The first iteration of Galaxy Zoo led to several collections of distinct objects, including a sample of 215 “blue early type galaxies” published in Schawinski et al. (2009)1which inexplicably and consistently says there were 204 objects while the catalog published in Vizier contains 215.I found this an interesting group of galaxies, partly because of a possible link to post-starburst (K+A) galaxies that was discussed in the original paper. The authors discuss at some length the likelihood that these are results of mergers in the cosmologically recent past, with at least one of the progenitors being gas rich. Many (at least 25% and possibly more than half) were found to be currently starforming and the rest likely to have only recently ceased forming stars as inferred from their blue colors.
The ongoing Zoogems program has 12 of Schawinski’s blue ETGs on its target list, of which 6 have been observed so far as of mid-January 2022. Somewhat surprisingly there are 24 in the final MaNGA release, over 11% of the sample!
Taking a look at the 6 with HST observations I would say none of these are typical ellipticals. Five show some degree of spiral structure although in 4 it’s embedded in a more diffuse body. One appears to me to be an S0 with both inner and outer rings — this is in agreement with the one published morphological classification I’ve found. All of the others appear more disky than ellipsoidal to me, although this is just my possibly flawed qualitative judgment. At least two are visibly disturbed. One (CGCG 315-014) is connected to a nearby galaxy with a long tidal tail as seen in the Legacy Survey thumbnail below. Markarian 888, which will be the subject of the rest of this post, has shells that extend well past the main body of the galaxy and prominent, centrally concentrated dust lanes.

So far it’s the only Zoogems blue etg target with a MaNGA observation (two others on the target list are in MaNGA but of course there’s no guarantee they will ever be observed). As is often the case the IFU could have been larger — this was observed with a 37 fiber bundle giving 111 dithered spectra in the RSS file.

