (uncorrected)
(R) SFH summed over IFU footprint
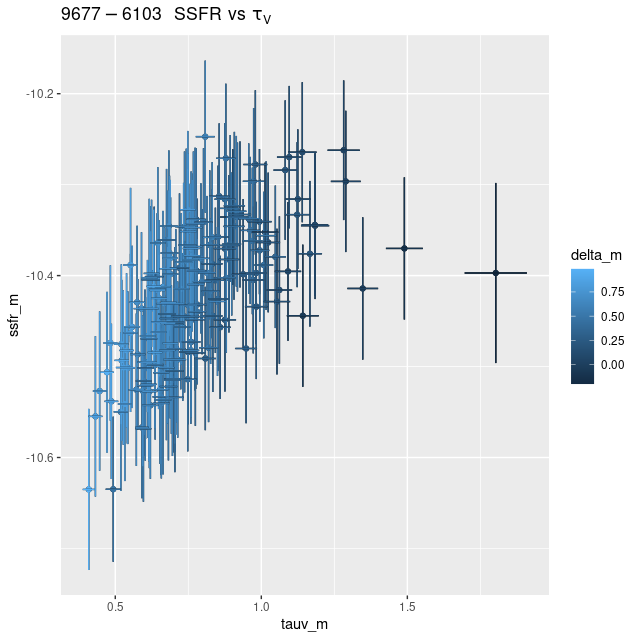
plateifus 9678-6103 and 9678-12702 (mangaid 52-19 and 52-24)
These are both in interarm regions with absolutely no cataloged objects of interest and complete blanks in the Galex false color image. Even diffuse emission is too weak to detect confidently. All regions in both show very low recent star formation with a long period of quiescence.
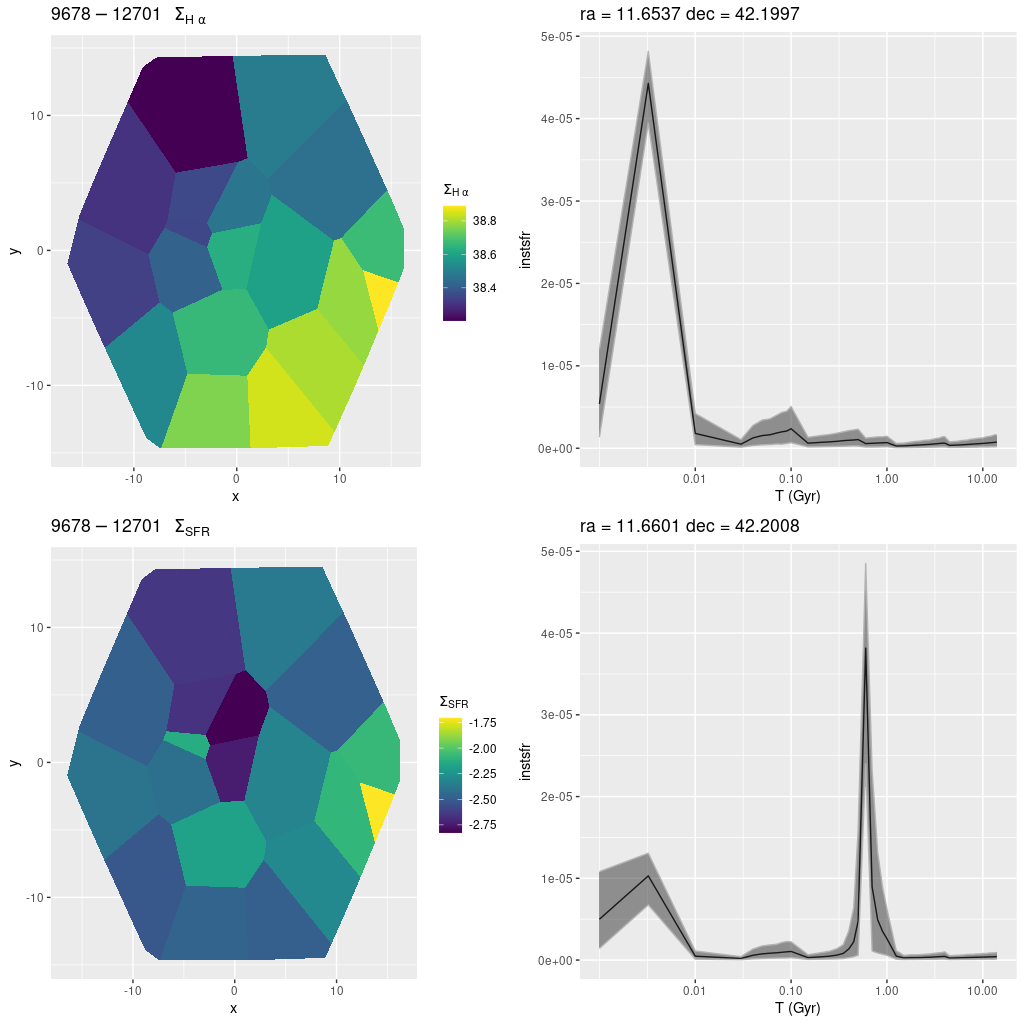
plateifu 9678-12701 (mangaid 52-25)
Finally, this is the outermost IFU in the program, located an estimated 15.7 kpc from the nucleus and very close to the major axis. Somewhat oddly it’s close to the most vigorously star forming region in this segment of the outer disk but offset by a little more than an IFU width. In fact in the Galex image it appears to be in a sort of notch with few UV bright sources.
MaNGA plateifu 9678-12701 (M31 outer disk)
Cutout from PHAT color image retrieved in Aladin.
No H II regions are cataloged within the IFU footprint but there is diffuse emission throughout with mostly starforming-like line ratios. The region with the highest modeled star formation rate is in the western corner of the IFU, where a number of blue stars can be seen in the PHAT color cutout. There is a single, somewhat isolated bright star near the center of the IFU. The SFH model for that region is in the lower right panel below. The model indicates a rather strong and short burst of star formation a little less than a Gyr ago. How much the model is influenced by the star is hard to say. The fit to the data is actually rather good. The star may be in the foreground: In Gaia DR3 (data retrieved through Aladin) its distance is listed as 2395 pc, which would obviously place it in the Galaxy. But that is based on estimates of its surface temperature and gravity rather than parallax, which is measured as negative and consistent with 0.
MaNGA plateifu 9678-12701 (M31 outer disk)
(TL) Hα luminosity density (uncorrected)
(BL) model star formation rate density
(TR) Star formation history for region with highest SFR density
(BR) SFH for a region with a bright starMaNGA plateifu 9678-12701 (M31 outer disk)
posterior predictive fit to the spectrum of a region with a bright star
After looking through all the data again I have to say I’m puzzled by some of the choices of IFU locations. All but 5 are in or very close to spiral features visible in Galex, but most are offset by as little as an IFU width from regions with more star forming activity. Even plateifu 9678-12703, which is very close to the most active starforming region in the PHAT coverage area, only captures the edge of a series of bright H II regions.
Overall I think the SFH models are successful with some caveats. Areas associated with bright Hα emission are generally showing increasing recent star formation rates reasonably consistent with the level of emission. It’s interesting that there are often nearby regions (separations ~10 pc or so) that have recently peaked but with high 100 Myr averaged SFR. This suggests we can actually see propagation of star formation over short distances and time scales.
A big concern is the effect of sampling small stellar mass regions, and in particular the effect of exceptionally luminous stars on model results. I plan to address this in a follow-up sometime soon.
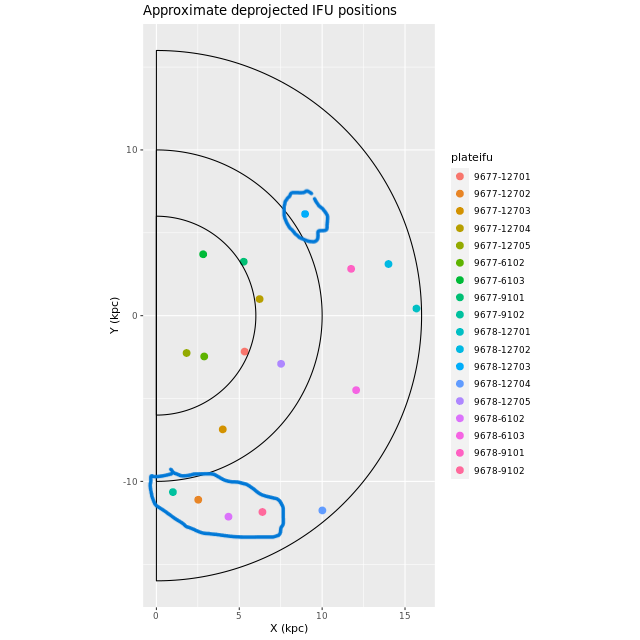
Before I get into details of the individual IFUs here is the result of a little exercise I did to estimate the deprojected positions of the IFU centers using the canonical values of 77° for the inclination and 38° for the major axis position angle, and applying the coordinate conversions I outlined way back in this post with slight modifications. These are fairly rough estimates since Andromeda’s disk is apparently warped and rather thick, but this may help give some perspective on relative positions in the plane of the galaxy. For reference I’ve drawn semcircles at 6, 10, and 16 kpc, and circled the IFUs that I had placed in the 10 kpc ring. Two of the IFUs — plateifus 9678-6102 and 9678-9102 — now appear to be at or beyond its outer edge at radii of 12.9 and 13.5 kpc, while plateifu 9678-9101 which I had assigned to the outer desk is a bit closer at 12.1 kpc. But, no matter. I will discuss them in the same order as I presented the IFU wide star formation histories several posts ago.
Approximate deprojected coordinates of M31 MaNGA IFUs. Coordinates are in kiloparsecs relative to the galaxy center, with the X axis parallel to the major axis and increasing to the northeast.
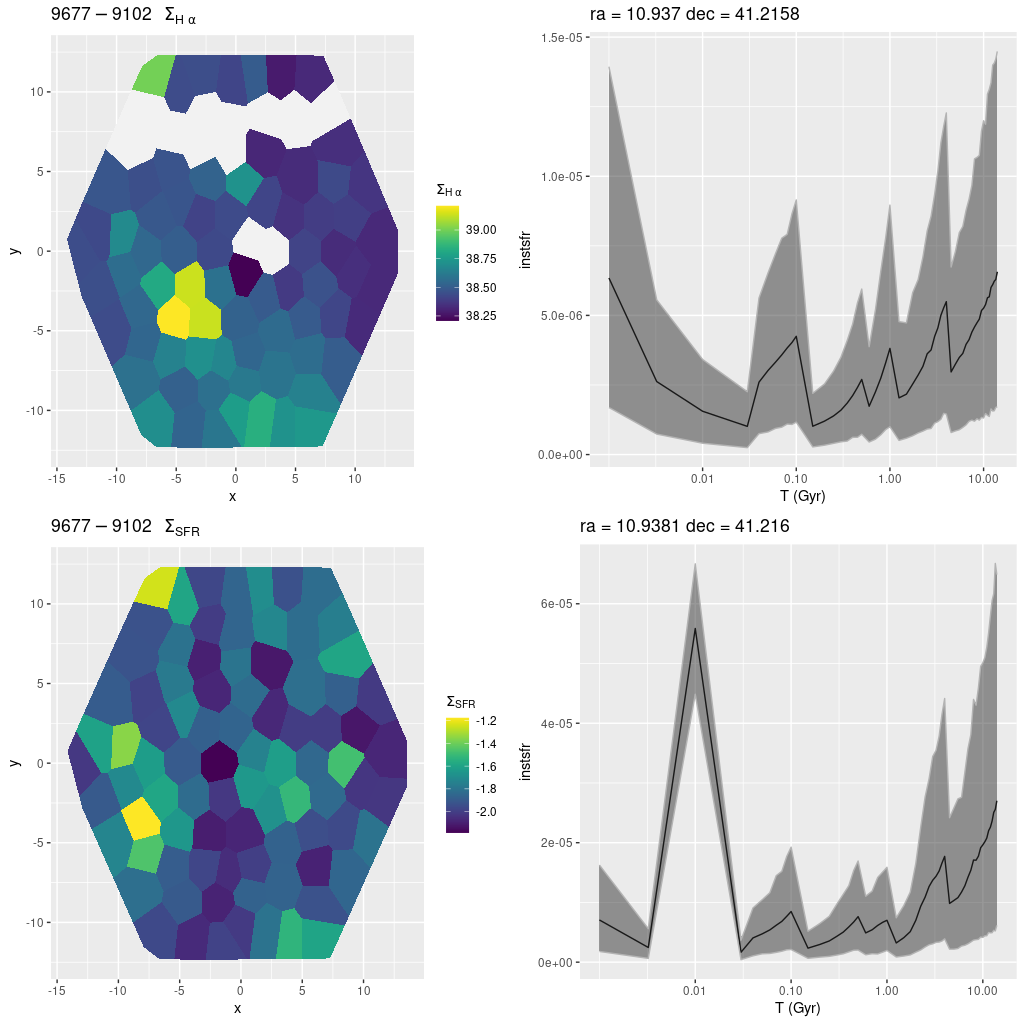
plateifu 9677-9102 (mangaid 52-1)
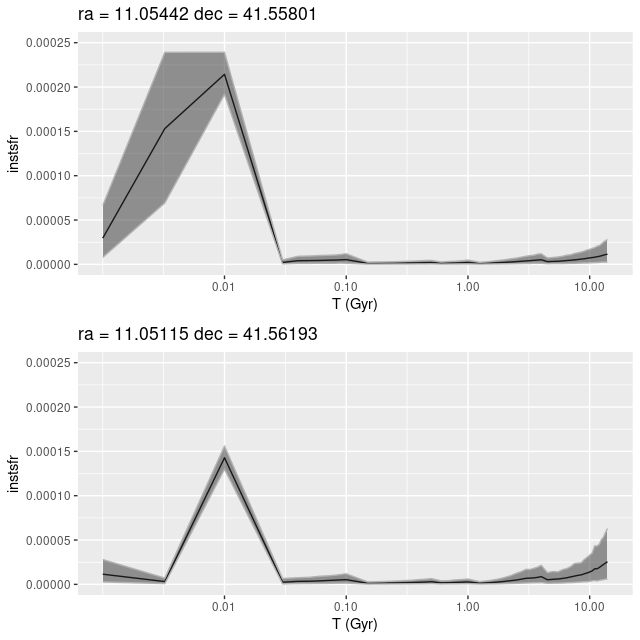
This is already a recurring theme. There is a single cataloged H II region within the IFU footprint that coincides with the highest (uncorrected) Hα luminosity density bin below. The bin with the highest (100 Myr) SFR density is displaced by several parsecs to the northeast. The first region has an increasing star formation rate over the last ~30 Myr, while the second shows a sharp peak and rapid decline over the last 10 Myr. If the models are remotely correct this is clear evidence for propagation of star formation over short distances.
