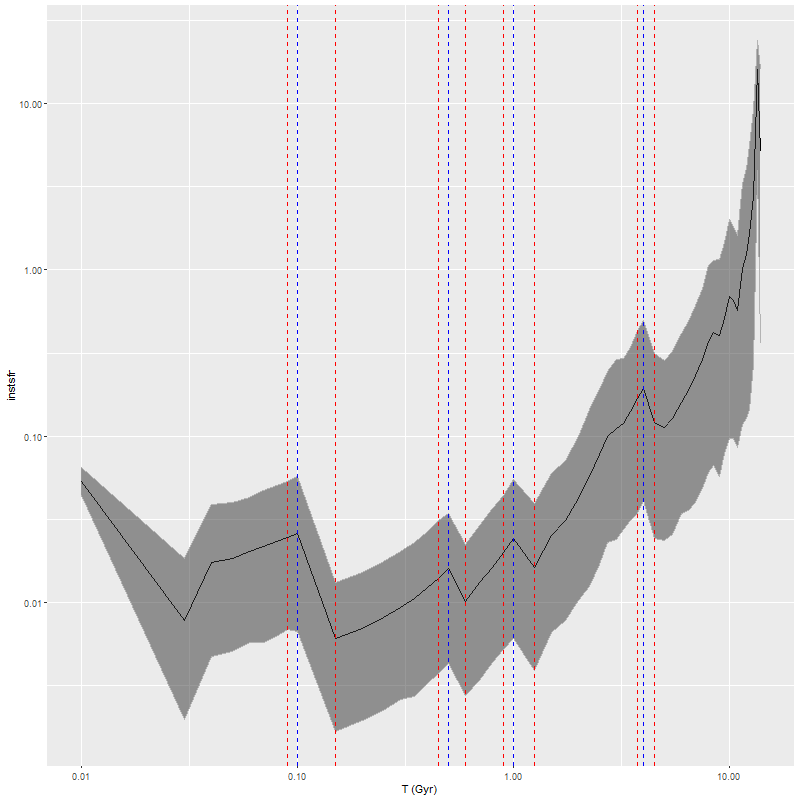
One of my favorite visualization tools for displaying results of star formation history modeling is a ribbon plot of star formation rate versus look back time. This simply plots the marginal posterior mean or median SFR along with 2.5 and 97.5th percentiles (by default) as the lower and upper boundaries of the ribbon. I’ve been using the simplest possible definition of the star formation rate, namely the total mass born in each age bin divided by the interval between the nominal age of each SSP model and the next younger. One striking feature of these plots that’s especially evident in grids of SFH models for an entire galaxy like the one shown in my last post is that there are invariably jumps in the SFR at certain specific ages as marked below. This particular example is from a sample of passively evolving Coma cluster galaxies, but the same features are seen regardless of the likely “true” star formation history.
Star formation rate history estimate – emiles with BaSTI isochrones
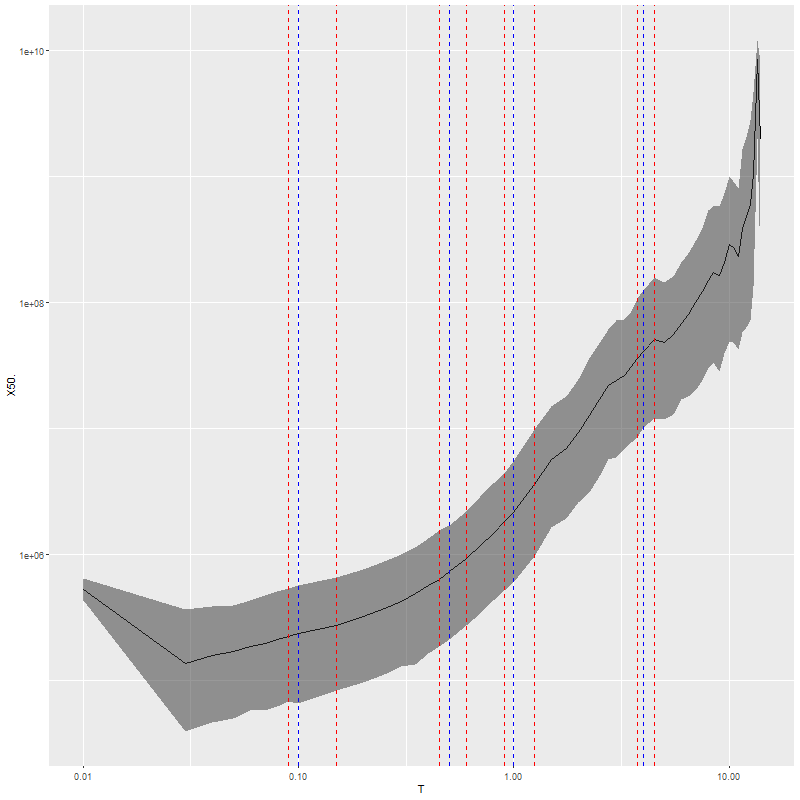
These jumps are artifacts of course: the BaSTI isochrones used for the EMILES SSP models that I currently use are tabulated at age intervals that are constant over certain age ranges, with jumps at 4 ages1100 Myr, 500 Myr, 1 Gyr, and 4 Gyr. The jumps in model SFR occur exactly at the breaks in the age intervals. This turns out to be due to an otherwise welcome feature of the SFH models that they “want” to produce SSP contributions that vary smoothly with age as shown below for the same model run. So for example the stellar mass born in the 90-100 Myr age bin per the model is about 90% of that in the 100-150 Myr bin while the time interval increases by a factor of 5, so the model SFR declines by a factor 4.5 or around 0.6 dex.
Modeled mass born in each age bin – central spectrum of plateifu 9876-12702
Can I do anything about this? Should I? Changing how I calculate the star formation rate might work — this is after all a derivative and I’m currently using the most stupidly simple numerical approximation possible. It also might help to adjust the effective ages of each SSP model. I should also look at the priors on the SSP model coefficients, although as I noted some time ago it’s hard to affect the model star formation histories much with adjustments to priors.
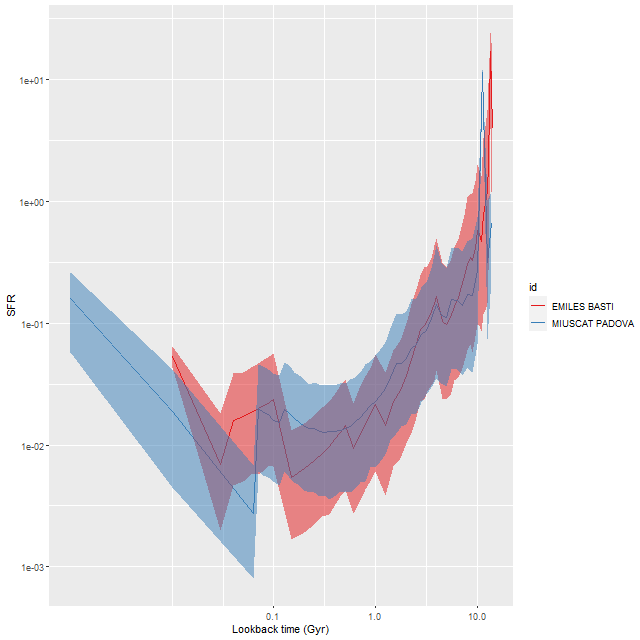
These jumps are something of a peculiarity of the BaSTI isochrones. I had previously used a subset of MILES SSP models from Padova isochrones, which are tabulated at equal logarithmic age intervals. A comparison model run lacks large jumps except for an early time burst. Since the youngest age bin in the Padova isochrones is around 60 Myr I had added two younger SSP models from an update of the BC03 library, and these show abrupt jumps in model SFR. This is also the case with the youngest age bin in my currently used EMILES library.
Comparison of star formation rate history estimates:
Red – EMILES SSP libraries with BaSTI isochrones
Blue – Miuscat SSP library with Padova isochrones
A final comment about these visualizations is that often the mode of the posterior distribution of an SSP model contribution is near 0, and it might make sense to display one sided confidence intervals since what we’re really constraining is an upper limit. I may work on this in the future.
I’m stranded at sea at the moment so I may as well make a short post. First, here is the complete Stan code of the current model that I’m running. I haven’t gotten around to version controlling this yet or uploading a copy to my github account, so this is the only non-local copy for the moment.
One thing I mentioned in passing way back in this post is that making the stellar contribution parameter vector a simplexseemed to improve sampler performance both in terms of execution time and convergence diagnostics. This was for a toy model where the inputs were nonnegative and summed to one, but it turns out to work better with real data as well. At some point I may want to resurrect old code to document this more carefully, but the main thing I’ve noticed is that post-warmup execution time per sample is often dramatically faster than previously (the execution time for the same number of warmup iterations is about the same or larger though). This appears to be largely due to needing fewer “leapfrog” steps per iteration. It’s fairly common for a model run to have a few “divergent transitions,” which Stan’s developers seem to think is a strong indicator of model failure1I’ve rarely actually seen anything particularly odd about the locations of the divergences and inferences I care about seem unaffected. I’m seeing fewer of these and a larger percentage of model runs with no divergences at all, which indicates the geometry in the unconstrained space may be more favorable.