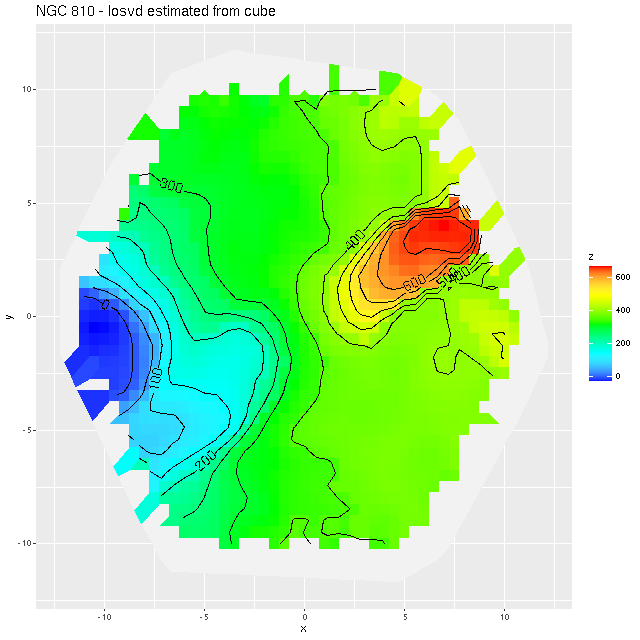
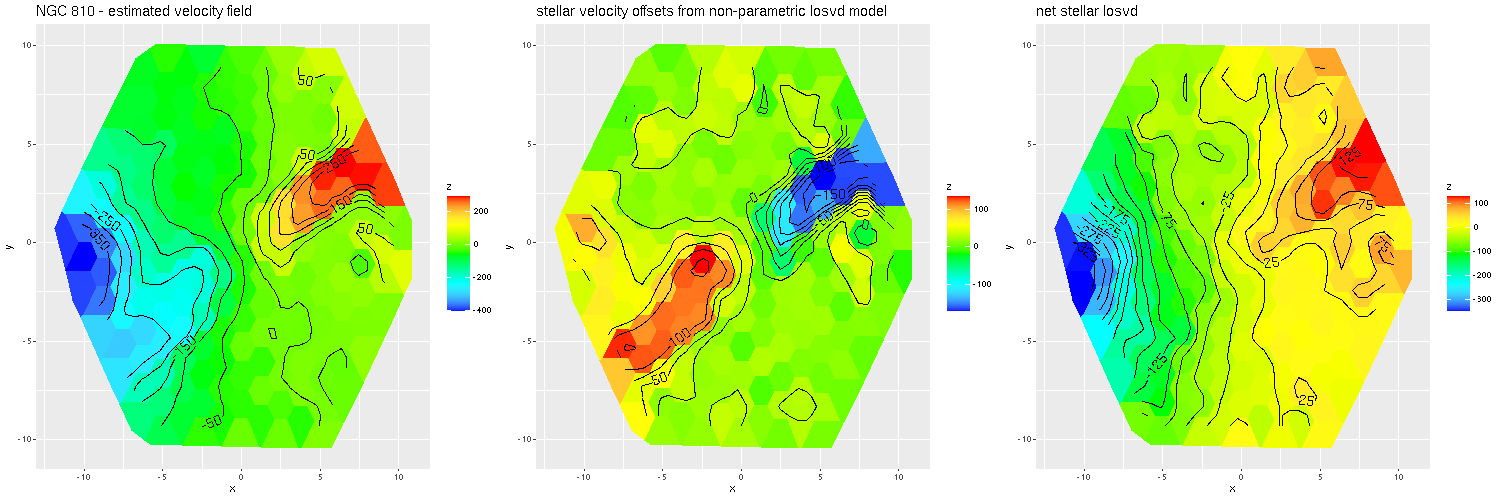
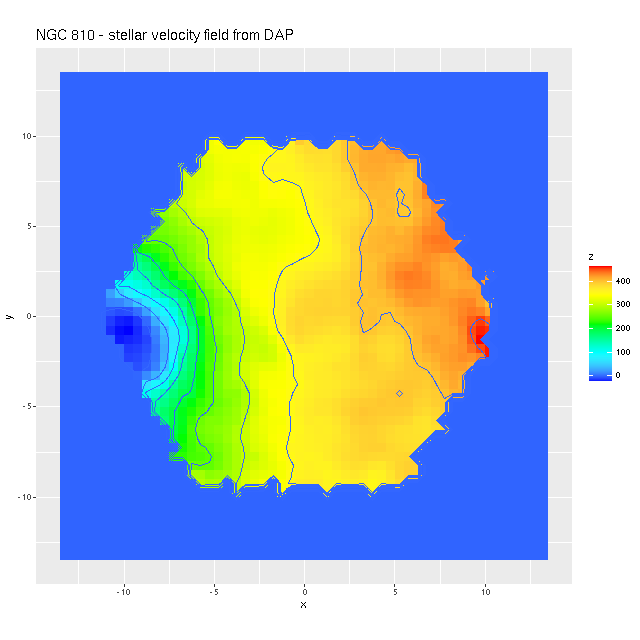
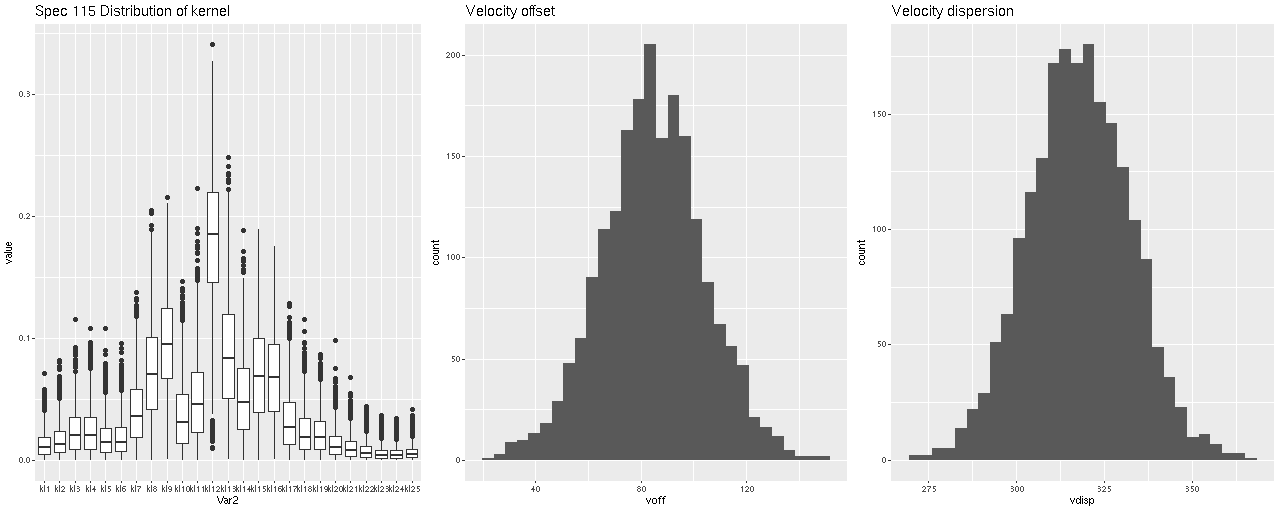
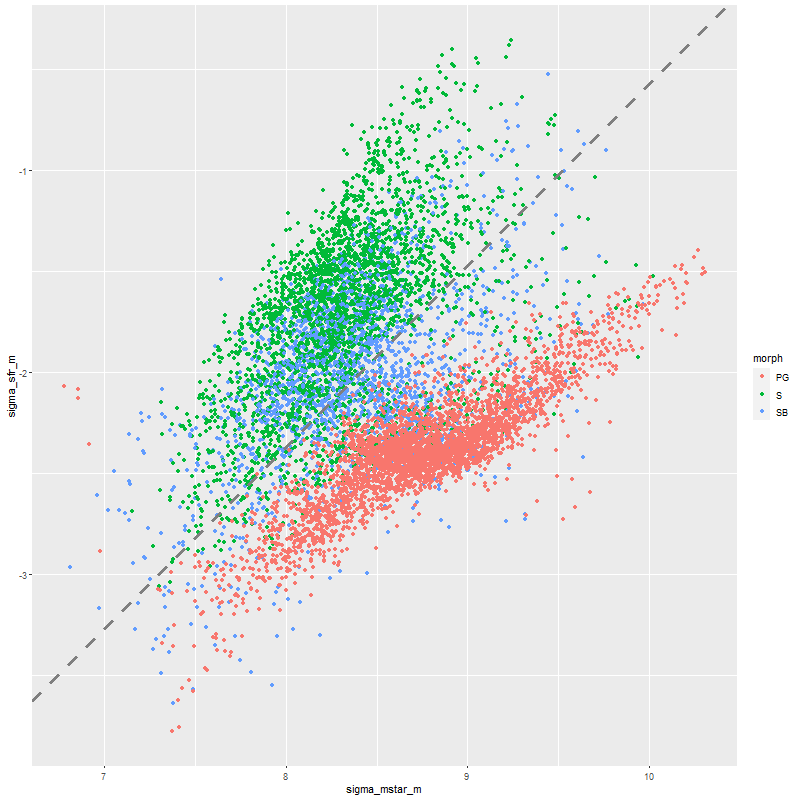
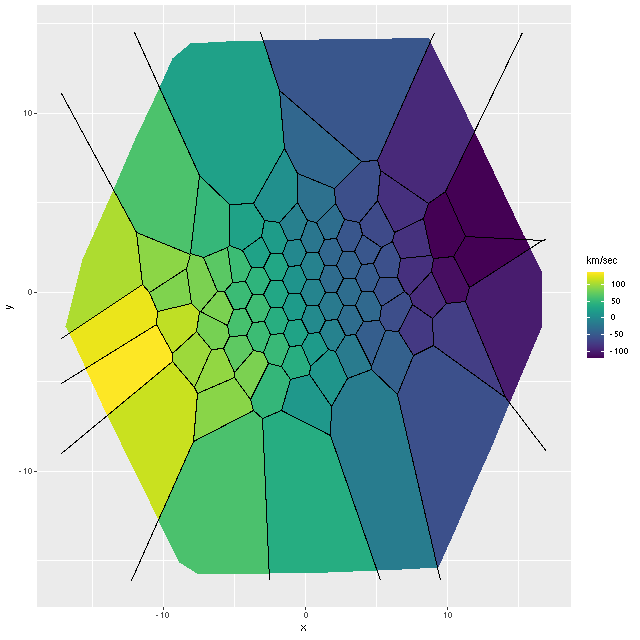
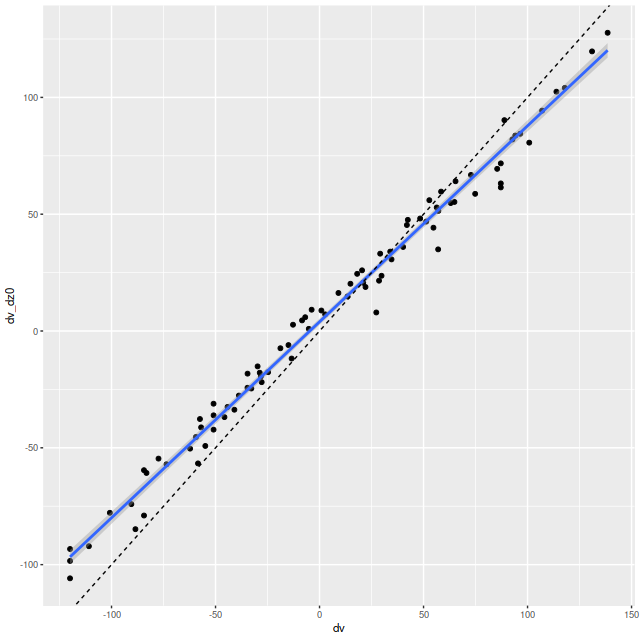
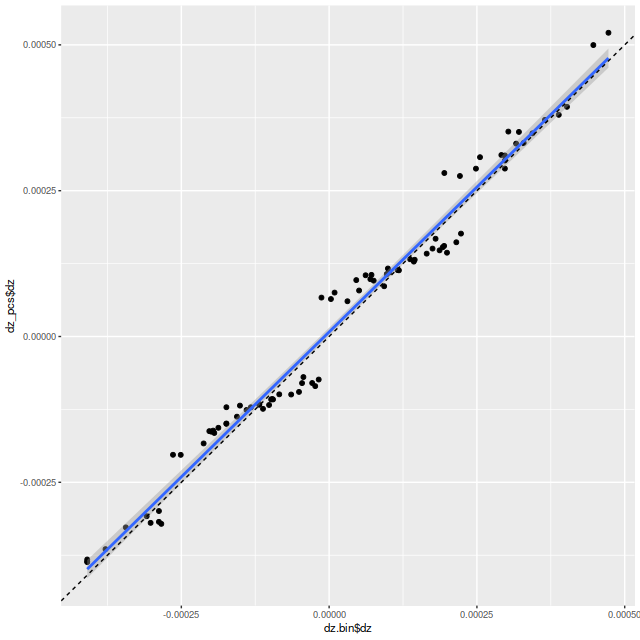
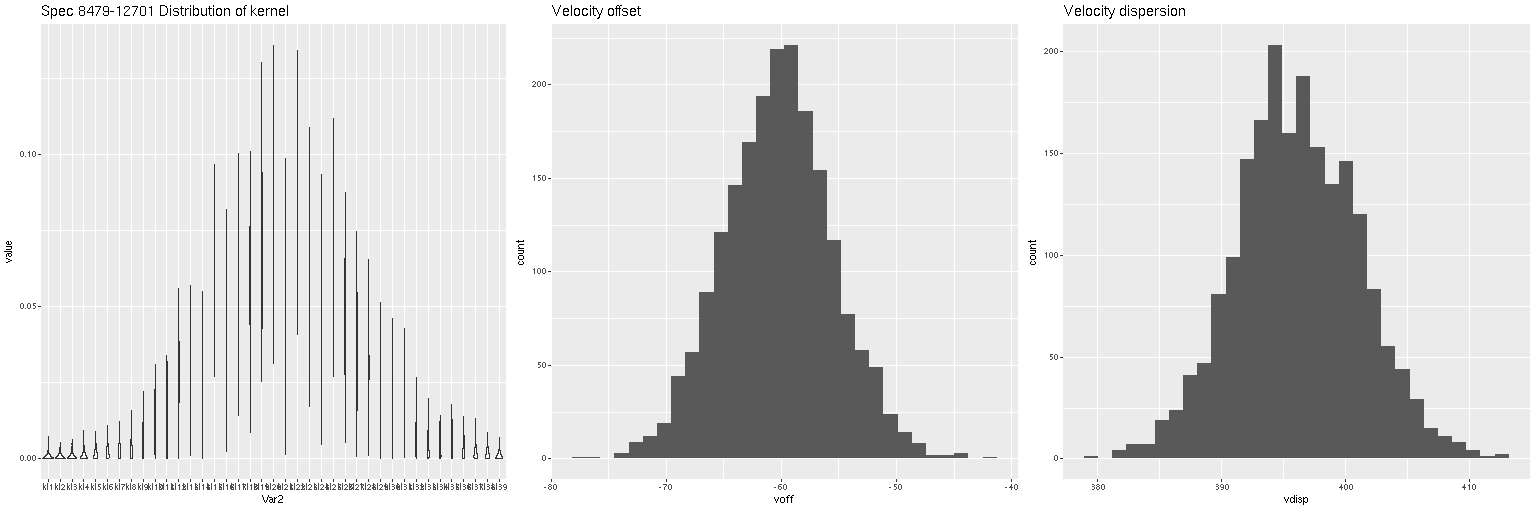
As always the first step in analyzing these data is to estimate redshift offsets for each spectrum, and from there we get a velocity field, which in this case shows a rapid rotator with a fairly symmetrical radial velocity pattern.
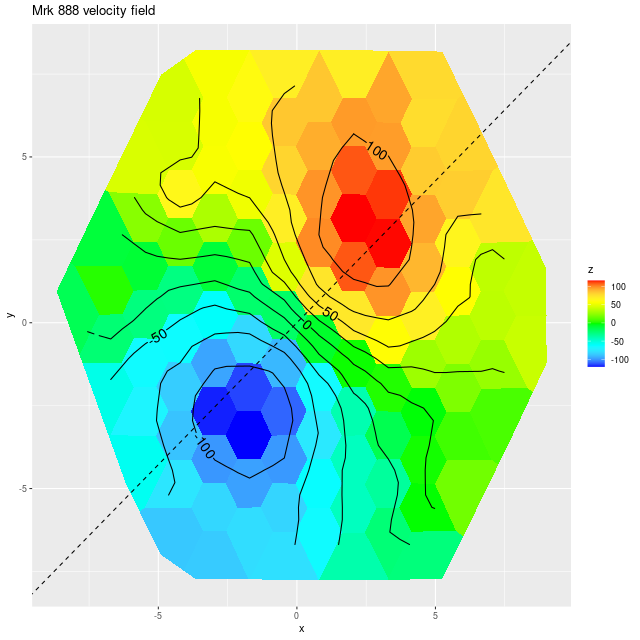
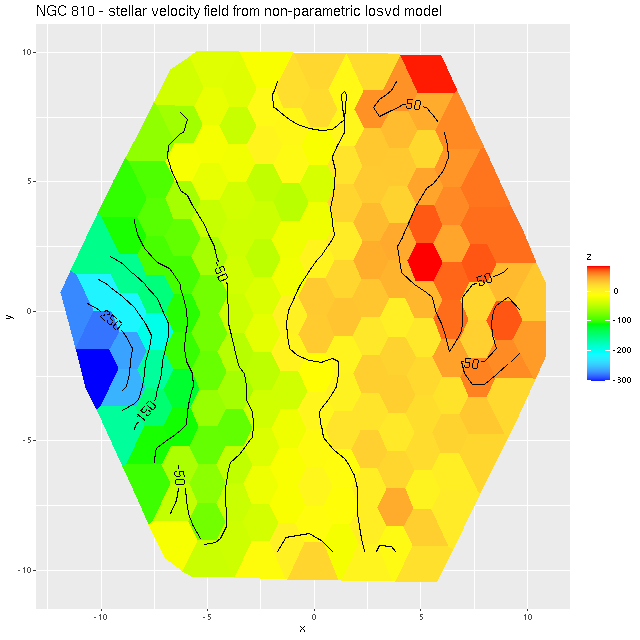
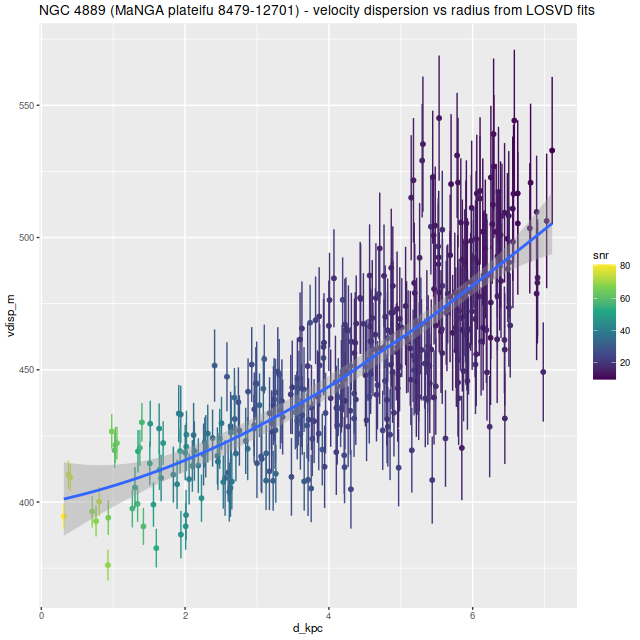
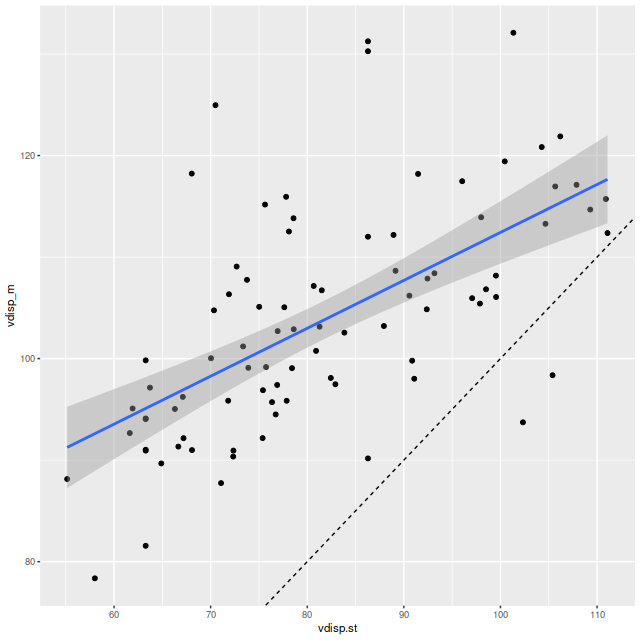
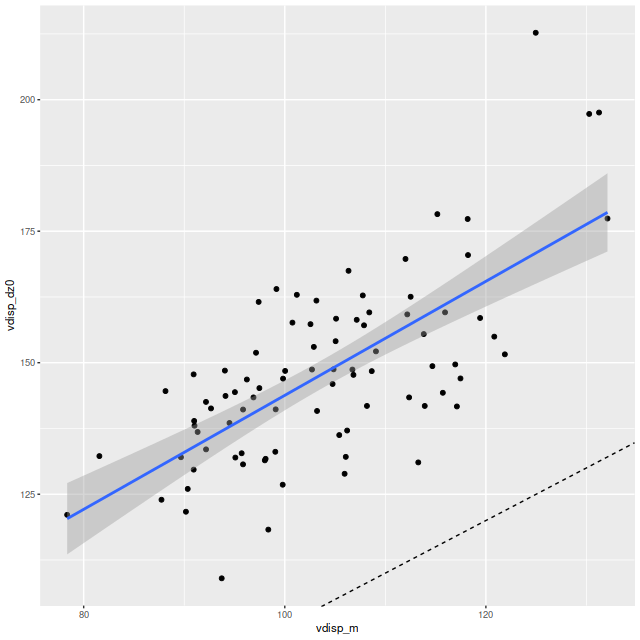
