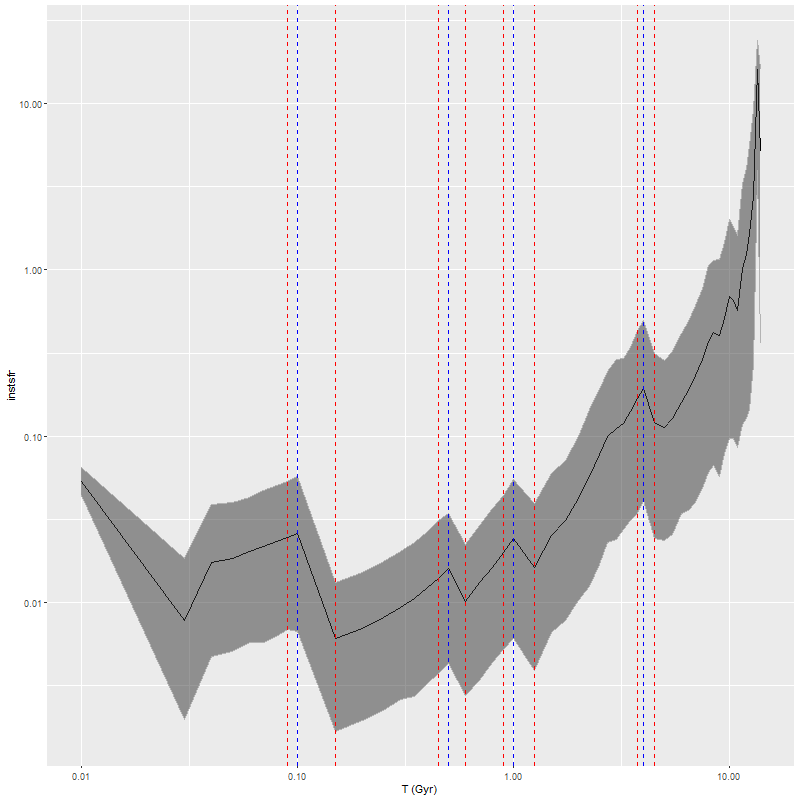
One of my favorite visualization tools for displaying results of star formation history modeling is a ribbon plot of star formation rate versus look back time. This simply plots the marginal posterior mean or median SFR along with 2.5 and 97.5th percentiles (by default) as the lower and upper boundaries of the ribbon. I’ve been using the simplest possible definition of the star formation rate, namely the total mass born in each age bin divided by the interval between the nominal age of each SSP model and the next younger. One striking feature of these plots that’s especially evident in grids of SFH models for an entire galaxy like the one shown in my last post is that there are invariably jumps in the SFR at certain specific ages as marked below. This particular example is from a sample of passively evolving Coma cluster galaxies, but the same features are seen regardless of the likely “true” star formation history.
Star formation rate history estimate – emiles with BaSTI isochrones
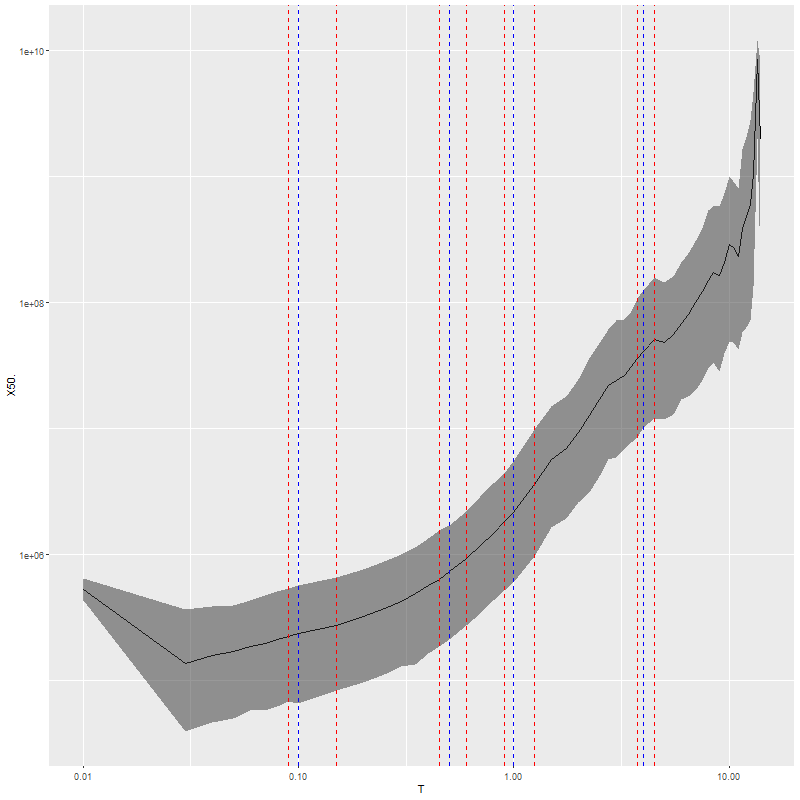
These jumps are artifacts of course: the BaSTI isochrones used for the EMILES SSP models that I currently use are tabulated at age intervals that are constant over certain age ranges, with jumps at 4 ages1100 Myr, 500 Myr, 1 Gyr, and 4 Gyr. The jumps in model SFR occur exactly at the breaks in the age intervals. This turns out to be due to an otherwise welcome feature of the SFH models that they “want” to produce SSP contributions that vary smoothly with age as shown below for the same model run. So for example the stellar mass born in the 90-100 Myr age bin per the model is about 90% of that in the 100-150 Myr bin while the time interval increases by a factor of 5, so the model SFR declines by a factor 4.5 or around 0.6 dex.
Modeled mass born in each age bin – central spectrum of plateifu 9876-12702
Can I do anything about this? Should I? Changing how I calculate the star formation rate might work — this is after all a derivative and I’m currently using the most stupidly simple numerical approximation possible. It also might help to adjust the effective ages of each SSP model. I should also look at the priors on the SSP model coefficients, although as I noted some time ago it’s hard to affect the model star formation histories much with adjustments to priors.
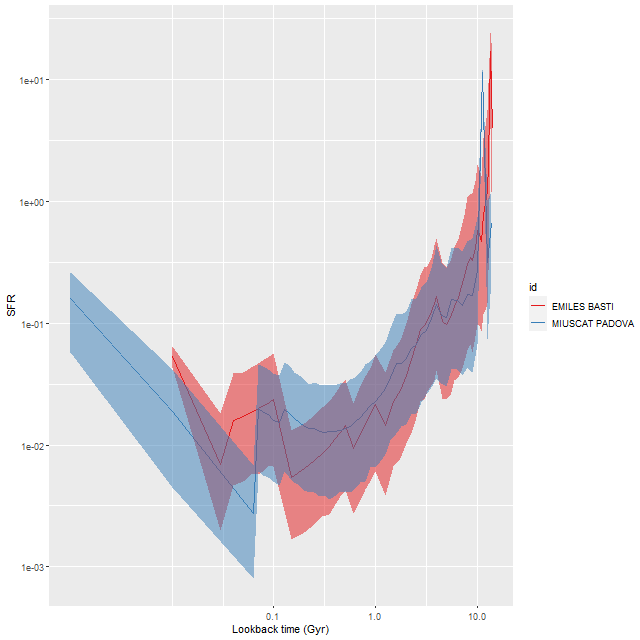
These jumps are something of a peculiarity of the BaSTI isochrones. I had previously used a subset of MILES SSP models from Padova isochrones, which are tabulated at equal logarithmic age intervals. A comparison model run lacks large jumps except for an early time burst. Since the youngest age bin in the Padova isochrones is around 60 Myr I had added two younger SSP models from an update of the BC03 library, and these show abrupt jumps in model SFR. This is also the case with the youngest age bin in my currently used EMILES library.
Comparison of star formation rate history estimates:
Red – EMILES SSP libraries with BaSTI isochrones
Blue – Miuscat SSP library with Padova isochrones
A final comment about these visualizations is that often the mode of the posterior distribution of an SSP model contribution is near 0, and it might make sense to display one sided confidence intervals since what we’re really constraining is an upper limit. I may work on this in the future.
It’s been available for a while actually, but not in a form I’ve been able to figure out how to use. That changed recently with the introduction of the reduce_sum “higher order function” in Stan 2.23.0. What reduce_sum does is allow data to be partitioned into conditionally independent slices that can be dispatched to parallel threads if the Stan program is compiled with threading enabled. My SFH modeling code turns out to be an ideal candidate for parallelization with this technique since flux errors given model coefficients and predictor values are treated as independent1This is an oversimplification since there is certainly some covariance between nearby wavelength bins. This is rarely if ever modeled though and I haven’t figured out how to do it. In any case adding covariance between measurements would complicate matters but not necessarily make it impossible to partition into independent chunks. Here is the line of Stan code that defines the log-likelihood for the current version of my model (see my last post for the complete listing):
This just says the galaxy flux values are drawn from independent gaussians with mean given by the model and known standard deviations. Modifying the code for reduce_sum requires a function to compute a partial sum over any subset of the data for, in this case, the log-likelihood. The partial sum function has to have a specific but fairly flexible function signature. One thing that confused me initially is that the first argument to the partial sum function is a variable to be sliced over that, according to the documentation, must be an array of any type. What was confusing was that passing a variable of vector type as the first argument will fail to compile. In other words a declaration in the data block like
vector[N] y;
with, in the functions block:
real partial_sum(vector y, ...);
fails, while
real y[N];
real partial_sum(real[] y, ...);
works. The problem here is that all of the non-scalar model parameters and data are declared as vector and matrix types because the model involves vector and matrix operations that are more efficiently implemented with high level matrix expressions. Making gflux the sliced variable, which seemed the most obvious candidate, won’t work unless it’s declared as real[] and that won’t work in the sampling statement unless it is cast to a vector since the mean in the expression at the top of the post is a vector. Preliminary investigation with a simpler model indicated that approach works but is so slow that it’s not worth the effort. But, based on a suggestion in the Stan discussion forum a simple trick solved the issue: declare a dummy variable with an array type, pass it as the first argument to the partial sum function, and just don’t use it. So now the partial sum function, which is defined in the functions block is
real sum_ll(int[] ind, int start, int end, matrix sp_st, matrix sp_em,
vector gflux, vector g_std, vector lambda, real a, real tauv, real delta,
vector b_st_s, vector b_em) {
return normal_lpdf(gflux[start:end] | a * (sp_st[start:end, :]*b_st_s) .* calzetti_mod(lambda[start:end], tauv, delta)
+ sp_em[start:end, :]*b_em, g_std[start:end]);
}
I chose to declare the dummy variable ind in a transformed data block. I also declare a tuning variable grainsize there and set it to 1, which tells Stan to set the slice size automatically at run time.
transformed data {
int grainsize = 1;
int ind[nl] = rep_array(1, nl);
}
The rest of the Stan code is the same as presented in the last post.
So why go to this much trouble? As it happens a couple years ago I built a new PC with what was at the time Intel’s second most powerful consumer level CPU, the I9-7960X, which has 16 physical cores and supports 32 threads. I’ve also installed 64GB of DRAM (recently upgraded from 32), which is overkill for most applications but great for running Stan programs which can be rather memory intensive. Besides managing my photo collection I use it for Stan models, but until now I haven’t really been able to make use of its full power. By default Stan runs 4 chains for MCMC sampling, and these can be run in parallel if at least 4 cores are available. It would certainly be possible to run more than 4 chains but this doesn’t buy much: increasing the effective sample size by a factor of 2 or even 4 doesn’t really improve the precision of posterior inferences enough to matter. Once I tried running 16 chains in parallel with a proportionate reduction in post-warmup iterations, but that turned out to be much slower than just using 4 chains. The introduction of reduce_sum raised at least the possibility of making full use of my CPU, and in fact working through the minimal example in Stan’s library of case studies indicated that close to factor of 4 speedups with 4 chains and 4 threads per chain are achievable. I got almost no further improvement setting the threads per chain to 8 and thus using all virtual cores, which apparently is expected at least with Intel CPUs. I haven’t yet tried other combinations, but using all physical cores with the default 4 chains seems likely to be close to optimal. I also haven’t experimented much with the single available tuning parameter, the grainsize. Setting it equal to the sample size divided by 4 and therefore presumably giving each thread an equal size slice did not work better than letting the system set it, in fact it was rather worse IIRC.
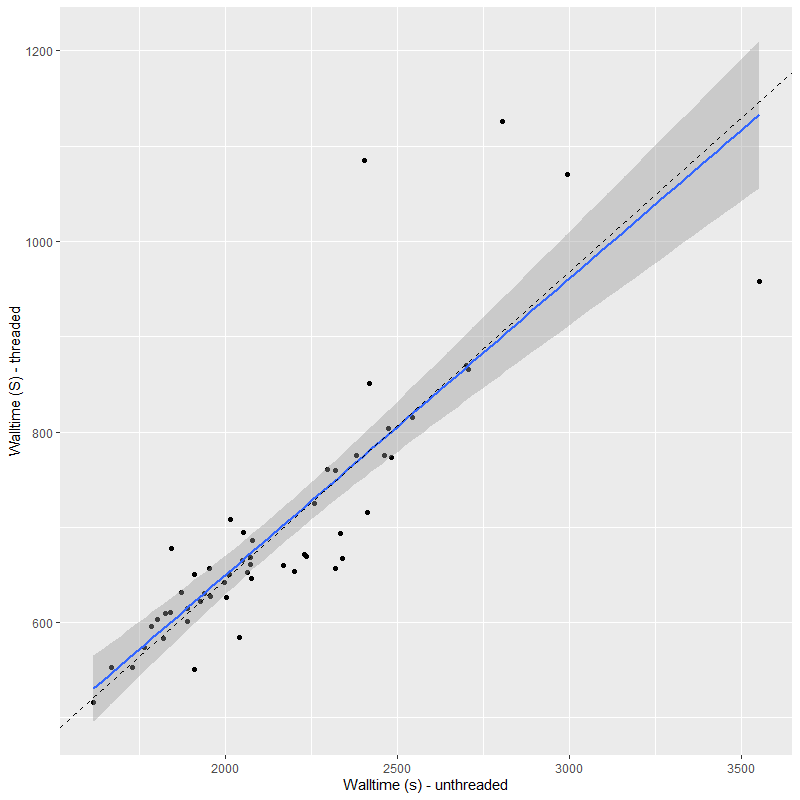
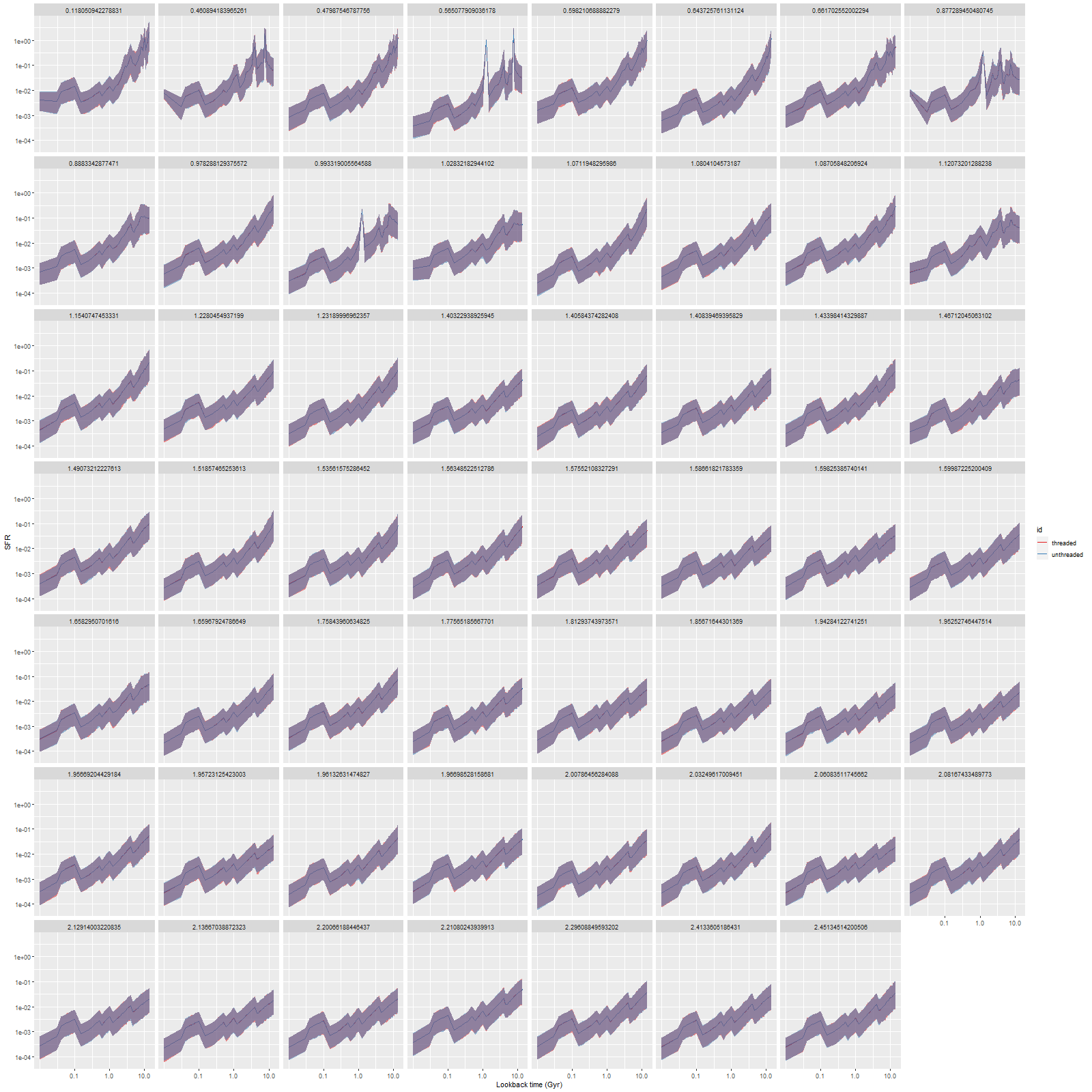
I’ve run both the threaded and unthreaded models on one complete set of data for one MaNGA galaxy. This particular data set used the smallest, 19 fiber IFU, which produces 57 spectra in the stacked RSS data. This was binned to 55 spectra, all with SNR > 5. The galaxy is a passively evolving S0 in or near the Coma cluster, but I’m not going to discuss its star formation history in any detail here. I’m only interested in comparative runtimes and the reproducibility of sampling. And here is the main result of interest, the runtimes (for sampling only) of the threaded and unthreaded code. All runs used 4 chains with 250 warmup iterations and 750 post-warmup. I’ve found 250 warmup iterations to be sufficient almost always and 3000 total samples is more than enough for my purposes. This is actually an increase from what had been my standard practice.