Here’s the Stan source:
// calzetti attenuation
// precomputed emission lines
functions {
vector calzetti_mod(vector lambda, real tauv, real delta) {
int nl = rows(lambda);
real lt;
vector[nl] fk;
for (i in 1:nl) {
lt = 5500./lambda[i];
fk[i] = -0.10177 + 0.549882*lt + 1.393039*pow(lt, 2) - 1.098615*pow(lt, 3)
+0.260618*pow(lt, 4);
fk[i] *= pow(lt, delta);
}
return exp(-tauv * fk);
}
}
data {
int<lower=1> nt; //number of stellar ages
int<lower=1> nz; //number of metallicity bins
int<lower=1> nl; //number of data points
int<lower=1> n_em; //number of emission lines
vector[nl] lambda;
vector[nl] gflux;
vector[nl] g_std;
real norm_g;
vector[nt*nz] norm_st;
real norm_em;
matrix[nl, nt*nz] sp_st; //the stellar library
vector[nt*nz] dT; // width of age bins
matrix[nl, n_em] sp_em; //emission line profiles
}
parameters {
real a;
simplex[nt*nz] b_st_s;
vector<lower=0>[n_em] b_em;
real<lower=0> tauv;
real delta;
}
model {
b_em ~ normal(0, 100.);
a ~ normal(1, 10.);
tauv ~ normal(0, 1.);
delta ~ normal(0., 0.1);
gflux ~ normal(a * (sp_st*b_st_s) .* calzetti_mod(lambda, tauv, delta)
+ sp_em*b_em, g_std);
}
// put in for posterior predictive checking and log_lik
generated quantities {
vector[nt*nz] b_st;
vector[nl] gflux_rep;
vector[nl] mu_st;
vector[nl] mu_g;
vector[nl] log_lik;
real ll;
b_st = a * b_st_s;
mu_st = (sp_st*b_st) .* calzetti_mod(lambda, tauv, delta);
mu_g = mu_st + sp_em*b_em;
for (i in 1:nl) {
gflux_rep[i] = norm_g*normal_rng(mu_g[i] , g_std[i]);
log_lik[i] = normal_lpdf(gflux[i] | mu_g[i], g_std[i]);
mu_g[i] = norm_g * mu_g[i];
}
ll = sum(log_lik);
}
The functions block at the top of the code defines the modified Calzetti attenuation relation that I’ve been discussing in the last several posts. This adds a single parameter delta to the model that acts as a sort of slope difference from the standard curve. As I explained in the last couple posts I give it a tighter prior in the model block than seems physically justified.
There are two sets of parameters for the stellar contributions declared in lines 36-37 of the parameters block. Besides the simplex declaration for the individual SSP contributions there is an overall multiplicative scale parameter a. The way I (re)scale the data, which I’ll get to momentarily, this should be approximately unit valued. This is expressed in the prior in line 44 of the model block. Even though negative values of a would be unphysical I don’t explicitly constrain it since the data should guarantee that almost all posterior probability mass is on the positive side of the real line.
The current version of the code doesn’t have an explicit prior for the simplex valued SSP model contributions which means they have an implicit prior of a maximally dispersed Dirichlet distribution. This isn’t necessarily what I would choose based on domain knowledge and I plan to investigate further, but as I discussed in that post I linked it’s really hard to influence the modeled star formation history much through the choice of prior.
In the MILES SSP models one solar mass is distributed over a given IMF and then allowed to evolve according to one of a choice of stellar isochrones. According to the MILES website the flux units of the model spectra have the peculiar scaling
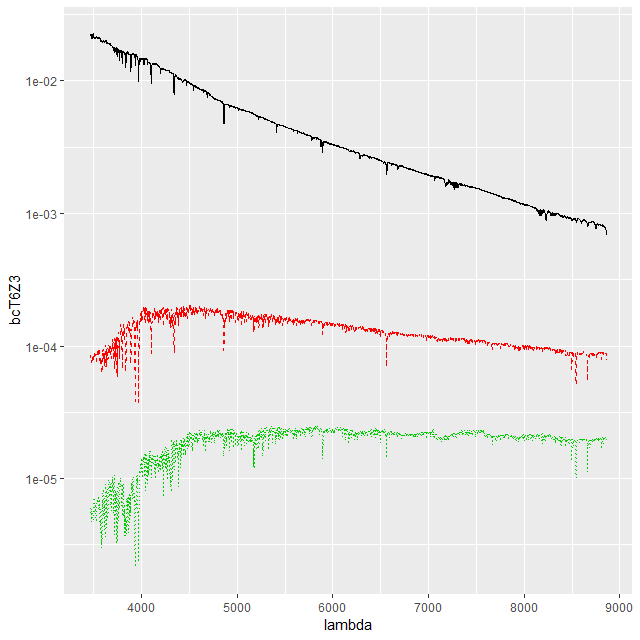
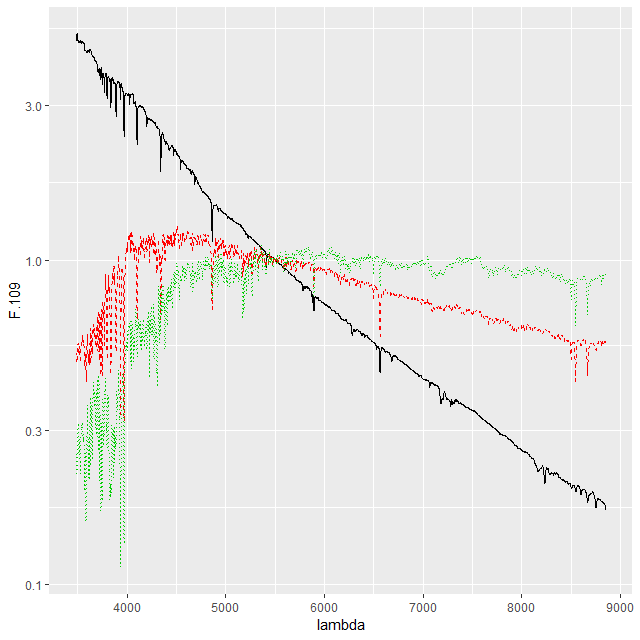
This convention, which is the same as and dates back to at least BC03, is convenient for stellar mass computations since the model coefficient values are proportional to the number of initially solar mass units of each SSP. Calculating quantities like total stellar masses or star formation rates is then a relatively trivial operation. Forward modeling (evolutionary synthesis) is also convenient since there’s a straightforward relationship between star formation histories and predictions for spectra. It may be less convenient for spectrum fitting however, especially using MCMC based methods. The plot below shows a small subset of the SSP library that I’m currently using. Not too surprisingly there’s a multiple order of magnitude range of absolute flux levels with the main source of variation being age. What might be less evident in this plot is that in the units SDSS uses coefficient values might be in the 10’s or hundreds of thousands, with multiple order of magnitude variations among SSP contributors. A simple rescaling of the library spectra to make at least some of the coefficients more nearly unit scaled will address the first problem, but won’t affect the multiple order of magnitude variations among coefficients.
Small sample of EMILES SSP model spectra in original flux units:
T (black): age 1 Myr from 2016 update of BC03 models
M (red) 1 Gyr
B (green) 10 Gyr
One alternative that’s close to standard statistical practice is to rescale the individual inputs to have approximately the same scale and central value. A popular choice for SED fitting is to normalize to 1 at some fiducial wavelength, often (for UV-optical-NIR data) around V. For my latest model runs I tried renormalizing each SSP spectrum to have a mean value of 1 in a ±150Å window around 5500Å, which happens to be relatively lacking in strong absorption lines at all ages and metallicities.
Same spectra normized to 1 in neighborhood of 5500 Å
This normalization makes the SSP coefficients estimates of light fractions at V, which is intuitively appealing since we are after all fitting light. The effect on sampler performance is hard to predict, but as I said at the top of the post a combination of light weighted fitting with the stellar contribution vector declared as a simplex seems to have favorable performance both in terms of execution time and convergence diagnostics. That’s based on a very small set of model runs and no rigorous performance comparisons at all2among other issues I’ve run versions of these models on at least 4 separate PCs with different generations of Intel processors and both Windows and Linux OSs. This alone produces factor of 2 or more variations in execution time..
For a quick visual comparison here are coefficient values for a single model run on a spectrum from somewhere in the disk of the spiral galaxy that’s been the subject of the last few posts. These are “interval” plots of the marginal posterior distributions of the SSP model contributions, arranged by metallicity bin (of which there are 4) from lowest to highest and within each bin by age from lowest to highest. The left hand strip of plots are the actual coefficient values representing light fractions at V, while the right hand strip are values proportional to the mass contributions. The latter is what gets transformed into star formation histories and other related quantities. The largest fraction of the light is coming from the youngest populations, which is not untypical for a star forming region. Most of the mass is in older populations, which again is typical.
Another thing that’s very typical is that contributions come from all age and metallicity bins, with similar but not quite identical age trends within each metallicity bin. I find it a real stretch to believe this tells us anything about the real chemical evolution distribution trend with lookback time, but how to interpret this still needs investigation.