Visual inspection suggests the line of sight velocity distribution is consistent with a rotating thin disk, so I fed the data to my Gaussian process based rotation modeling code, with results summarized below. In fact the model does an excellent job of accounting for the data, with residuals (not shown) from the model fit (top right) in a range of ±15 km/sec. One unusual feature of the velocity field is the rotation velocity turns over at somewhat less than one effective radius. Whether the rotation curve declines smoothly outside the IFU footprint or is kinematically disconnected from the outer parts of the galaxy is of course unknowable at this time.

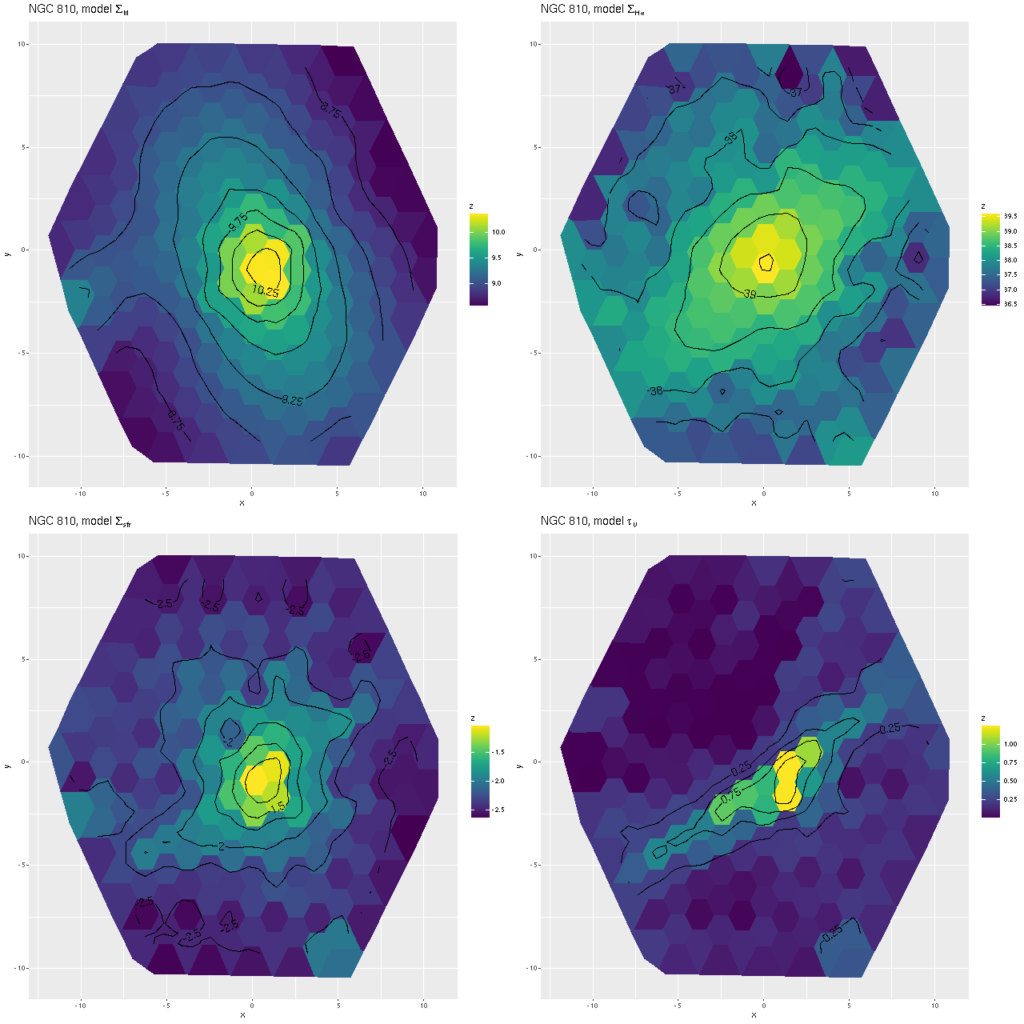
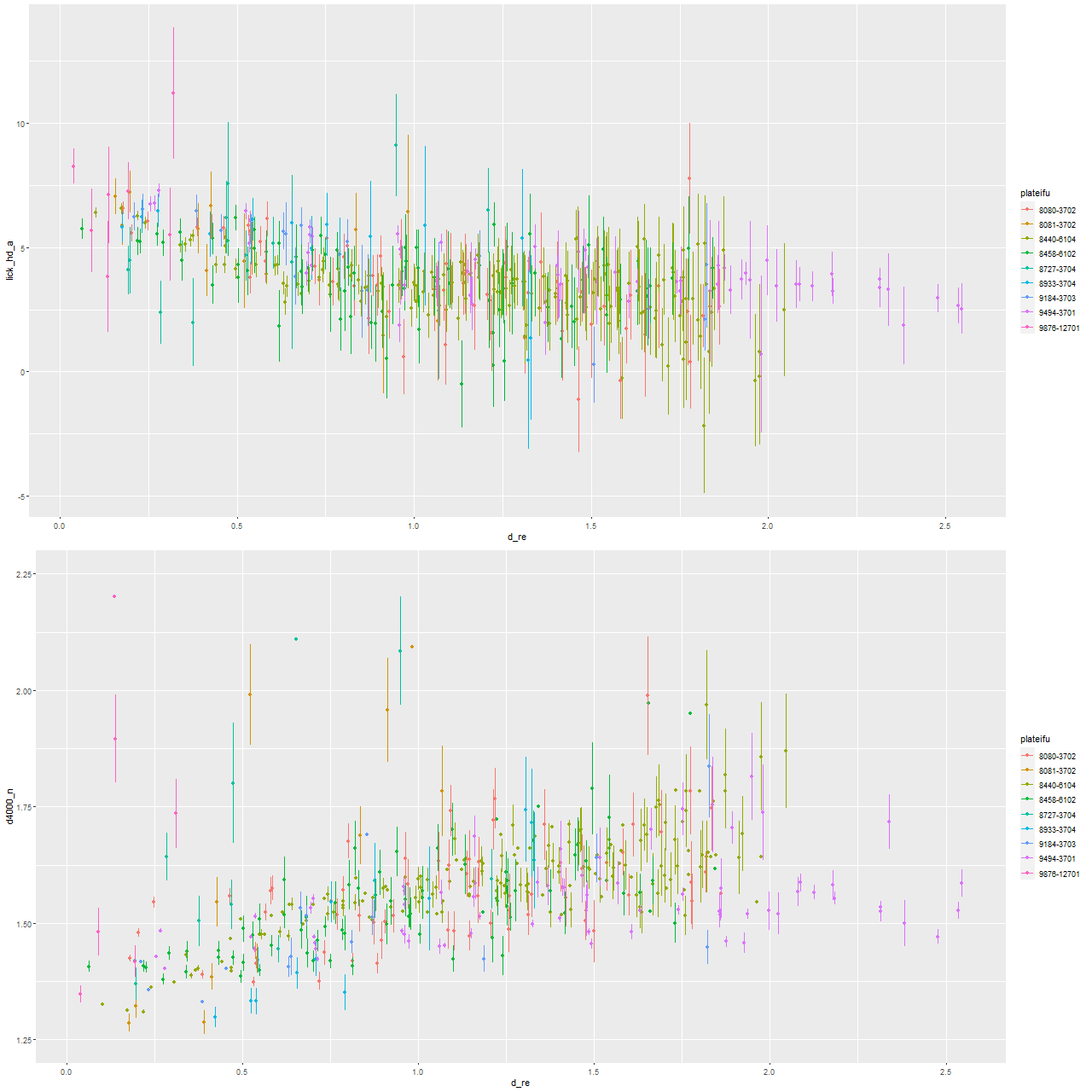
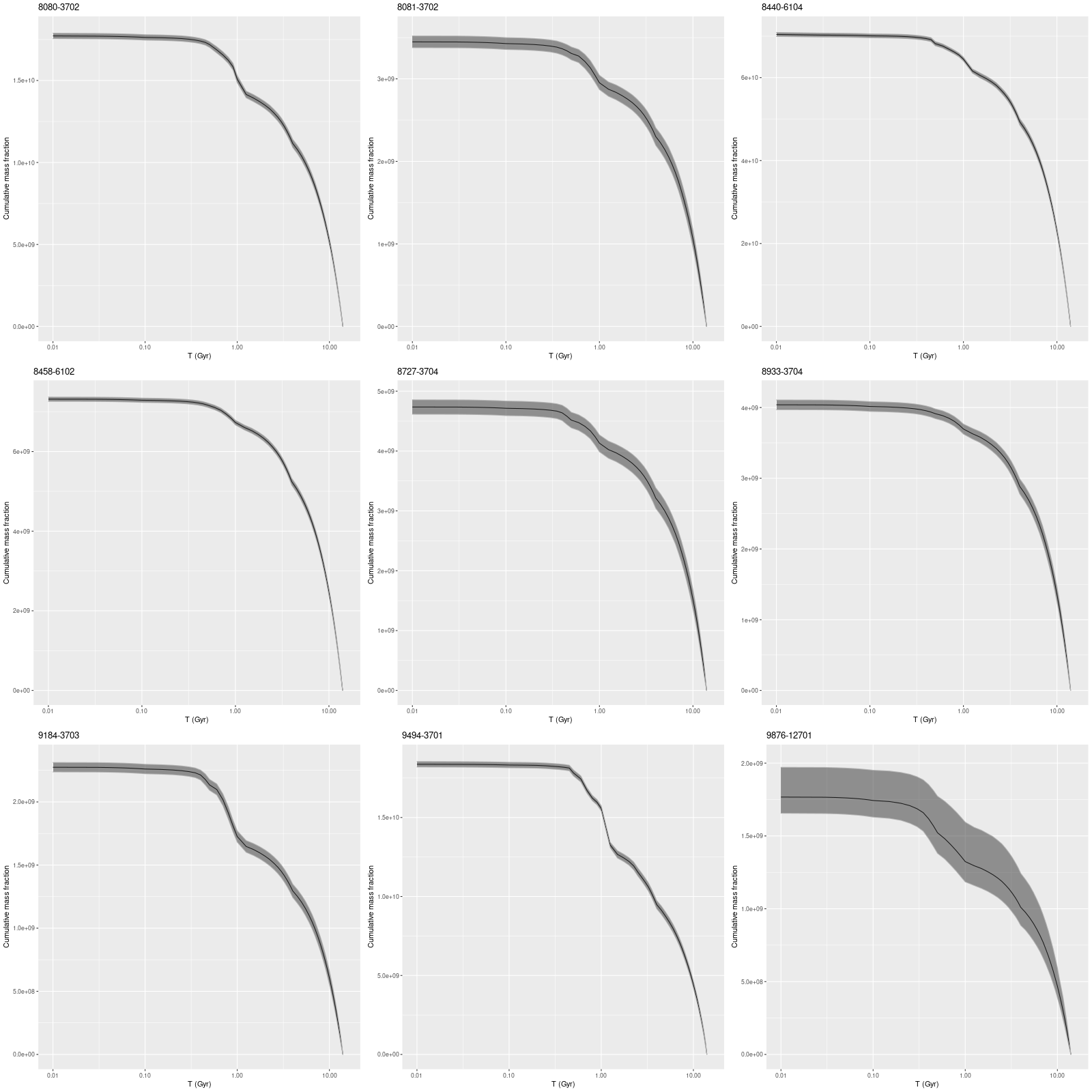
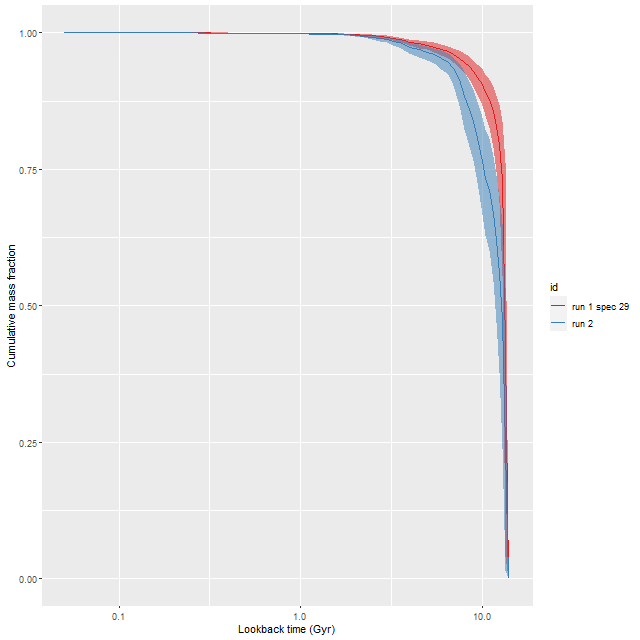
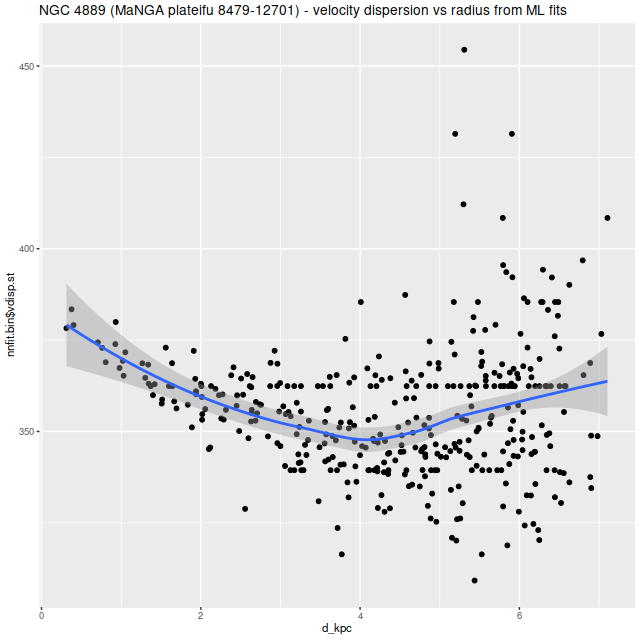
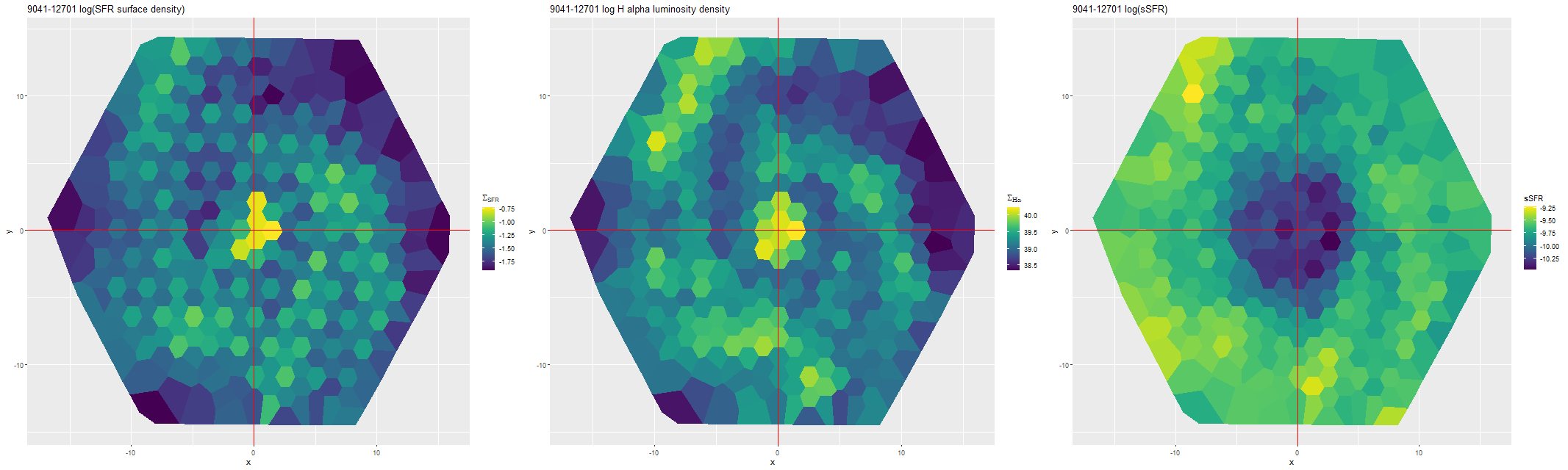
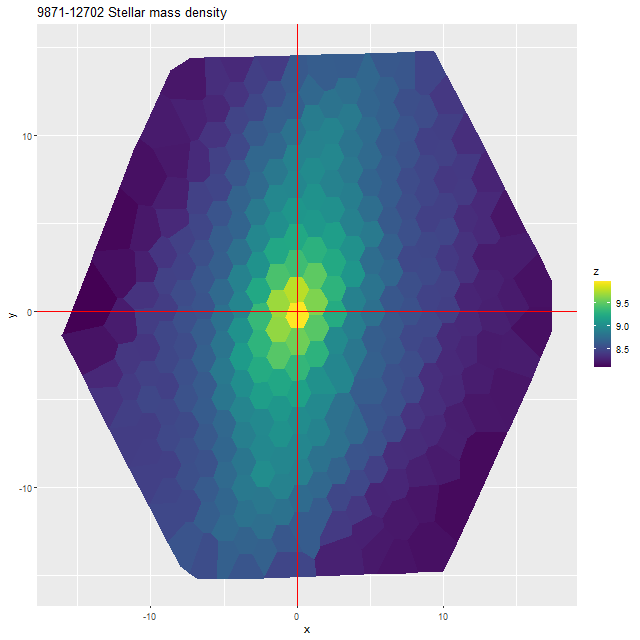
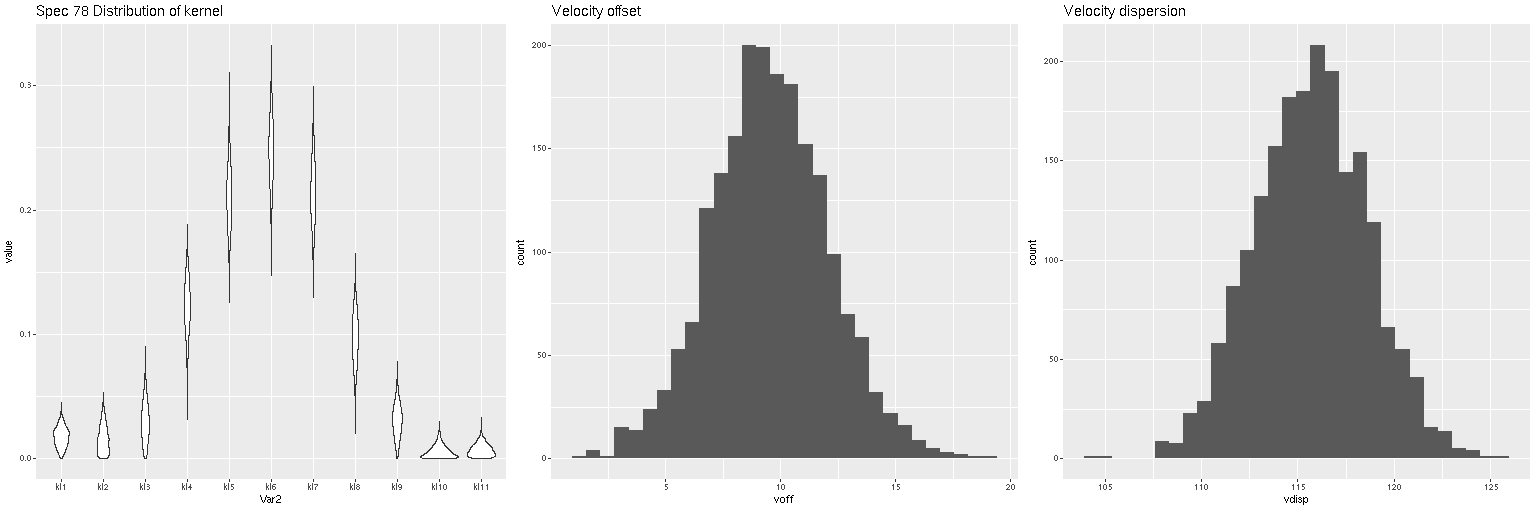
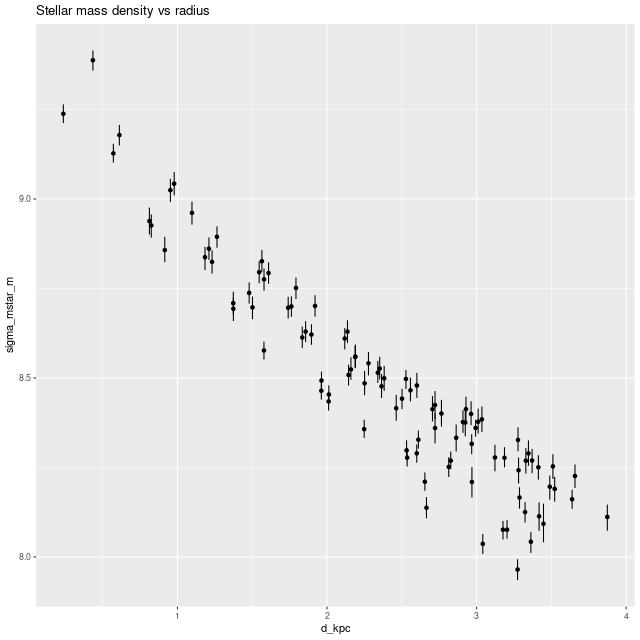
I also ran my usual star formation history modeling code on the data binned to 97 spectra. First, here are some summary results. The stellar mass density declines roughly exponentially, which is consistent with a disky morphology:
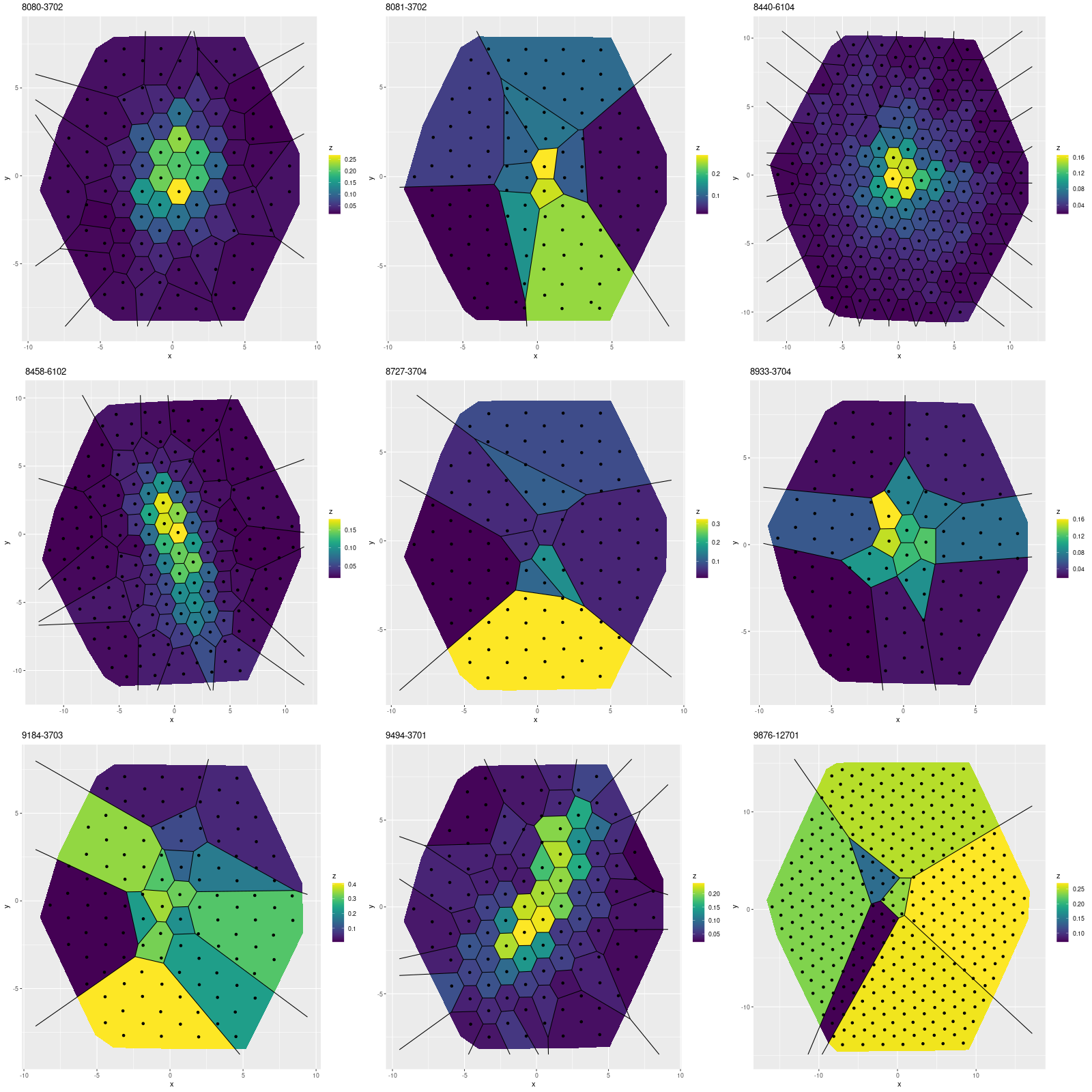
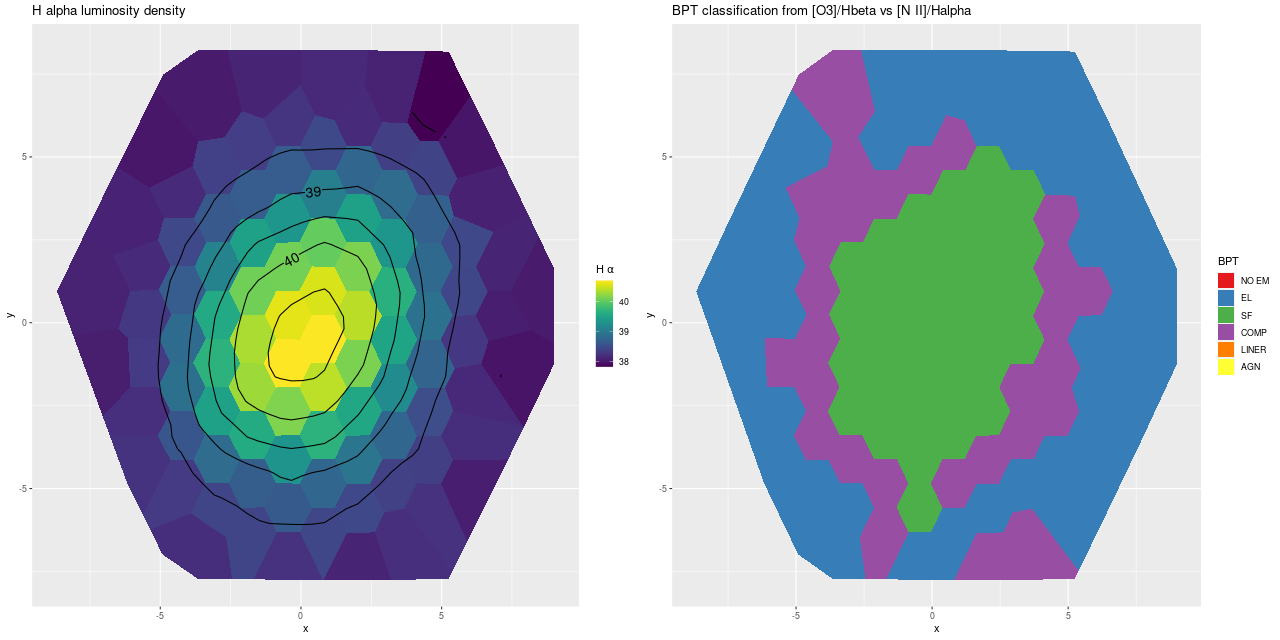
Next are maps of the estimated Hα luminosity density and, on the right, the BPT classification from the [O III]/Hβ vs. [N II]/Hα diagnostic. The contours are elliptical with major axes closely aligned to the rotation axis (the posterior mean for the angle is the dashed line in the velocity field plot above). Again, the emission appears to arise in a disk.
The proper interpretation of the “composite” BPT classification is something I think I’ve written about in the past. It was originally suggested to indicate a mix of AGN and stellar ionization, but here it arises in a thin ring of weak but detectable emission just outside the star forming region. If it’s truly composite it’s likely to arise from a mix of weak star formation and ionization by hot evolved stars. In any case there’s no evidence for an AGN in the optical data.