plateifu 9677-9102 (M31 10 kpc ring).
(TL) Hα luminosity density.
(BL) SFR density (100 Myr average)
(TR) SFR history for the region with highest Hα density.
(BR) SFR history for the region with highest SFR density.
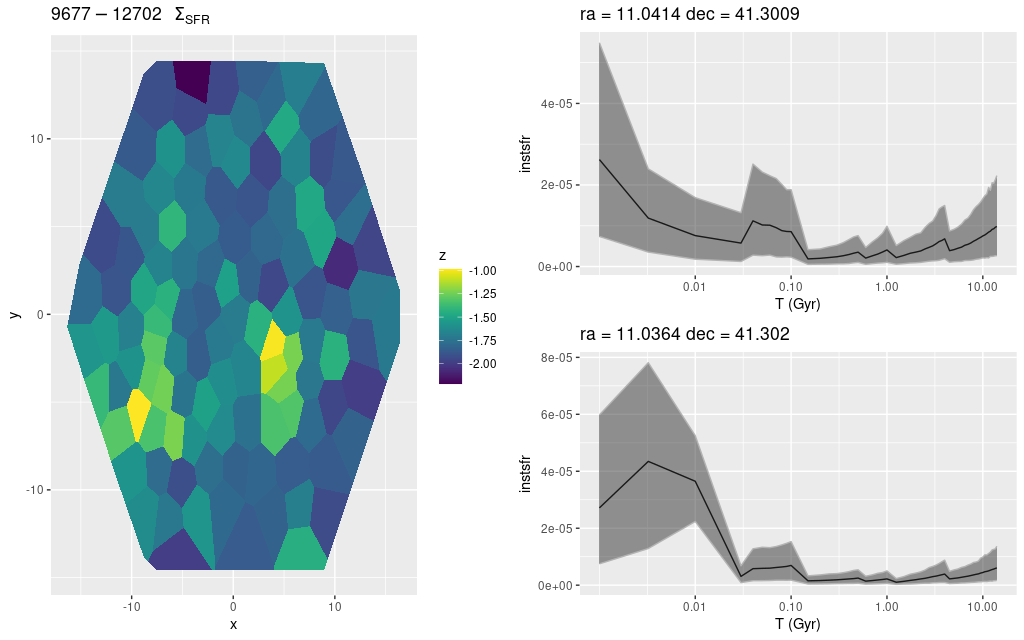
plateifu 9677-12702 (mangaid 52-7)
Despite being right in the middle of the 10 kpc ring there’s nothing very interesting in this IFU, with just a single cataloged red supergiant and a small and rather faint H II region that’s at or beyond the edge of the footprint. Only weak diffuse emission is seen in the MaNGA data. Nevertheless there are a few areas with evidence for recent star formation:
plateifu 9677-12702 (M31 10 kpc ring)
(L) map of SFR density
(R) star formation histories for 2 regions with higher than average SFR density.
I recently noticed that one of the imaging products available in Aladin is a color composite assembled from the PHAT F475W and F814W ACS/WFC observations. One thing these are good for is they give you a very rough idea of stellar temperatures. To my eyes at least stars appear orange, white, or blue. Bright blue stars must be young; bright orange ones are evolved (or reddened by dust perhaps) and might be young or old. Notice below that the two areas with relatively high star formation have a sprinkling of bright blue stars, while the bulk of the field contains predominantly orange ones.
The other optical wavelength imaging I look at comes from SDSS. Even though the imaging in this area is incomplete and the processing leaves something to be desired it does have the virtue that Hα is, at low redshift, in the r filter, which forms the green channel in their images. M31 H II regions then are identifiable by their green color. Also, red supergiants look distinctly red since their brightness is still increasing into the near IR.
plateifu 9677-12702 (M31 10 kpc ring)
Cutout of PHAT color composite taken from Aladin
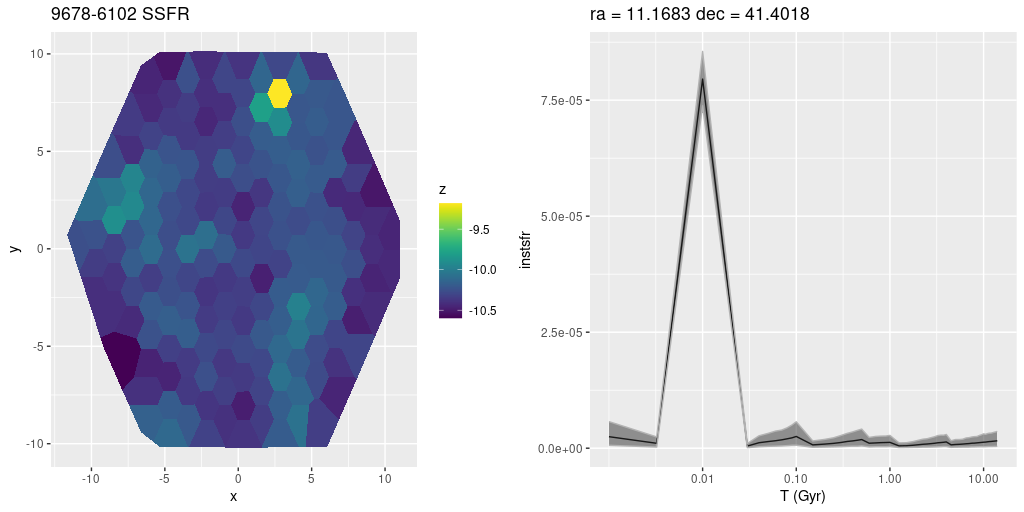
plateifu 9678-6102 (mangaid 52-20)
This lies on the outer edge of the 10 kpc ring, some distance from UV bright sources and H II regions. There is one cataloged planetary nebula and that shows up in my modeling as a region with “AGN” like emission line ratios. One fiber has a much higher modeled specific star formation rate than its surroundings. A map of SSFR and star formation history for that region are shown below. There are bright red and yellow stars in the region which might be (uncatalogued?) red supergiants.
MaNGA plateifu 9678-6102 (M31 10 kpc ring)
(L) map of model specific star formation rate
(R) star formation history for the region with highest SSFR
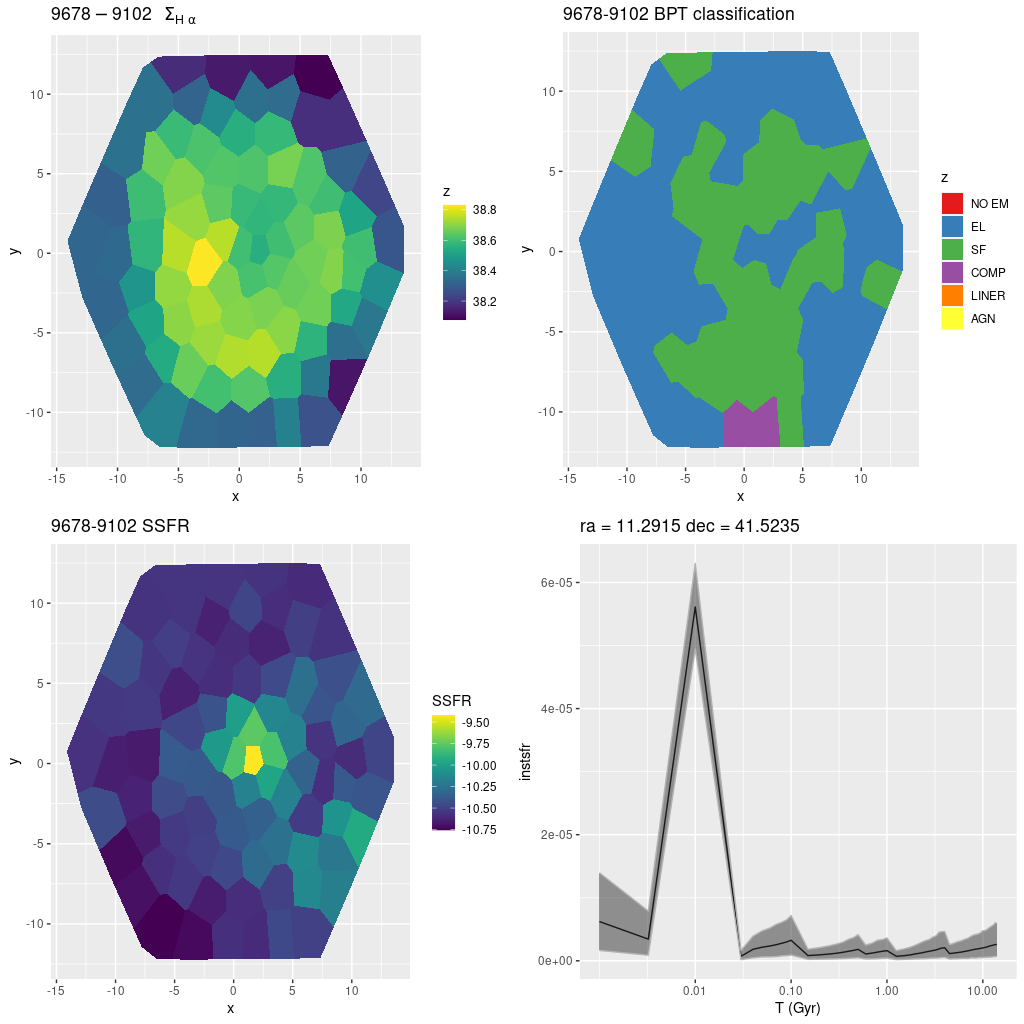
9678-9102 (mangaid 52-18)
This is the final IFU on the eastern side of the 10 kpc ring. Once again it lies at the outer edge, well away from active star forming regions. There is weak emission throughout, with star forming line ratios through much of the IFU footprint despite the lack of evident star forming regions. There’s some unresolved UV emission in the GALEX color image that roughly corresponds in location to the area of brighter Hα.