Light (L) and mass (R) weighted marginal distributions of coefficient values for a single model run on a disk galaxy spectrum
Here’s an SDSS finder chart image of one of the two grand design spirals that found its way into my “transitional” galaxy sample:
Central galaxy: Mangaid 1-382712 (plateifu 9491-6101), aka CGCG 088-005
and here’s a zoomed in thumbnail with IFU footprint:
plateifu 9491-6101 IFU footprint
This galaxy is in a compact group and slightly tidally distorted by interaction with its neighbors, but is otherwise a fairly normal star forming system. I picked it because I had a recent set of model runs and because it binned to a manageable but not too small number of spectra (112). The fits to the data in the first set of model runs were good and the (likely) AGN doesn’t have broad lines. Here are a few selected results from the set of model runs using the modified Calzetti attenuation relation on the same binned spectra. First, using a tight prior on the slope parameter δ had the desired effect of returning the prior for δ when τ was near zero, while the marginal posterior for τ was essentially unchanged:
Estimated optical depth for modified Calzetti attenuation vs. unmodified. MaNGA plateifu 9491-6101
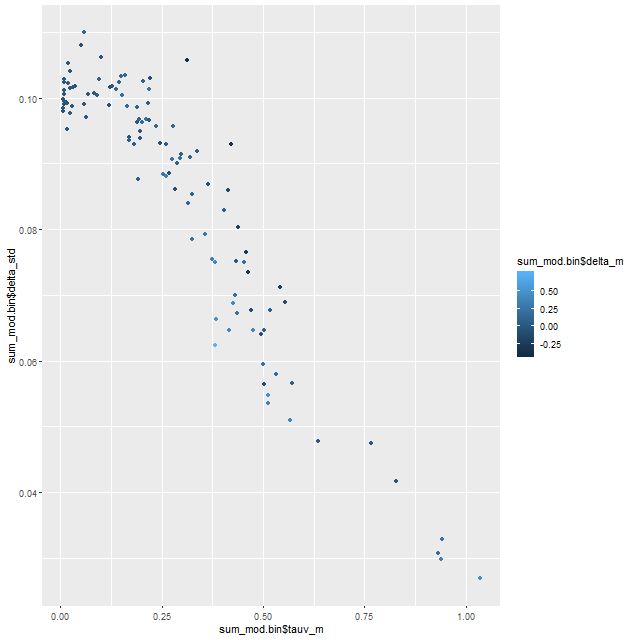
At larger optical depths the data do constrain both the shape of the attenuation curve and optical depth. At low optical depth the posterior uncertainty in δ is about the same as the prior, while it decreases more or less monotonically for higher values of τ. A range of (posterior mean) values of δ from slightly shallower than a Calzetti relation to somewhat steeper. The general trend is toward a steeper relation with lower optical depth in the dustier regions (per the models) of the galaxy.
Posterior marginal standard deviation of parameter δ vs. posterior mean optical depth. MaNGA plateifu 9491-6101
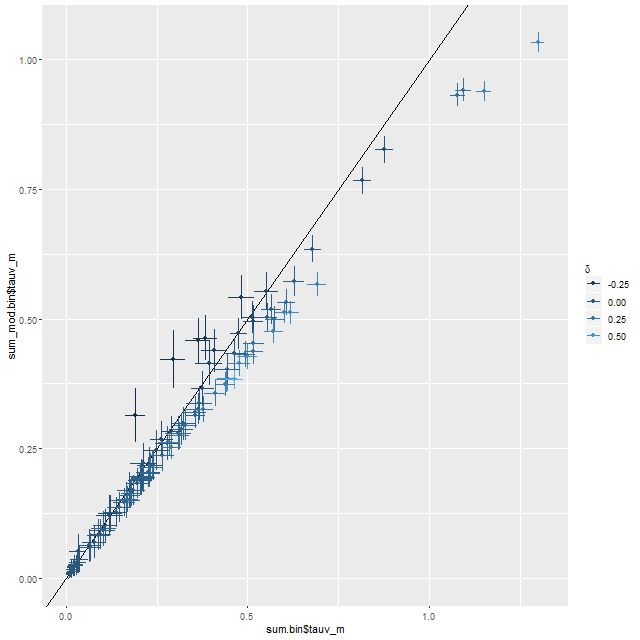
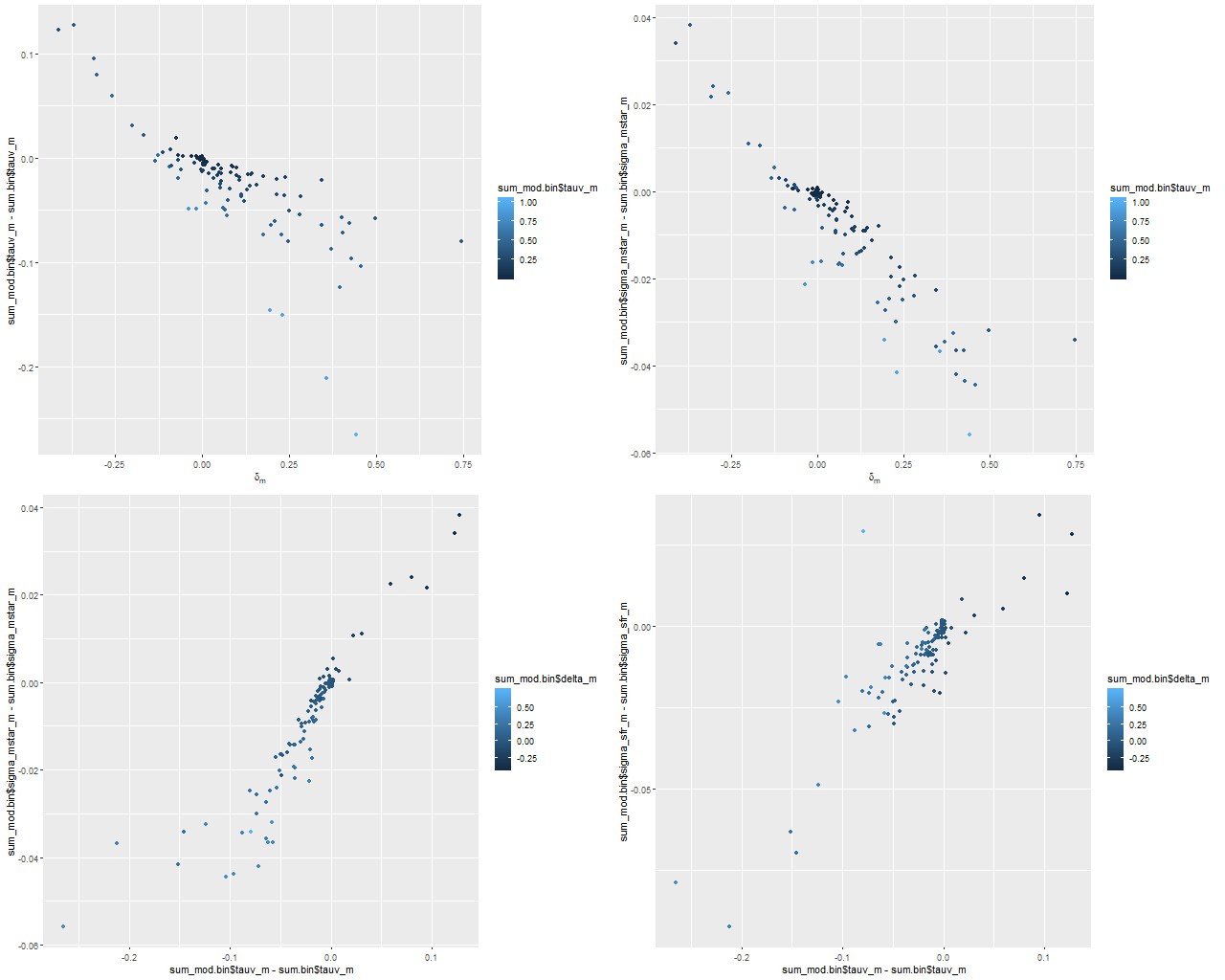
There’s an interesting pattern of correlations1astronmers like to call these “degeneracies,” and it’s fairly well known that they exist among attenuation, stellar age, stellar mass, and other properties here, some of which are summarized in the sequence of plots below. The main result is that a steeper (shallower) attenuation curve requires a smaller (larger) optical depth to create a fixed amount of reddening, so there’s a negative correlation between the slope parameter δ and the change in optical depth between the modified and unmodified curves. A lower optical depth means that a smaller amount of unattenuated light, and therefore lower stellar mass, is needed to produce a given observed flux. so there’s a negative correlation between the slope parameter and stellar mass density or a positive correlation between optical depth and stellar mass. The star formation rate density is correlated in the same sense but slightly weaker. In this data set both changed by less than about ± 0.05 dex.
(TL) change in optical depth (modified – unmodified calzetti) vs. slope parameter δ (TR) change in stellar mass density vs. δ (BL) change in stellar mass density vs. change in optical depth (BR) change in SFR density vs change in optical depth Note: all quantities are marginal posterior mean estimagtes.
