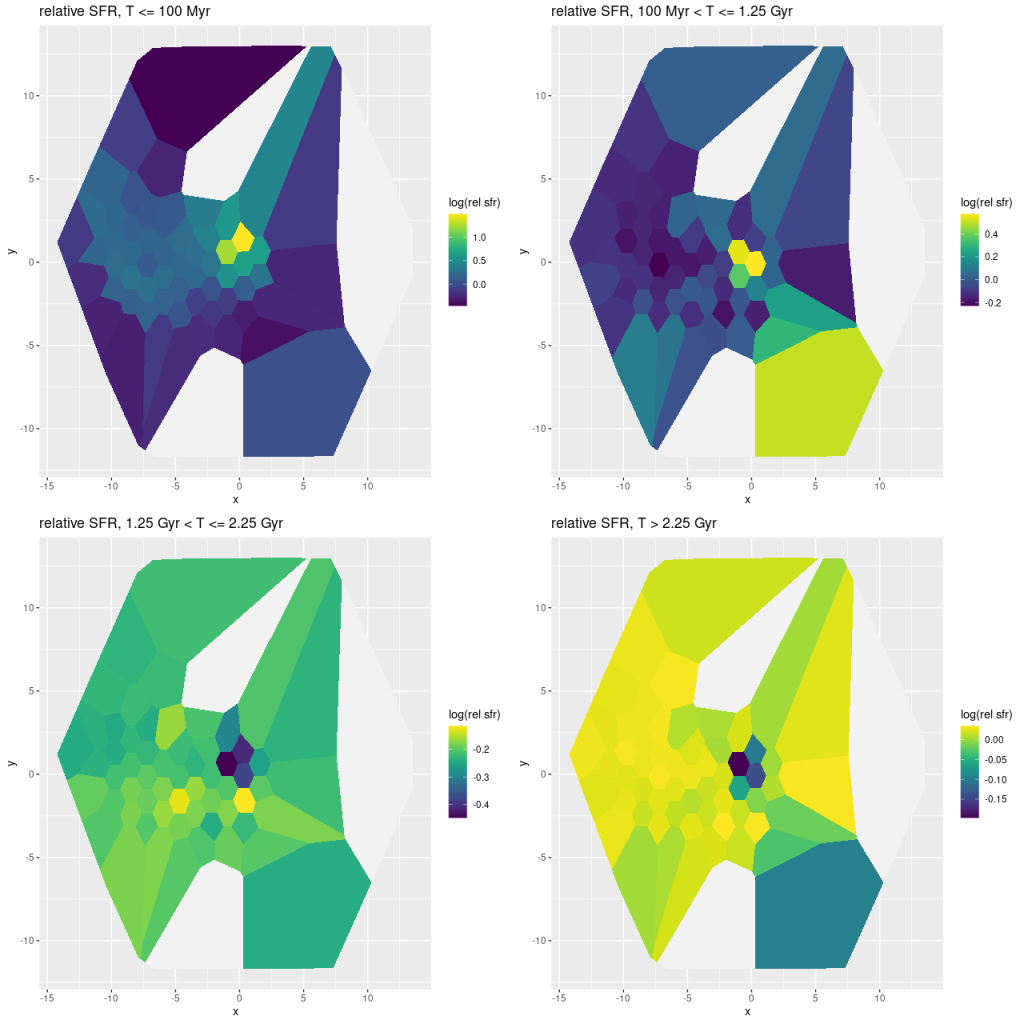
I’ve been making my way through Leung’s PSB sample and noticed this exceptionally interesting “CPSB” sample member, which oddly enough they chose not to include in their analysis. This is NGC 2623, a rather famous merging galaxy pair that was one of Toomre‘s exemplars of a late stage merger. This is a well studied system, with over 500 references listed in NED and observations apparently in every electromagnetic frequency range for which telescopes exist (nothing from JWST yet though).

MaNGA targeted it with one of their largest IFUs, which covers most of the visible light (at the depth of SDSS imaging) of the merger remnant, but very little of the tidal tails. There’s also a CALIFA IFU dataset with a larger spatial footprint but lower spectral resolution. I haven’t looked at that in detail yet except to estimate the relative velocity field..