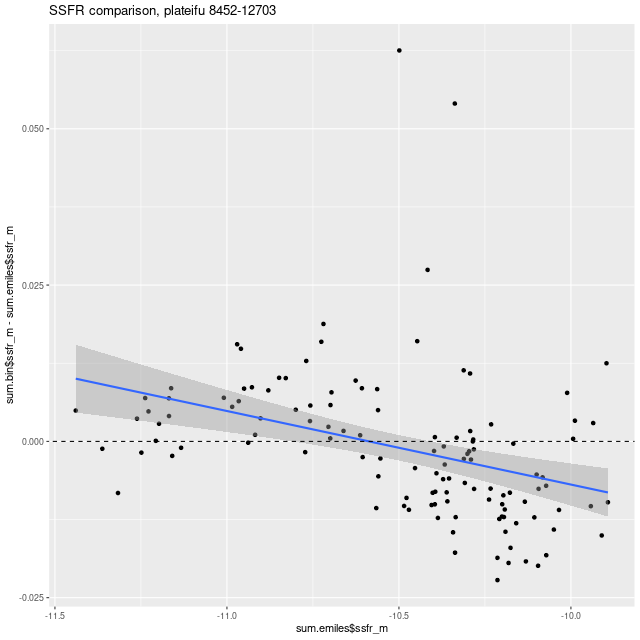
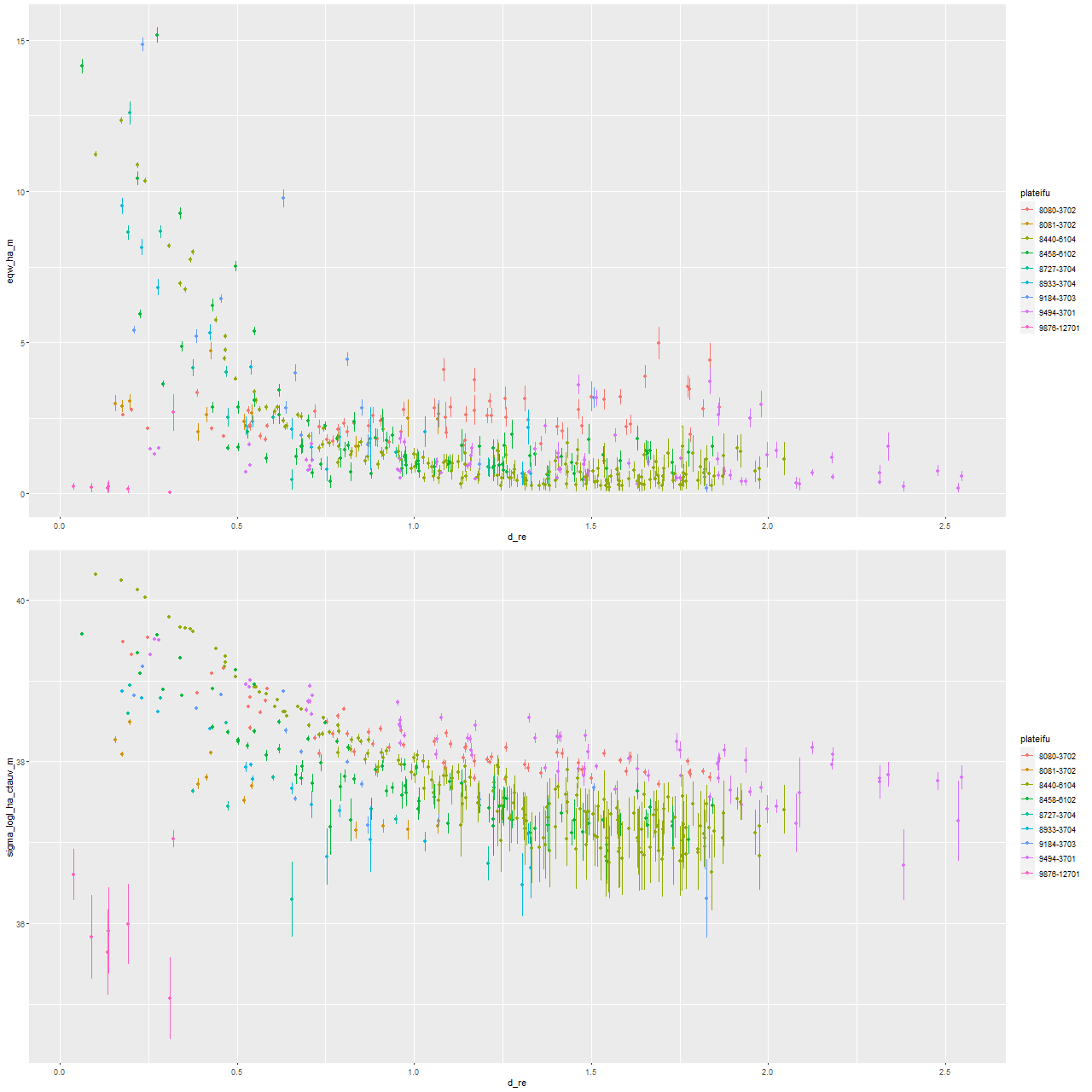
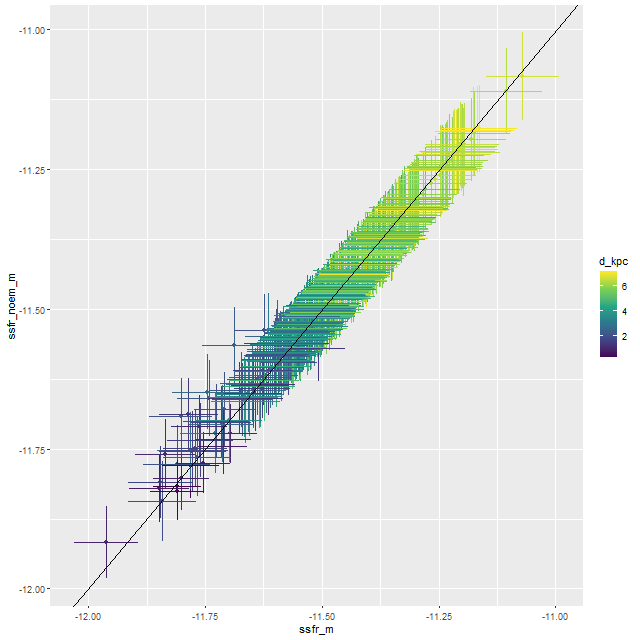
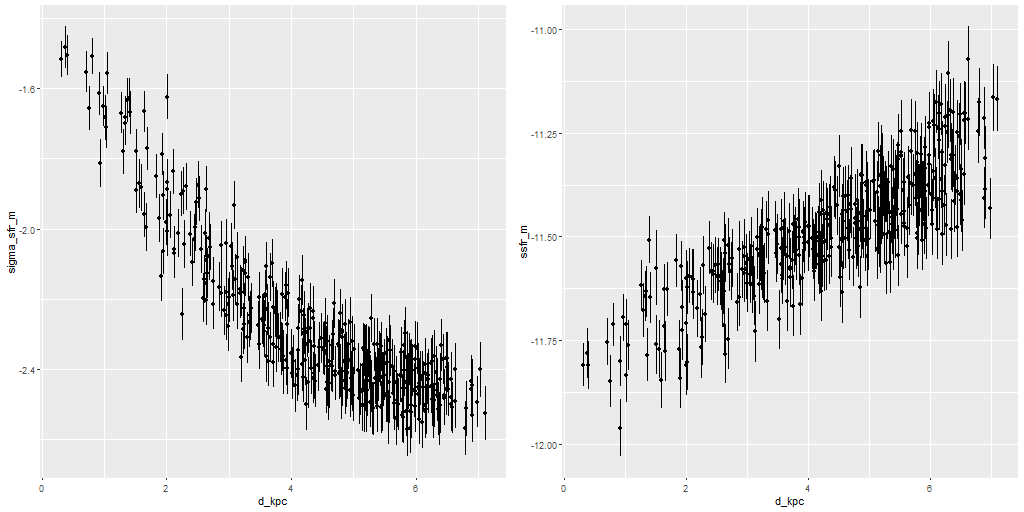
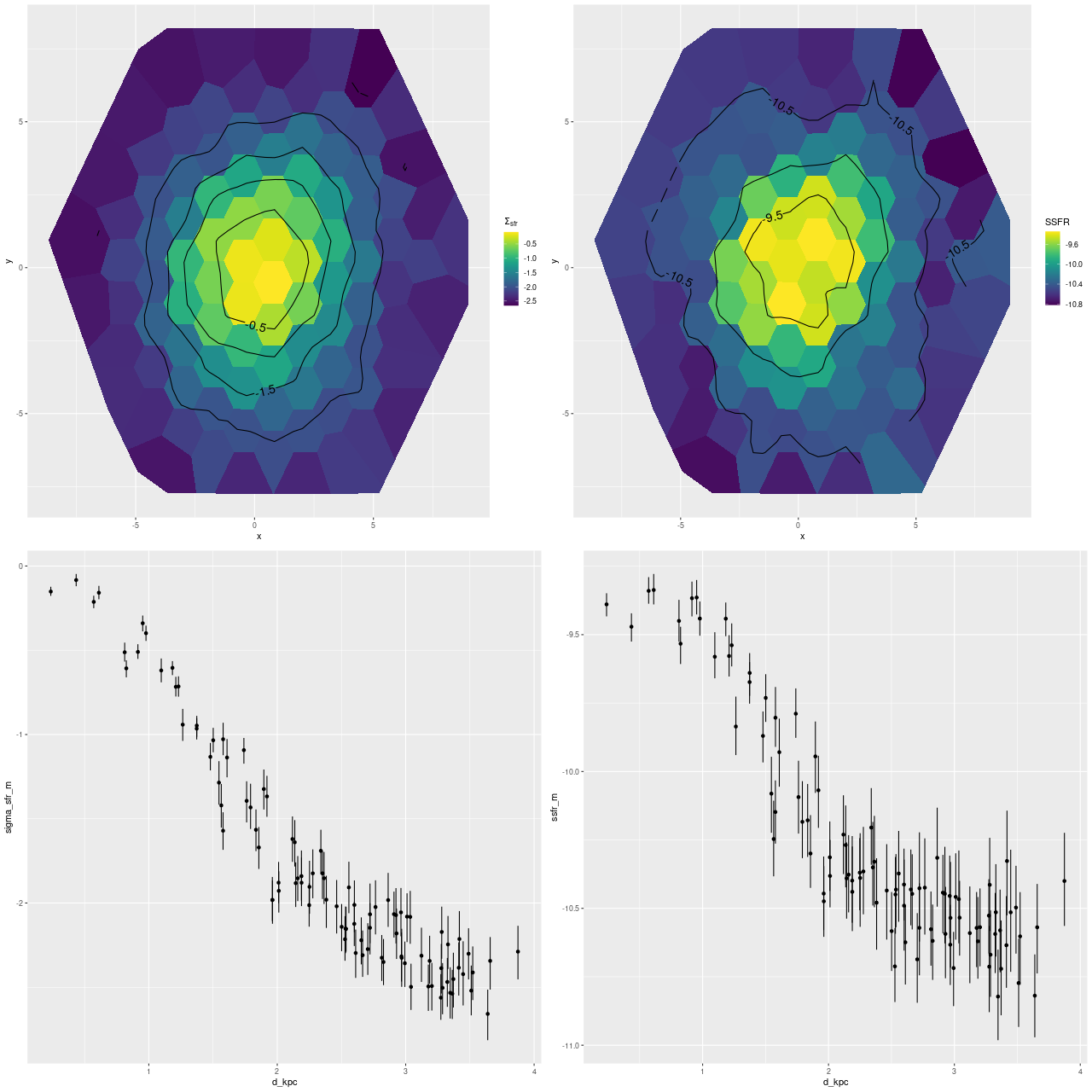
Next are maps of the modeled (100 Myr average) star formation rate density and specific star formation rate, and in the second row scatter plots of the same estimates against radius in kpc. The trends with radius are somewhat unusual, especially for SSFR which in a normal disk galaxy typically increases with radius even if the highest total star formation rates are centrally concentrated. Highly centrally concentrated star formation in the aftermath of mergers is predicted by some simulations.