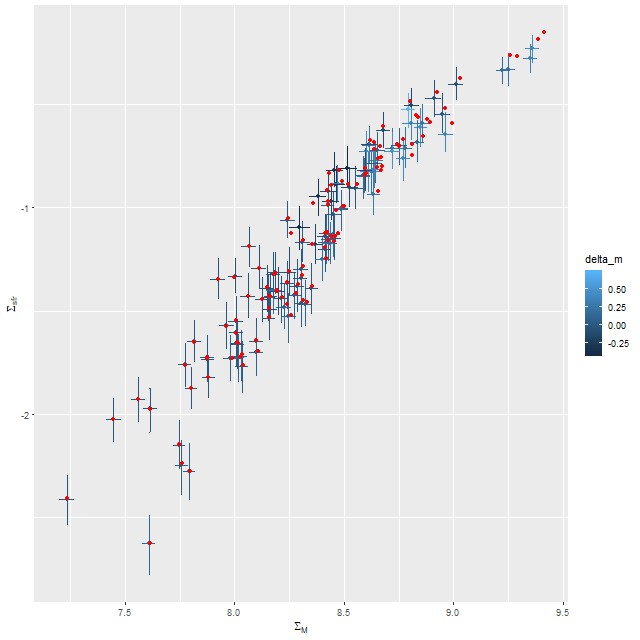
Here are a few relationships that I’ve shown previously. First between stellar mass and star formation rate density. The points with error bars (which are 95% marginal credible limits) are from the modified Calzetti run, while the red points are from the original. Regions with small stellar mass density and low star formation rate have small attenuation as well in this system, so the estimates hardly differ at all. Only at the high end are differences about as large as the nominal uncertainties.
SFR density vs. stellar mass density. Red points are point estimates for unmodified Calzetti attenuation. MaNGA plateifu 9491-6101
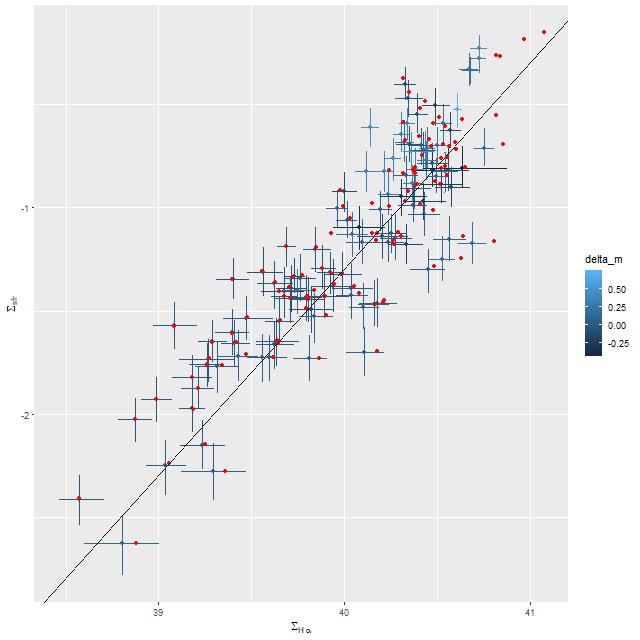
Finally, here is the relation between Hα luminosity density and star formation rate with the former corrected for attenuation using the Balmer decrement. The straight line is, once again, the calibration of Moustakas et al. Allowing the shape of the attenuation curve to vary has a larger effect on the luminosity correction than it does on the SFR estimates, but both sets of estimates straddle the line with roughly equal scatter.
SFR density vs. Hα luminosity density. Red points are point estimates for unmodified Calzetti attenuation.
MaNGA plateifu 9491-6101
To conclude for now, adding the more flexible attenuation prescription proposed by Salim et al. has some quantitative effects on model posteriors, but so far at least qualitative inferences aren’t significantly affected. I haven’t yet looked in detail at star formation histories or at effects on metallicity or metallicity evolution. I’ve been skeptical that SFH modeling constrains stellar metallicity or (especially) metallicity evolution well, but perhaps it’s time to take another look.
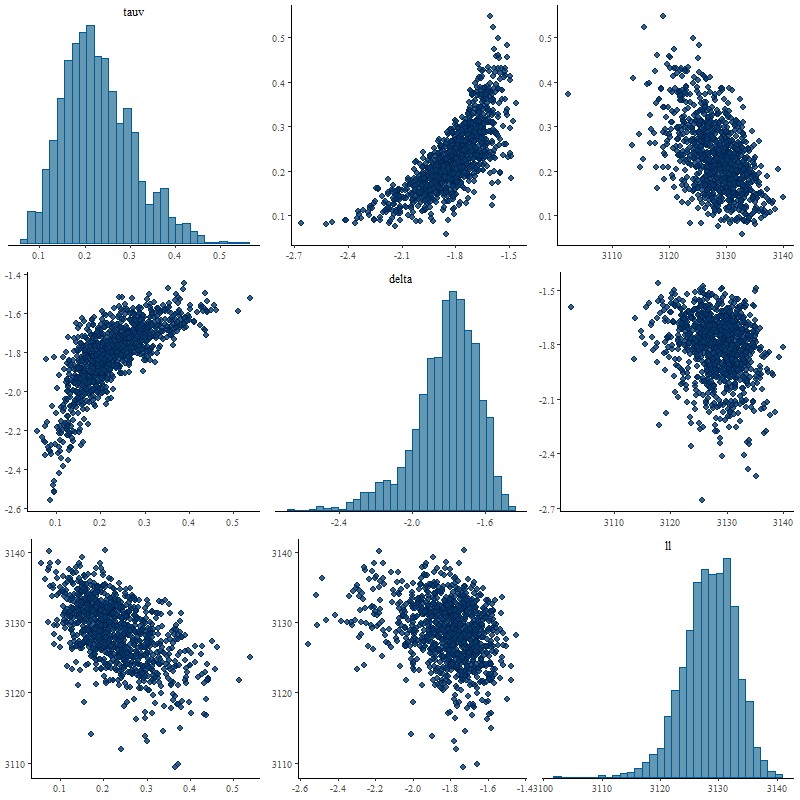
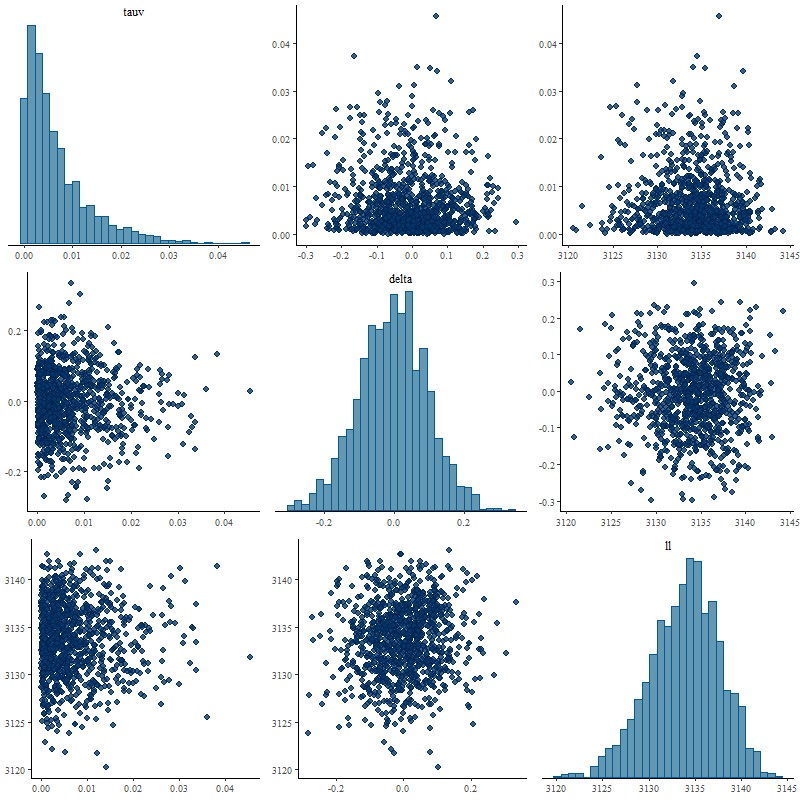
Here’s a problem that isn’t a huge surprise but that I hadn’t quite anticipated. I initially chose, without a lot of thought, a prior \(\delta \sim \mathcal{N}(0, 0.5)\) for the slope parameter delta in the modified Calzetti relation from the last post. This seemed reasonable given Salim et al.’s result showing that most galaxies have slopes \(-0.1 \lesssim \delta \lesssim +1\) (my wavelength parameterization reverses the sign of \(\delta\) ). At the end of the last post I made the obvious comment that if the modeled optical depth is near 0 the data can’t constrain the shape of the attenuation curve and in that case the best that can be hoped for is the model to return the prior for delta. Unfortunately the actual model behavior was more complicated than that for a spectrum that had a posterior mean tauv near 0:
Pairs plot of parameters tauv and delta, plus summed log likelihood with “loose” prior on delta.
Although there weren’t any indications of convergence issues in this run experts in the Stan community often warn that “banana” shaped posteriors like the joint distribution of tauv and delta above are difficult for the HMC algorithm in Stan to explore. I also suspect the distribution is multi-modal and at least one mode was missed, since the fit to the flux data as indicated by the summed log-likelihood is slightly worse than the unmodified Calzetti model.