The region with the greatest recent star formation has some fairly bright blue and yellow stars in the PHAT color image
plateifu 9678-9102 (M31 10 kpc ring)
(TL) Hα luminosity density
(TR) BPT classiication by [N II]/Hα vs {O III]]/Hβ diagnostic
(BL) 100Myr average specific star formation rate
(BR) model star formation history for the region with highest SSFR
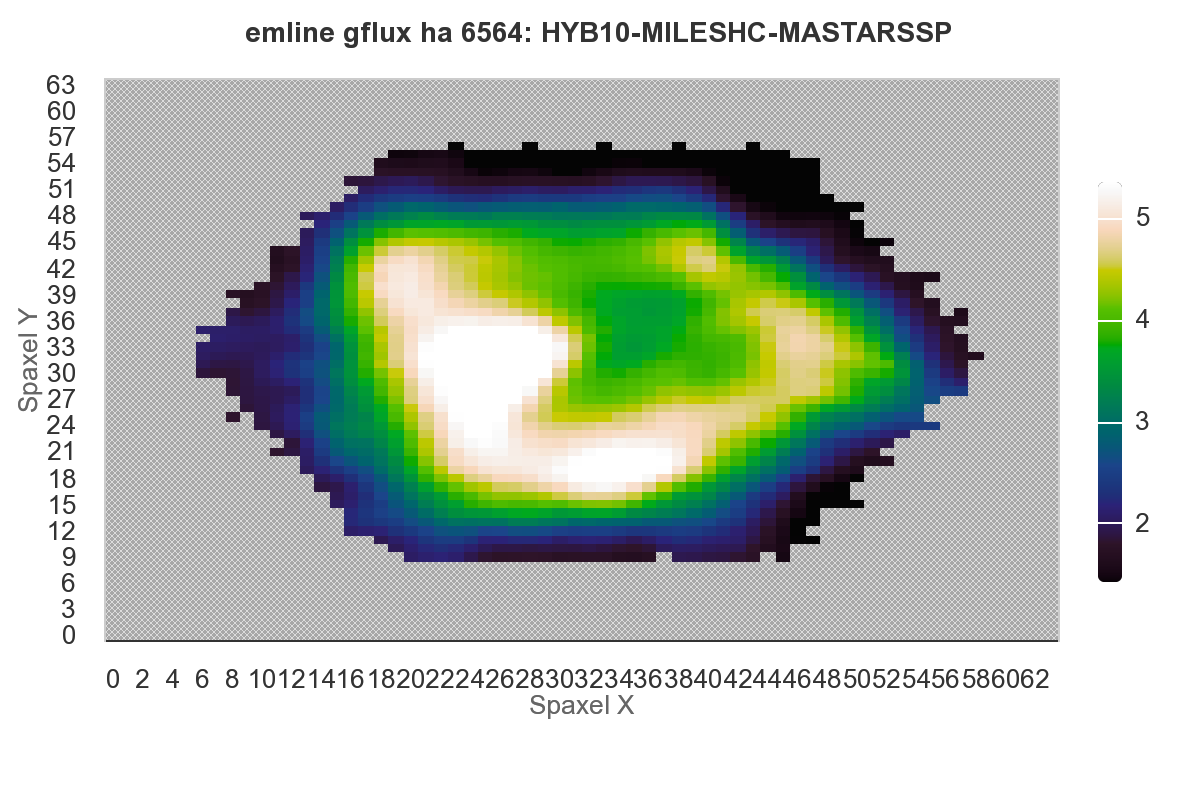
By the way I do check observational quantities in my models against the SDSS product Marvin now and then. Here’s their rendering of the Hα flux:
Qualitatively at least the agreement is excellent. I’d have to check if their fluxes are consistent with my log-luminosities.
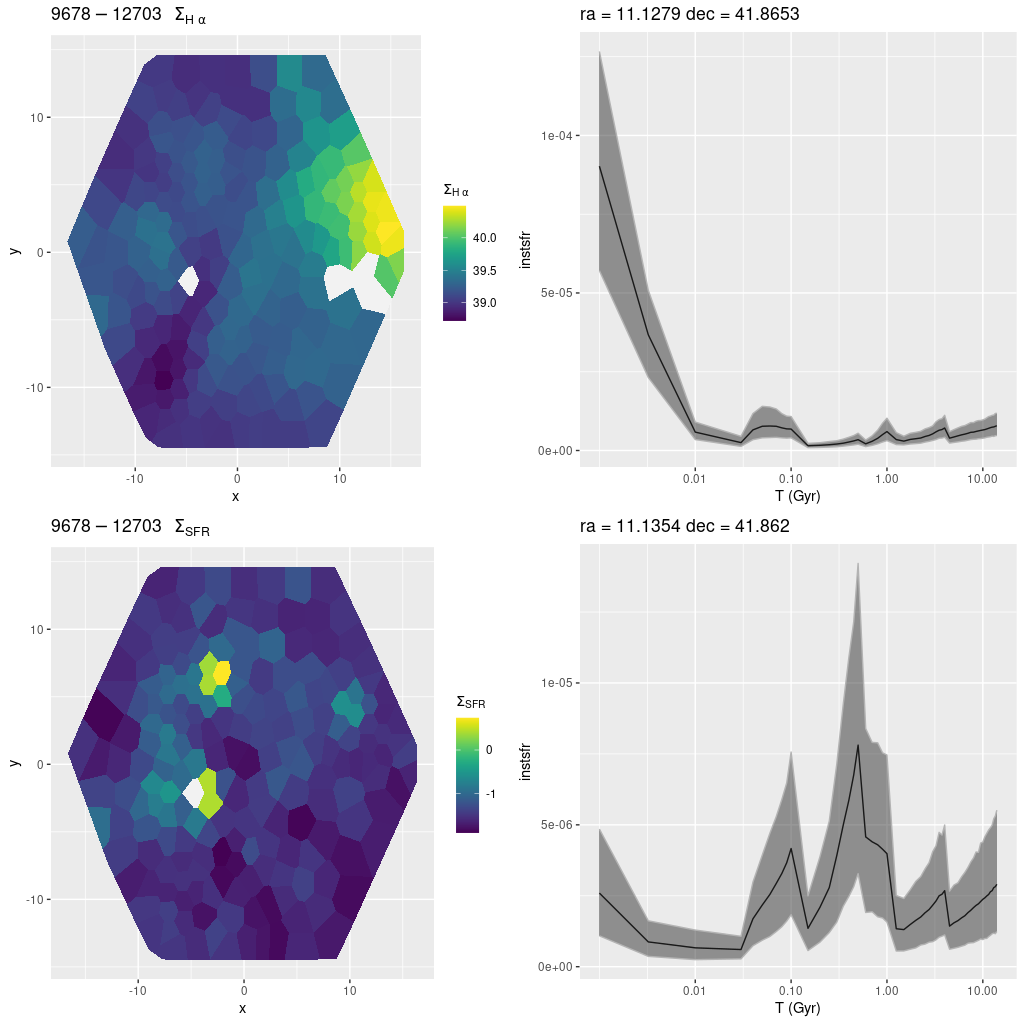
plateifu 9678-12703 (mangaid 52-23)
Finally we get to the most interesting IFU in the project, plateifu 9678-12703, which lies very close to the region with the highest recent star formation in the northeastern half of the galaxy. It also appears to coincide in position with one of the regions that Lewis et al. (2015) highlighted (their Figure 2). As can be seen in the Aladin cutouts (from SDSS and PHAT color images) below there are several young stellar objects within and near the IFU footprint: at least two red supergiants (which are a problem); 3 catalogued H II regions, one of which is bright and extended; some OB associations that are centered outside the footprint; and one open star cluster. There are a number of bright blue stars scattered throughout as can be seen in the color PHAT image.
plateifu 9678-12703 (M31 10 kpc ring)
Symbols: yellow circle: H II region
red circle: red supergiant
purple oval: star cluster
blue rhombus: OB association
blue squares: IFU outline
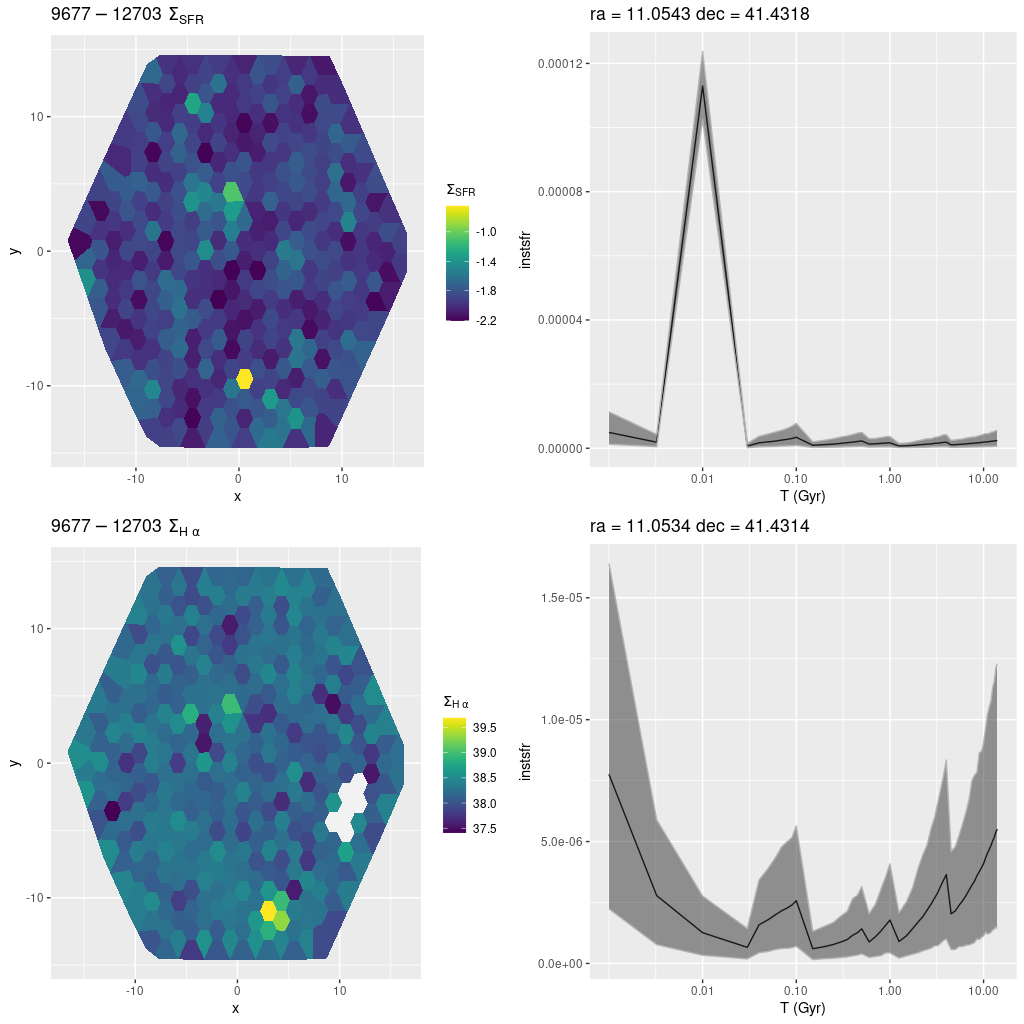
Plotted below are maps of Hα luminosity density and model star formation rate density, along with model star formation histories for two regions. The first is for the bins in the brightest part of the H II region along the western edge of the IFU. The second is for two bins at the position of a cataloged open cluster (Johnson et al. 2016) that’s fairly obvious in the PHAT cutout. The cataloged (log) age of the cluster is 8.4-0.1+0.3 with a mass around 104 M☉. The peak star formation rate in the model history below (bottom right) is at about 500 Myr lookback time with several hundred Myr of enhanced star formation, so this is pretty good agreement.
plateifu 9678-12703 (M31 10 kpc ring)
(TL) Hα luminosity density (uncorrected)
(BL) model star formation rate density
(TR) star formation history for areas with highest Hα luminosity.
(BR) SFH for a region covering a cataloged open cluster
When I did my initial fitting runs on this IFU I noticed one fit that was rather poor which I attributed to a foreground star, and therefore I masked it for subsequent analysis. It turned out though the culprit was not a foreground star but instead a local red supergiant that’s been cataloged (for example) by Ren et al. (2021). Their catalog lists its G band magnitude from Gaia DR2 as 19.1 which makes its absolute magnitude around -5.3, a reasonable value for its presumed spectral type.
This raises an issue that’s fairly well known. Simple stellar population models assume the age zero main sequence is fully occupied according to a well defined initial mass function. This is a fairly innocuous assumption (although the choice of IMF is not) when we’re sampling ~billion solar mass regions, but it’s not so innocuous for cluster size agglomerations, which is what we’re sampling here1the typical binned region has a present day stellar mass around 104 M☉ per my models. The particular problem here is that a single red supergiant is making a significant contribution to the spectrum in the red, and that could be biasing the model SFH in as yet unexplored ways.
The bin at the position of the other bright supergiant in the footprint was analyzed, so lets take a quick look. In the top pane below is the model star formation history, and in the two below the (posterior predictive) fit to the data and the residuals from same. The fit doesn’t look so bad except for a region around 7200 Å, which often seems to be a problem with EMILES spectra.
Superficially the model star formation history looks not implausible, and similar to others I’ve shown. The presence of an evolved star indicates a stellar age in the right general range, as does the relative lack of H II emission. Despite the strength of the burst it adds only about 7% to the present day stellar mass, with as elsewhere the majority of the stellar mass was in place by 8 Gyr ago (per the model, as always).