Total execution time for sampling (warmup + post-warmup) in the slowest chain. Graph shows multithreaded vs. threaded time on the same data (N=55 spectra). All threaded runs used 4 chains and 4 threads per chain on a 16 core CPU.
On average the threaded code ran a factor of 3.1 times faster than the unthreaded, and was never worse than about a factor 2 faster2but also never better than a factor 3.7 faster. This is in line with expectations. There’s some overhead involved in threading so speedups are rarely proportional to the number of threads. This is also what I found with the published minimal example and with a just slightly beyond minimal multiple regression model with lots of (fake) data I experimented with. I’ve also found the execution time for these models, particularly in the adaptation phase, to be highly variable with some chains occasionally much faster or slower than others. Stan’s developers are apparently working on communicating between chains during the warmup iterations (they currently do not) and this might reduce between chain disparities in execution time in the future.
I’m mostly interested in model star formation histories, so here’s the comparison of star formation rate densities for both sets of model runs on all 55 bins, ordered by distance from the IFU center (which coincides with the galaxy nucleus):
Star formation rate density. Estimates are for threaded and unthreaded model runs.
Notice that all the ribbons are purple (red + blue), indicating the two sets of runs were nearly enough identical. Exact reproducibility is apparently hard to achieve in multithreaded code, and I didn’t try. I only care about reproducibility within expected Monte Carlo variations, and that was clearly achieved here.
There are only a few down sides to multithreading. The main one is that rstan is currently several dot releases behind Stan itself and seems unlikely to catch up to 2.23.x before 2021. I do extensive pre- and post-processing in R and all of my visualization tools use ggplot2 (an R package) and various extensions. At present the best way to integrate R with a current release of Stan is a (so far) pre-release package called cmdstanr, which bills itself as a “lightweight interface to Stan for R users.” What it actually is is an interface between R and cmdstan, which is in turn the command line driven interface to Stan.
By following directions closely and with a few hints from various sources I was able to install cmdstan from source and with threading support in Windows 10 using Rtools 4.0. The development version of cmdstanr is trivial to install and seems to work exactly as advertised. It is not a drop in replacement for rstan though, and this required me to write some additional functions to fit it into my workflow. Fortunately there’s an rstan function that reads the output files from cmdstan and creates a stanfit object, and this enables me to use virtually all of my existing post-processing code intact.
The other consequence is that cmdstan uses R dump or json format files for input and outputs csv files, the inputs have to be created on the fly, and the outputs have to be read into memory. Cmdstanr with some help from rstan handles this automatically, but there’s some additional overhead compared to rstan which AFAIK keeps all data and sampler output in memory. On my machine the temporary directories reside on a SSD, so all this file I/O goes fairly quickly but still slower than in memory operations. I also worry a bit about the number of read-write cycles but so far the SSD is performing flawlessly.
Multithreading is beneficial to the extent that physical cores are available. This is great for people with access to HPC clusters and it’s helpful to me with an overspec’d and underutilized PC. My current Linux box, which is really better suited to this type of work, only has a several generations old Intel I7 with 4 cores. It’s still a competent and highly reliable machine, but it’s not likely to see any performance improvement from multithreading. Fortunately the current trend is to add more cores to mainstream CPUs: AMD’s Ryzen line currently tops out at 16 cores and their Threadripper series have 24-64 cores. This would be a tempting next build, but alas I’m trying not to spend a lot of money on hobbies these days for more or less obvious reasons.
I’m stranded at sea at the moment so I may as well make a short post. First, here is the complete Stan code of the current model that I’m running. I haven’t gotten around to version controlling this yet or uploading a copy to my github account, so this is the only non-local copy for the moment.
One thing I mentioned in passing way back in this post is that making the stellar contribution parameter vector a simplexseemed to improve sampler performance both in terms of execution time and convergence diagnostics. This was for a toy model where the inputs were nonnegative and summed to one, but it turns out to work better with real data as well. At some point I may want to resurrect old code to document this more carefully, but the main thing I’ve noticed is that post-warmup execution time per sample is often dramatically faster than previously (the execution time for the same number of warmup iterations is about the same or larger though). This appears to be largely due to needing fewer “leapfrog” steps per iteration. It’s fairly common for a model run to have a few “divergent transitions,” which Stan’s developers seem to think is a strong indicator of model failure1I’ve rarely actually seen anything particularly odd about the locations of the divergences and inferences I care about seem unaffected. I’m seeing fewer of these and a larger percentage of model runs with no divergences at all, which indicates the geometry in the unconstrained space may be more favorable.
Here’s the Stan source:
// calzetti attenuation
// precomputed emission lines
functions {
vector calzetti_mod(vector lambda, real tauv, real delta) {
int nl = rows(lambda);
real lt;
vector[nl] fk;
for (i in 1:nl) {
lt = 5500./lambda[i];
fk[i] = -0.10177 + 0.549882*lt + 1.393039*pow(lt, 2) - 1.098615*pow(lt, 3)
+0.260618*pow(lt, 4);
fk[i] *= pow(lt, delta);
}
return exp(-tauv * fk);
}
}
data {
int<lower=1> nt; //number of stellar ages
int<lower=1> nz; //number of metallicity bins
int<lower=1> nl; //number of data points
int<lower=1> n_em; //number of emission lines
vector[nl] lambda;
vector[nl] gflux;
vector[nl] g_std;
real norm_g;
vector[nt*nz] norm_st;
real norm_em;
matrix[nl, nt*nz] sp_st; //the stellar library
vector[nt*nz] dT; // width of age bins
matrix[nl, n_em] sp_em; //emission line profiles
}
parameters {
real a;
simplex[nt*nz] b_st_s;
vector<lower=0>[n_em] b_em;
real<lower=0> tauv;
real delta;
}
model {
b_em ~ normal(0, 100.);
a ~ normal(1, 10.);
tauv ~ normal(0, 1.);
delta ~ normal(0., 0.1);
gflux ~ normal(a * (sp_st*b_st_s) .* calzetti_mod(lambda, tauv, delta)
+ sp_em*b_em, g_std);
}
// put in for posterior predictive checking and log_lik
generated quantities {
vector[nt*nz] b_st;
vector[nl] gflux_rep;
vector[nl] mu_st;
vector[nl] mu_g;
vector[nl] log_lik;
real ll;
b_st = a * b_st_s;
mu_st = (sp_st*b_st) .* calzetti_mod(lambda, tauv, delta);
mu_g = mu_st + sp_em*b_em;
for (i in 1:nl) {
gflux_rep[i] = norm_g*normal_rng(mu_g[i] , g_std[i]);
log_lik[i] = normal_lpdf(gflux[i] | mu_g[i], g_std[i]);
mu_g[i] = norm_g * mu_g[i];
}
ll = sum(log_lik);
}
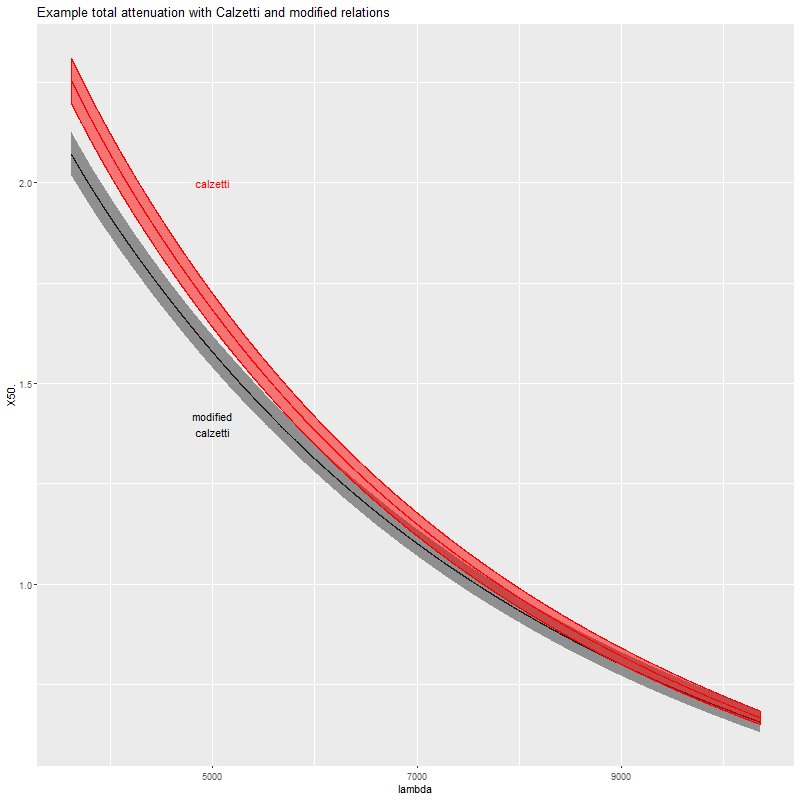
The functions block at the top of the code defines the modified Calzetti attenuation relation that I’ve been discussing in the last several posts. This adds a single parameter delta to the model that acts as a sort of slope difference from the standard curve. As I explained in the last couple posts I give it a tighter prior in the model block than seems physically justified.
There are two sets of parameters for the stellar contributions declared in lines 36-37 of the parameters block. Besides the simplex declaration for the individual SSP contributions there is an overall multiplicative scale parameter a. The way I (re)scale the data, which I’ll get to momentarily, this should be approximately unit valued. This is expressed in the prior in line 44 of the model block. Even though negative values of a would be unphysical I don’t explicitly constrain it since the data should guarantee that almost all posterior probability mass is on the positive side of the real line.
The current version of the code doesn’t have an explicit prior for the simplex valued SSP model contributions which means they have an implicit prior of a maximally dispersed Dirichlet distribution. This isn’t necessarily what I would choose based on domain knowledge and I plan to investigate further, but as I discussed in that post I linked it’s really hard to influence the modeled star formation history much through the choice of prior.
In the MILES SSP models one solar mass is distributed over a given IMF and then allowed to evolve according to one of a choice of stellar isochrones. According to the MILES website the flux units of the model spectra have the peculiar scaling
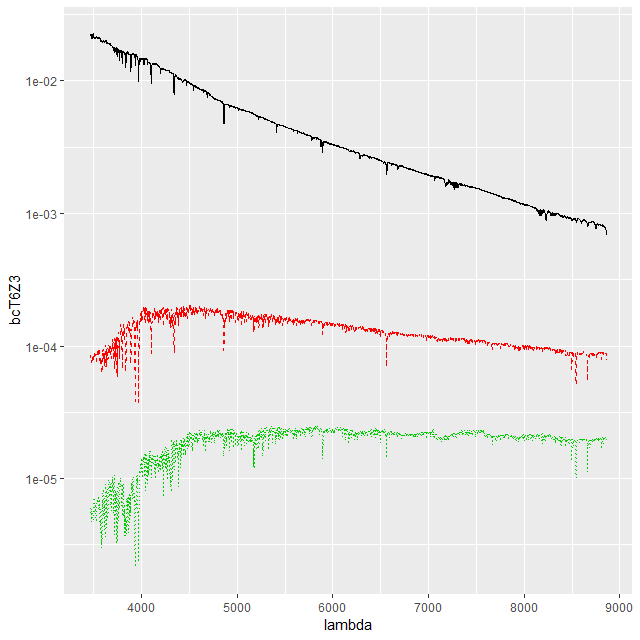
This convention, which is the same as and dates back to at least BC03, is convenient for stellar mass computations since the model coefficient values are proportional to the number of initially solar mass units of each SSP. Calculating quantities like total stellar masses or star formation rates is then a relatively trivial operation. Forward modeling (evolutionary synthesis) is also convenient since there’s a straightforward relationship between star formation histories and predictions for spectra. It may be less convenient for spectrum fitting however, especially using MCMC based methods. The plot below shows a small subset of the SSP library that I’m currently using. Not too surprisingly there’s a multiple order of magnitude range of absolute flux levels with the main source of variation being age. What might be less evident in this plot is that in the units SDSS uses coefficient values might be in the 10’s or hundreds of thousands, with multiple order of magnitude variations among SSP contributors. A simple rescaling of the library spectra to make at least some of the coefficients more nearly unit scaled will address the first problem, but won’t affect the multiple order of magnitude variations among coefficients.
Small sample of EMILES SSP model spectra in original flux units:
T (black): age 1 Myr from 2016 update of BC03 models
M (red) 1 Gyr
B (green) 10 Gyr
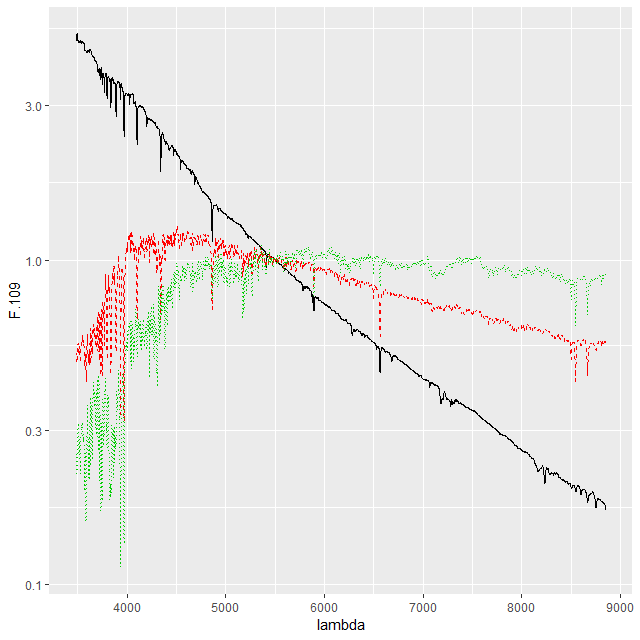
One alternative that’s close to standard statistical practice is to rescale the individual inputs to have approximately the same scale and central value. A popular choice for SED fitting is to normalize to 1 at some fiducial wavelength, often (for UV-optical-NIR data) around V. For my latest model runs I tried renormalizing each SSP spectrum to have a mean value of 1 in a ±150Å window around 5500Å, which happens to be relatively lacking in strong absorption lines at all ages and metallicities.
Same spectra normized to 1 in neighborhood of 5500 Å
This normalization makes the SSP coefficients estimates of light fractions at V, which is intuitively appealing since we are after all fitting light. The effect on sampler performance is hard to predict, but as I said at the top of the post a combination of light weighted fitting with the stellar contribution vector declared as a simplex seems to have favorable performance both in terms of execution time and convergence diagnostics. That’s based on a very small set of model runs and no rigorous performance comparisons at all2among other issues I’ve run versions of these models on at least 4 separate PCs with different generations of Intel processors and both Windows and Linux OSs. This alone produces factor of 2 or more variations in execution time..
For a quick visual comparison here are coefficient values for a single model run on a spectrum from somewhere in the disk of the spiral galaxy that’s been the subject of the last few posts. These are “interval” plots of the marginal posterior distributions of the SSP model contributions, arranged by metallicity bin (of which there are 4) from lowest to highest and within each bin by age from lowest to highest. The left hand strip of plots are the actual coefficient values representing light fractions at V, while the right hand strip are values proportional to the mass contributions. The latter is what gets transformed into star formation histories and other related quantities. The largest fraction of the light is coming from the youngest populations, which is not untypical for a star forming region. Most of the mass is in older populations, which again is typical.
Another thing that’s very typical is that contributions come from all age and metallicity bins, with similar but not quite identical age trends within each metallicity bin. I find it a real stretch to believe this tells us anything about the real chemical evolution distribution trend with lookback time, but how to interpret this still needs investigation.