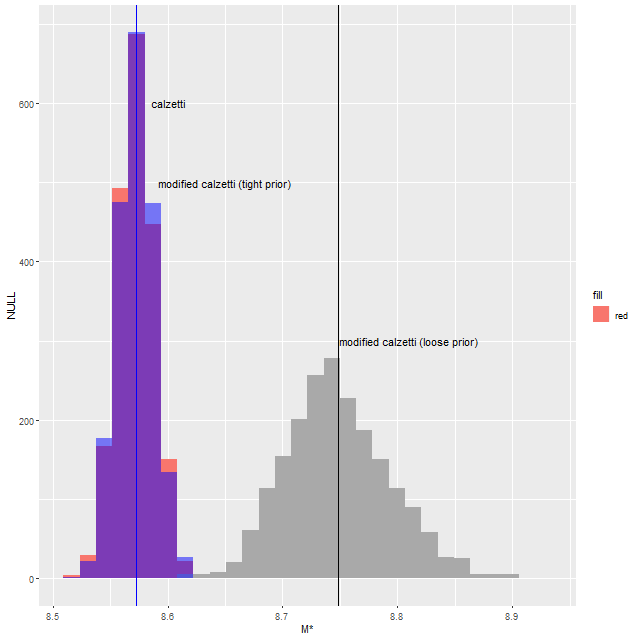
A value of \(\delta\) this small actually reverses the slope of the attenuation curve, making it larger in the red than in the blue. It also resulted in a stellar mass estimate about 0.17 dex larger than the original model, which is well outside the statistical uncertainty:
Stellar mass estimates for loose and tight priors on delta + unmodified Calzetti attenuation curve
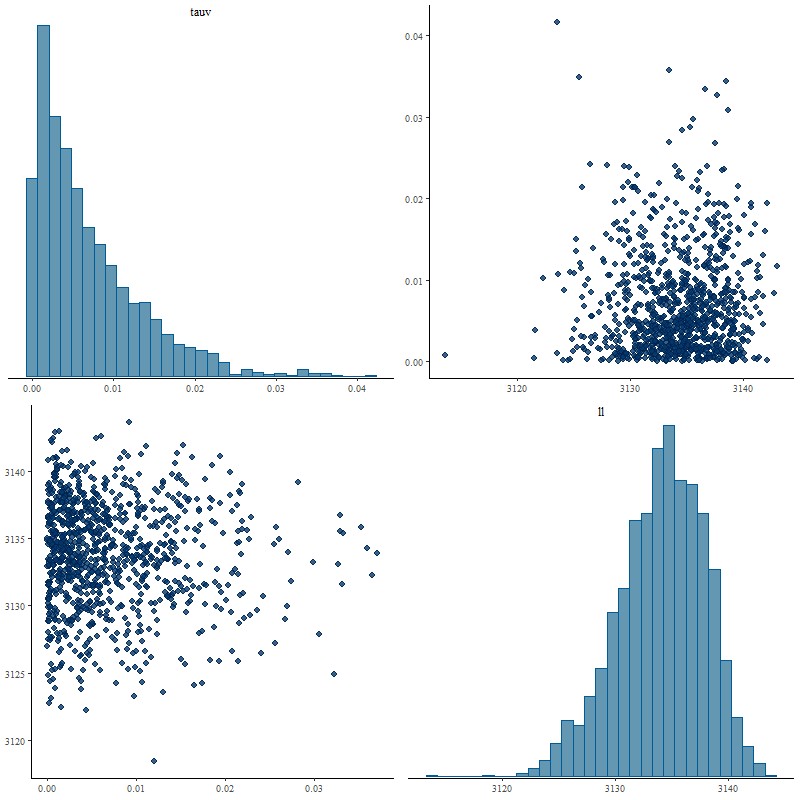
I next tried a tighter prior on delta of 0.1 for the scale parameter, with the following result:
Pairs plot of parameters tauv and delta, plus summed log likelihood with “tight” prior on delta.
Now this is what I hoped to see. The marginal posterior of delta almost exactly returns its prior, properly reflecting the inability of the data to say anything about it. The posterior of tauv looks almost identical to the original model with a very slightly longer tail:
Pairs plot of parameters tauv and summed log likelihood, unmodified Calzetti attenuation curve
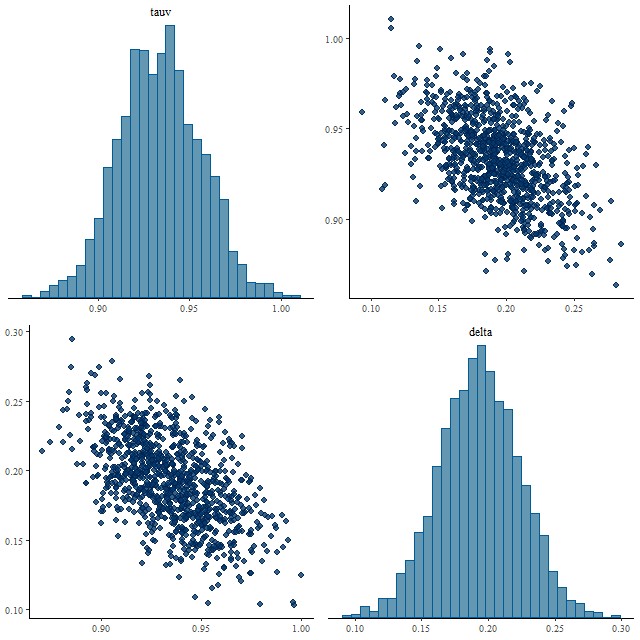
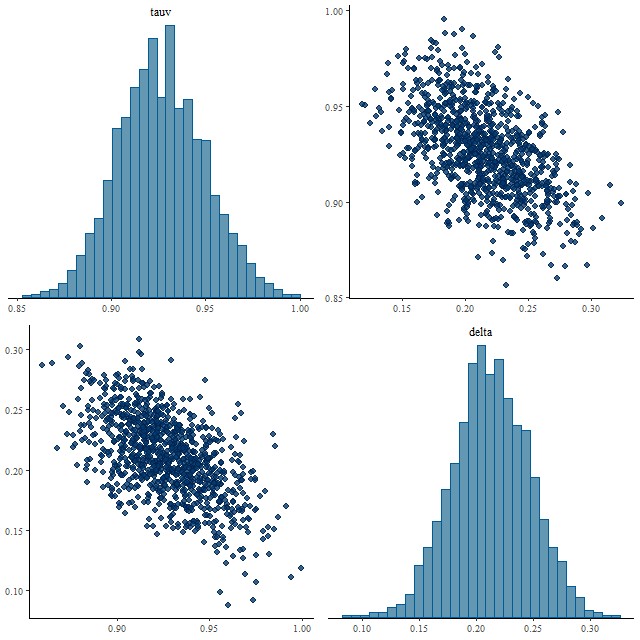
So this solves one problem but now I must worry that the prior is too tight in general since Salim’s results predict a considerably larger spread of slopes. As a first tentative test I ran another spectrum from the same spiral galaxy (this is mangaid 1-382712) that had moderately large attenuation in the original model (1.08 ± 0.04) with both “tight” and “loose” priors on delta with the following results:
Joint posterior of parameters tau and delta with “tight” priorJoint posterior of parameters tau and delta with “loose” prior
The distributions of tauv look nearly the same, while delta shrinks very slightly towards 0 with a tight prior, but with almost the same variance. Some shrinkage towards Calzetti’s original curve might be OK. Anyway, on to a larger sample.
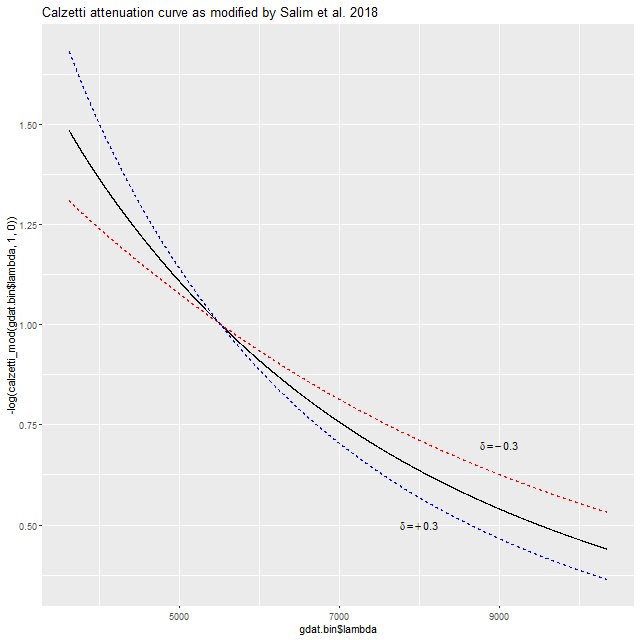
I finally got around to reading a paper by Salim, Boquien, and Lee (2018), who proposed a simple modification to Calzetti‘s well known starburst attenuation relation that they claim accounts for most of the diversity of curves in both star forming and quiescent galaxies. For my purposes their equation 3, which summarizes the relation, can be simplified in two ways. First, for mostly historical reasons optical astronomers typically quantify the effect of dust with a color excess, usually E(B-V). If the absolute attenuation is needed, which is certainly the case in SFH modeling, the ratio of absolute to “selective” attenuation, usually written as \(\mathrm{R_V = A_V/E(B-V)}\) is needed. Parameterizing attenuation by color excess adds an unnecessary complication for my purposes. Salim et al. use a family of curves that differ only in a “slope” parameter \(\delta\) in their notation. Changing \(\delta\) changes \(\mathrm{R_V}\) according to their equation 4. But I have always parametrized dust attenuation by optical depth at V, \(\tau_V\) so that the relation between intrinsic and observed flux is
Note that parameterizing by optical depth rather than total attenuation \(\mathrm{A_V}\) is just a matter of taste since they only differ by a factor 1.08. The wavelength dependent part of the relationship is the same.