But, there’s at least one indicator of a problem: the modeled optical depth of attenuation is extraordinarily high at τV ≈ 4.4, compared to the optical depth estimated from the Balmer decrement of τVbd = 1.47 ± 0.23. I plan to discuss this in more detail in a future post, but for now I’m moving on.
plateifu 9678-12703 (M31 10 kpc ring)
model star formation history for a region with high recent SFR
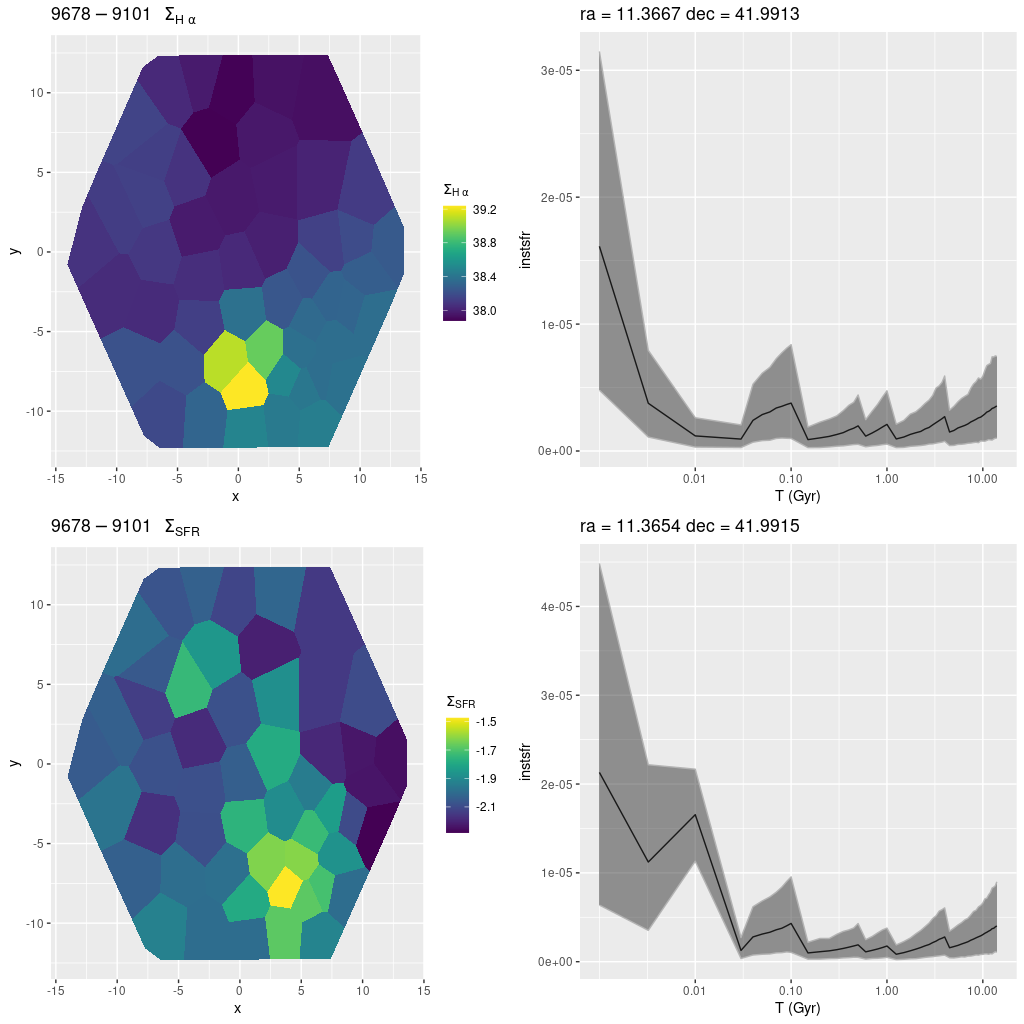
plateifu 9678-9101 (mangaid 52-26)
As mentioned at the top this appears to be in a spur off the 10 kpc ring. There is just one cataloged H II region within the footprint that appears to be compact. Just to the west there is a sprinkling of bright blue stars and an unresolved blob in the Galex color image. The H II region is evident in the map below. Once again the regions with the highest Hα luminosity and highest (100 Myr averaged) star formation rate are slightly offset from each other. The model star formation histories are very similar though.
plateifu 9678-9101 (M31 10 kpc ring)
(TL) Hα luminosity density (uncorrected)
(BL) model star formation rate density
(TR) star formation history for area with highest Hα luminosity.
(BR) SFH for area with highest recent star formation rate
I’m going to stop for now and cover the last 4 outer disk IFUs in (probably) the next post.
Instead of trying a systematic investigation I’m just going to go through each IFU and discuss whatever I found interesting, with no particular theme in mind. I still don’t really know what I’m going to find since it’s been a while since I looked at model results. Besides modeling star formation histories for each spectrum I calculate summaries in the form of posterior marginal means, standard deviations, and a few quantiles for a large number of quantities. Some of these are highly model dependent such as 100 Myr averaged star formation rates and specific star formation. Some are only weakly model dependent, such as emission line fluxes1These depend on correction for absorption, but we don’t need a believable star formation history for that, just a reasonable template match. One thing I haven’t looked at much is stellar metallicities and especially their evolution in the models. There are always contributions from all metallicity bins at all times in my models, and how to interpret them or whether even to try still puzzles me. I am starting to look more seriously at strong emission line metallicity estimates. The estimator proposed by Dopita et al. (2016) based on [N II], [S II], and Hα seems especially promising since they’re usually detected with reasonable precision in SDSS spectra.
So, the plan is to look at each IFU, working my way outward in the disk in the same order as my second post in this series.
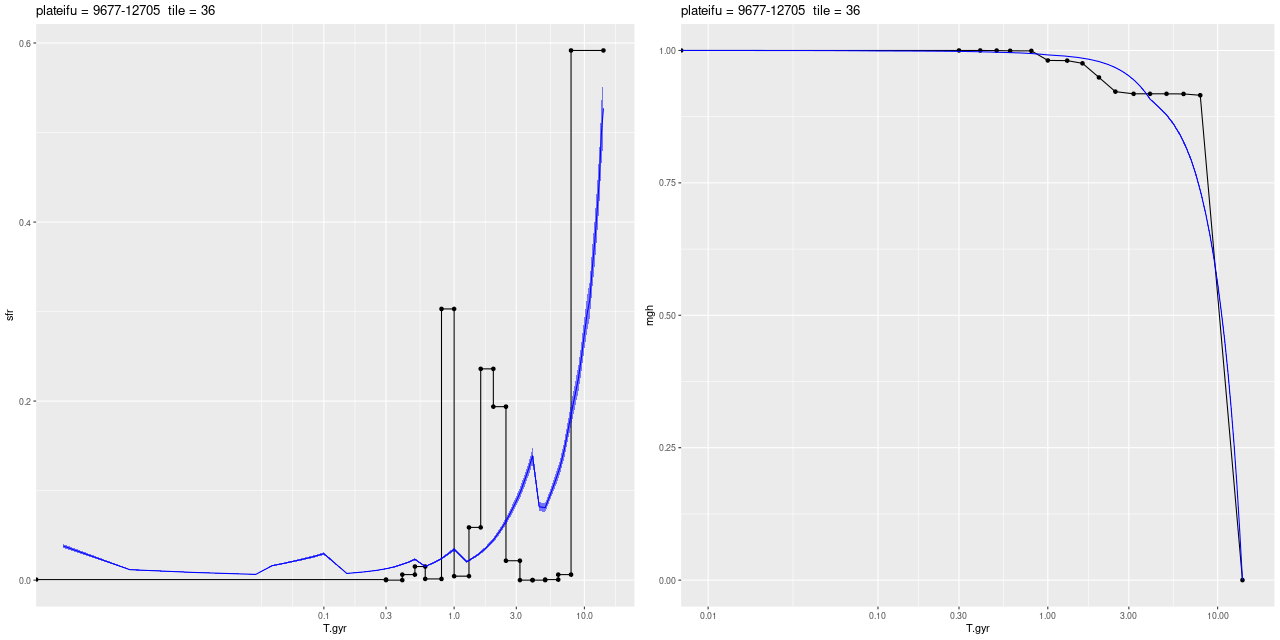
plateifu 9677-12705 (mangaid 52-4)
This is the innermost IFU with a projected distance from the nucleus of 1.9 kpc. According to Walterbos and Kennicutt (1988) the effective radius of the bulge is 2 kpc, so a significant fraction of the light is coming from bulge stars.
What’s most interesting about this IFU is what it lacks, which is any significant star formation. I also saw little spatial variation in model star formation histories, so I’ll simply repeat the IFU wide history compared to the nearest PHAT tile:
Innermost IFU 9677-12705 SFR and mass growth histories compared to models for nearest PHAT region.
This region had the most rapid initial stellar mass growth and conversely the steepest decline in SFR of any of the MaNGA IFU’s, which is completely consistent with the consensus “inside out” growth paradigm.
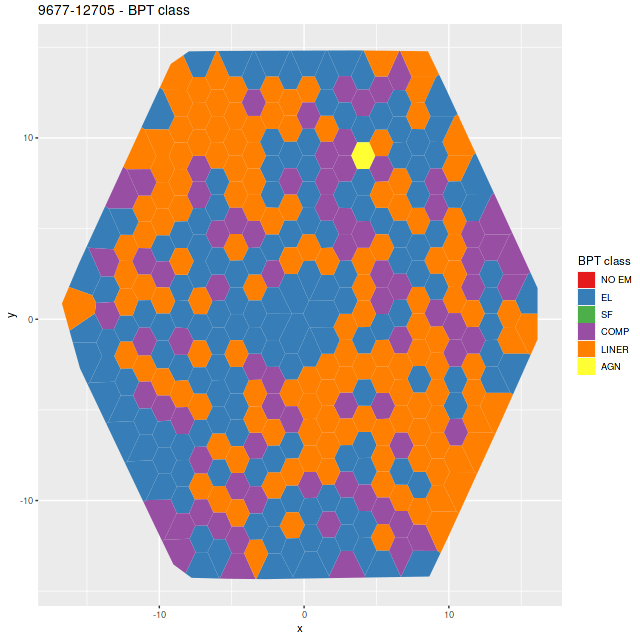
One other moderately interesting result is that despite the lack of young stars there are detectable emission lines throughout with a mix of “LINER” and composite like line ratios from the [N II]/Hα vs. [O III]/Hβ diagnostic and the classification scheme of Kauffmann with Schawinski’s addition of the LINER/AGN divide. As is well known by now LINER (and presumably “composite” although I haven’t seen literature on the issue) emission can be spatially extended and does not at all necessarily indicate ionization by an AGN. M31 has widespread emission from diffuse ionized gas. About 14% of all binned spectra had line ratios in these categories and “AGN” like, and 90% of the LINER-like spectra are in this IFU. A similar fraction of spectra have star forming emission line ratios, which reflects the patchy nature of star formation in M31.
plateifu 9677-12705 – BPT class per [N II]/Hα vs [O III]/Hβ diagnostic
plateifu 9677-6102 (mangaid 52-3)
There’s little to say about this one. The entire IFU is offset by a small amount from some GALEX UV bright sources and there are no objects in any of the catalogs I’ve loaded within the footprint. The only prominent feature is a very prominent dust lane that covers the southeastern half of the IFU. Oddly, the estimated specific star formation rate tracks the dust rather closely.
plateifu 9677-6102 (M31 inner disk). Specific star formation rate
There’s a clear correlation between SSFR and optical depth of attenuation, and also with the “tilt” of the attenuation relation:
plateifu 9677-6102 (M31 inner disk). Specific star formation rate vs. dust optical depth.
Whether this is meaningful or a modeling artifact I can’t say at this point. I kept my simple single component dust model for these runs even though M31 is known to have both a foreground screen and embedded dust.
plateifu 9677-6103 (mangaid 52-2)
This again is in a nearly featureless area except for a prominent dust lane, with no sources in any catalog I consulted. The entire IFU lacks significant emission and there is no evidence in the models for significant recent star formation. Oddly, there’s a very similar relation between model specific star formation rate and model optical depth:
plateifu 9677-6103 (M31 inner disk). Specific star formation rate vs. dust optical depth.
plateifu 9677-12701 (mangaid 52-8)
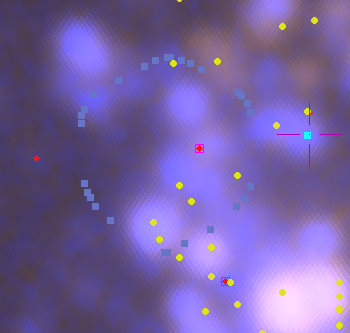
This is the closest IFU to the nucleus that lies within a significant spiral structure as seen by GALEX. The thumbnail below shows its position overlaid on the false color GALEX image available within Aladin. The IFU appears to lie in a spur off a spiral arm a little farther out2There doesn’t seem to be a strong consenus about the overall spiral structure of M31. All modern authors agree that the “10 kpc ring” is a complete ring, with a split in the south not too far from the projected position of M32. I’ve also seen references to 6 and 16 kpc rings, but others claim that various classes of young objects are strung out along a pair of logarithmic spirals. This idea goes back to early 1960’s work by Baade and Arp. I will just note IFU’s in UV bright areas in GALEX since this seems to be the best tracer of recent star formation and a number of discrete UV bright sources are visible within its footprint, which is marked with the irregular set of blue symbols. Also shown are cataloged positions of H II regions (yellow dots), red supergiants (red diamonds), and an OB association (blue square)3data sources are given in the last post. All of these are available through Aladin’s data collection.
Thumbnail of plateifu 9677-12701 (M31 inner disk) overlaid on GALEX false color image. Yellow dots: cataloged H II regions. Red dots: cataloged red supergiants. Blue square: OB association.