Light (L) and mass (R) weighted marginal distributions of coefficient values for a single model run on a disk galaxy spectrum
Here’s an SDSS finder chart image of one of the two grand design spirals that found its way into my “transitional” galaxy sample:
Central galaxy: Mangaid 1-382712 (plateifu 9491-6101), aka CGCG 088-005
and here’s a zoomed in thumbnail with IFU footprint:
plateifu 9491-6101 IFU footprint
This galaxy is in a compact group and slightly tidally distorted by interaction with its neighbors, but is otherwise a fairly normal star forming system. I picked it because I had a recent set of model runs and because it binned to a manageable but not too small number of spectra (112). The fits to the data in the first set of model runs were good and the (likely) AGN doesn’t have broad lines. Here are a few selected results from the set of model runs using the modified Calzetti attenuation relation on the same binned spectra. First, using a tight prior on the slope parameter δ had the desired effect of returning the prior for δ when τ was near zero, while the marginal posterior for τ was essentially unchanged:
Estimated optical depth for modified Calzetti attenuation vs. unmodified. MaNGA plateifu 9491-6101
At larger optical depths the data do constrain both the shape of the attenuation curve and optical depth. At low optical depth the posterior uncertainty in δ is about the same as the prior, while it decreases more or less monotonically for higher values of τ. A range of (posterior mean) values of δ from slightly shallower than a Calzetti relation to somewhat steeper. The general trend is toward a steeper relation with lower optical depth in the dustier regions (per the models) of the galaxy.
Posterior marginal standard deviation of parameter δ vs. posterior mean optical depth. MaNGA plateifu 9491-6101
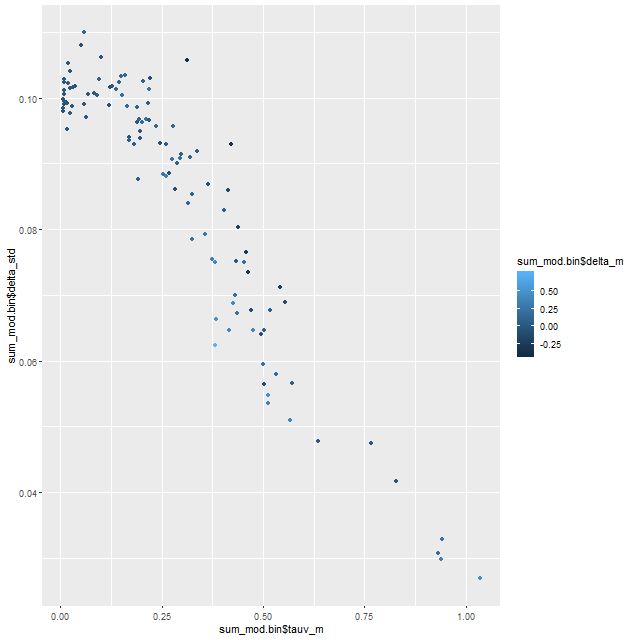
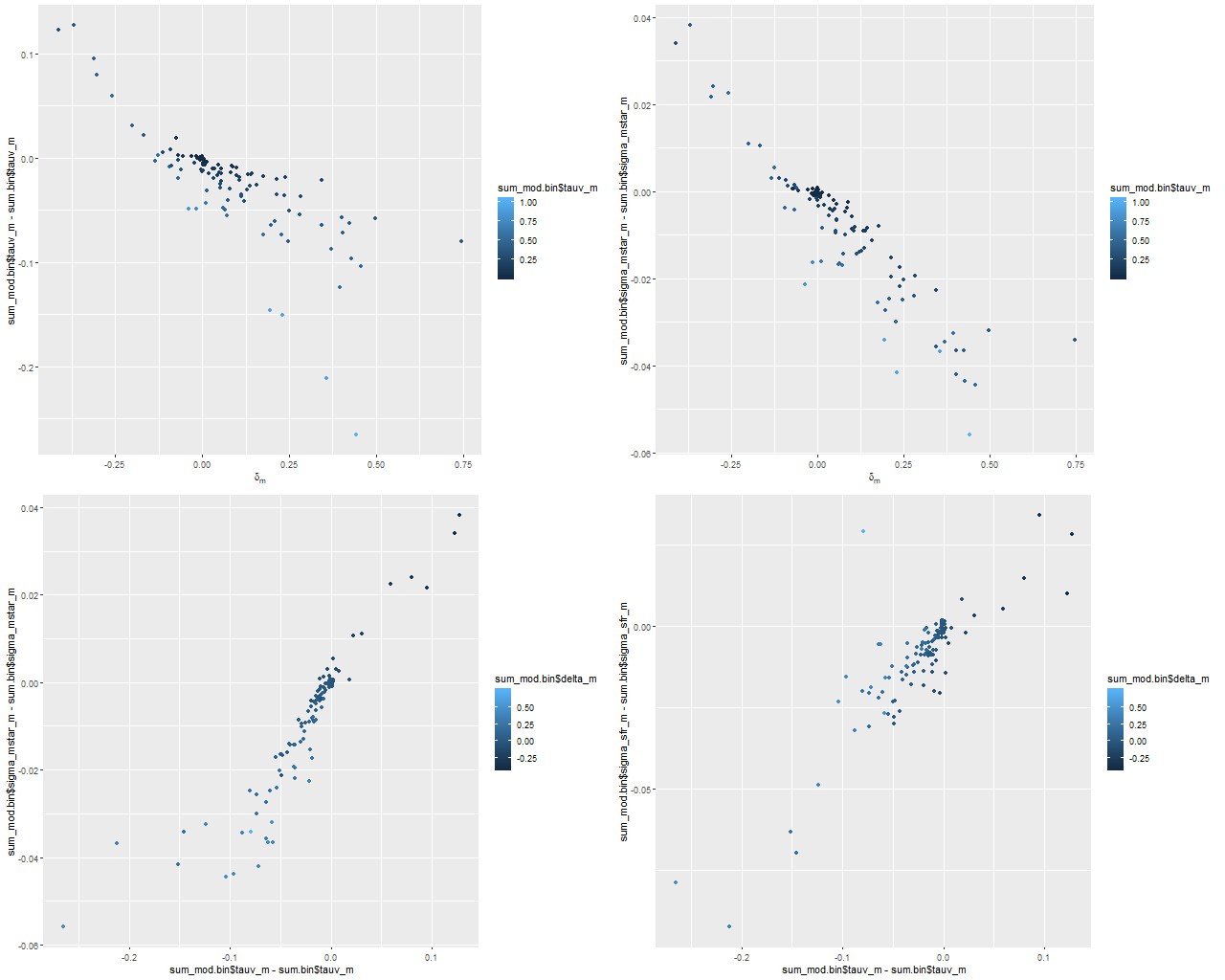
There’s an interesting pattern of correlations1astronmers like to call these “degeneracies,” and it’s fairly well known that they exist among attenuation, stellar age, stellar mass, and other properties here, some of which are summarized in the sequence of plots below. The main result is that a steeper (shallower) attenuation curve requires a smaller (larger) optical depth to create a fixed amount of reddening, so there’s a negative correlation between the slope parameter δ and the change in optical depth between the modified and unmodified curves. A lower optical depth means that a smaller amount of unattenuated light, and therefore lower stellar mass, is needed to produce a given observed flux. so there’s a negative correlation between the slope parameter and stellar mass density or a positive correlation between optical depth and stellar mass. The star formation rate density is correlated in the same sense but slightly weaker. In this data set both changed by less than about ± 0.05 dex.
(TL) change in optical depth (modified – unmodified calzetti) vs. slope parameter δ (TR) change in stellar mass density vs. δ (BL) change in stellar mass density vs. change in optical depth (BR) change in SFR density vs change in optical depth Note: all quantities are marginal posterior mean estimagtes.
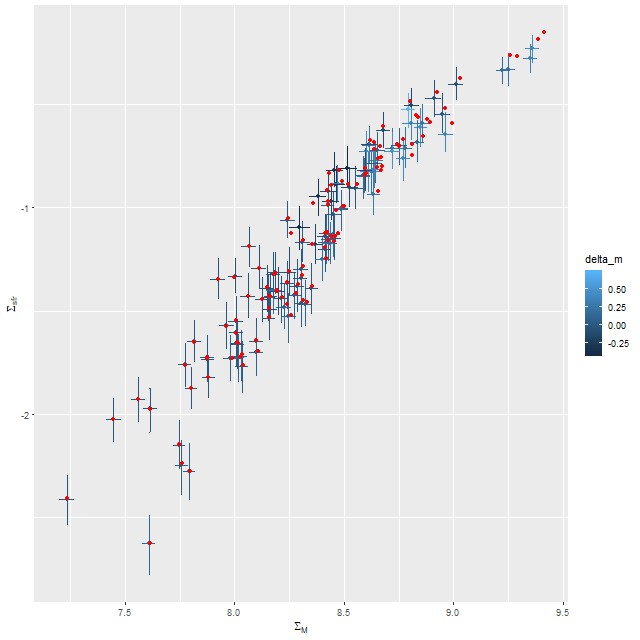
Here are a few relationships that I’ve shown previously. First between stellar mass and star formation rate density. The points with error bars (which are 95% marginal credible limits) are from the modified Calzetti run, while the red points are from the original. Regions with small stellar mass density and low star formation rate have small attenuation as well in this system, so the estimates hardly differ at all. Only at the high end are differences about as large as the nominal uncertainties.
SFR density vs. stellar mass density. Red points are point estimates for unmodified Calzetti attenuation. MaNGA plateifu 9491-6101
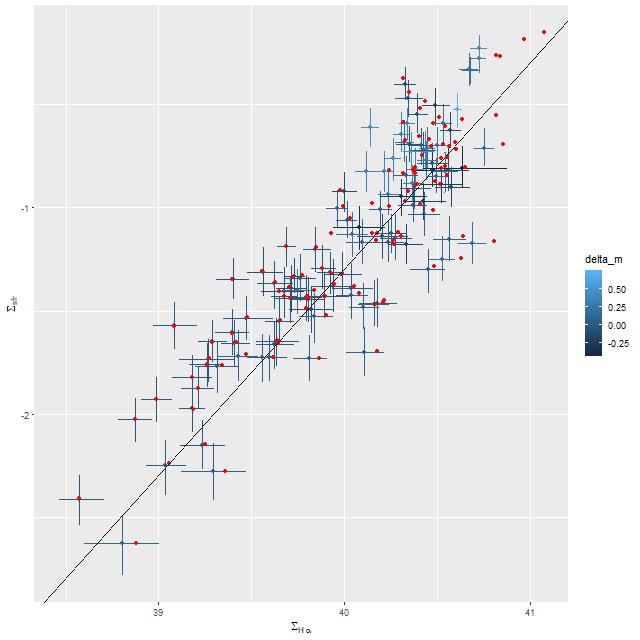
Finally, here is the relation between Hα luminosity density and star formation rate with the former corrected for attenuation using the Balmer decrement. The straight line is, once again, the calibration of Moustakas et al. Allowing the shape of the attenuation curve to vary has a larger effect on the luminosity correction than it does on the SFR estimates, but both sets of estimates straddle the line with roughly equal scatter.
SFR density vs. Hα luminosity density. Red points are point estimates for unmodified Calzetti attenuation.
MaNGA plateifu 9491-6101
To conclude for now, adding the more flexible attenuation prescription proposed by Salim et al. has some quantitative effects on model posteriors, but so far at least qualitative inferences aren’t significantly affected. I haven’t yet looked in detail at star formation histories or at effects on metallicity or metallicity evolution. I’ve been skeptical that SFH modeling constrains stellar metallicity or (especially) metallicity evolution well, but perhaps it’s time to take another look.
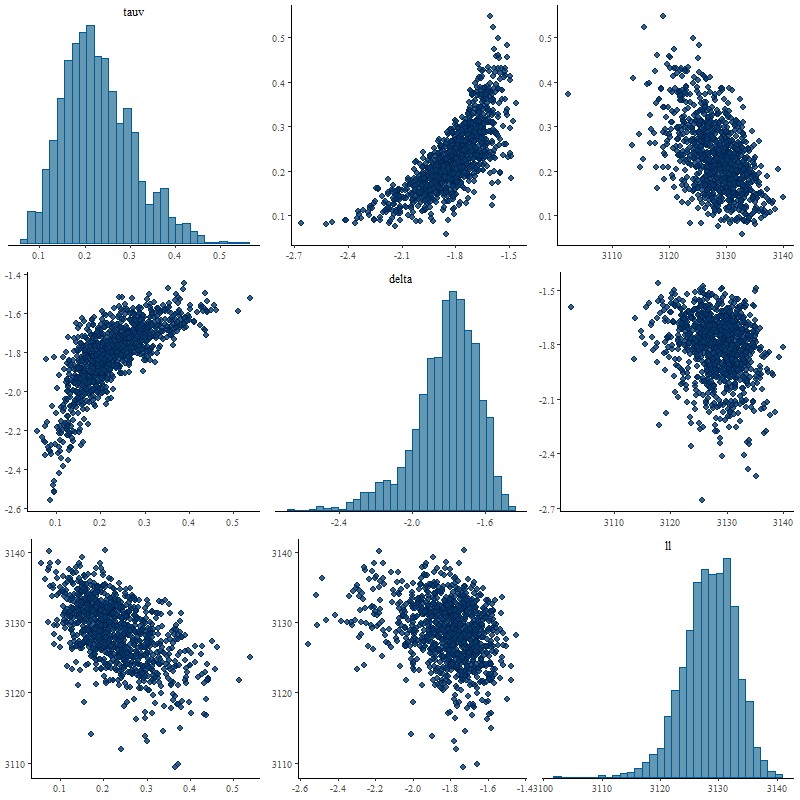
Here’s a problem that isn’t a huge surprise but that I hadn’t quite anticipated. I initially chose, without a lot of thought, a prior \(\delta \sim \mathcal{N}(0, 0.5)\) for the slope parameter delta in the modified Calzetti relation from the last post. This seemed reasonable given Salim et al.’s result showing that most galaxies have slopes \(-0.1 \lesssim \delta \lesssim +1\) (my wavelength parameterization reverses the sign of \(\delta\) ). At the end of the last post I made the obvious comment that if the modeled optical depth is near 0 the data can’t constrain the shape of the attenuation curve and in that case the best that can be hoped for is the model to return the prior for delta. Unfortunately the actual model behavior was more complicated than that for a spectrum that had a posterior mean tauv near 0:
Pairs plot of parameters tauv and delta, plus summed log likelihood with “loose” prior on delta.
Although there weren’t any indications of convergence issues in this run experts in the Stan community often warn that “banana” shaped posteriors like the joint distribution of tauv and delta above are difficult for the HMC algorithm in Stan to explore. I also suspect the distribution is multi-modal and at least one mode was missed, since the fit to the flux data as indicated by the summed log-likelihood is slightly worse than the unmodified Calzetti model.
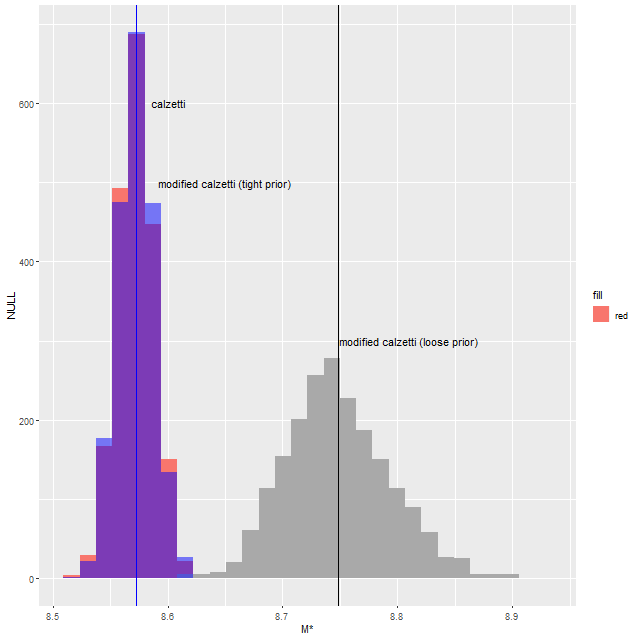
A value of \(\delta\) this small actually reverses the slope of the attenuation curve, making it larger in the red than in the blue. It also resulted in a stellar mass estimate about 0.17 dex larger than the original model, which is well outside the statistical uncertainty:
Stellar mass estimates for loose and tight priors on delta + unmodified Calzetti attenuation curve
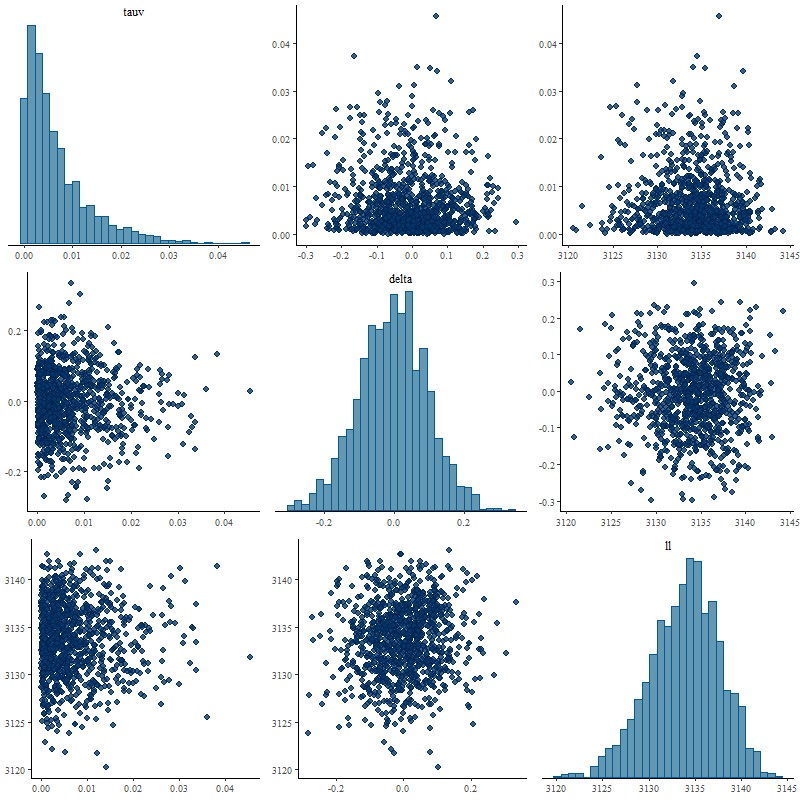
I next tried a tighter prior on delta of 0.1 for the scale parameter, with the following result:
Pairs plot of parameters tauv and delta, plus summed log likelihood with “tight” prior on delta.