The second simplification results from the fact that the UV or 2175Å “bump” in the attenuation curve will never be redshifted into the spectral range of MaNGA data and in any case the subset of the EMILES library I currently use doesn’t extend that far into the UV. That removes the bump amplitude parameter and the second term in Salim et al.’s equation 3, reducing it to the form
The published expression for \(k(\lambda)\) in Calzetti et al. (2000) is given in two segments with a small discontinuity due to rounding at the transition wavelength of 6300Å. This produces a small unphysical discontinuity when applied to spectra, so I just made a polynomial fit to the Calzetti curve over a longer wavelength range than gets used for modeling MaNGA or SDSS data. Also, I make the wavelength parameter \(y = 5500/\lambda\) instead of using the wavelength in microns as in Calzetti. With these adjustments Calzetti’s relation is, to more digits than necessary:
Note that δ has the opposite sign as in Salim et al. Here is what the curve looks like over the observer frame wavelength range of MaNGA. A positive value of δ produces a steeper attenuation curve than Calzetti’s, while a negative value is shallower (grayer in common astronomers’ jargon). Salim et al. found typical values to range between about -0.1 and +1.
Calzetti attenuation relation with modification proposed by Salim, Boquien, and Lee (2018). Dashed lines show shift in curve for their parameter δ = ± 0.3.
For a first pass attempt at modeling some real data I chose a spectrum from near the northern nucleus of Mrk 848 but outside the region of the highest velocity outflows. This spectrum had large optical depth \(\tau_V \approx 1.52\) and the unusual nature of the galaxy gave reason to think its extinction curve might differ significantly from Calzetti’s.
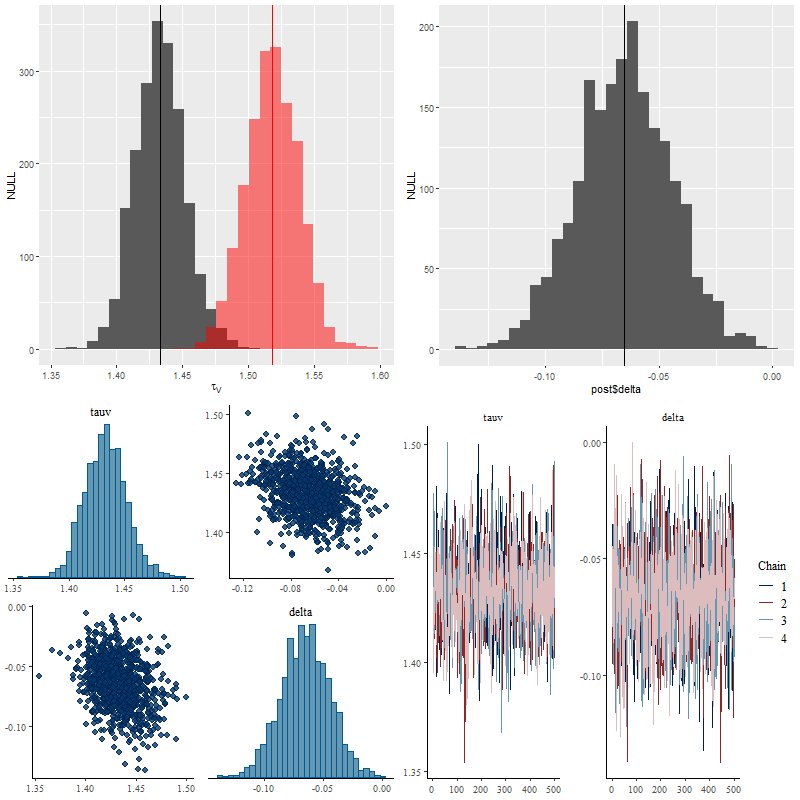
Encouragingly, the Stan model converged without difficulty and with an acceptable run time. Below are some posterior plots of the two attenuation parameters and a comparison to the optical depth parameter in the unmodified Calzetti dust model. I used a fairly informative prior of Normal(0, 0.5) for the parameter delta. The data actually constrain the value of delta, since its posterior marginal density is centered around -0.06 with a standard deviation of just 0.02. In the pairs plot below we can see there’s some correlation between the posteriors of tauv and delta, but not so much as to be concerning (yet).
(TL) marginal posteriors of optical depth parameter for Calzetti (red) and modified (dark gray) relation.
(TR) parameter δ in modified Calzetti relation
(BL) pairs plot of `tauv` and `delta`
(BR) trace plots of `tauv` and `delta`
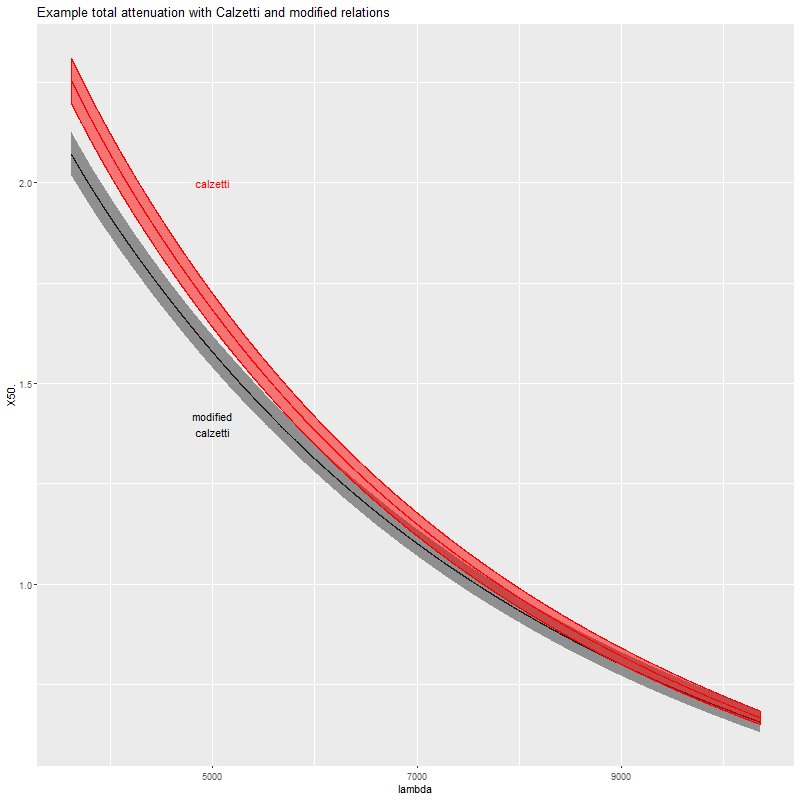
Overall the modified Calzetti model favors a slightly grayer attenuation curve with lower absolute attenuation:
Total attenuation for original and modified Calzetti relations. Spectrum was randomly selected near the northern nucleus or Mrk 848.
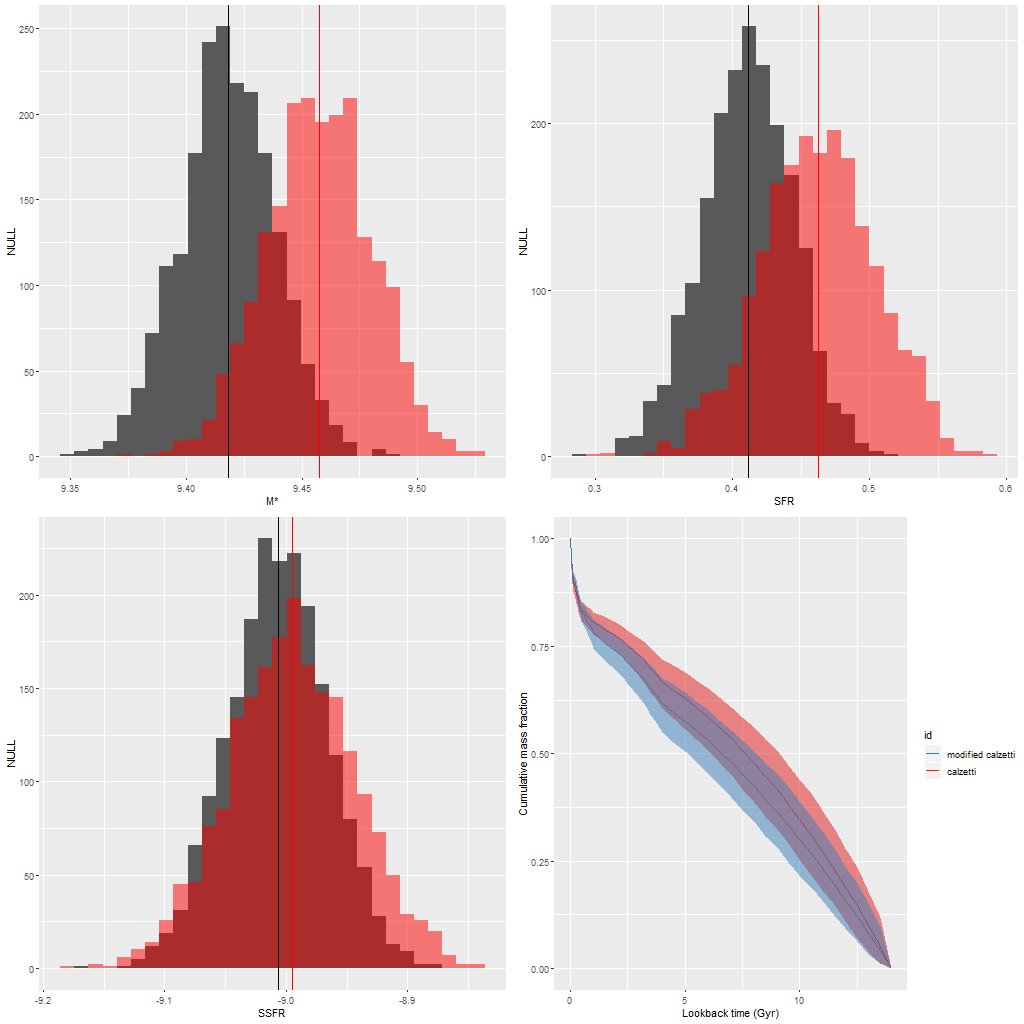
Here’s a quick look at the effect of the model modification on some key quantities. In the plot below the red symbols are for the unmodified Calzetti attenuation model, and gray or blue the modified one. These show histograms of the marginal posterior density of total stellar mass, 100Myr averaged star formation rate, and specific star formation rate. Because the modified model has lower total attenuation it needs fewer stars, so the lower stellar mass (by ≈ 0.05 dex) is a fairly predictable consequence. The star formation rate is also lower by a similar amount, making the estimates of specific star formation rate nearly identical.