Let’s look at a couple of maps. The blank area at upper right was masked due to a likely foreground star. The spectra in the chain of blank areas at bottom had Hα partially masked. Units in the Hα luminosity density map are log10 ergs/sec/kpc2, uncorrected for attenuation. Units of the SFR density maps are log10 M☉/yr/kpc2.
To a pretty good approximation regions that are relatively bright in Hα track the UV bright areas and cataloged H II regions. There are two areas that stand out as having much higher than average SFR density. One, at lower left, coincides with a bright H II region. The other one, at center right, has low Hα luminosity but lies right on the cataloged position of a red supergiant. The presence of an evolved star and absence of emission suggests that star formation has recently (in the last ~70 Myr, say) ended in that area. Comparing the model star formation histories the region with little Hα emission does show a sharp drop-off after a peak at 10 Myr lookback time:
plateifu 9677-12701 (M31 inner disk) – model star formation histories for 2 star forming regions.
One other thing I’ll just note for now is that regions with the highest star formation rate tend to have neighboring regions with higher than average star formation as well. These seem to occur in clumps or chains a few 10s of parsec in size. I will get, eventually, to some more dramatic examples.
plateifu 9677-9101 (mangaid 52-9)
This and the next IFU are in a spiral segment that some authors call the “6 kpc ring,” but the GALEX false color image shows no very bright UV sources and there are no cataloged young objects within the footprint.
9677-12701 GALEX cutout
One mildly interesting result is that the modeled 100 Myr SFR density correlates rather strongly with Hα luminosity density, but an order of magnitude higher than predicted from Calzetti’s calibration. All of the emission in this region appears to be from diffuse ionized gas as there are no cataloged discrete sources of emission, and no regions with starforming line ratios. A literal interpretation of this, which might even be true, is that star formation has ceased in the recent past.
plateifu 9677-9101 (M31 inner disk). Star formation rate density vs. Hα luminosity density.
plateifu 9677-12704 (mangaid 52-5)
This is also in the 6 kpc spiral feature but in an area with no bright UV sources and that appears to be heavily dust obscured in optical images. Since I don’t have anything very interesting to say about this region I’ll just post the modeled star formation history for the region within the IFU footprint with the highest modeled SFR density. This is near the western edge of the IFU and isn’t associated with any cataloged young objects.
plateifu 9677-12704 (M31 inner disk). Star formation rate history for a region within the IFU footprint with the highest modeled recent SFR.
The region with the highest Hα luminosity is near the southwest edge and covers the position of a cataloged planetary nebula. The emission line ratios are inconsistent with a starforming region, falling in Kauffmann’s “AGN” region.
plateifu 9677-12703 (mangaid 52-6)
This and the last IFU are in an inter-line region between the 6 and 10 kpc structures as seen by GALEX, but with lots of diffuse starlight and relatively little dust. Emission lines are weak or undetected throughout, but there is a cataloged H II region near the southern edge. The peak in Hα luminosity density is easily seen in the map below in the bottom left pane. The region with the highest SFR density is displaced by ~10 pc. from the region with highest Hα luminosity. Interestingly, the SFR models show significant differences in recent histories: the region with highest SFR shows a very sharp and short lived peak at ~10 Myr, while the highest Hα luminosity region is still growing in SFR (per the model). Again, I hesitate to take these model histories too literally, especially at the youngest ages, but these are consistent with the fact that ionized gas emission will fade rather rapidly as the most massive stars in a region evolve away from the main sequence.
plateifu 9677-12703 (M31 inner disk). (TL) SFR density (100 Myr average) (BL) Hα luminosity density. (TR) SFR history for the region with highest SFR density. (BR) SFR history for the region with highest SFR Hα luminosity density.
plateifu 9678-12705 (mangaid 52-21)
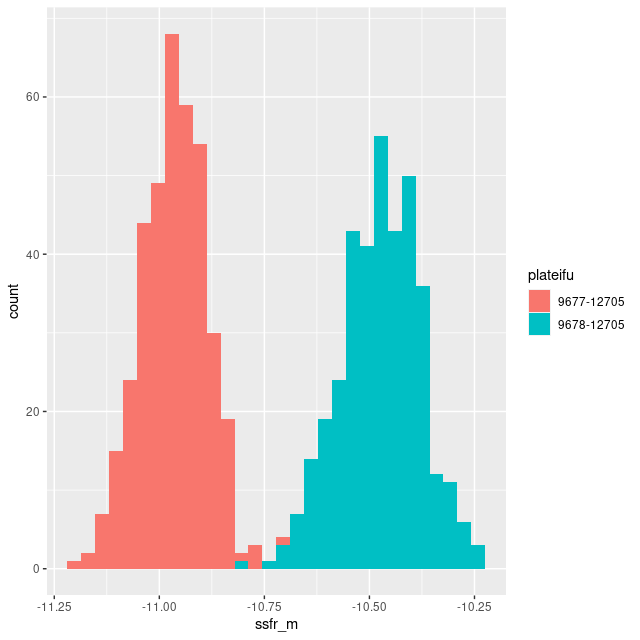
I don’t have much to say about this one either. It lies in a region that’s almost completely blank in the GALEX imaging, with a rather uniform sprinkle of stars in PHAT and the DSS2 image displayable in Aladin. Ionized gas emission is weak or undetected throughout. For the sake of having a graph to display here is a histogram of the per spectrum mean specific star formation rate (100 Myr average as always) comparing this IFU to the innermost one — plateifu 9677-12705.
Distributions of mean specific star formation rate in two MaNGA M31 IFU’s
I hope to finish off M31 in one or at most two more posts. Next up are IFUs that fall in or near the 10 kpc ring, followed by the outer disk.
After a fairly long break I want to get back to M31 and MaNGA for one, or perhaps several posts and take a more detailed look at my model results. I still haven’t decided where I’m going to take this investigation. I may examine every IFU or just the ones that I found most interesting, and I’m not sure which of the many quantities that I estimate I’ll discuss. Besides my models I’ve retrieved a number of catalogs of interesting objects using Aladin. These include in particular H II regions (Azimlu et al. 2011), OB associations (Magnier et al. 1993), and red supergiants (Ren et al. 2021). All of these are products of recent or ongoing star formation. There are of course a huge number of catalogs of just about every type of astronomical object found in galaxies, and I may examine some more depending on what interests me.
For orientation here’s a screencap of the Legacy Survey sky browser’s false color GALEX image of the northern half of M31 with the IFU positions overlaid and labelled with MaNGA’s plateifu identifiers. As a reminder these are all located within the PHAT survey footprint and specifically within the region for which star formation histories were estimated by Williams et al. (2017).
Screen capture of Legacy Survey Galex image of M31 with MaNGA IFU overlay
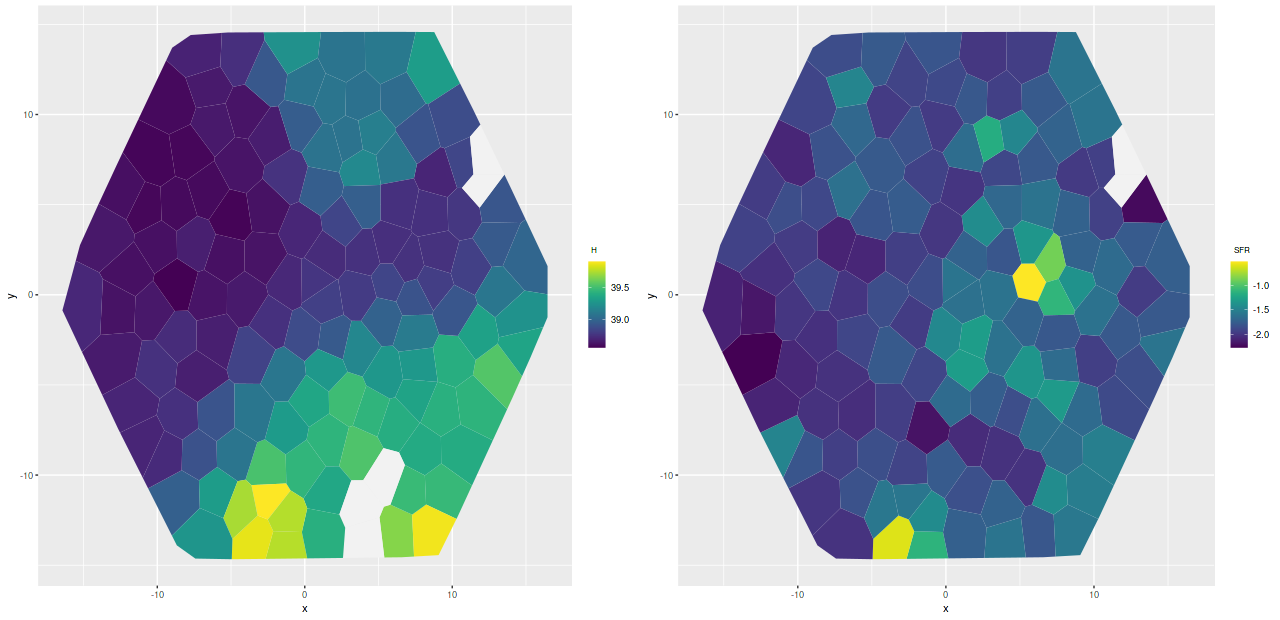
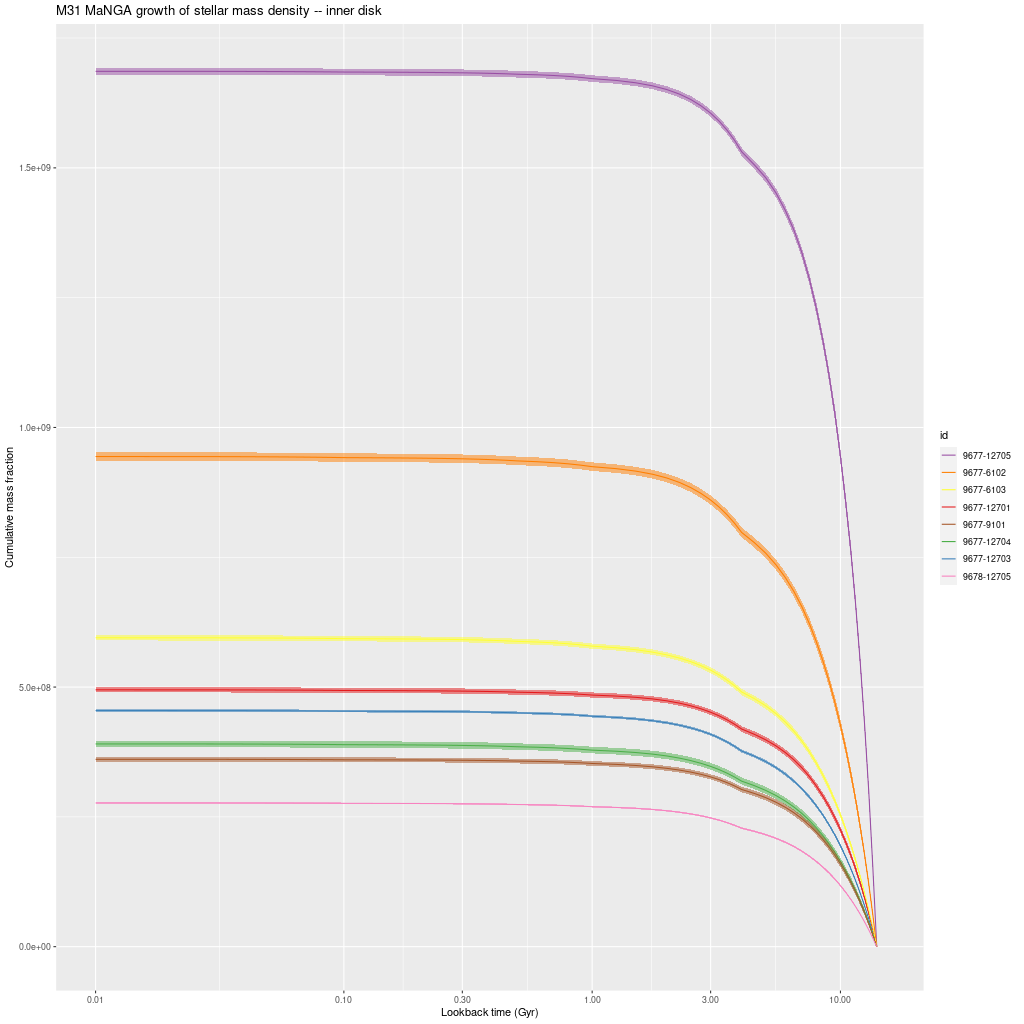
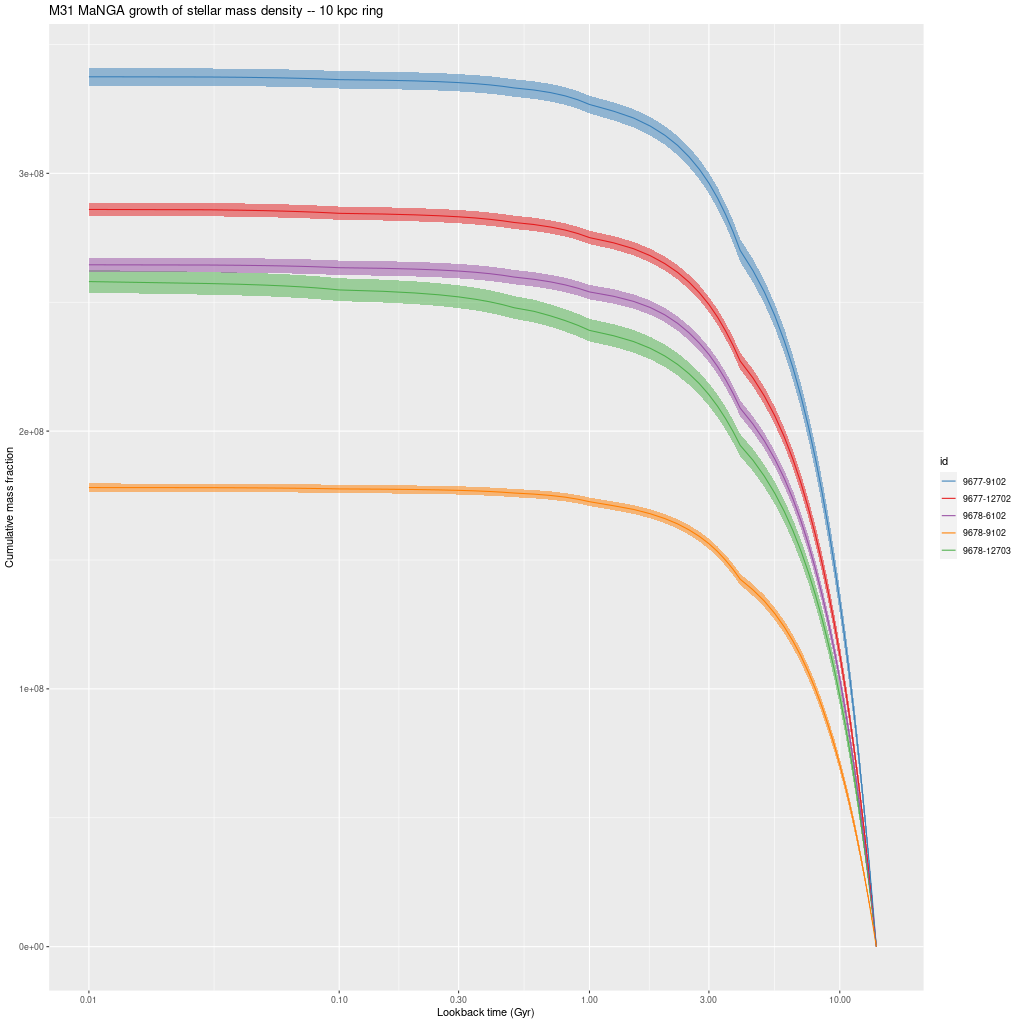