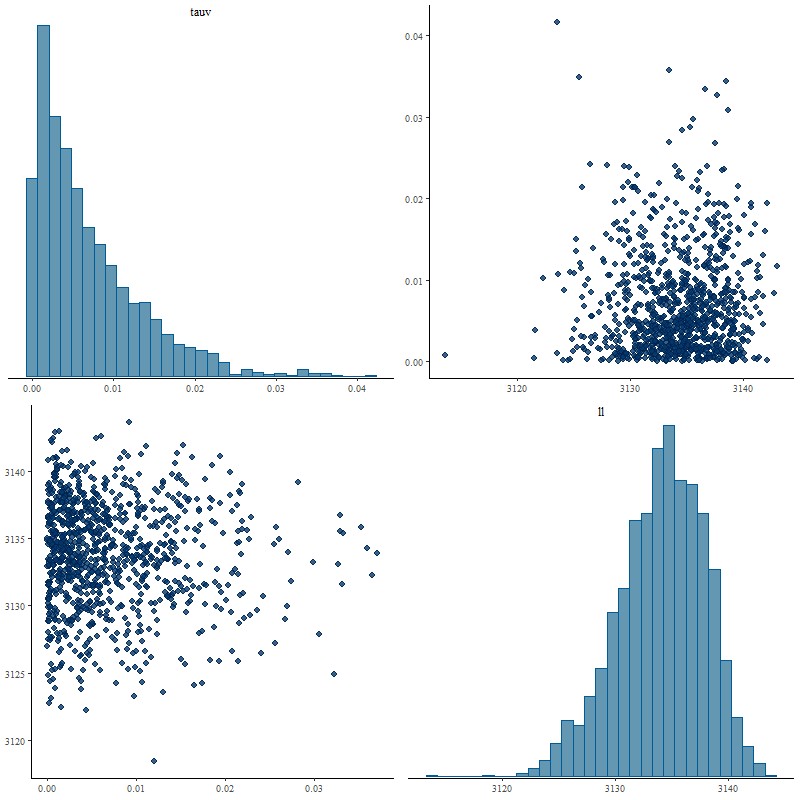
Now this is what I hoped to see. The marginal posterior of delta almost exactly returns its prior, properly reflecting the inability of the data to say anything about it. The posterior of tauv looks almost identical to the original model with a very slightly longer tail:
Pairs plot of parameters tauv and summed log likelihood, unmodified Calzetti attenuation curve
So this solves one problem but now I must worry that the prior is too tight in general since Salim’s results predict a considerably larger spread of slopes. As a first tentative test I ran another spectrum from the same spiral galaxy (this is mangaid 1-382712) that had moderately large attenuation in the original model (1.08 ± 0.04) with both “tight” and “loose” priors on delta with the following results:
Joint posterior of parameters tau and delta with “tight” priorJoint posterior of parameters tau and delta with “loose” prior
The distributions of tauv look nearly the same, while delta shrinks very slightly towards 0 with a tight prior, but with almost the same variance. Some shrinkage towards Calzetti’s original curve might be OK. Anyway, on to a larger sample.
I finally got around to reading a paper by Salim, Boquien, and Lee (2018), who proposed a simple modification to Calzetti‘s well known starburst attenuation relation that they claim accounts for most of the diversity of curves in both star forming and quiescent galaxies. For my purposes their equation 3, which summarizes the relation, can be simplified in two ways. First, for mostly historical reasons optical astronomers typically quantify the effect of dust with a color excess, usually E(B-V). If the absolute attenuation is needed, which is certainly the case in SFH modeling, the ratio of absolute to “selective” attenuation, usually written as \(\mathrm{R_V = A_V/E(B-V)}\) is needed. Parameterizing attenuation by color excess adds an unnecessary complication for my purposes. Salim et al. use a family of curves that differ only in a “slope” parameter \(\delta\) in their notation. Changing \(\delta\) changes \(\mathrm{R_V}\) according to their equation 4. But I have always parametrized dust attenuation by optical depth at V, \(\tau_V\) so that the relation between intrinsic and observed flux is
Note that parameterizing by optical depth rather than total attenuation \(\mathrm{A_V}\) is just a matter of taste since they only differ by a factor 1.08. The wavelength dependent part of the relationship is the same.
The second simplification results from the fact that the UV or 2175Å “bump” in the attenuation curve will never be redshifted into the spectral range of MaNGA data and in any case the subset of the EMILES library I currently use doesn’t extend that far into the UV. That removes the bump amplitude parameter and the second term in Salim et al.’s equation 3, reducing it to the form
The published expression for \(k(\lambda)\) in Calzetti et al. (2000) is given in two segments with a small discontinuity due to rounding at the transition wavelength of 6300Å. This produces a small unphysical discontinuity when applied to spectra, so I just made a polynomial fit to the Calzetti curve over a longer wavelength range than gets used for modeling MaNGA or SDSS data. Also, I make the wavelength parameter \(y = 5500/\lambda\) instead of using the wavelength in microns as in Calzetti. With these adjustments Calzetti’s relation is, to more digits than necessary:
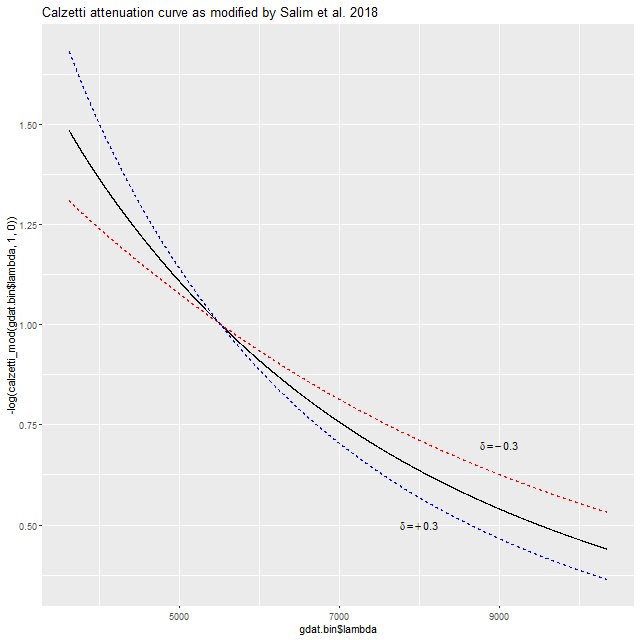
Note that δ has the opposite sign as in Salim et al. Here is what the curve looks like over the observer frame wavelength range of MaNGA. A positive value of δ produces a steeper attenuation curve than Calzetti’s, while a negative value is shallower (grayer in common astronomers’ jargon). Salim et al. found typical values to range between about -0.1 and +1.
Calzetti attenuation relation with modification proposed by Salim, Boquien, and Lee (2018). Dashed lines show shift in curve for their parameter δ = ± 0.3.
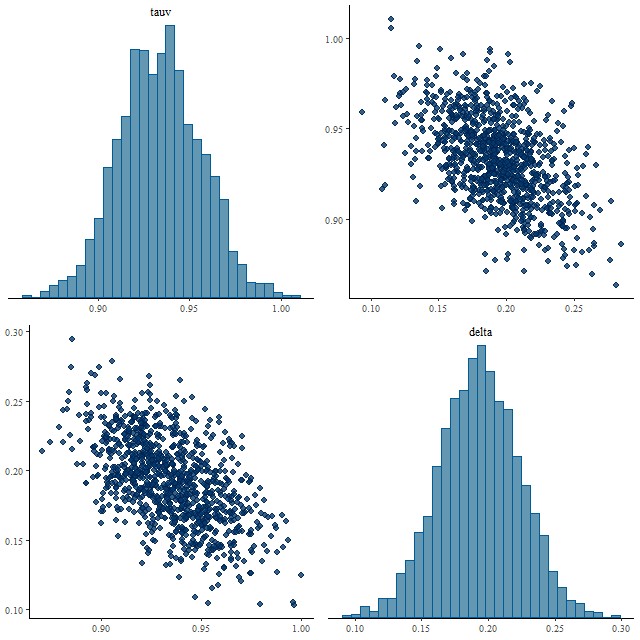
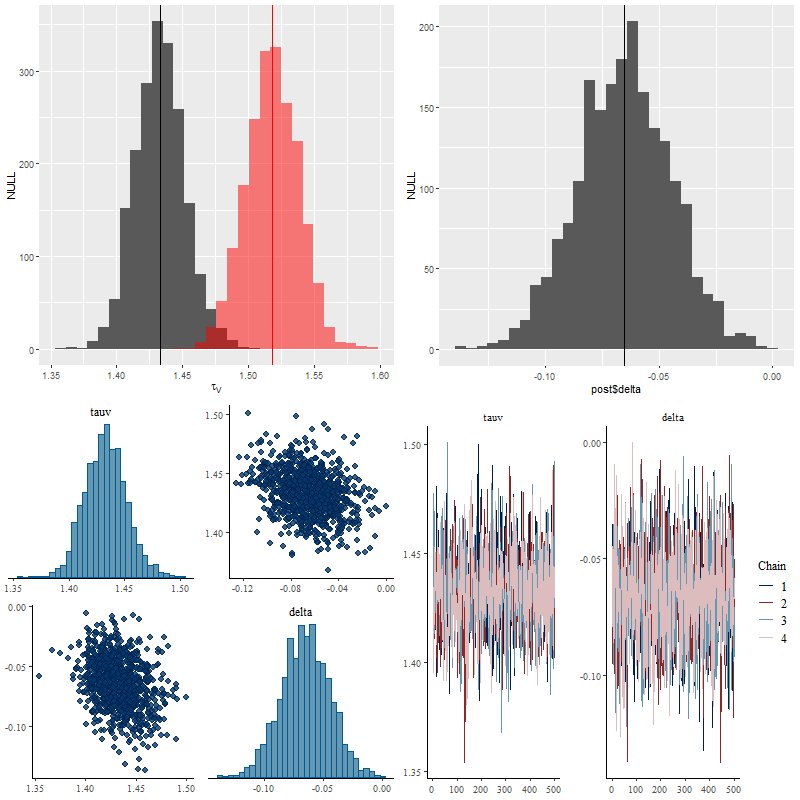
For a first pass attempt at modeling some real data I chose a spectrum from near the northern nucleus of Mrk 848 but outside the region of the highest velocity outflows. This spectrum had large optical depth \(\tau_V \approx 1.52\) and the unusual nature of the galaxy gave reason to think its extinction curve might differ significantly from Calzetti’s.
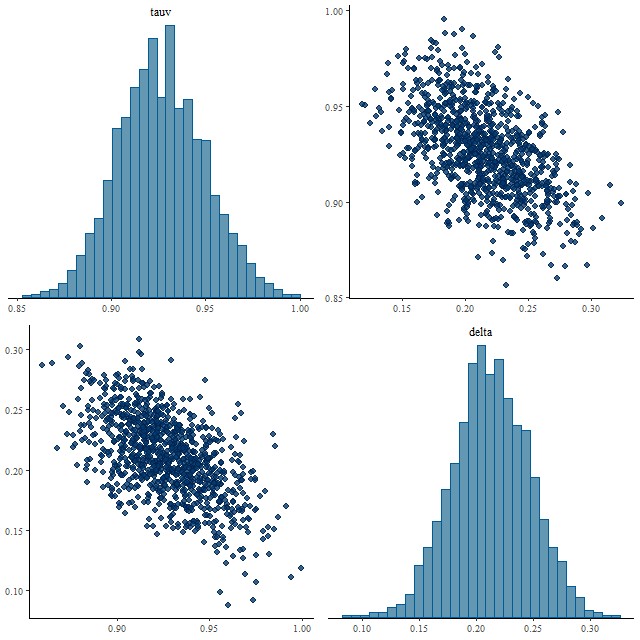
Encouragingly, the Stan model converged without difficulty and with an acceptable run time. Below are some posterior plots of the two attenuation parameters and a comparison to the optical depth parameter in the unmodified Calzetti dust model. I used a fairly informative prior of Normal(0, 0.5) for the parameter delta. The data actually constrain the value of delta, since its posterior marginal density is centered around -0.06 with a standard deviation of just 0.02. In the pairs plot below we can see there’s some correlation between the posteriors of tauv and delta, but not so much as to be concerning (yet).
(TL) marginal posteriors of optical depth parameter for Calzetti (red) and modified (dark gray) relation.
(TR) parameter δ in modified Calzetti relation
(BL) pairs plot of `tauv` and `delta`
(BR) trace plots of `tauv` and `delta`
Overall the modified Calzetti model favors a slightly grayer attenuation curve with lower absolute attenuation:
Total attenuation for original and modified Calzetti relations. Spectrum was randomly selected near the northern nucleus or Mrk 848.
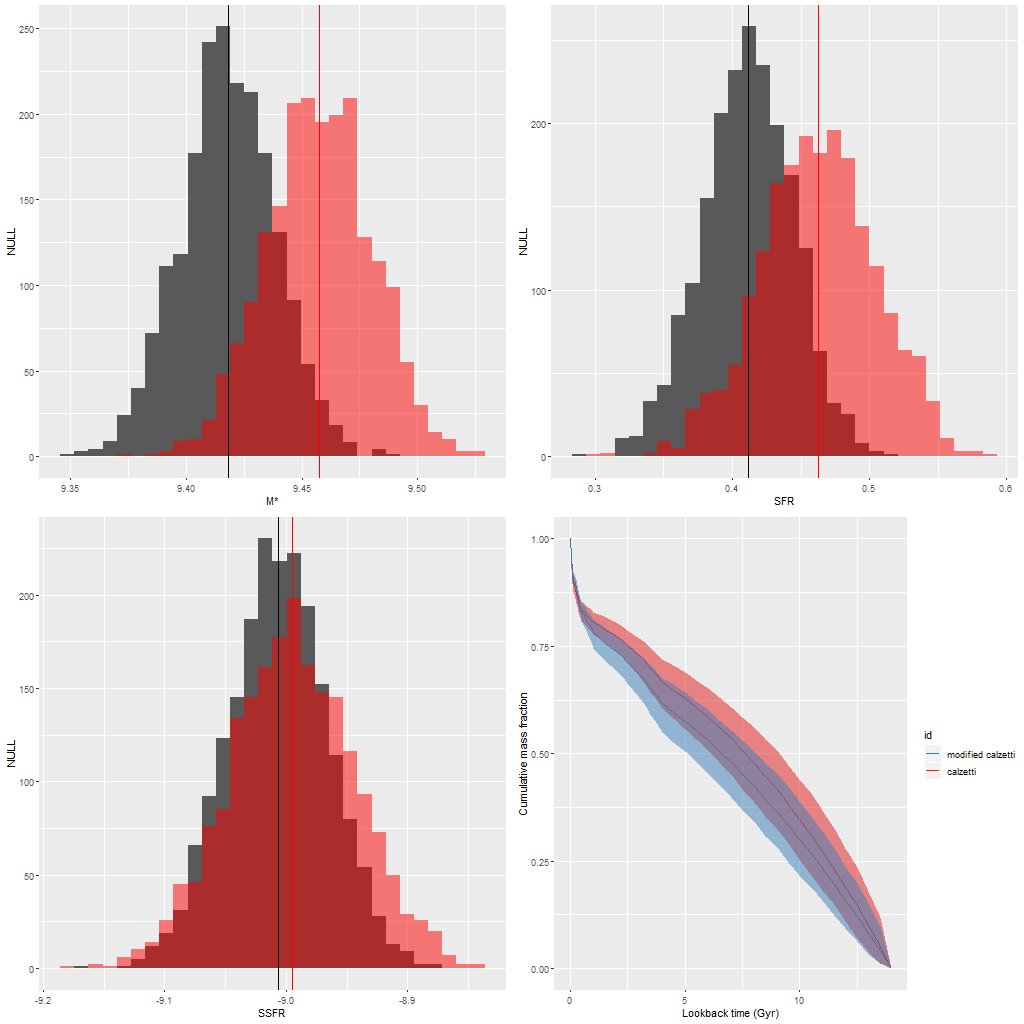
Here’s a quick look at the effect of the model modification on some key quantities. In the plot below the red symbols are for the unmodified Calzetti attenuation model, and gray or blue the modified one. These show histograms of the marginal posterior density of total stellar mass, 100Myr averaged star formation rate, and specific star formation rate. Because the modified model has lower total attenuation it needs fewer stars, so the lower stellar mass (by ≈ 0.05 dex) is a fairly predictable consequence. The star formation rate is also lower by a similar amount, making the estimates of specific star formation rate nearly identical.