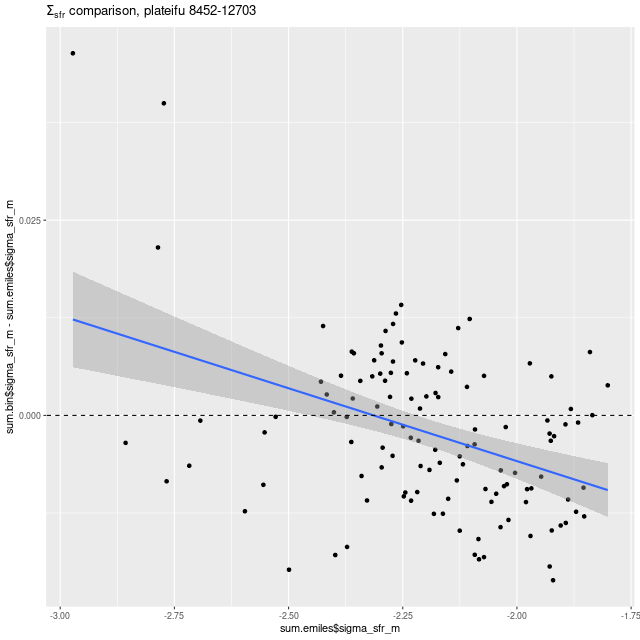
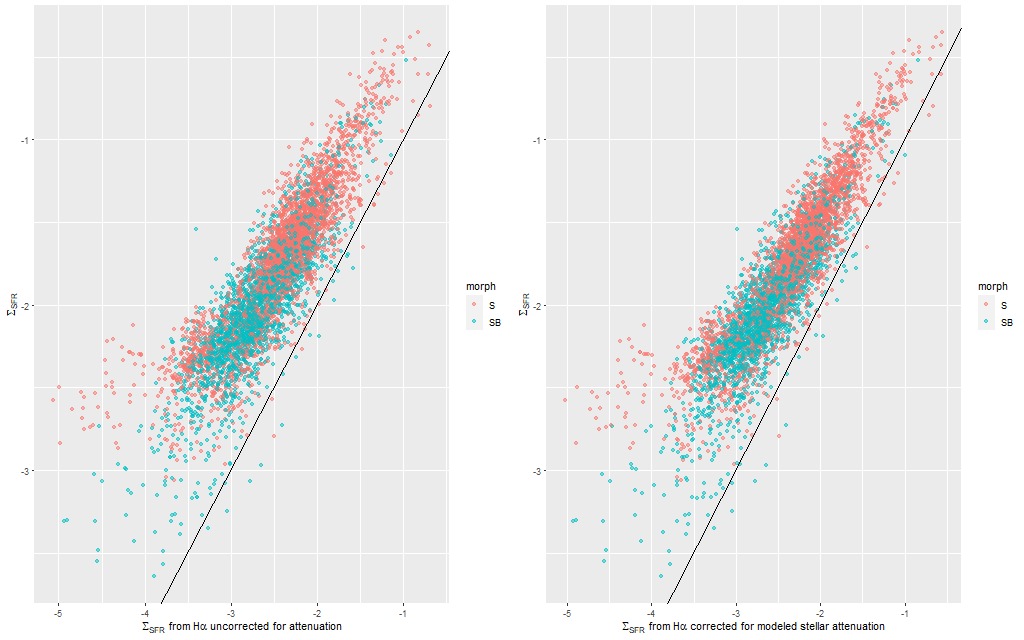
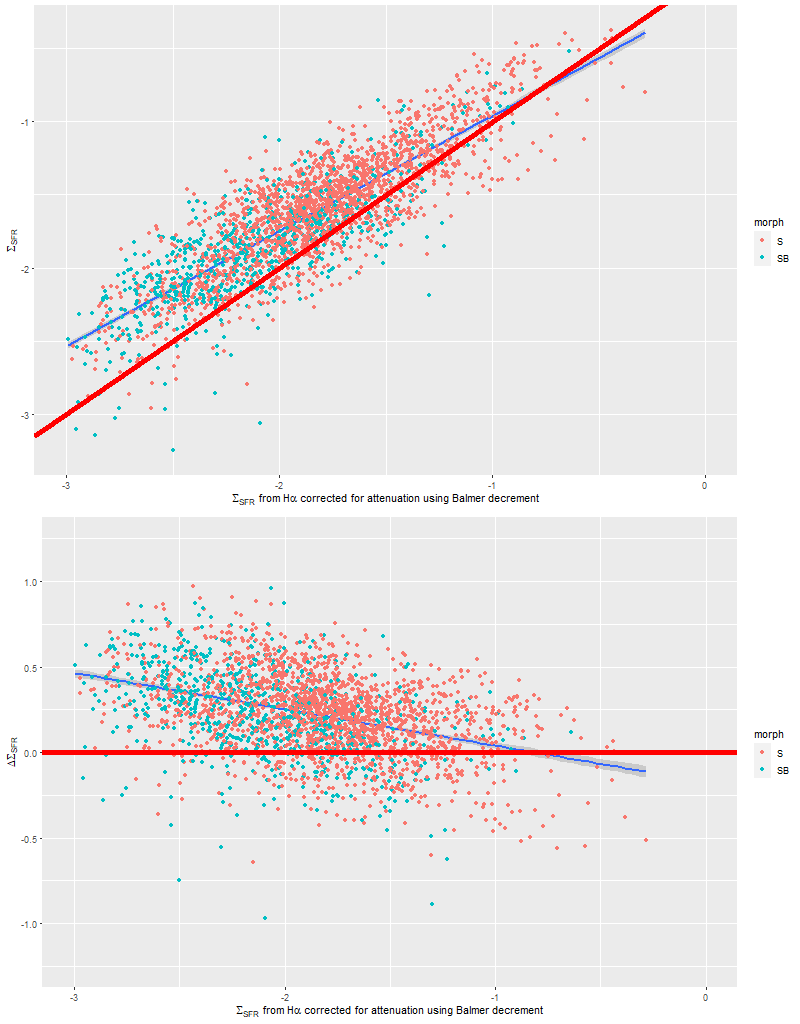
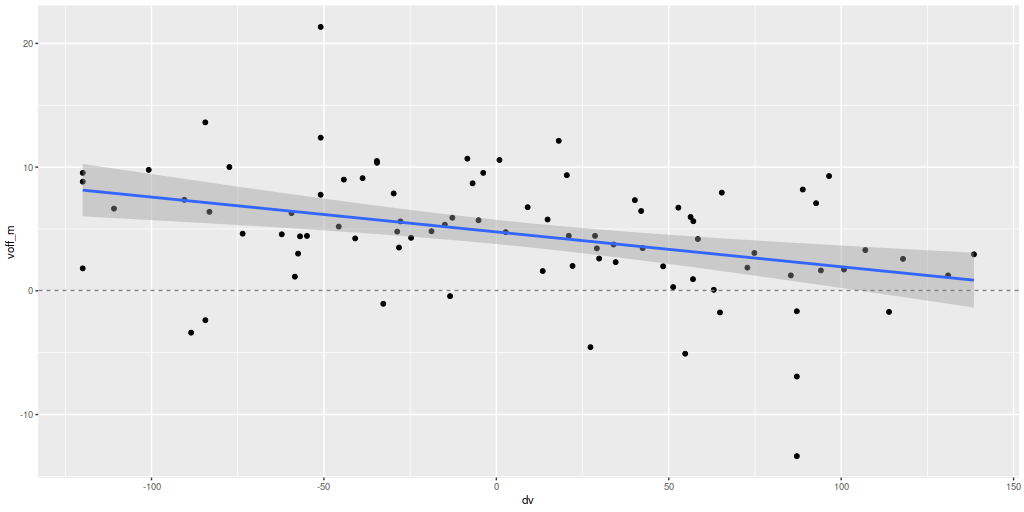
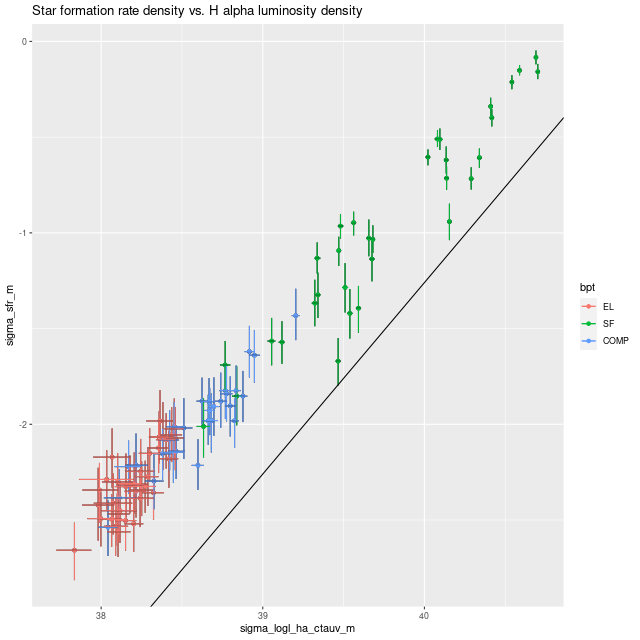
A couple more graphs will round out my discussion of summary model estimates. As I’ve shown several times before there’s a pretty tight linear relationship between modeled SFR density and estimated Hα luminosity density. In this plot Hα is corrected for modeled stellar attenuation, which is expected always to underestimate the attenuation in emission line emitting regions. That, and the fact that Hα emission and the model star formation rate estimates probe order of magnitude different time scales probably account for the systematic offset from the standard calibration given by the straight line.