The lower right pane compares model mass growth histories. I don’t have any immediate intuition about how the difference in attenuation models affects the SFH models, but notice that both show recent acceleration in star formation, which was a main theme of my Markarian 848 posts.
Stellar mass, SFR,, SSFR, and mass growth histories for original and modified Calzetti attenuation relation.
So, this first run looks ok. Of course the problem with real data is there’s no way to tell if a model modification actually brings it closer to reality — in this case it did improve the fit to the data a little bit (by about 0.2% in log likelihood) but some improvement is expected just from adding a parameter.
My concern right now is that if the dust attenuation is near 0 the data can’t constrain the value of δ. The best that can happen in this situation is for the model to return the prior. Preliminary investigation of a low attenuation spectrum (per the original model) suggests that in fact a tighter prior on delta is needed than what I originally chose.
One more post making use of the measurement error model introduced last time and then I think I move on. I estimate the dust attenuation of the starlight in my SFH models using a Calzetti attenuation relation parametrized by the optical depth at V (τV). If good estimates of Hα and Hβ emission line fluxes are obtained we can also make optical depth estimates of emission line regions. Just to quickly review the math we have:
\(A_\lambda = \mathrm{e}^{-\tau_V k(\lambda)}\)
where \(k(\lambda)\) is the attenuation curve normalized to 1 at V (5500Å) and \(A_\lambda\) is the fractional flux attenuation at wavelength λ. Assuming an intrinsic Balmer decrement of 2.86, which is more or less the canonical value for H II regions, the estimated optical depth at V from the observed fluxes is:
The SFH models return samples from the posteriors of the emission lines, from which are calculated sample values of \(\tau_V^{bd}\).
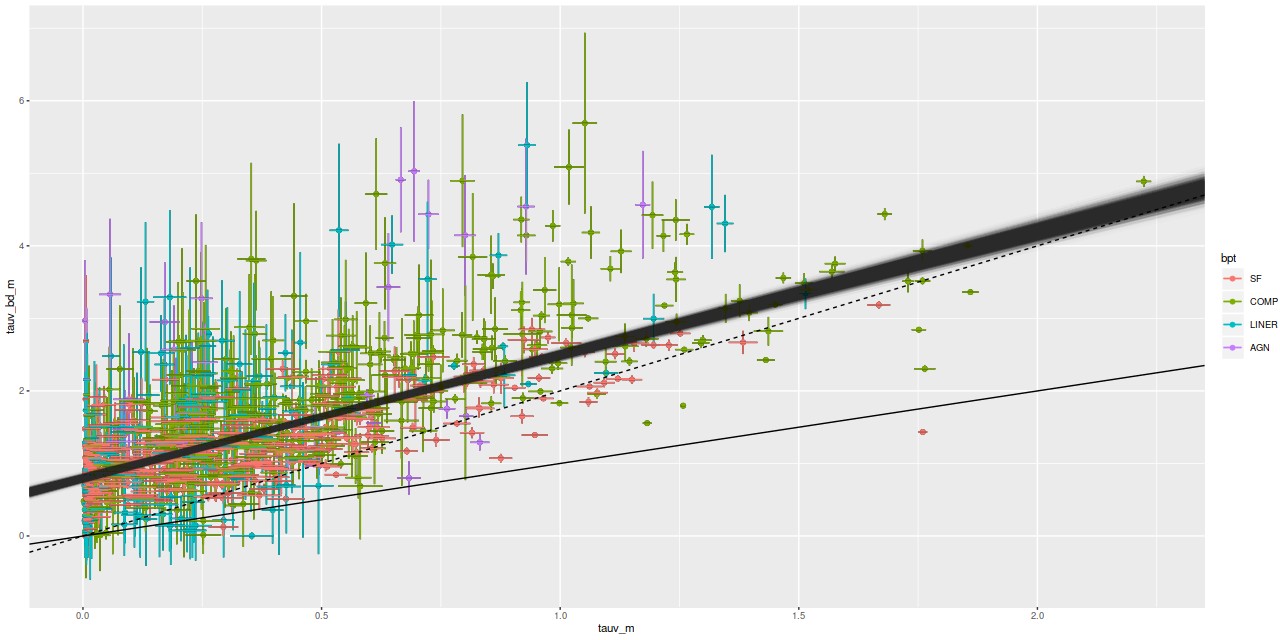
Here is a plot of the estimated attenuation from the Balmer decrement vs. the SFH model estimates for all spectra from the 28 galaxy sample in the last two posts that have BPT classifications other than no or weak emission. Error bars are ±1 standard deviation.
τVbd vs. τVstellar for 962 binned spectra in 28 MaNGA galaxies. Cloud of lines is from fit described in text. Solid and dashed lines are 1:1 and 2:1 relations.
It’s well known that attenuation in emission line regions is larger than that of the surrounding starlight, with a typical reddening ratio of ∼2 (among many references see the review by Calzetti (2001) and Charlot and Fall (2000)). One thing that’s clear in this plot that I haven’t seen explicitly mentioned in the literature is that even in the limit of no attenuation of starlight there typically is some in the emission lines. I ran the regression with measurement error model on this data set, and got the estimated relationship \(\tau_V^{bd} = 0.8 (\pm 0.05) + 1.7 ( \pm 0.09) \tau_V^{stellar}\) with a rather large estimated scatter of ≈ 0.45. So the slope is a little shallower than what’s typically assumed. The non-zero intercept seems to be a robust result, although it’s possible the models are systematically underestimating Hβ emission. I have no other reason to suspect that, though.
The large scatter shouldn’t be too much of a surprise. The shape of the attenuation curve is known to vary between and even within galaxies. Adopting a single canonical value for the Balmer decrement may be an oversimplification too, especially for regions ionized by mechanisms other than hot young stars. My models may be overdue for a more flexible prescription for attenuation.
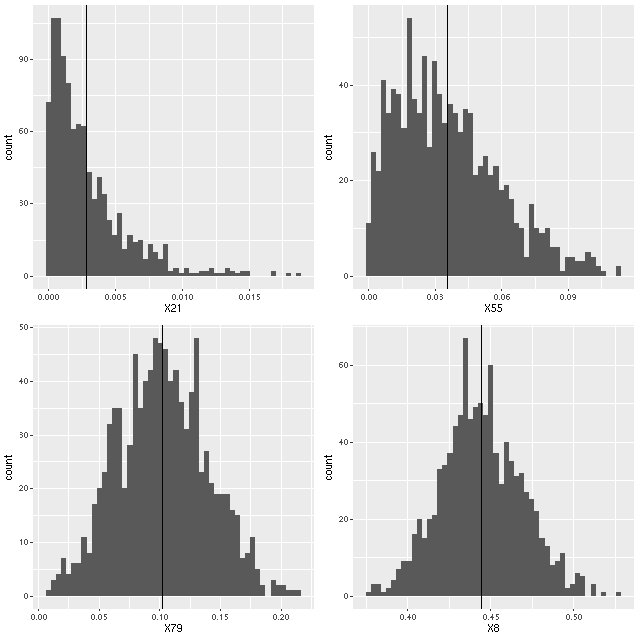
The statistical assumptions of the measurement error model are a little suspect in this data set as well. The attenuation parameter tauv is constrained to be positive in the models. When it wants to be near 0 the samples from the posterior will pile up near 0 with a tail of larger values, looking more like draws from an exponential or gamma distribution than a gaussian. Here is an example from one galaxy in the sample that happens to have a wide range of mean attenuation estimates:
Histograms of samples from the marginal posterior distributions of the parameter tauv for 4 spectra from plateifu 8080-3702.