The lower right pane compares model mass growth histories. I don’t have any immediate intuition about how the difference in attenuation models affects the SFH models, but notice that both show recent acceleration in star formation, which was a main theme of my Markarian 848 posts.
Stellar mass, SFR,, SSFR, and mass growth histories for original and modified Calzetti attenuation relation.
So, this first run looks ok. Of course the problem with real data is there’s no way to tell if a model modification actually brings it closer to reality — in this case it did improve the fit to the data a little bit (by about 0.2% in log likelihood) but some improvement is expected just from adding a parameter.
My concern right now is that if the dust attenuation is near 0 the data can’t constrain the value of δ. The best that can happen in this situation is for the model to return the prior. Preliminary investigation of a low attenuation spectrum (per the original model) suggests that in fact a tighter prior on delta is needed than what I originally chose.
One more post making use of the measurement error model introduced last time and then I think I move on. I estimate the dust attenuation of the starlight in my SFH models using a Calzetti attenuation relation parametrized by the optical depth at V (τV). If good estimates of Hα and Hβ emission line fluxes are obtained we can also make optical depth estimates of emission line regions. Just to quickly review the math we have:
\(A_\lambda = \mathrm{e}^{-\tau_V k(\lambda)}\)
where \(k(\lambda)\) is the attenuation curve normalized to 1 at V (5500Å) and \(A_\lambda\) is the fractional flux attenuation at wavelength λ. Assuming an intrinsic Balmer decrement of 2.86, which is more or less the canonical value for H II regions, the estimated optical depth at V from the observed fluxes is:
The SFH models return samples from the posteriors of the emission lines, from which are calculated sample values of \(\tau_V^{bd}\).
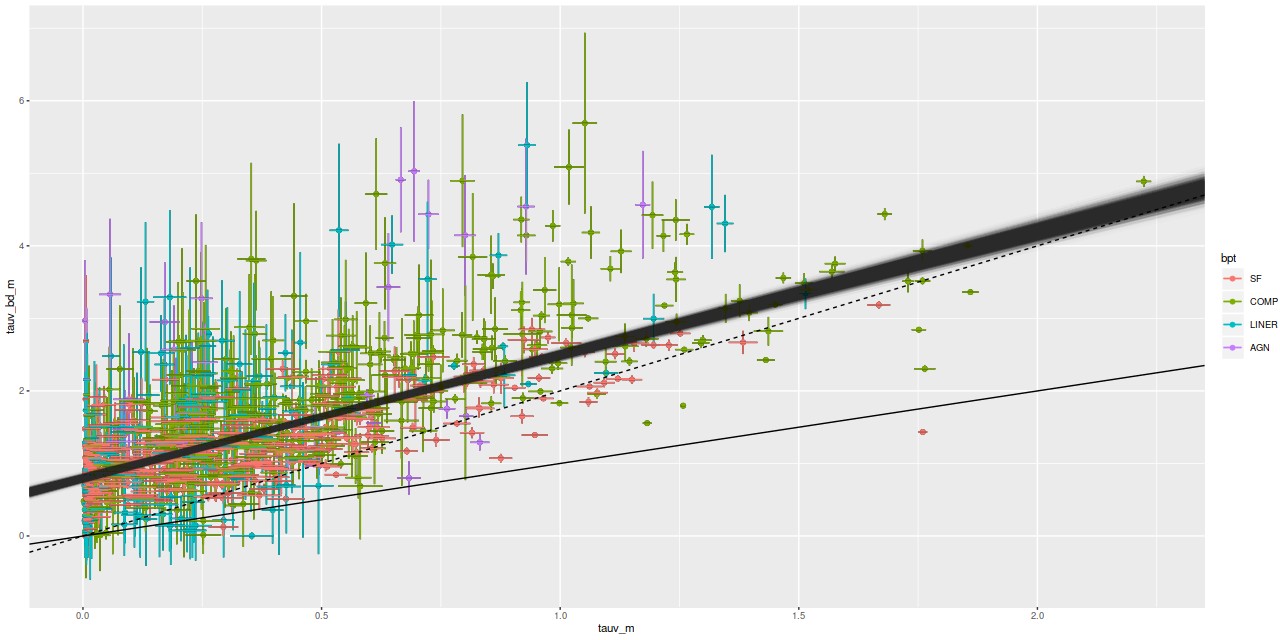
Here is a plot of the estimated attenuation from the Balmer decrement vs. the SFH model estimates for all spectra from the 28 galaxy sample in the last two posts that have BPT classifications other than no or weak emission. Error bars are ±1 standard deviation.
τVbd vs. τVstellar for 962 binned spectra in 28 MaNGA galaxies. Cloud of lines is from fit described in text. Solid and dashed lines are 1:1 and 2:1 relations.
It’s well known that attenuation in emission line regions is larger than that of the surrounding starlight, with a typical reddening ratio of ∼2 (among many references see the review by Calzetti (2001) and Charlot and Fall (2000)). One thing that’s clear in this plot that I haven’t seen explicitly mentioned in the literature is that even in the limit of no attenuation of starlight there typically is some in the emission lines. I ran the regression with measurement error model on this data set, and got the estimated relationship \(\tau_V^{bd} = 0.8 (\pm 0.05) + 1.7 ( \pm 0.09) \tau_V^{stellar}\) with a rather large estimated scatter of ≈ 0.45. So the slope is a little shallower than what’s typically assumed. The non-zero intercept seems to be a robust result, although it’s possible the models are systematically underestimating Hβ emission. I have no other reason to suspect that, though.
The large scatter shouldn’t be too much of a surprise. The shape of the attenuation curve is known to vary between and even within galaxies. Adopting a single canonical value for the Balmer decrement may be an oversimplification too, especially for regions ionized by mechanisms other than hot young stars. My models may be overdue for a more flexible prescription for attenuation.
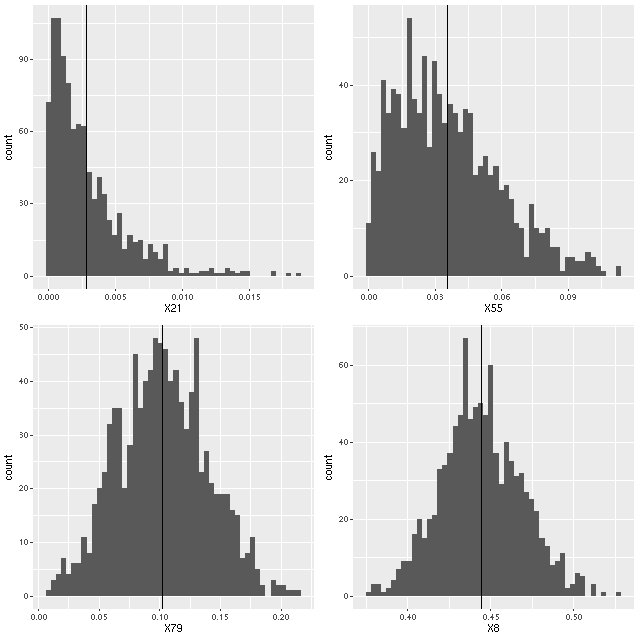
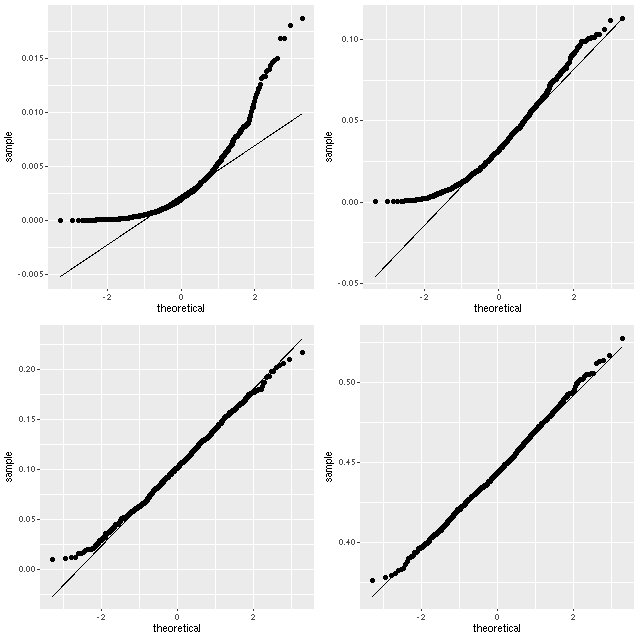
The statistical assumptions of the measurement error model are a little suspect in this data set as well. The attenuation parameter tauv is constrained to be positive in the models. When it wants to be near 0 the samples from the posterior will pile up near 0 with a tail of larger values, looking more like draws from an exponential or gamma distribution than a gaussian. Here is an example from one galaxy in the sample that happens to have a wide range of mean attenuation estimates:
Histograms of samples from the marginal posterior distributions of the parameter tauv for 4 spectra from plateifu 8080-3702.
I like theoretical quantile-quantile plots better than histograms for this type of visualization:
Normal quantile-quantile plots of samples from the marginal posterior distributions of the parameter tauv for 4 spectra from plateifu 8080-3702.
I haven’t looked at the distributions of emission line ratios in much detail. They might behave strangely in some cases too. But regardless of the validity of the statistical model applied to this data set it’s apparent that there is a fairly strong correlation, which is encouraging.
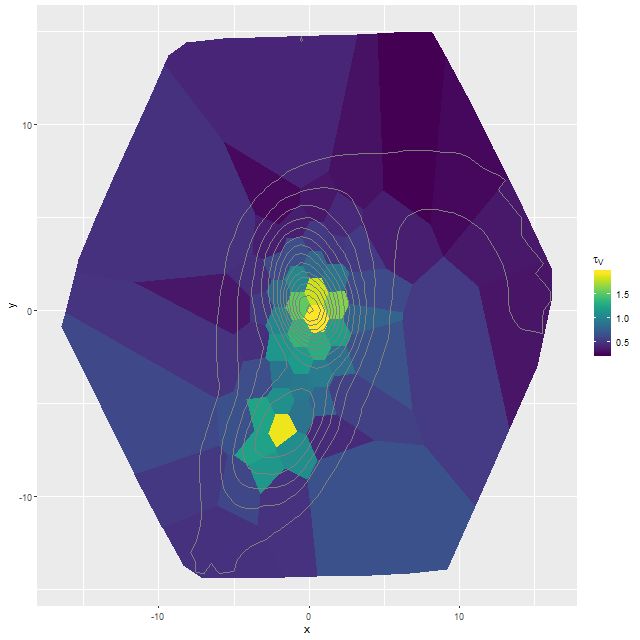
I’m going to close out my analysis of Mrk 848 for now with three topics. First, dust. Like most SED fitting codes mine produces an estimate of the internal attenuation, which I parameterize with τV, the optical depth at V assuming a conventional Calzetti attenuation curve. Before getting into a discussion for context here is a map of the posterior mean estimate for the higher S/N target binning of the data. For reference isophotes of the synthesized r band surface brightness taken from the MaNGA data cube are superimposed:
Map of posterior mean of τV from single component dust model fits with Calzetti attenuation
This compares reasonably well with my visual impression of the dust distribution. Both nuclei have very large dust optical depths with a gradual decline outside, while the northern tidal tail has relatively little attenuation.
The paper by Yuan et al. that I looked at last time devoted most of its space to different ways of modeling dust attenuation, ultimately concluding that a two component dust model of the sort advocated by Charlot and Fall (2000) was needed to bring results of full spectral fitting using ppxf on the same MaNGA data as I’ve examined into reasonable agreement with broad band UV-IR SED fits.
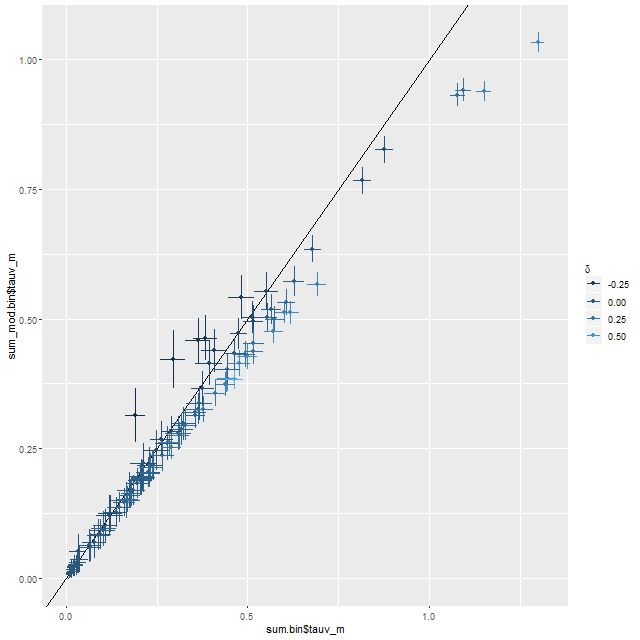
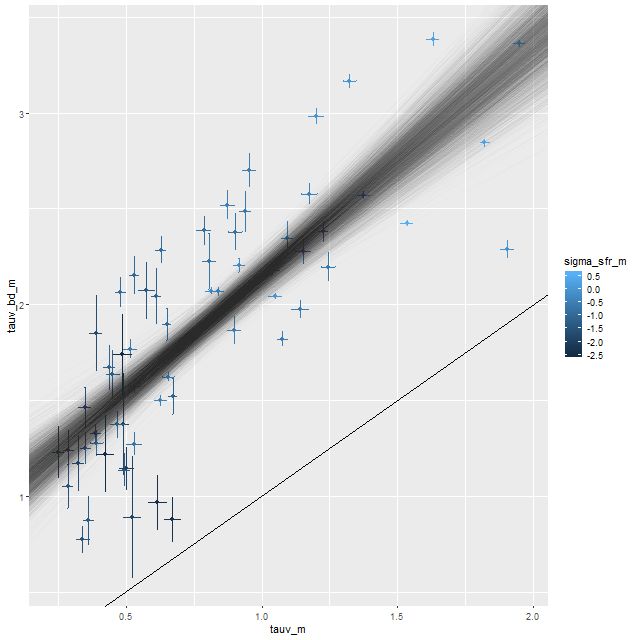
There’s certainly some evidence in support of this. Here is a plot I’ve shown for some other systems of the estimated optical depth of the Balmer emission line emitting regions based on the observed vs. theoretical Balmer decrement (I’ve assumed an intrinsic Hα/Hβ ratio of 2.86 and a Calzetti attenuation relation) plotted against the optical depth estimated from the SFH models, which roughly estimates the amount of reddening needed to fit the SSP model spectra to the observed continuum. In some respects this is a more favorable system than some I’ve looked at because Hβ emission is at measurable levels throughout. On the other hand there is clear evidence that multiple ionization mechanisms are at work, so the assumption of a single canonical value of Hα/Hβ is likely too simple. This might be a partial cause of the scatter in the modeled relationship, but it’s encouraging that there is a strong positive correlation (for those who care, the correlation coefficient between the mean values is 0.8).
The solid line in the graph below is 1:1. The semi-transparent cloud of lines are the sampled relationships from a Bayesian errors in variables regression model. The mean (and marginal 1σ uncertainty) is \(\tau_{V, bd} = (0.94\pm 0.11) + (1.21 \pm 0.12) \tau_V\). So the estimated relationship is just a little steeper than 1:1 but with an offset of about 1, which is a little different from the Charlot & Fall model and from what Yuan et al. found, where the youngest stellar component has about 2-3 times the dust attenuation as the older stellar population. I’ve seen a similar not so steep relationship in every system I’ve looked at and don’t know why it differs from what is typically assumed. I may look into it some day.
τV estimated from Balmer decrement vs. τV from model fits. Straight line is 1:1 relation. Cloud of lines are from Bayesian errors in variables regression model.