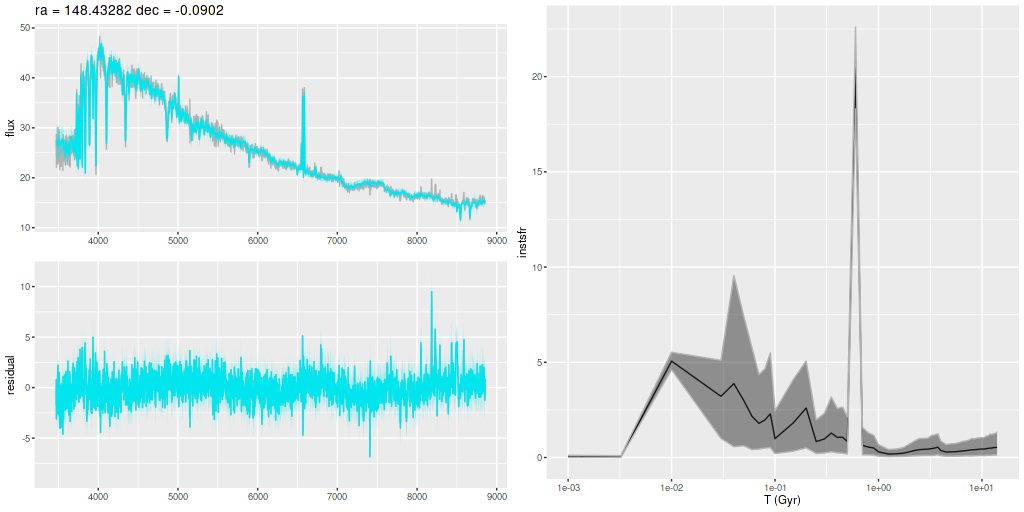
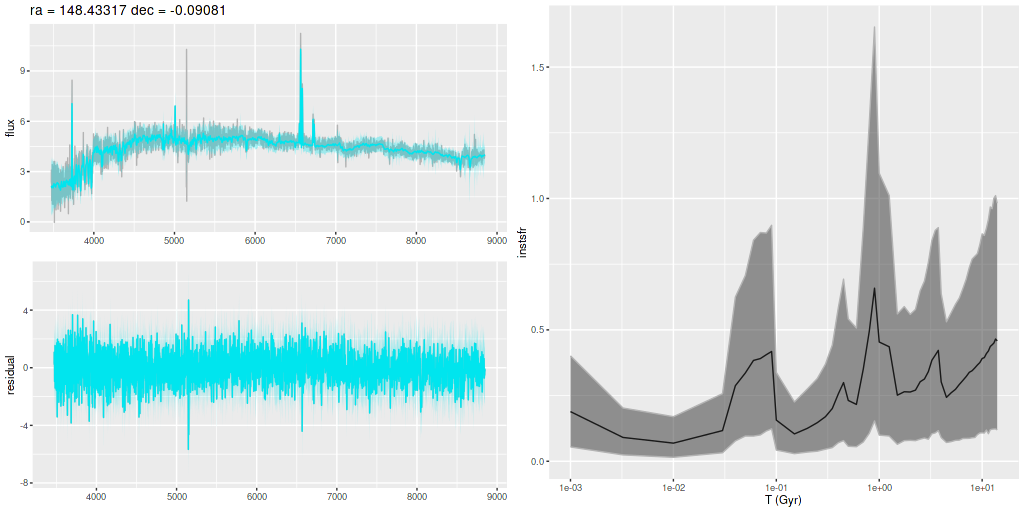
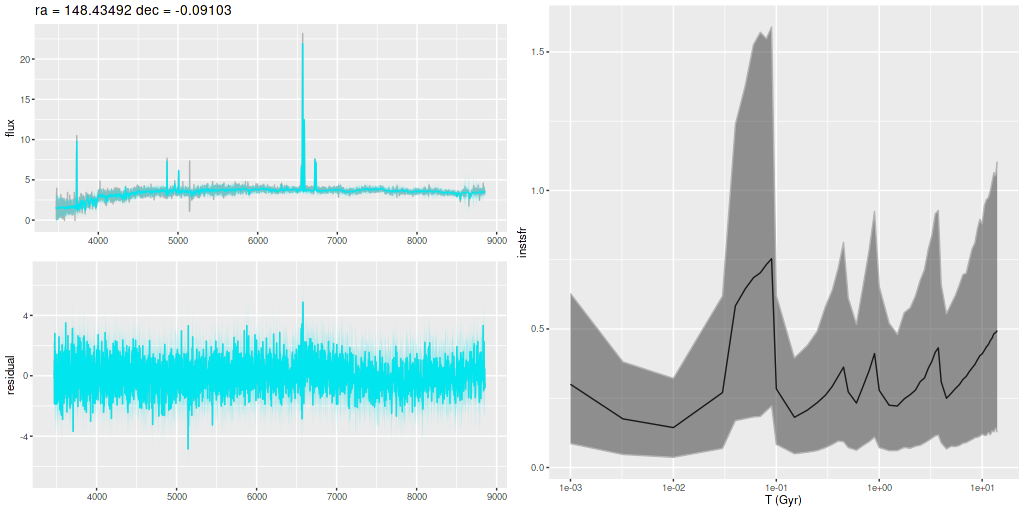