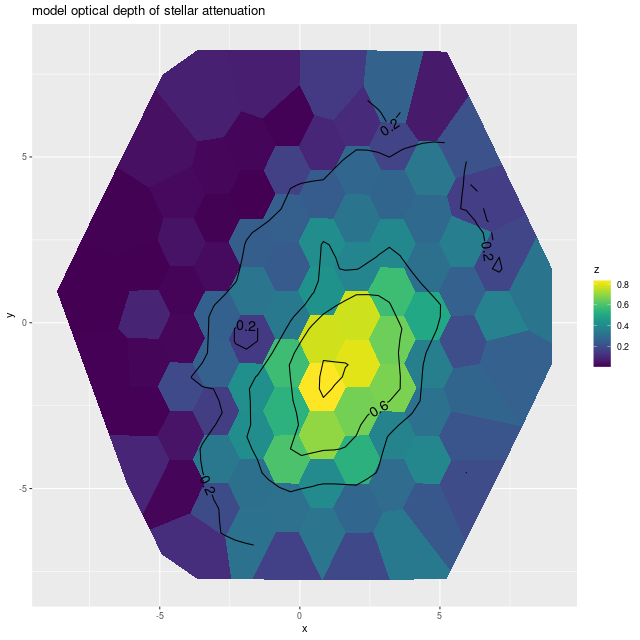
And, once again I show a map of the modeled optical depth of stellar attenuation. The region of highest optical depth nicely tracks the visible dust (the HST image at the top is rotated about 90º from the SDSS image). Outside the dusty region there appears to be a shallow gradient, which might indicate that the nearer side is to the northeast.
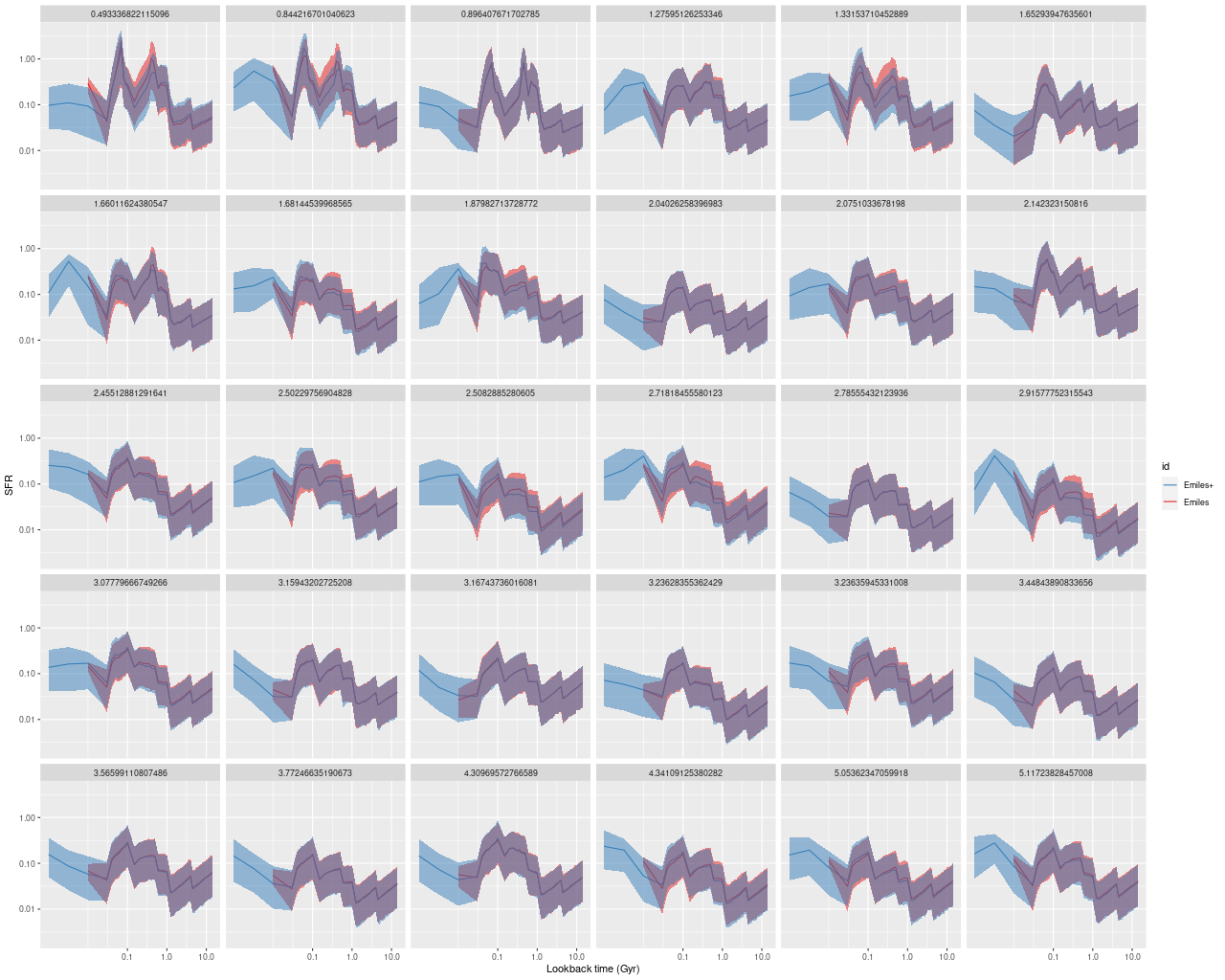
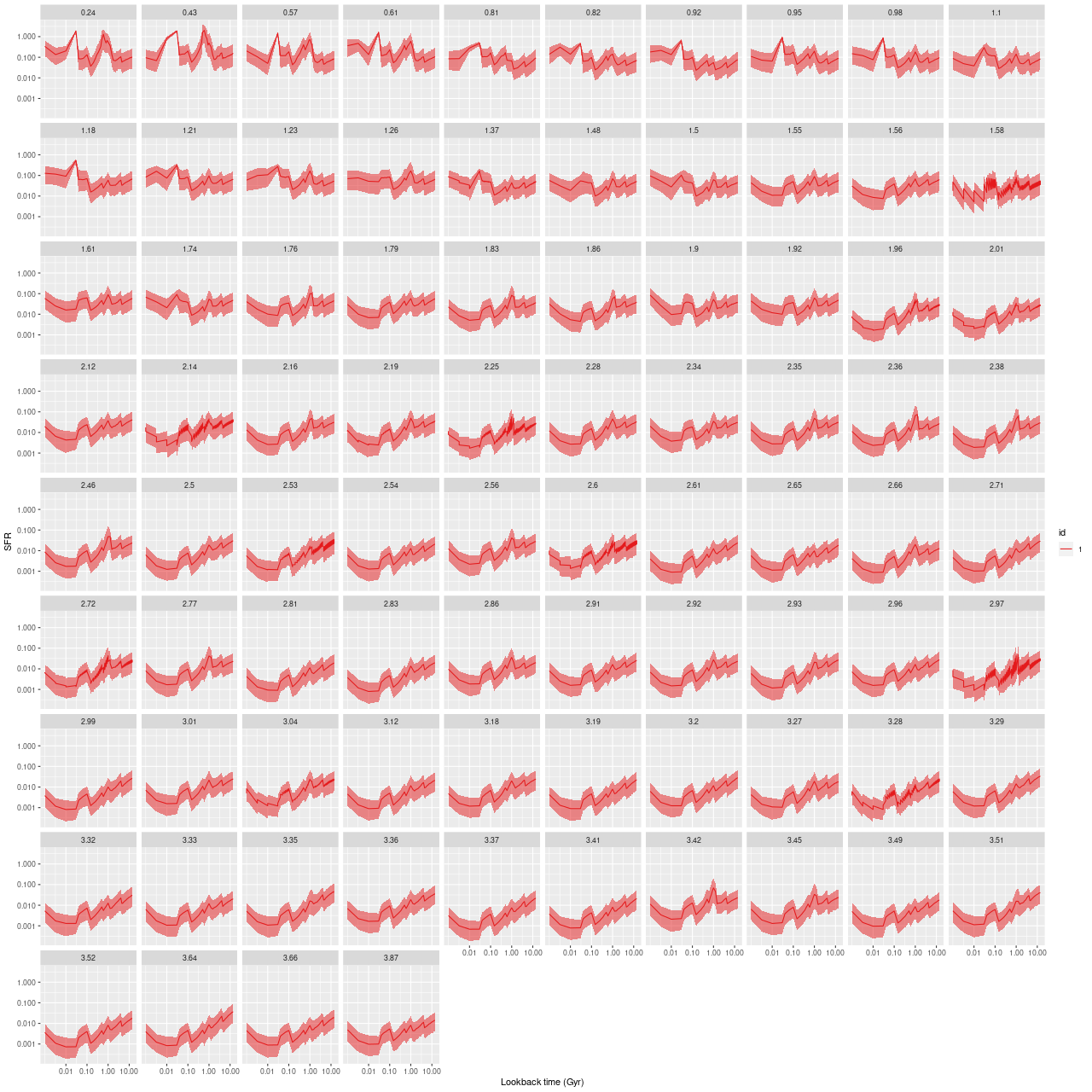
Finally here are plots of the model star formation history for all spectra ordered by distance from the IFU center. In the inner 1.5 kpc or so there’s some recent burstiness with possibly a very recent acceleration of star formation. For reasons I’ve discussed recently I don’t take either the timing or magnitude of bursts of star formation too seriously, but the behavior of the models is consistent with a recent revival of star formation due presumably to a merger, for which there are multiple lines of evidence.
With 24 of these galaxies and another 31 from the compilation of Melnick and dePropris and the post-starburst ancillary program in the final release of MaNGA these samples satisfy my criteria of being manageably sized for my computing resources while large enough to say something about the groups. So, when time permits I plan to take a look. I already have the data in hand.