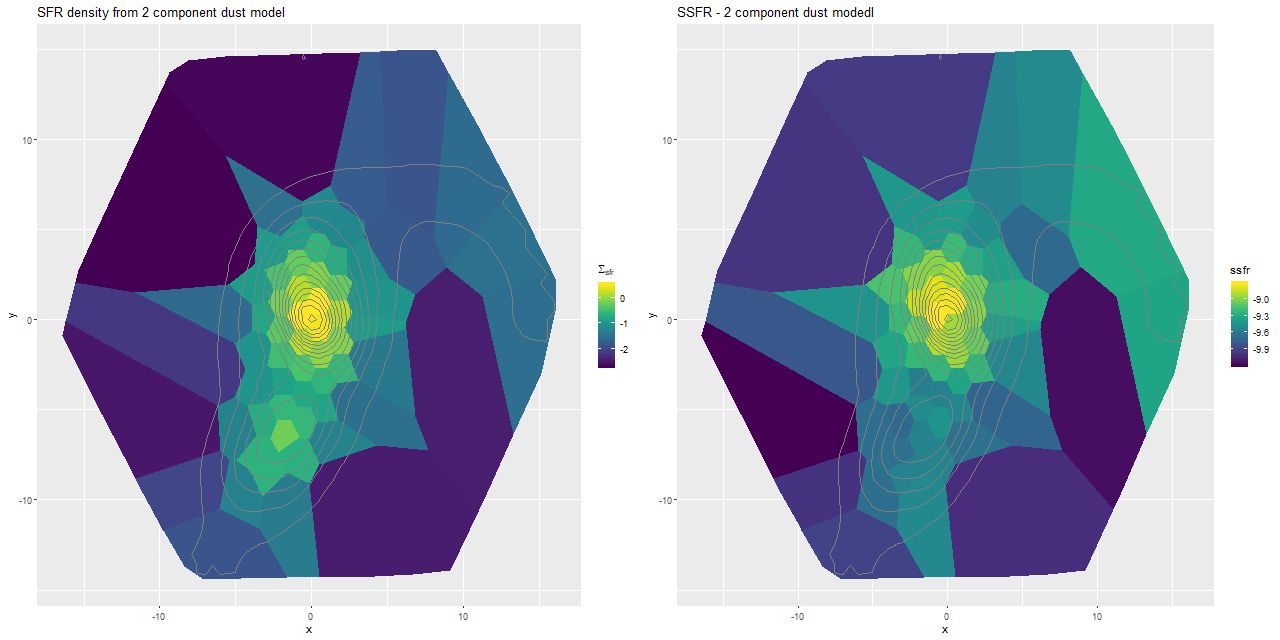
I did have time to run some 2 dust component SFH models. This is a very simple extension of the single component models: a single optical depth is applied to all SSP spectra. A second component with the optical depth fixed at 1 larger than the bulk value is applied only to the youngest model spectra, which recall were taken from unevolved SSPs from the updated BC03 library. I’m just going to show the most basic results from the models for now in the form of maps of the SFR density and specific star formation rate. Compared to the same maps displayed at the end of the last post there is very little difference in spatial variation of these quantities. The main effect of adding more reddened young populations to the model is to replace some of the older light — this is the well known dust-age degeneracy. The average effect was to increase the stellar mass density (by ≈ 0.05 dex overall) while slightly decreasing the 100Myr average SFR (by ≈ 0.04 dex), leading to an average decrease in specific star formation rate of ≈ 0.09 dex. While there are some spatial variations in all of these quantities no qualitative conclusion changes very much.
Results from fits with 2 component dust models.
(L) SFR density.
(R) Specific SFR
Contrary to Yuan+ I don’t find a clear need for a 2 component dust model. Without trying to replicate their results I can’t say why exactly we disagree, but I think they erred in aggregating the MaNGA data to the lowest spatial resolution of the broad band photometric data they used, which was 5″ radius. There are clear variations in physical conditions on much smaller scales than this.
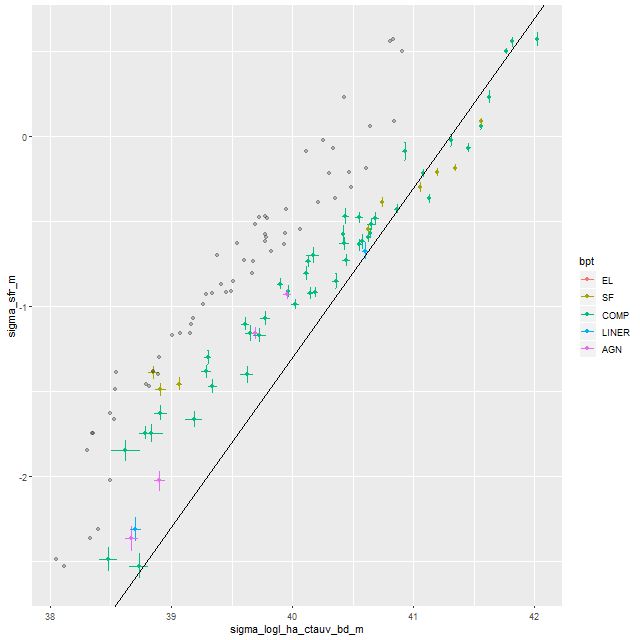
Second topic: the most widely accepted SFR indicator in visual wavelengths is Hα luminosity. Here is another plot I’ve displayed previously: a simple scatterplot of Hα luminosity density against the 100Myr averaged star formation rate density from the SFH models. Luminosity density is corrected for attenuation estimated from the Balmer decrement and for comparison the light gray points are the uncorrected values. Points are color coded by BPT class determined in the usual manner. The straight line is the Hα – SFR calibration of Moustakas et al. (2006), which in turn is taken from earlier work by Kennicutt.
Model SFR density vs. Hα luminosity density corrected for extinction estimated from Balmer decrement. Light colored points are uncorrected for extinction. Straight line is Hα-SFR calibration from Moustakas et al. (2006)
Keeping in mind that Hα emission tracks star formation on timescales of ∼10 Myr1to the extent that ionization is caused by hot young stars. There are evidently multiple ionizing sources in this system, but disentangling their effects seems hard. Note there’s no clear stratification by BPT class in this plot. this graph strongly supports the scenario I outlined in the last post. At the highest Hα luminosities the SFR-Hα trend nicely straddles the Kennicutt-Moustakas calibration, consistent with the finding that the central regions of the two galaxies have had ∼constant or slowly rising star formation rates in the recent past. At lower Hα luminosities the 100Myr average trends consistently above the calibration line, implying a recent fading of star formation.
The maps below add some detail, and here the perceptual uniformity of the viridis color palette really helps. If star formation exactly tracked Hα luminosity these two maps would look the same. Instead the northern tidal tail in particular and the small piece of the southern one within the IFU footprint are underluminous in Hα, again implying a recent fading of star formation in the peripheries.
(L) Hα luminosity density, corrected for extinction estimated by Balmer decrement.
(R) SFR density (100 Myr average).
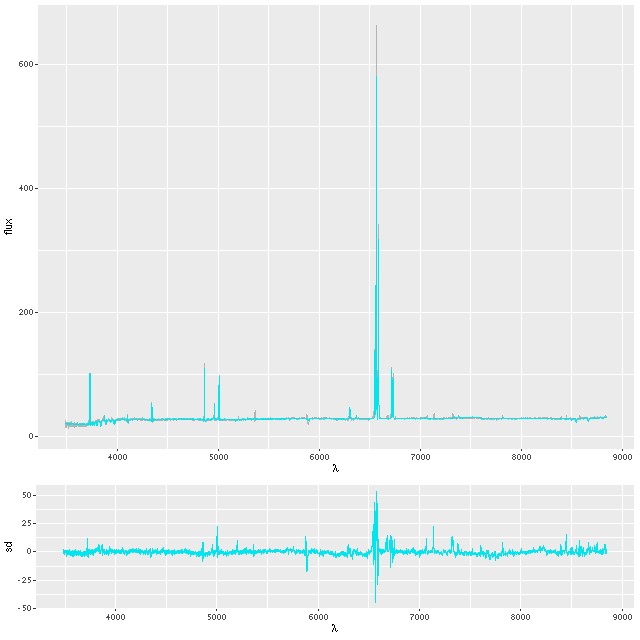
Final topic: the fit to the data, and in particular the emission lines. As I’ve mentioned previously I fit the stellar contribution and emission lines simultaneously, generally assuming separate single component gaussian velocity dispersions and a common system velocity offset. This works well for most galaxies, but for active galaxies or systems like this one with complex velocity profiles maybe not so much. In particular the northern nuclear region is known to have high velocity outflows in both ionized and neutral gas due presumably to supernova driven winds. I’m just going to look at the central fiber spectrum for now. I haven’t examined the fits in detail, but in general they get better outside the immediate region of the center. First, here is the fit to the data using my standard model. In the top panel the gray line, which mostly can’t be seen, is the observed spectrum. Blue are quantiles of the posterior mean fit — this is actually a ribbon, although its width is too thin to be discernable. The bottom panel are the residuals in standard deviations. Yes, they run as large as ±50σ, with conspicuous problems around all emission lines. There are also a number of usually weak emission lines that I don’t track that are present in this spectrum.
Fit to central fiber spectrum; model with single gaussian velocity distributions.
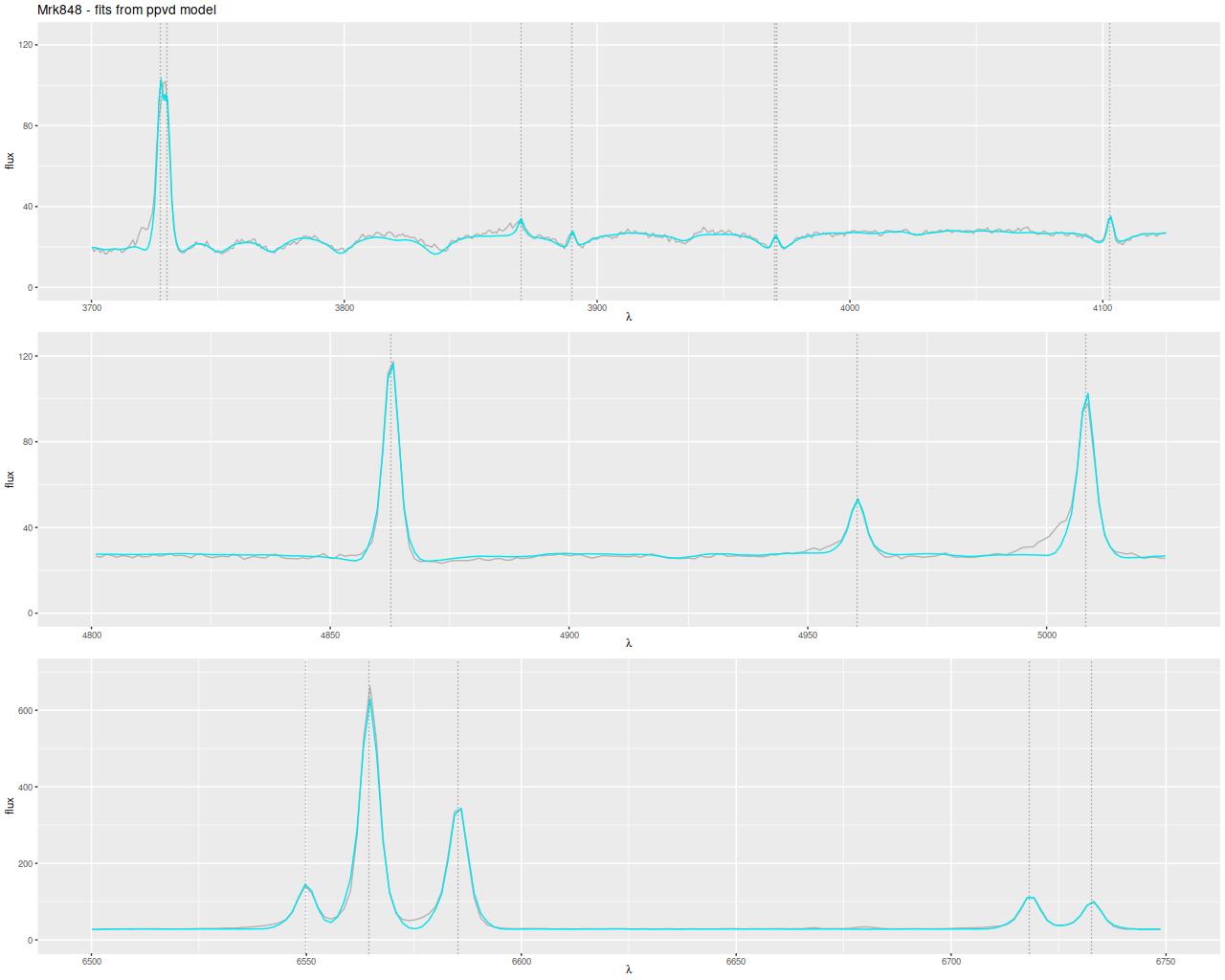
I have a solution for cases like this which I call partially parametric. I assume the usual Gauss-Hermite form for the emission lines (as in, for example, ppxf) while the stellar velocity distribution is modeled with a convolution kernel2I think I’ve discussed this previously but I’m too lazy to check right now. If I haven’t I’ll post about it someday. Unfortunately the Stan implementation of this model takes at least an order of magnitude longer to execute than my standard one, which makes its wholesale use prohibitively expensive. It does materially improve the fit to this spectrum although there are still problems with the stronger emission lines. Let’s zoom in on a few crucial regions of the spectrum:
Zoomed in fit to central fiber spectrum using “partially parametric velocity distribution” model. Grey: observed flux. Blue: model.
The two things that are evident here are the clear sign of outflow in the forbidden emission lines, particularly [O III] and [N II], while the Balmer lines are relatively more symmetrical as are the [S II] doublet at 6717, 6730Å. The existence of rather significant residuals is likely because emission is coming from at least two physically distinct regions while the fit to the data is mostly driven by Hα, which as usual is the strongest emission line. The fit captures the emission line cores in the high order Balmer lines rather well and also the absorption lines on the blue side of the 4000Å break except for the region around the [Ne III] line at 3869Å.
I’m mostly interested in star formation histories, and it’s important to see what differences are present. Here is a comparison of three models: my standard one, the two dust component model, and the partially parametric velocity dispersion model:
Detailed star formation history models for the northern nucleus using 3 different models.
In fact the differences are small and not clearly outside the range of normal MCMC variability. The two dust model slightly increases the contribution of the youngest stellar component at the expense of slightly older contributors. All three have the presumably artifactual uptick in SFR at 4Gyr and very similar estimated histories for ages >1 Gyr.
I still envision a number of future model refinements. The current version of the official data analysis pipeline tracks several more emission lines than I do at present and has updated wavelengths that may be more accurate than the ones from the SDSS spectro pipeline. It might be useful to allow at least two distinct emission line velocity distributions, with for example one for recombination lines and one for forbidden. Unfortunately the computational expense of this sort of generalization at present is prohibitive.
I’m not impressed with the two dust model that I tried, but there may still be useful refinements to the attenuation model to be made. A more flexible form of the Calzetti relation might be useful for example3there is recent relevant literature on this topic that I’m again too lazy to look up.
My initial impression of this system was that it was a clear false positive that was selected mostly because of a spurious BPT classification. On further reflection with MaNGA data available it’s not so clear. A slight surprise is the strong Balmer absorption virtually throughout the system with evidence for a recent shut down of star formation in the tidal tails. A popular scenario for the formation of K+A galaxies through major mergers is that they experience a centrally concentrated starburst after coalescence which, once the dust clears and assuming that some feedback mechanism shuts off star formation leads to a period of up to a Gyr or so with a classic K+A signature4I previously cited Bekki et al. 2005, who examine this scenario in considerable detail.Capturing a merger in the instant before final coalescence provides important clues about this process.
To the best of my knowledge there have been no attempts at dynamical modeling of this particular system. There is now reasonably good kinematic information for the region covered by the MaNGA IFU, and there is good photometric data from both HST and several imaging surveys. Together these make detailed dynamical modeling technically feasible. It would be interesting if star formation histories could further constrain such models. Being aware of the multiple “degeneracies” between stellar age and other physical properties I’m not highly confident, but it seems provocative that we can apparently identify distinct stages in the evolutionary history of this system.
In this post I’m going to take a quick look at detailed, spatially resolved star formation histories for this galaxy pair and briefly compare to some of the recent literature. Before I start though, here is a reprocessed version of the blog’s cover picture with a different crop and some Photoshop curve and level adjustments to brighten the tidal tails a bit. Also I cleaned up some more of the cosmic ray hits.