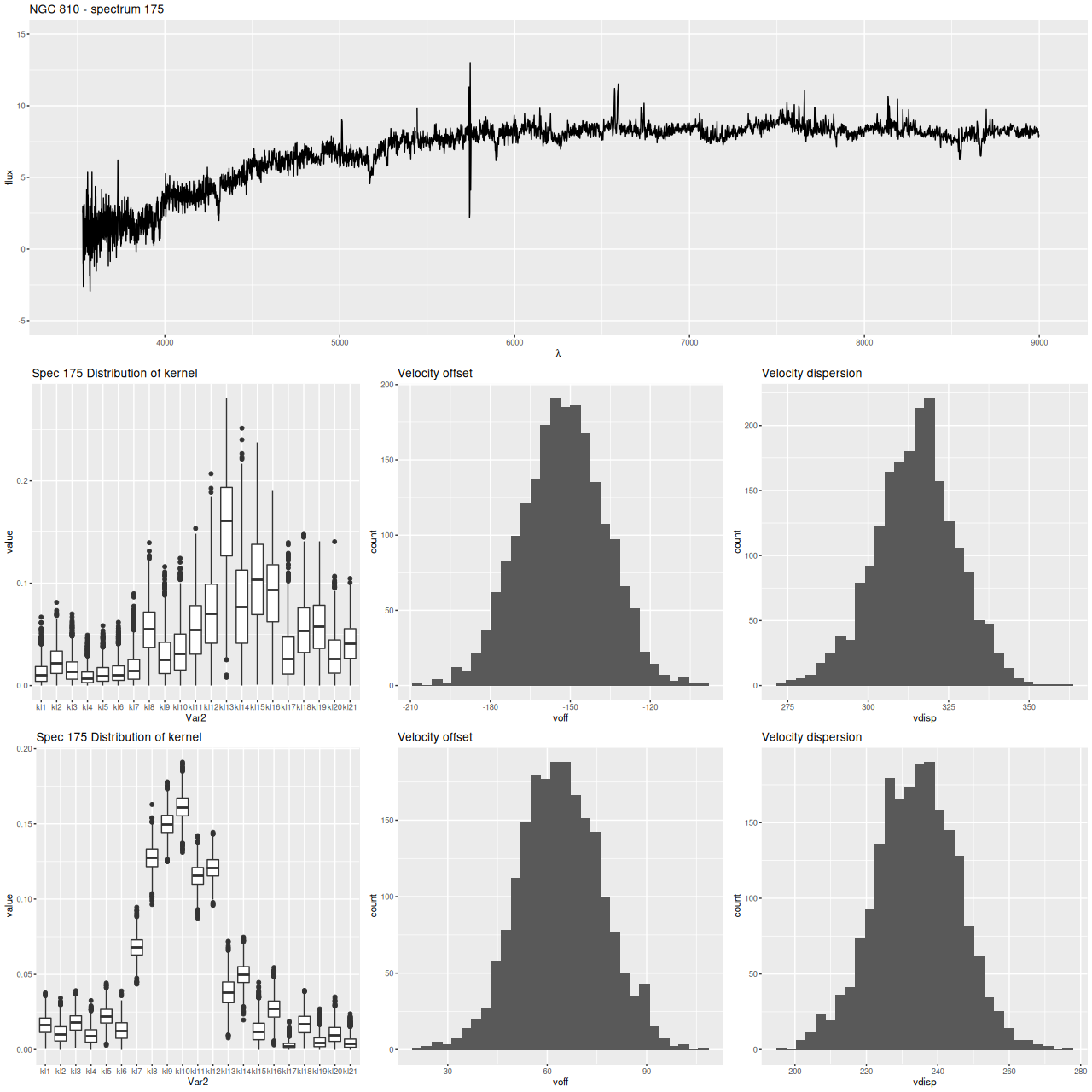
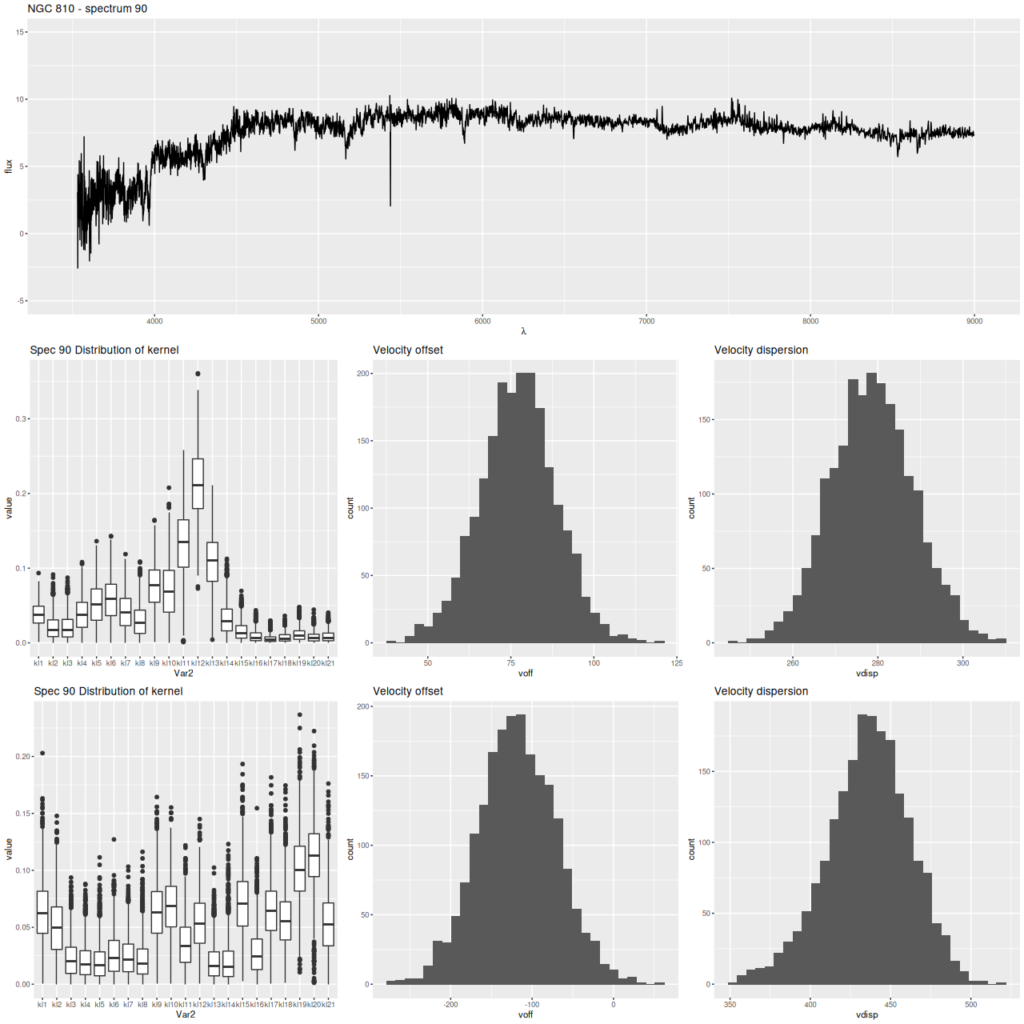