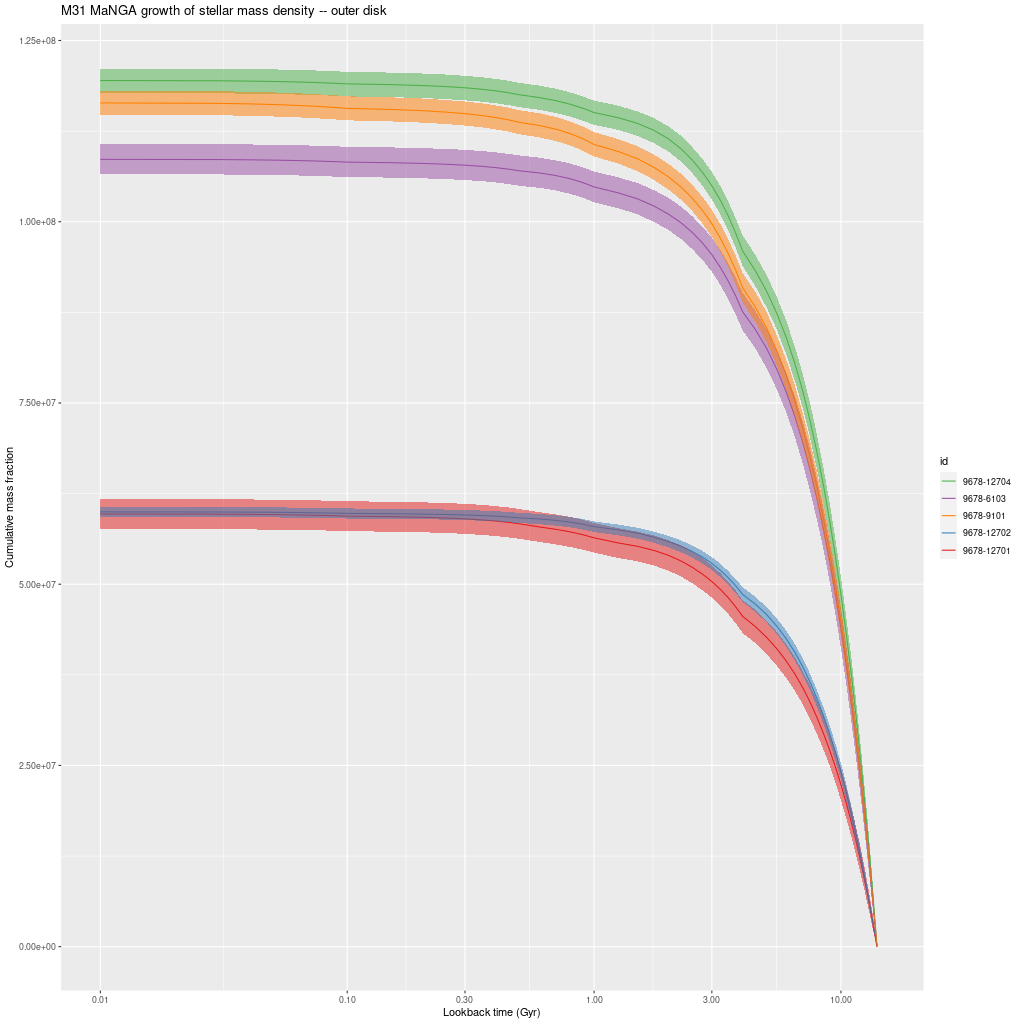
Before getting to individual IFU’s here is one more set of IFU-wide results. The following three graphs are model mass growth histories in units of present day solar mass per kiloparsec2. These are uncorrected for projection effects.
There are a couple interesting points here. There’s a clear stratification of mass density with projected radius, with about a factor 30 decline from the innermost to outermost IFU. This is in fairly good agreement with Williams’ estimate in their Figure 14.
The other thing to note is that all regions had most (> 55%) of their stellar mass in place by 8 Gyr ago and 92-99% in place by 1 Gyr ago. The largest fraction of recent star formation is in the IFU 9678-12703, which is very close to the region with the highest SFR in this half of the galaxy. There is also a trend towards later mass build up with increasing radius, which is completely consistent with the “inside-out” growth paradigm. The outermost IFU, 9678-12701 at about 16kpc radius has formed about 5% of its present day stellar mass in the past Gyr.
As I said in the previous post I don’t see clear evidence for a widespread burst of star formation that’s widely believed to have occurred around 2-4 Gyr ago. A confounding factor in my models is that they invariably show jumps in SFR at times when the interval between SSP model ages change and the two oldest of these occur at 1 and 4 Gyr, so this produces a possibly spurious period of apparently accelerated star formation. I hope to find (or perhaps produce) a set of SSP models with a better age distribution this year.
Growth of stellar mass density – inner disk M31 MaNGA IFU’sGrowth of stellar mass density – M31 MaNGA IFU’s in 10 kpc ringGrowth of stellar mass density – outer disk M31 MaNGA IFU’s
I think I’m going to hit publish now and resume with inner disk IFU’s next time.
I’ll resume my M31 posts soon (I hope), but I wanted to do a short post on the recent Zoogems HST observation of IC 3025 which is a dwarf elliptical in the Virgo cluster that was selected as part of the “post-starburst” galaxy sample. Thanks mostly to its membership in Virgo this galaxy is fairly well studied and even has multiple HST observations. Just for fun I tried to make a false color RGB image from three observations, with two in the IR through F160W and F110W filters, and the blue channel from the Zoogems observation in F475W.
IC 3025
False color composite from HST WFC3 IR images in F160W and F110W filters (proposal ID 11712, PI Blakeslee) and ACS/WFC F475W filter (proposal ID 15445, PI Keel).
This used a program named SWarp (author Bertin) to rescale and align the images and STIFF (also Bertin) to combine them, with some Photoshop work in a mostly futile attempt to get a more pleasing color balance and clean up some of the hot pixels. I don’t know exactly how STIFF maps counts to gray scale levels, but despite the odd color cast this picture may actually give a reasonably accurate rendering of the relative fluxes in each filter. The galaxy as a whole has a g-J color of about 1.3 mag (based on my measurements with APT and NED) and J-H ≈ 0.2 mag. per Jensen et al. (2015), so an orange or even green color in the body of the galaxy is not so unreasonable.
The blue(er) central region is notable and apparently real also. This is one of a distinct class of dwarf early type galaxies with blue centers, given the designation dE(bc) by Lisker et al. (2006). The blue centers are almost certainly due to recent star formation, as I’ll verify below.
There are 3 bright, unresolved clusters near the center with a number of others scattered around the body of the galaxy. By my measurements with the manual Aperture Photometry Tool the brightest of these has a g band (F475W) magnitude of 20.71 and J (110W) of 20.084, or g-J ≈ 0.62. The other two near the galaxy center are slightly fainter and considerably redder: g = 21.5 and 22.6 for the western and eastern flanking clusters, with g-J ≈ 1.2 for both. Jensen et al. (cited above) measure the distance modulus to be m-M = 31.42, which makes the F475W absolute magnitude of the central cluster equal to -10.71. Like the Zoogems target I discussed several months ago this would be quite luminous for a galactic globular cluster but is typical for a dwarf galaxy’s nuclear star cluster (Neumayer, Seth, and Boker 2020). This distance modulus, which corresponds to a luminosity distance of 19.2 Mpc, is considerably larger than the canonical distance to the Virgo cluster of m-M = 31.09 (per Jensen again). This is one of several lines of evidence that the galaxy is currently falling into the cluster.
Like the other galaxies in the Zoogems “post-starburst” sample the SDSS spectrum was incorrectly classified by the SDSS spectro pipeline as coming from a star, but this one has a correct redshift and has been used in science studies (for example in Lisker et al. cited above). From the reported position the fiber center was just west of the brightest central cluster and includes both that one and the cluster just to the west. The spectrum is very much typical of a post-starburst, with deep Balmer absorption and a shallow 4000Å break. I measure HδA = 7.24 ± 0.60Å and Dn4000 = 1.26 ± 0.0141this spectrum was analyzed in the JHU/MPA pipeline with nearly identical values and uncertainties, very similar values to the other two that I posted about last year. Finally, although it’s far from evident on visual inspection, there are firm (4-5 σ) detections of Hα and S[II] 6717, 6730 in emission. No other emission lines were detected.
IC 3025 – SDSS spectrum
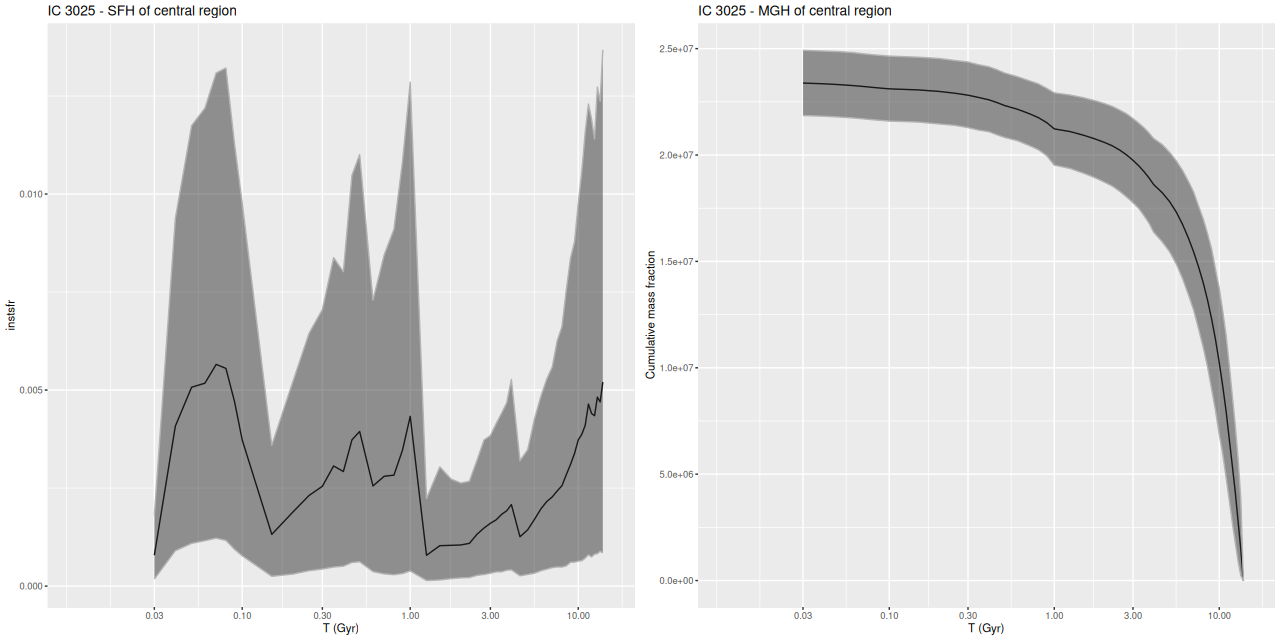
I used my usual star formation history modeling code with the metal poor subset of the EMILES SSP library as described here, which produced the estimated star formation and mass growth histories:
IC 3025 – Star formation history and mass growth history modeled from SDSS spectrum
with a very good fit to the data except for a small region around 7500Å (which is often the case with the EMILES library):
IC 3025 – posterior predictive fit to spectrum from SFH model
My results can be compared fairly directly to an analysis by Lisker et al. (cited above), who performed some simple stellar population modeling on SDSS spectra with what appears to be their own unreleased code. They limited their populations to 3 discrete ages with the oldest fixed at 5 Gyr and the mass fractions and ages for the other 2 chosen from a finite set of possible values.