Markarian 848 – full resolution crop with level curve adjustment
HST ACS/WFC F435W/F814W/F160 false color image
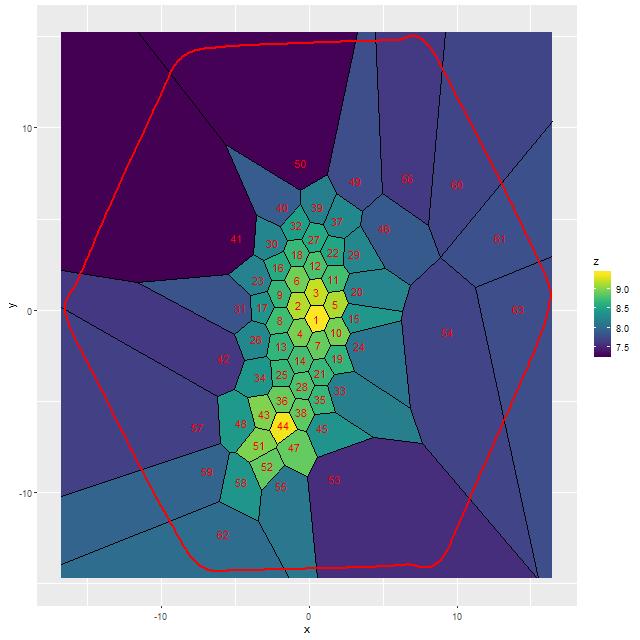
The SFH models I’m going to discuss were based on MaNGA data binned to a more conservative signal to noise target than in the last post. I set a target S/N of 25 — Cappellari’s Voronoi binning algorithm has a hard coded acceptance threshold of 80% of the target S/N, which results in all but a few bins having an actual S/N of at least 20. This produced a binned data set with 63 bins. The map below plots the modeled (posterior mean log) stellar mass density, with clear local peaks in the bins covering the positions of the two nuclei. The bins are numbered in order of increasing distance of the weighted centroids from the IFU center, which corresponds with the position of the northern nucleus. The center of bin 1 is slightly offset from the northern nucleus by about 2/3″. For reference the angular scale at the system redshift (z ≈ 0.040) is 0.8 kpc/” and the area covered by each fiber is 2 kpc2.
Although there’s nothing in the Voronoi binning algorithm that guarantees this it did a nice job of partitioning the data into physically distinct regions, with the two nuclei, the area around the northern nucleus, and the bridge between them all binned to single fiber spectra. The tidal tails are sliced into several pieces while the very low surface brightness regions to the NE and SW get a few bins.
Stellar mass density and bin numbers ordered in increasing distance from northern nucleus
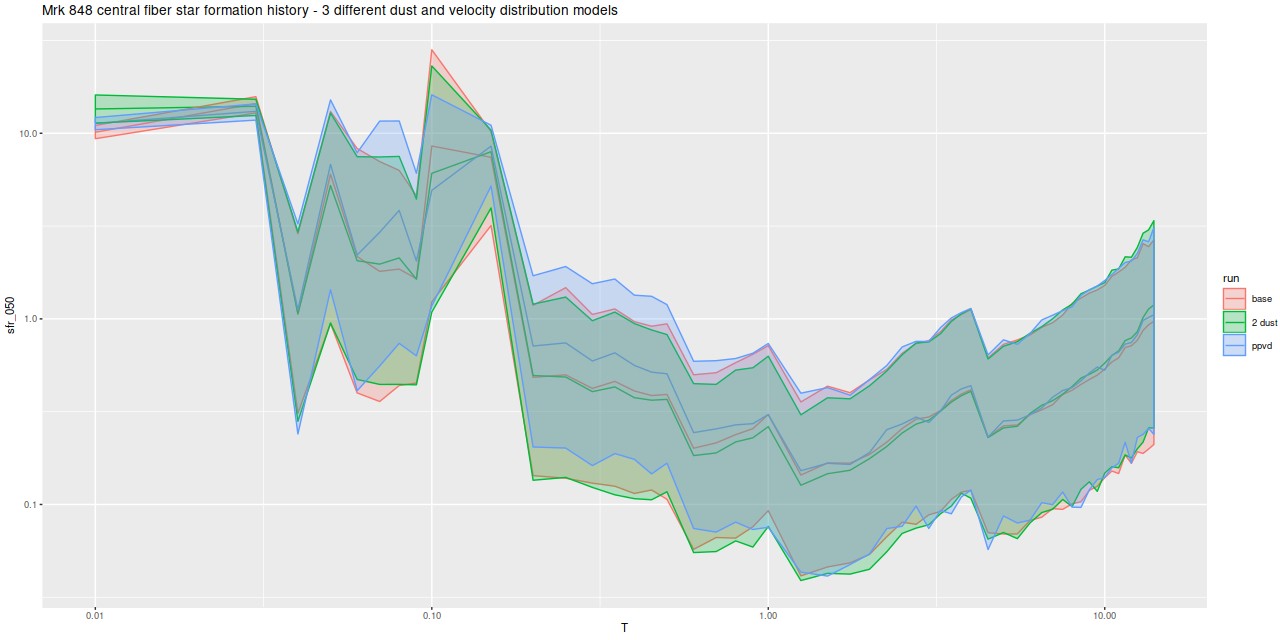
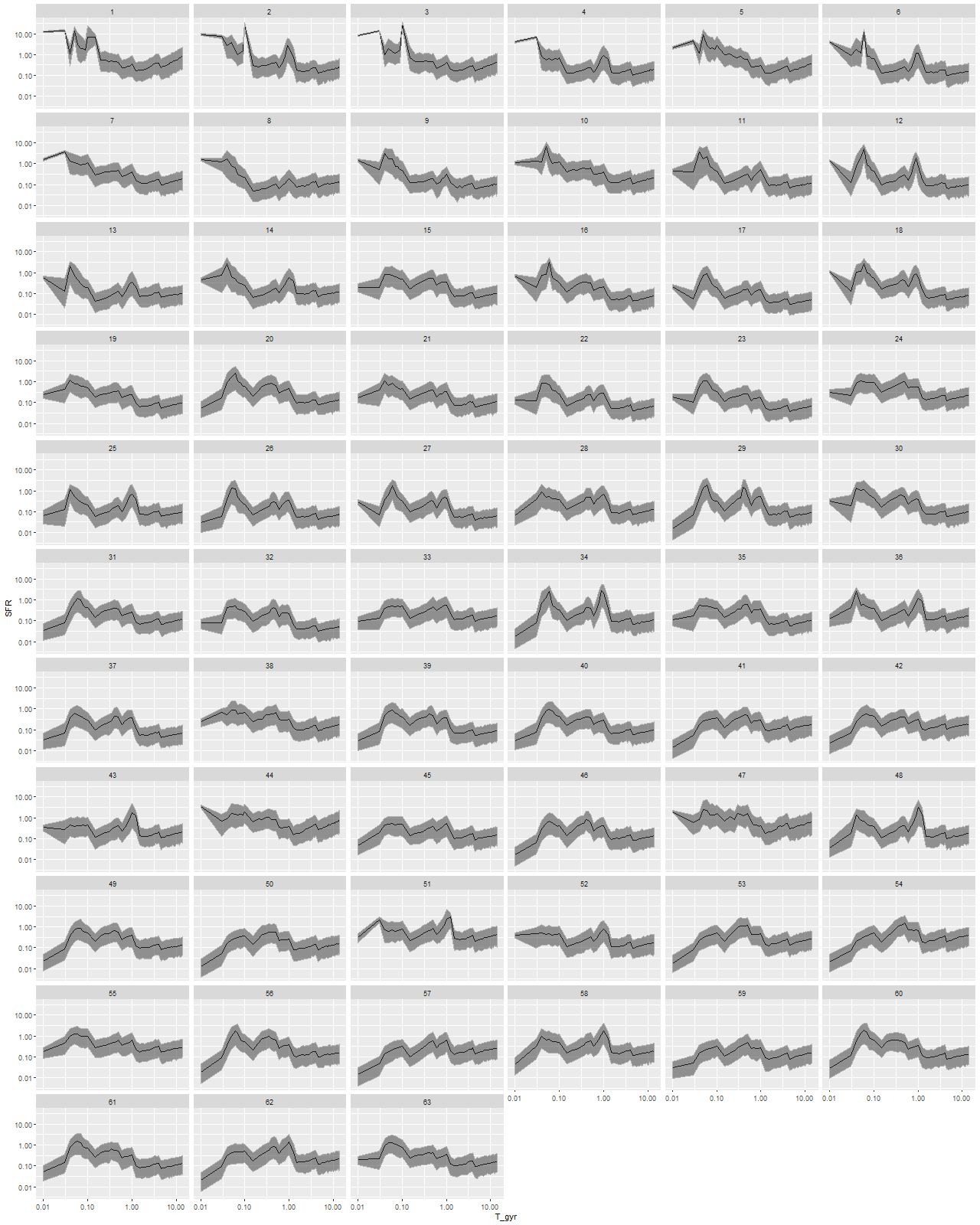
I modeled star formation histories with my largest subset of the EMILES library consisting of SSP model spectra for 54 time bins and 4 metallicity bins. As in previous exercises I fit emission lines and the stellar contribution simultaneously, which is riskier than usual in this system because some regions, especially near the northern nucleus, have complex velocity structures producing emission line profiles that are far from single component gaussians. I’ll look at this in more detail in a future post, but for now let’s just take these SFH models at face value and see where they lead. As I’ve done in several previous posts what’s plotted below are star formation rates in solar masses/year over cosmic time, counting backwards from “now” (now being when the light left the galaxies about 500Myr ago). This time I’ve used log scaling for both axes and for the first time in these posts I’ve displayed results for every bin ordered by increasing distance from the IFU center. The first two rows cover the central ~few kpc region surrounding the northern nucleus. The southern nucleus covered by bin 44 is in row 8, second from left. Both the time and SFR scales are the same for all plots. The black lines are median posterior marginal estimates and the ribbons are 95% posterior confidence intervals.
Star formation histories for the Voronoi binned regions shown in the previous map. Numbers at the top correspond to the bin numbers in the map.
Browsing through these, all regions show ∼constant or gradually decreasing star formation up to about 1 Gyr ago1You may recall I’ve previously noted there is always an uptick in star formation rate at 4 Gyr in my EMILES based models, and that’s seen in all of these as well. This must be spurious, but I still don’t know the cause.. This of course is completely normal for spiral galaxies.
Most regions covered by the IFU began to show accelerated and in some areas bursts of star formation at ∼1 Gyr. In more than half of the bins the maximum star formation rate occurred around 40-60 Myr ago, with a decline or in some areas cessation of star formation more recently. In the central few kpc around the northern nucleus on the other hand star formation accelerated rapidly beginning ~100 Myr ago and continues at high levels. The southern nucleus has a rather different estimated recent star formation history, with no (visible) starburst and instead gradually increasing SFR to a recent maximum. Ongoing star formation at measurable levels is much more localized in the southern central regions and weaker by factors of several than the northern companion.
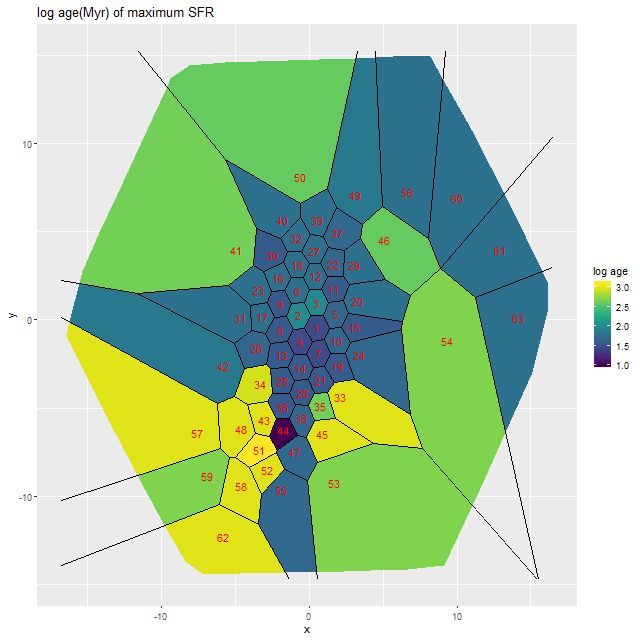
Here’s a map that I thought would be too noisy to be informative, but turns out to be rather interesting. This shows the spatial distribution of the lookback time to the epoch of maximum star formation rate estimated by the marginal posterior mean. The units displayed are log(age) in Myr; recall that I added unevolved SSP models from the 2013 update of the BC03 models to the BaSTI based SSP library, assigning them an age of 10Myr, so a value of 1 here basically means ≈ now.
Look back time to epoch of maximum star formation rate as estimated by marginal posterior mean. Units are log(age in Myr).
To summarize, there have been three phases in the star formation history of this system: a long period of normal disk galaxy evolution; next beginning about 1 Gyr ago widespread acceleration of the SFR with localized bursts; and now, within the past 50-100 Myr a rapid increase in star formation that’s centrally concentrated in the two nuclei (but mostly the northern one) while the peripheral regions have had suppressed activity.
I previously reviewed some of the recent literature on numerical studies of galaxy mergers. The high resolution simulations of Hopkins et al. (2013) and the movies available online at http://www.tapir.caltech.edu/~phopkins/Site/Movies_sbw_mgr.html seem especially relevant, particularly their Milky Way and Sbc analogs. They predict a general but clumpy enhancement of star formation at around the time of first pericenter passage; a stronger, centrally concentrated starburst at the time of second pericenter passage, with a shorter period of separation before coalescence. Surprisingly perhaps, the merger timescales for both their MW and Sbc analogs are very similar to my SFH models, with ∼ 1 Gyr between first and second perigalactic passage and another few 10’s of Myr to final coalescence.
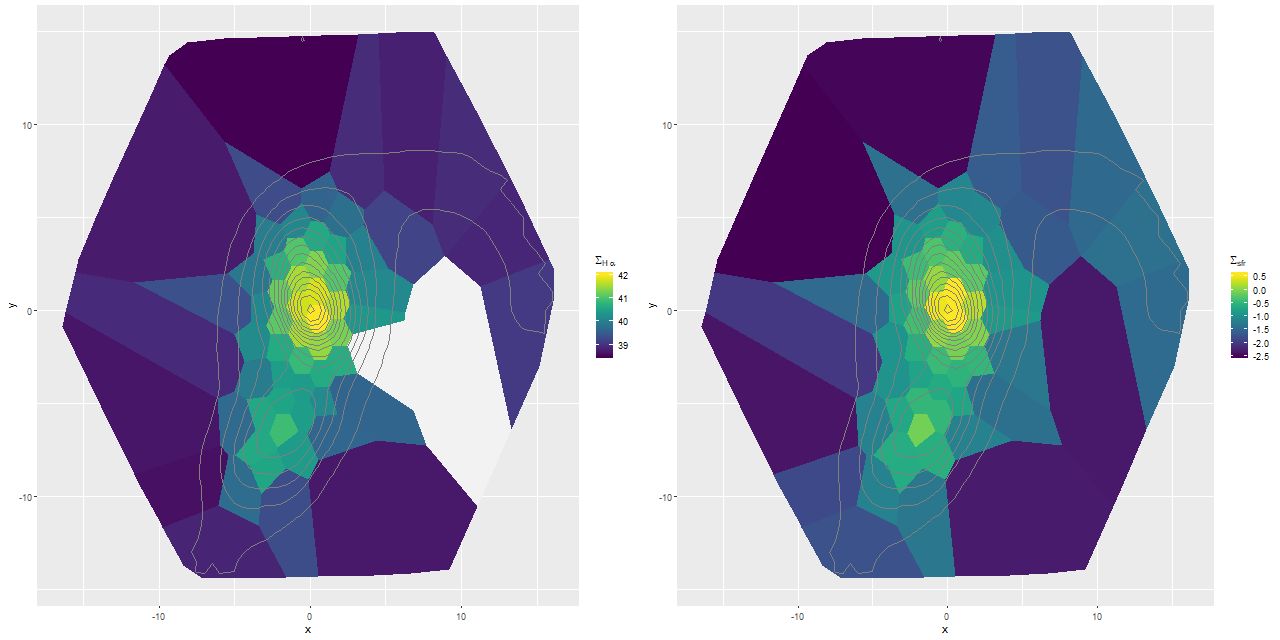
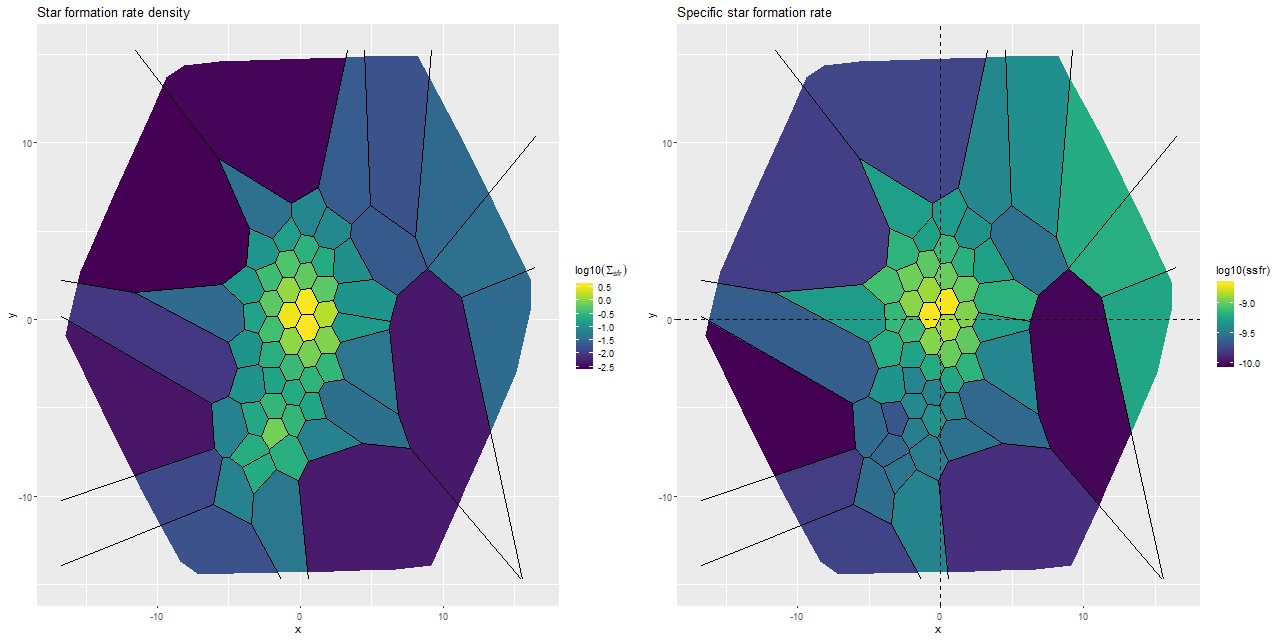
I’m going to wrap up with maps of the (posterior mean estimates) of star formation rate density (as \(\log10(\mathsf{M_\odot/yr/kpc^2})\)) and specific star formation rate, which has units log10(yr-1). These are 100Myr averages and recall are based solely on the SSP template contributions.