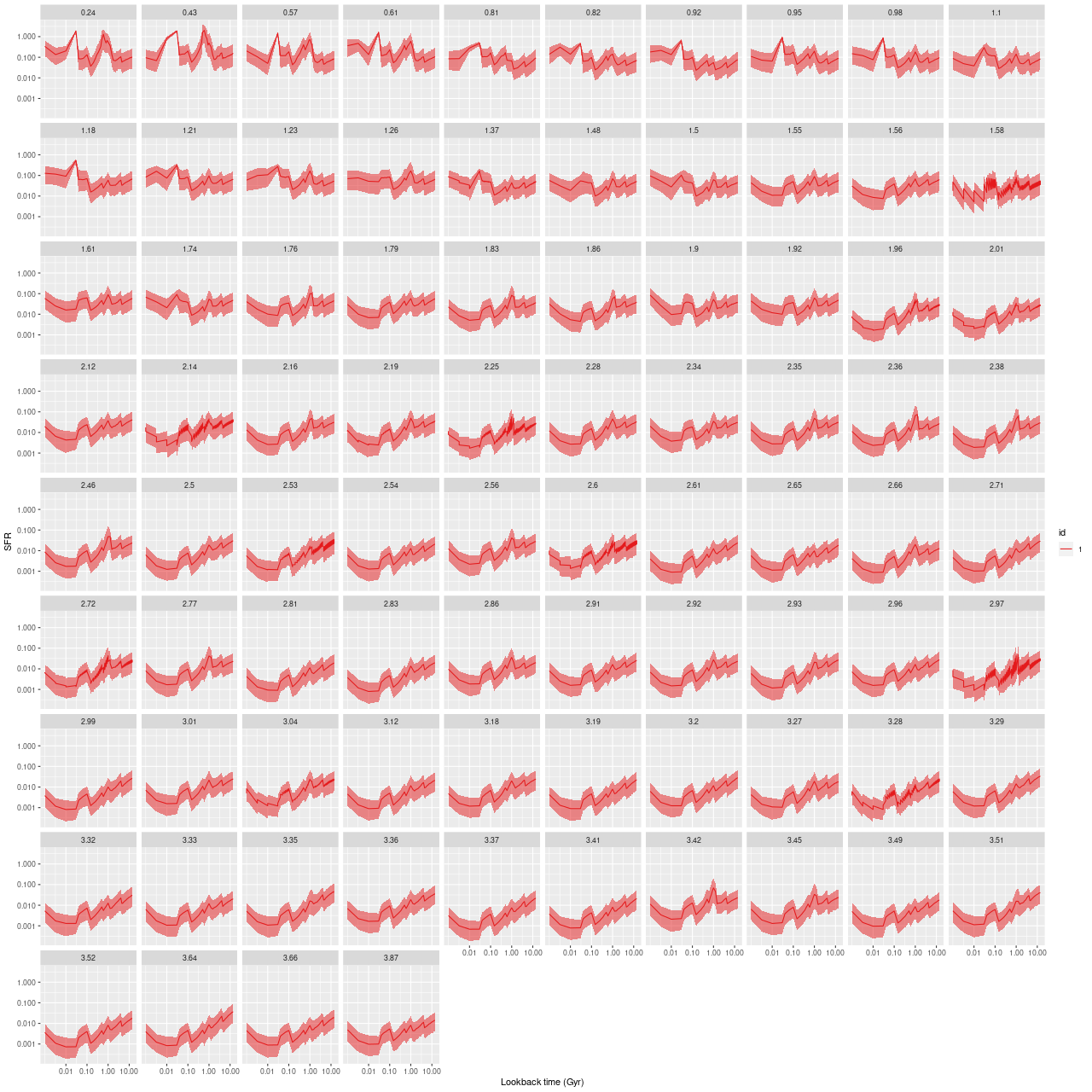
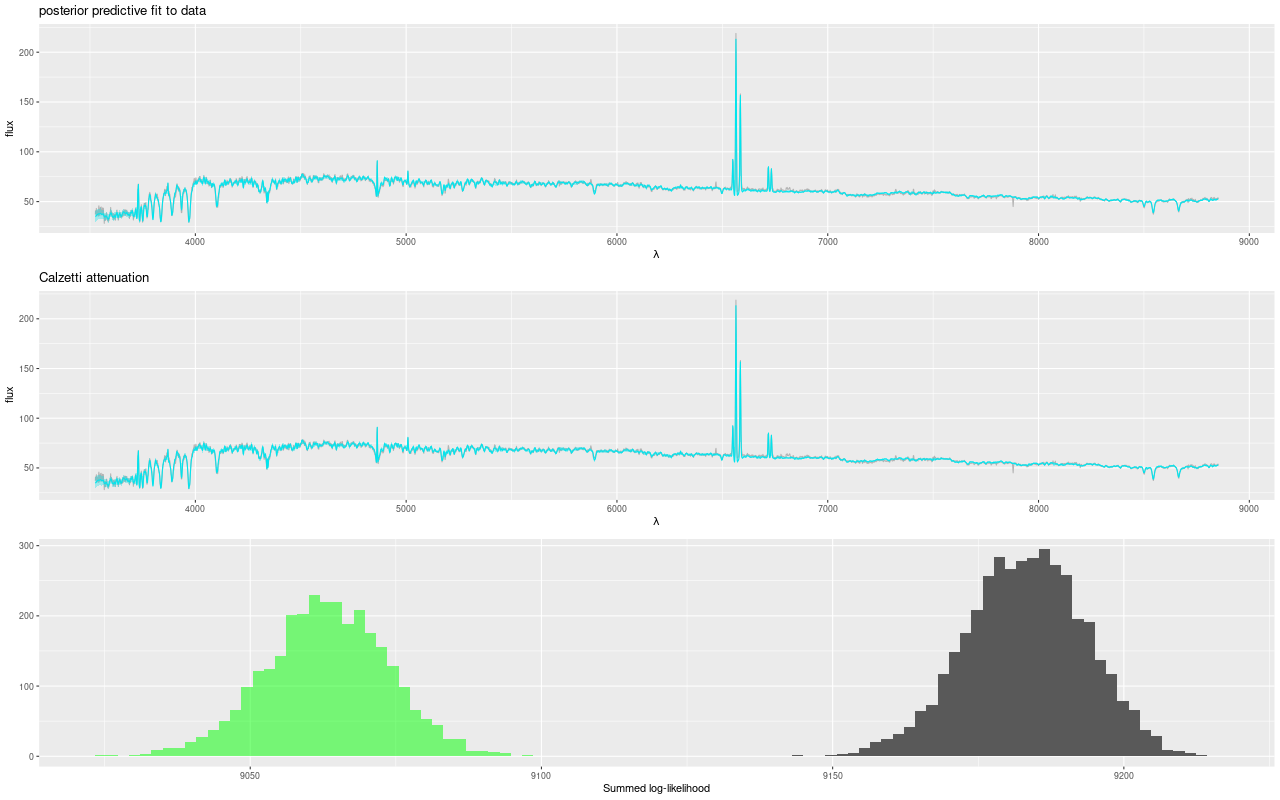
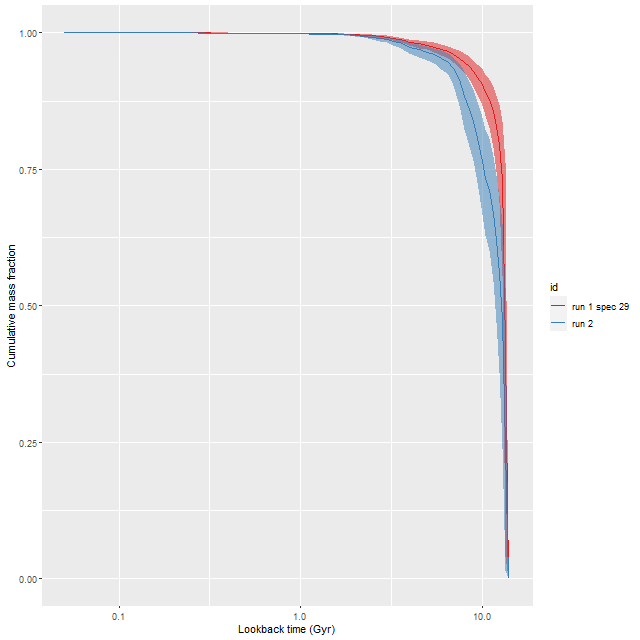