Perhaps surprisingly my results agree rather well with theirs. For VCC 21 (the Virgo Cluster Catalog designation for IC 3025) their best fit had about 9% of the total mass in young and intermediate age populations, with the young population chosen at 9 Myr age and 0.3% of mass and the intermediate population age of 509 Myr.
My models also show three broad periods of star formation with some lulls in between that can conveniently be divided into young, intermediate, and old populations. The youngest SSP models in my metal poor subset are 30 Myr, so of course there can’t be any truly young populations in the model. The peak in recent star formation was at ~70 Myr with a steep decline at the youngest lookback times. Around 1% of the present day stellar mass in the fiber footprint is in stars younger than 100 Myr, with just under 10% under 1 Gyr.
Based on the colors we can infer that the acceleration of star formation that began ~1 Gyr ago was limited to the central region and the presumed nuclear star cluster. The remainder of the galaxy and its cluster system must already have been quiescent by then.
Edit
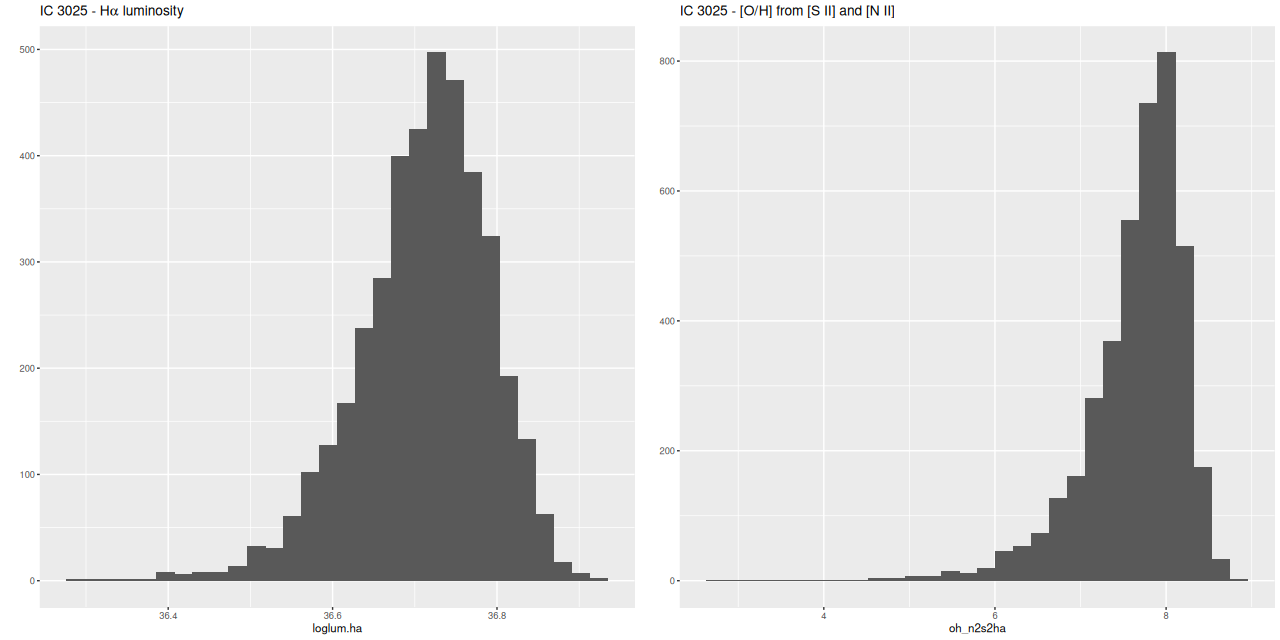
I mentioned above my SFH models indicated there were firm detections of Hα and the [S II] doublet in emission. Although [N II] wasn’t detected at better than the 1σ level it’s still possible to make a strong line metallicity estimate from the posteriors. I also plot the marginal posterior for Hα luminosity below:
IC 3025
(L) Hα luminosity from SDSS spectrum
(R) log(O/H) estimated from [N II]/Hα and [S II]/Hα
Using Calzetti’s calibration of the Hα – SFR relation this implies a current day star formation rate ~10-4.5 M☉/yr. This should be considered an upper limit since we don’t know the ionizing source. Using Dopita’s calibration of the [N II]/Hα plus [S II]/Hα strong line metallicity estimator the upper limit to 12+log(O/H) is around 8, which is subsolar by almost an order of magnitude.
In this post I’m going to compare IFU wide star formation histories from my models to those of Williams et al. (2017) in the nearest 83″ by 83″ PHAT tile to each MaNGA IFU in the study. I picked the Williams paper for comparison mostly because it’s possible to! They give a complete tabulation of model results for all regions and all 4 sets of isochrones that they used, and these are available through the Vizier service. Specifically I used their Table 2, which provides star formation rate densities summed over all metallicities. Since the SSP model spectra I use are based on BaSTI isochrones I initially compared to their BaSTI based models. One problem with the Williams comparison is the authors had a very wide youngest time bin of 300 Myr, which is where my models should generally have the highest precision (I make no strong claims about accuracy). It would be nice to do a similar comparison to the earlier companion paper on recent star formation by Lewis et al., which gives a much finer grained view of the last ~half Gyr, but unfortunately there is no published tabulation of their results.
At the other end of the timeline the oldest bin is also very wide, from 8 to 14 Gyr lookback time. This isn’t a surprise: the limits for reliable photometry of individual stars were rather shallow, no fainter than m = 28 or Mg ≈ 3.6 according to Lewis. This is brighter than the main sequence turnoff at 8 Gyr, so any information about the truly ancient star formation history is coming from giant branch stars which have very similar evolutionary tracks at old ages1Checked by downloading a few isochrones from the BaSTI website.
At the end of my last post I mentioned the necessity to correct densities for the rather large inclination of M31’s disk. It turns out though that I reproduce Williams’ Table 3 from their Table 2 if the densities are uncorrected. Their tabulated SFR densities are in units of 10-4 M☉arcmin-2/year. One arcminute at their adopted M31 distance is about 0.227 kpc, so to convert to star formation rates per kpc2 the values in table 2 are multiplied by 19.8 × 10-4. From my models I sum the star formation rates over all modeled spectra in each IFU and divide by the total area in fibers, with each fiber covering a projected area of 42.78 pc2. Note that I do not try to analyze a single composite spectrum summed over the entire IFU since dust attenuation is quite patchy.
The graphs below overlay my modeled star formation rate densities on those of Williams in the tile with the nearest center to that of each IFU. The ribbons indicate the nominal 95% credible limits of SFR. These are certainly wildly optimistic. Table 2 of the paper includes uncertainty estimates, which I chose not to include. SFR densities are linearly scaled with different limits for each plot. The time scale is logarithmic. Something in between linear and logarithmic would seem more appropriate since this perhaps gives too much space to very recent times, but I haven’t found a suitable scaling.
These are ordered into three groups by location: the inner disk which is everything inside the 10 kpc ring, the 10 kpc ring, and the outer disk which is everything outside the 10 kpc ring. There’s some ambiguity about the locations of the plateifu’s 9678-9101 and 9678-12704. The first of these is about 12 kpc from the nucleus in what could be either a wide section of the 10 kpc ring or a separate structure. 9678-12704 appears in projection to be just outside the 10 kpc ring but it may be considerably farther out in a segment of spiral arm at ~15 kpc.
Commentary will continue after the graphs. I will discuss the individual IFU’s in more detail in later post(s).
Inner Disk
M31 MaNGA ancillary program – my star formation history models summed over each IFU compared to nearest tile in Williams et al. (2017) with BaSTI isochrones. Inner disk IFU’s.
10 Kpc ring
M31 MaNGA ancillary program – my star formation history models summed over each IFU compared to nearest tile in Williams et al. (2017) with BaSTI isochrones. 10 kpc ring IFU’s.
Outer disk
M31 MaNGA ancillary program – my star formation history models summed over each IFU compared to nearest tile in Williams et al. (2017) with BaSTI isochrones. Outer disk IFU’s.
The first two things I noticed were that star formation in every region declines monotonically from very early times to at least 4 Gyr ago. It also starts out lower than in the PHAT team’s models. Because of this early time mass deficit all of my models have smaller current day stellar mass densities by varying amounts. I don’t really have a pat explanation for this. Some authors have posited a “dazzle effect”2I’m going to discuss this a little further at the end of the post where recent star formation obscures the contribution of old populations. It’s certainly likely that this occurs, but if these Bayesian models are behaving as I hoped this lack of information should manifest as larger uncertainties rather than a systematic bias. Well, my hope could be wrong. On the other hand I don’t see strong evidence in these models for such an effect. From my eyeball analysis I don’t see an obvious correlation between present day star formation and the size of the early time deficit.
Another possibility is a systematic difference in the amount or shape of attenuation between my models and theirs. There is another well known “degeneracy” between stellar age and attenuation in SFH modeling, but I haven’t yet investigated whether this could be occurring here.
The PHAT models have a very long interval from 8 to ~2-3 Gyr ago with very little star formation. Some authors find evidence for a large increase from about 2-4 Gyr which is usually attributed to a merger or perhaps close encounter with M33. This isn’t seen in the BaSTI based models but there is a large more recent burst from about 1-2 Gyr lookback time. My models see neither a cessation of star formation nor a particularly large burst at intermediate ages. As I’ve noted before my models “want” to have smoothly time varying light3and therefore mass contributions and this might make a modest burst at moderately large ages difficult to discern. Another confounding factor arises from the abrupt changes in age intervals (at 0.1, 0.5, 1, and 4 Gyr) which results in the sawtooth pattern in SFR that’s obvious in every plot above.
At ages younger than 1 Gyr there’s generally good agreement about the course of star formation up until the youngest age bin of width 300Myr in the PHAT models. My models have anywhere from slightly to dramatically higher SFR densities averaged over the most recent age bin. I suspect this is because many of the IFU positions were chosen to be in regions with active star formation. In particular the plateifu 9678-12703 (mangaid 52-23) is very close to the region in the 10 kpc ring with the highest density of ongoing star formation in the northern half of the disk.
I plan to discuss the individual IFUs in more detail in a later post. Below the fold are some more graphics: mass growth histories and SFR densities compared to the PADOVA isochrone based models.
One of the ancillary programs (with principal investigator Julianne Dalcanton) in the final MaNGA release targeted 18 fields in the disk of the Andromeda galaxy M31. The targets were selected from within the footprint of the “Panchromatic Hubble Andromeda Treasury,” aka PHAT1not my coinage., also with PI Dalcanton. The initial PHAT survey description was in Dalcanton et al. (2012) and was followed by a lengthy series of papers. Especially relevant for this discussion are two papers describing estimates of the recent and ancient star formation histories of the disk outside the area dominated by bulge light: Lewis et al. (2015), “The Panchromatic Hubble Andromeda Treasury. XI. The Spatially Resolved Recent Star Formation History of M31” and Williams et al. (2017), “PHAT. XIX. The Ancient Star Formation History of the M31 Disk.” For reference here is a mosaic of HST images in the F475W filter with the IFU locations overlaid:
Mosaic of HST F475W images of PHAT study region with M31 MaNGA IFU positions overlaid
Zooming out to show the whole disk here they are overlaid on a false color FUV+NUV image from GALEX, which gives a pretty good picture of where stars are actually forming:
GALEX false color NUV+FUV image of M31 with MaNGA IFU positions overlaid – screencap from Aladin
This data set provides an excellent opportunity to compare my SFH modeling code to a completely different, more direct, method of inferring star formation histories namely counting resolved stars in color magnitude diagrams. I recently completed model runs for all 18 IFU’s with the same Voronoi binning of stacked RSS spectra, the same modeling code and SSP model spectra as I’ve used for a while now.