(L) Star formation rate density
(R) Specific star formation rate
Several recent papers have made quantitative estimates of star formation rates in this system, which I’ll briefly review. Detailed comparisons are somewhat difficult because both the timescales probed by different SFR calibrators differ and the spatial extent considered in the studies varies, so I’ll just summarize reported results and compare as best as I can.
Yuan et al. (2018) modeled broad band UV-IR SED’s taking data from GALEX, SDSS, and Spitzer; and also did full spectrum fitting using ppxf on the same MaNGA data I’ve been examining. They divided the data into 5″ (≈ 4 kpc) radius regions covering the tidal tails and each nucleus. The broadband data were fit with parametric SFH models with a pair of exponential bursts (one fixed at 13Gyr, the other allowed to vary). From the parametric models they estimated the SFR in the northern and southern nuclei as 76 and 11 \(\mathsf{M_\odot/yr}\) (the exact interpretation of this value is unclear to me). For comparison I get values of 33 and 13 \(\mathsf{M_\odot/yr}\) for regions within 4 kpc of the two nuclei by calculating the average (posterior mean) star forming density and multiplying by π*42. They also calculated 100Myr average SFRs from full spectrum fitting with several different dust models and also from the Hα luminosity, deriving estimates that varied by an order of magnitude or more. Qualitatively we reach similar conclusions that the tails had earlier starbursts and are now forming stars at lower rates than their peak, and also that the northern nucleus has recent star formation a factor of several higher than the southern.
Cluver et al. (2017) were primarily trying to derive SFR calibrations for WISE W3/W4 filters using samples of normal star forming and LIRG/ULIRGs (including this system) with Spitzer and Herschel observations. Oddly, although they tabulate IR luminosities for the entire sample they don’t tabulate SFR estimates. But plugging into their equations 5 and 7 I get star formation rate estimates of just about 100 \(\mathsf{M_\odot/yr}\). These are global values for the entire system. For comparison I get a summed SFR for my models of ≈ 45 \(\mathsf{M_\odot/yr}\) (after making a 0.2 dex adjustment for fiber overlap).
Tsai and Hwang (2015) also used IR data from Spitzer and conveniently present results for quantities I track using the same units. Their estimates of the (log) stellar mass density, SFR density, and specific star formation rate in the central kpc of (presumably) the northern nucleus were 9.85±0.09, 0.43±0.00, and -9.39±0.09 respectively. For comparison in the fiber that covers the northern nucleus my models return 9.41±0.02, 0.57±0.04, and -8.84±0.04. For the 6 fibers closest to the nucleus the average stellar mass density drops to 9.17 and SFR density to about 0.39. So, our SFR estimates are surprisingly close while my mass density estimate is as much as 0.7 dex lower.
Finally, Vega et al. (2008) performed starburst model fits to broadband IR-radio data. They estimated a burst age of about 60Myr for this system, with average SFR over the burst of 225 \(\mathsf{M_\odot/yr}\) and current (last 10 Myr) SFR 87 \(\mathsf{M_\odot/yr}\) in a starforming region of radius 0.27kpc. Their model has optical depth of 33 at 1 μm, which would make their putative starburst completely invisible at optical wavelengths. Their calculations assumed a Salpeter IMF, which would add ≈0.2 dex to stellar masses and star formation rates compared to the Kroupa IMF used in my models.
Overall I find it encouraging that my model SFR estimates are no worse than factors of several lower than what are obtained from IR data — if the Vega+ estimate of the dust optical depth is correct most of the star formation is well hidden. Next time I plan to look at Hα emission and tie up other loose ends. If time permits before I have to drop this for a while I may look at two component dust models.
This galaxy1also known as VV705, IZw 107, IRAS F15163+4255, among others has been my feature image since I started this blog. Why is that besides that it’s kind of cool looking? As I’ve mentioned before I took a shot a few years ago at selecting a sample of “transitional” galaxies from the SDSS spectroscopic sample, that is ones that may be in the process of rapidly shutting down star formation2See for example Alatalo et al. (2017) for recent usage of this terminology.. I based the selection on a combination of strong Hδ absorption and either weak emission lines or line ratios other than pure starforming, using measurements from the MPA-JHU pipeline. This galaxy pair made the sample based on the spectrum centered on the northern nucleus (there is also a spectrum of the southern nucleus from the BOSS spectrograph, but no MPA pipeline measurements). Well now, these galaxies are certainly transitioning to something, but they’re probably not shutting down star formation just yet. Simulations of gas rich mergers generally predict a starburst that peaks around the time of final coalescence. There is also significant current star formation, as high as 100-200 \(M_\odot/yr\) per various literature estimates, although it is mostly hidden. So on the face of it at least this appears to be a false positive. This was also an early MaNGA target, and one of a small number where both nuclei of an ongoing merger are covered by a single IFU:
Markarian 848. SDSS image thumbnail with MaNGA IFU footprint.
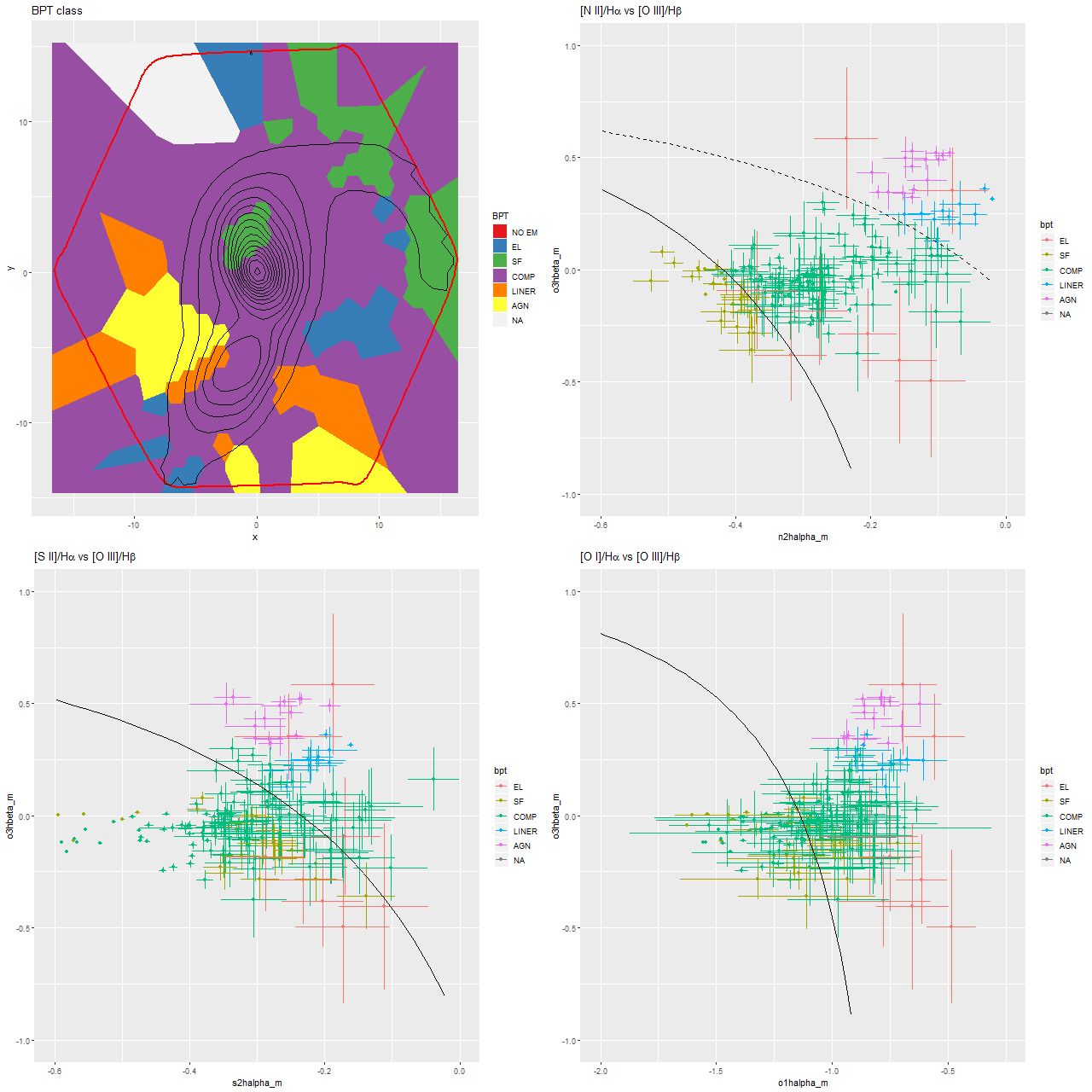
Today I’m going to look at a few results of my analysis of the IFU data that aren’t too model dependent to get some insight into why this system was selected. As usual I’m looking at the stacked RSS data rather than the data cubes, and for this exercise I Voronoi binned the spectra to a very low target SNR of 6.25. This leaves most of the fibers unbinned in the vicinity of the two nuclei. First, here is a map of BPT classification based on the [O III]/Hβ vs. [N II]/Hα diagnostic as well as scatterplots of several BPT diagnostics. Unfortunately the software I use for visualizing binned maps extends the bins out to the edge of the bounding rectangle rather than the hexagonally shaped edge of the data, which is outlined in red. Also note that different color coding is used for the scatter plots than the map. The contour lines in the map are arbitrarily spaced isophotes of the synthesized R band image supplied with the data cube.
Map of BPT class determined from [O III]/Hβ vs. [N II}/Hα diagnostic diagram, and BPT diagnostics for [N II], [S II] and [O I]. Curves are boundary lines form Kewley et al. (2006).
What’s immediately obvious is that most of the area covered by the IFU including both nuclei fall in the so-called “composite” region of the [N II]/Hα BPT diagram. This gets me back to something I’ve complained about previously. There was never a clear physical justification for the composite designation (which recall was first proposed in Kauffmann et al. 2003), and the upper demarcation line between “pure” AGN and composite systems as shown in the graph at upper right was especially questionable. It’s now known if it wasn’t at the turn of the century (which I doubt is the case) that a number of ionization mechanisms can produce line ratios that fall generally in the composite/LINER regions of BPT diagnostics. Shocks in particular are important in ongoing mergers. High velocity outflow of both ionized and neutral gas have been observed in the northern nucleus by Rupke and Veillux (2013), which they attributed to supernova driven winds.
The evidence for AGN in either nucleus is somewhat ambiguous. Fu et al. (2018) called this system a binary AGN, but that was based on the “composite” BPT line ratios from the same MaNGA data as we are examining (their map, by the way, is nearly identical to mine; see also Yuan et al. 2018). By contrast Vega et al. 2008 were able to fit the entire SED from NIR to radio frequencies with a pure starburst model and no AGN contribution at all, while more recently Dietrich et al. 2018 estimated the AGN fraction to be around 0.25 from NIR to FIR SED fitting. A similar conclusion that both nuclei contain both a starburst and AGN component was reached by Vardoulaki et al. 2015 based on radio and NIR data. One thing I haven’t seen commented on in the MaNGA data that possibly supports the idea that the southern nucleus harbors an AGN is that the regions with unambiguous AGN-like optical emission line ratios are fairly symmetrically located on either side of the southern nucleus and separated from it by ∼1-2 kpc. This could perhaps indicate the AGN is obscured from our view but visible from other angles.
There are also several areas with starforming emission line ratios just to the north and east of the northern nucleus and scattered along the northern tidal tail (the southern tail is largely outside the IFU footprint). In the cutout below taken from a false color composite of the F435W+F814W ACS images several bright star clusters can be seen just outside the more heavily obscured nuclear region, and these are likely sources of ionizing photons.
Markarian 848 nuclei. Cutout from HST ACS F814W+F435W images.
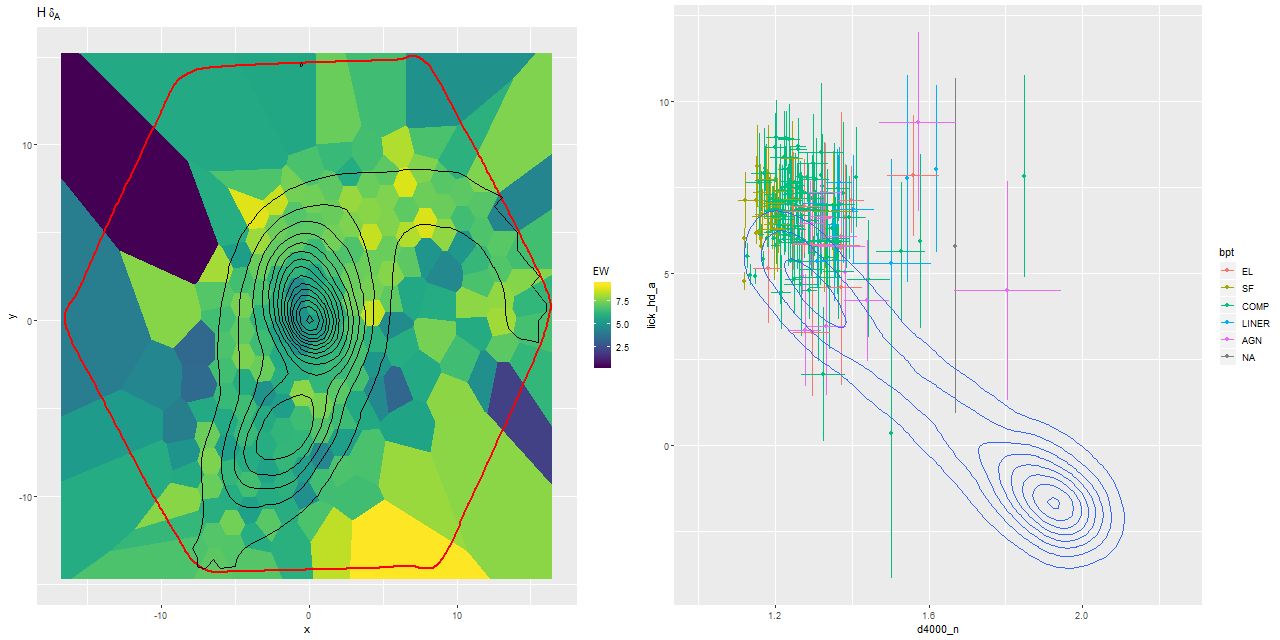
Finally turning to the other component of the selection criteria, here is a map of the (pseudo) Lick HδA index and a plot of the widely used HδA vs Dn(4000) diagnostic. It’s a little hard to see a clear pattern in the map because this is a rather noisy index, but strong Balmer absorption is seen pretty much throughout, with the highest values outside the two nuclei and especially along the northern tidal tail.
Location in the Hδ – D4000 plane doesn’t uniquely constrain the star formation history, but the contour plot taken from a largish sample of SDSS spectra from the NGP is clearly bimodal, with mostly starforming galaxies at upper left and passively evolving ones at lower right, with a long “green valley” in between. Simple models of post-starburst galaxies will loop upwards and to the right in this plane as the starburst ages before fading towards the green valley. This is exactly where most of points in this diagram lie, which certainly suggests an interesting recent star formation history.
(L) Map of HδA index.
(R) HδA vs Dn(4000) index. Contours are for a sample of SDSS spectra from the north galactic pole.
I’m going to end with a bit of speculation. In simulations of gas rich major mergers the progenitors generally complete 2 or 3 orbits before final coalescence, with some enhancement of star formation during the perigalactic passages and perhaps some ebbing in between. This process plays out over hundreds of Myr to some Gyr. What I think we are seeing now is the 2nd or third encounter of this pair, with the previous encounters having left an imprint in the star formation history.
I’ve done SFH modeling for this binning of the data, and also for data binned to higher SNR and modeled with higher time resolution models. Next post I’ll look at these in more detail.