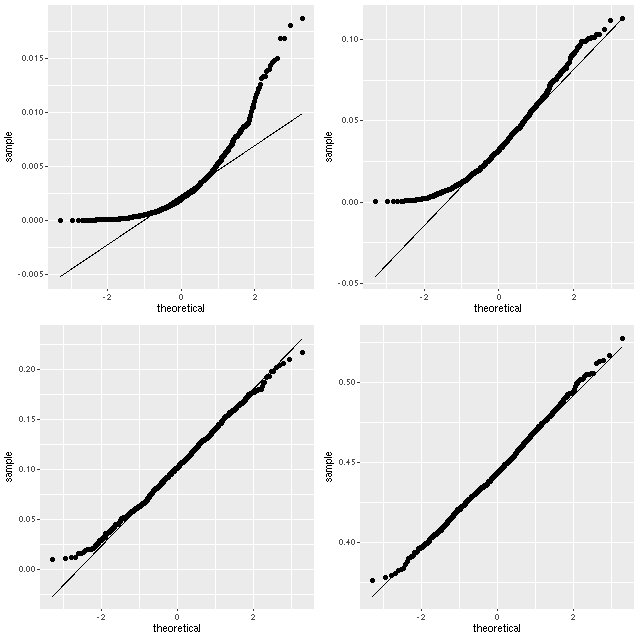
I like theoretical quantile-quantile plots better than histograms for this type of visualization:
Normal quantile-quantile plots of samples from the marginal posterior distributions of the parameter tauv for 4 spectra from plateifu 8080-3702.
I haven’t looked at the distributions of emission line ratios in much detail. They might behave strangely in some cases too. But regardless of the validity of the statistical model applied to this data set it’s apparent that there is a fairly strong correlation, which is encouraging.
Here’s a pretty common situation with astronomical data: two or more quantities are measured with nominally known uncertainties that in general will differ between observations. We’d like to explore the relationship among them, if any. After graphing the data and establishing that there is a relationship a first cut quantitative analysis would usually be a linear regression model fit to the data. But the ordinary least squares fit is biased and might be severely misleading if the measurement errors are large enough. I’m going to present a simple measurement error model formulation that’s amenable to Bayesian analysis and that I’ve implemented in Stan. This model is not my invention by the way — in the astronomical literature it dates at least to Kelly (2007), who also explored a number of generalizations. I’m only going to discuss the simplest case of a single predictor or covariate, and I’m also going to assume all conditional distributions are gaussian.
The basic idea of the model is that the real, unknown quantities (statisticians call these latent variables, and so will I) are related through a linear regression. The conditional distribution of the latent dependent variable is
where \(\sigma_{x, i}, \sigma_{y, i}\) are the known standard deviations. The full joint distribution is completed by specifying priors for the parameters \(\beta_0, \beta_1, \sigma\). This model is very easy to implement in the Stan language and the complete code is listed below. I’ve also uploaded the code, a script to reproduce the simulated data example discussed below, and the SFR-stellar mass data from the last page in a dropbox folder.
Most of this code should be self explanatory, but there are a few things to note. In the transformed data section I standardize both variables, that is I subtract the means and divide by the standard deviations. The individual observation standard deviations are also scaled. The transformed parameters block is strictly optional in this model. All it does is spell out the linear part of the linear regression model.
In the model block I give a very vague prior for the latent x variables. This has almost no effect on the model output since the posterior distributions of the latent values are strongly constrained by the observed data. The parameters of the regression model are given less vague priors. Since we standardized the data we know beta0 should be centered near 0 and beta1 near 1 and all three should be approximately unit scaled. The rest of the model block just encodes the conditional distributions I wrote out above.
Finally the generated quantities block does two things: generate some some new simulated data values under the model using the sampled parameters, and rescale the parameter values to the original data scale. The first task enables what’s called “posterior predictive checking.” Informally the idea is that if the model is successful simulated data generated under it should look like the data that was input.
It’s always a good idea to try out a model with some simulated data that conforms to it, so here’s a script to generate some data, then print and graph some basic results. This is also in the dropbox folder.
Inference for Stan model: ls_me.
4 chains, each with iter=2000; warmup=1000; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=4000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
b0 9.995 0.001 0.042 9.912 9.966 9.994 10.023 10.078 5041 0.999
b1 1.993 0.001 0.040 1.916 1.965 1.993 2.020 2.073 4478 1.000
sigma_unorm 0.472 0.001 0.037 0.402 0.447 0.471 0.496 0.549 2459 1.003
Samples were drawn using NUTS(diag_e) at Thu Jan 9 10:09:34 2020.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
>
and graph:
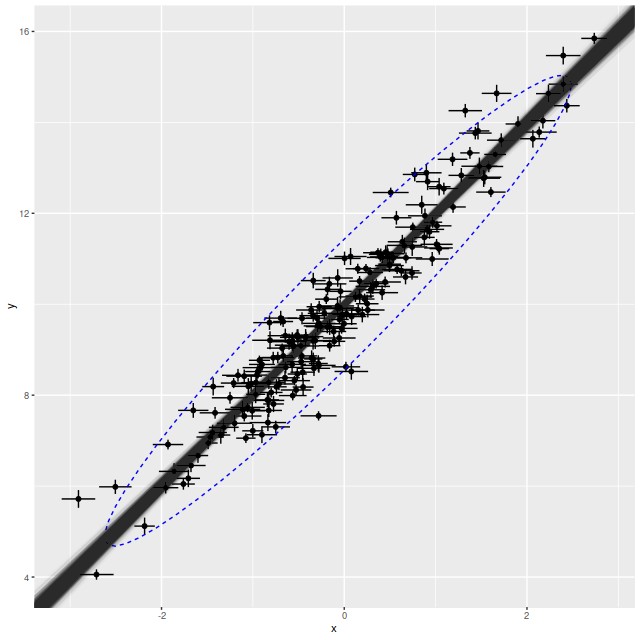
Simulated data and model fit from script in text. Ellipse is 95% confidence interval for new data generated from model.
This all looks pretty good. The true parameters are well within the 95% confidence bounds of the estimates. In the graph the simulated new data is summarized with a 95% confidence ellipse, which encloses just about 95% of the input data, so the posterior predictive check indicates a good model. Stan is quite aggressive at flagging potential convergence failures, and no warnings were generated.
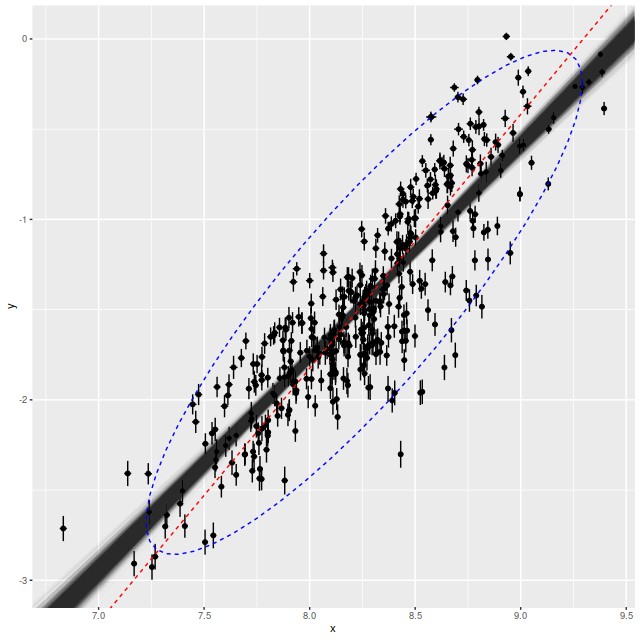
Turning to some real data I also included in the dropbox folder the star formation rate density versus stellar mass density data that I discussed in the last post. This is in something called R “dump” format, which is just an ascii file with R assignment statements for the input data. This isn’t actually a convenient form for input to rstan’s sampler or ggplot2’s plotting commands, so once loaded the data are copied into a list and a data frame. The interactive session for analyzing the data was:
Star formation rate vs. Stellar mass for star forming regions. Data from previous post.
Semi-transparent lines – model fits to the regression line as described in text.
Dashed red line – “orthogonal distance regression” fit.
Inference for Stan model: ls_me.
4 chains, each with iter=2000; warmup=1000; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=4000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
b0 -11.20 0 0.26 -11.73 -11.37 -11.19 -11.02 -10.67 7429 1
b1 1.18 0 0.03 1.12 1.16 1.18 1.20 1.24 7453 1
sigma_unorm 0.27 0 0.01 0.25 0.27 0.27 0.28 0.29 7385 1
Samples were drawn using NUTS(diag_e) at Thu Jan 9 10:49:42 2020.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
Once again the model seems to fit the data pretty well, the posterior predictive check is reasonable, and Stan didn’t complain. Astronomers are often interested in the “cosmic variance” of various quantities, that is the true amount of unaccounted for variation. If the error estimates in this data set are reasonable the cosmic variance in SFR density is estimated by the parameter σ. The mean estimate of around 0.3 dex is consistent with other estimates in the literature1see the compilation in the paper by Speagle et al. that I cited last time, for example.
I noticed in preparing the last post that several authors have used something called “orthogonal distance regression” (ODR) to estimate the star forming main sequence relationship. I don’t know much about the technique besides that it’s an errors in variables regression method. There is an R implementation in the package pracma. The red dashed line in the plot above is the estimate for this dataset. The estimated slope (1.41) is much steeper than the range of estimates from this model. On casual visual inspection though it’s not clearly worse at capturing the mean relationship.