There’s no redshift listed in the DRP catalog; NED gives a heliocentric redshift of -0.001, but for purposes of calculating intrinsic quantities I need the “Hubble flow” redshift. I adopted a distance of 761 (± 11) kpc or distance modulus of (m-M)0 = 24.407 from Li et al. (2021), which is the most recent and according to the authors most precise determination to date. With my adopted Hubble constant of H0 = 70 km/sec/Mpc this makes the Hubble flow recession velocity 53.27 km/sec or zdist = 0.0001777. The angular scale is 3.69 pc/arc-second. This distance estimate is a few percent smaller than the PHAT team authors and most other recent literature I reviewed, but fortunately most other sources of uncertainty are much larger.
An issue I noticed early on was the modelled values of the optical depth of attenuation were right at 0 for almost all spectra with only a few much larger exceptions. A quick check of the metadata showed that the values adopted for the foreground galactic extinction almost certainly were taken from the SFD dust maps which faithfully capture the intrinsic dust content of M31 albeit at rather low resolution. These hugely overestimate the actual foreground galactic extinction and that has multiple undesirable consequences. So, I assigned a single extinction value of E(B-V) = 0.055 to all IFU’s, consistent with the NED value of AV = 0.17 mag. The preliminary runs were redone with the newly adopted extinction value.
After binning to a minimum mean SNR of 5 there were 2,624 spectra in the 18 IFUs, of which I ran models for 2,621. Three spectra had apparent foreground stars, although one of those might actually be a red supergiant in M31. The fibers are basically sampling star cluster size and stellar mass regions so a single extremely luminous star could potentially affect a spectrum.
I’m only going to show a few summary results for the entire sample in this post. My goal is to do a more detailed quantitative comparison to (at least) the SFH models of Wilson, for which there are extensive results tabulated. There are of course many catalogs of interesting objects within M31, and I plan to look at some of them.
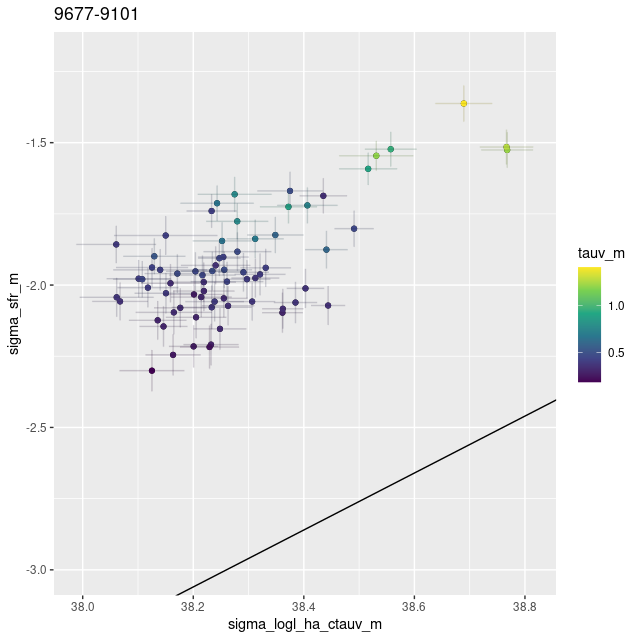
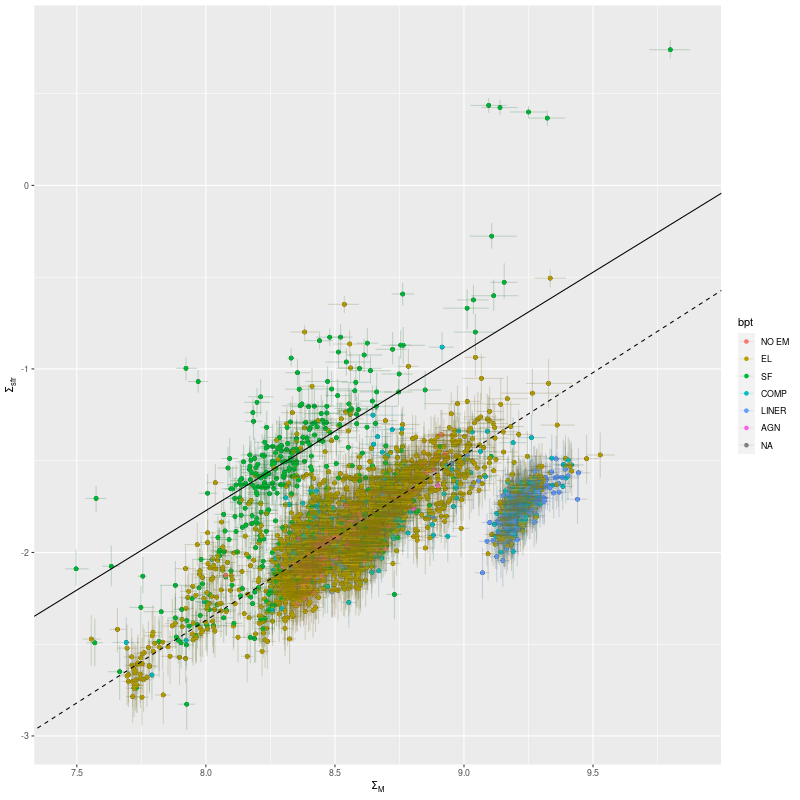
First, here is a plot of the (100 Myr averaged) star formation rate density against stellar mass density, color coded by BPT diagnostic. The solid line is my estimate of the “spatially resolved star forming main sequence” based on a small sample of non-barred spiral galaxies. The dashed line is the estimate of Bluck et al. (2020), which I commented previously appears to mark approximately the location of the green valley at least with regard to my models. A striking feature of this plot is the apparent stratification into at least three distinct groups that can be interpreted as starforming, quiescently evolving, and passively evolving. I suspect this observed stratification is just the result of hand picking a small number of “interesting” regions. Most or perhaps all of the points in the passively evolving group are in the IFU closest to the bulge, while most of those along and above the SFMS lie near the most vigorously star forming regions in the PHAT footprint. Especially noteworthy are 5 outliers that are well above any others in the plot in terms of SFR density. These are all in the same IFU (plateifu 9678-12703) which is located within the largest star forming region in that quadrant of the “10 kpc ring.”
100 Myr average star formation rate density vs. stellar mass density for 2621 binned spectra in M31 disk. Solid and dashed lines are my and Bluck’s central estimates of the “spatially resolved star forming main sequence.
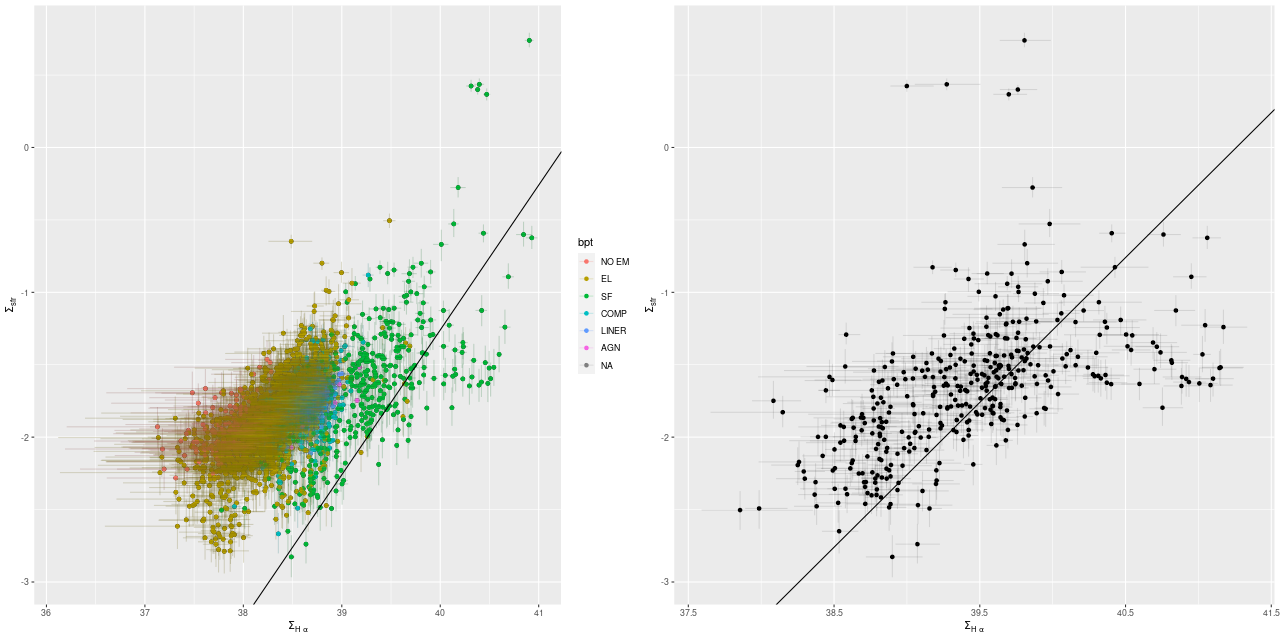
Next are plots of star formation rate density against Hα luminosity density. The left panel is for all spectra color coded by BPT diagnostic, with Hα adjusted by the modeled amount of stellar attenuation. The right panel shows regions with star forming BPT diagnostics only, with Hα corrected by the observed Balmer decrement. The solid line in both panels is Calzetti’s calibration of the Hα – SFR relationship. The relationships plotted here are consistent with what I’ve seen in other MaNGA samples and with published values, which is encouraging.
Star formation rate density vs. Hα luminosity density for 2621 binned spectra in M31 disk. (L) Emission corrected for modeled stellar attenuation. (R) For regions with star forming emission line ratios only: emission corrected from estimated Balmer decrement.
The obvious point of comparison to my models are the detailed star formation histories in the two PHAT papers mentioned at the top. Unfortunately there is no detailed tabulation of model results in the paper by Lewis et al. The paper by Williams et al. has extensive tables, but there are still a few obstacles to detailed comparisons which I will discuss next time.
A few more items from my handwritten notes that I want to get in pixels. I have never previously tried to correct surface densities for inclination in disk galaxies, but for comparison purposes and because of the large inclination of M31’s disk I need to do so here. I adopted an inclination angle of 77°, so a 1″ radius fiber covers a 3.69 x 16.4 pc (semi major and minor axes) elliptical region, or 190 pc2. Densities need to be adjusted downward by a factor 4.45 or -0.648 dex2This adjustment was not made in the plots above. Since these are plots of densities against densities all points would just shift downwards along lines of slope one..
In order to achieve 100% coverage of the IFU footprints the exposures were dithered to three different positions with overlapping fiber positions. Comparing the area in fibers to the area in spaxels in the cubes the overfilling factor averages 0.217 dex or 65%. The total area in all cubes is 10,731 arcsec2, or a deprojected area of 0.65 kpc2. The most distant IFU from the nucleus is at a projected radius of about 16 kpc. A simple extrapolation to the ≈800 kpc2 area of the disk within that radius is probably unsafe.
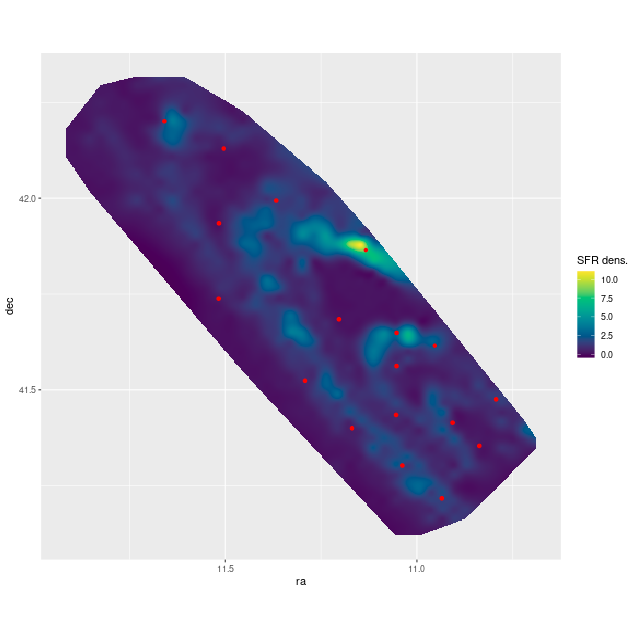
One final map to anticipate the next post(s). Wilson provides tables of model star formation rates for 16 age bins, 826 regions, and 4 different sources of isochrones including the same BASTI isochrones I use. The complete data set is available through Vizier. In the plot below I created a map of the recent star formation rate density interpolated to nominal 10″ resolution from their Table 2 models with BASTI isochrones. This should be compared to their Figure 16 (they use logarithmic scaling).
Current (300 Myr average) star formation rate density in the PHAT footprint per models of Wilson et al. (2017) with positions of MaNGA IFUs overlaid.