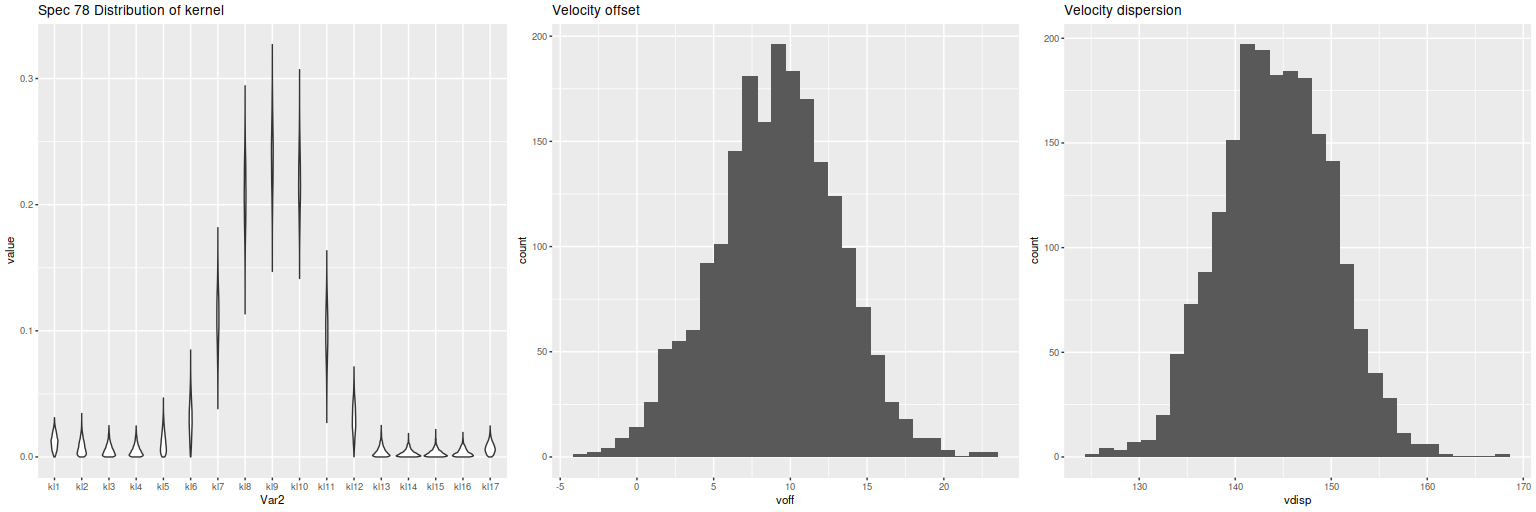
As usual I work with RSS spectra stacked and binned to a target S/N. For this final post starburst project I’m trying to set a higher S/N threshold. In this case I ended up with 214 spectra with S/N per pixel ranging from 8.5 to 42.5.

Kinematics
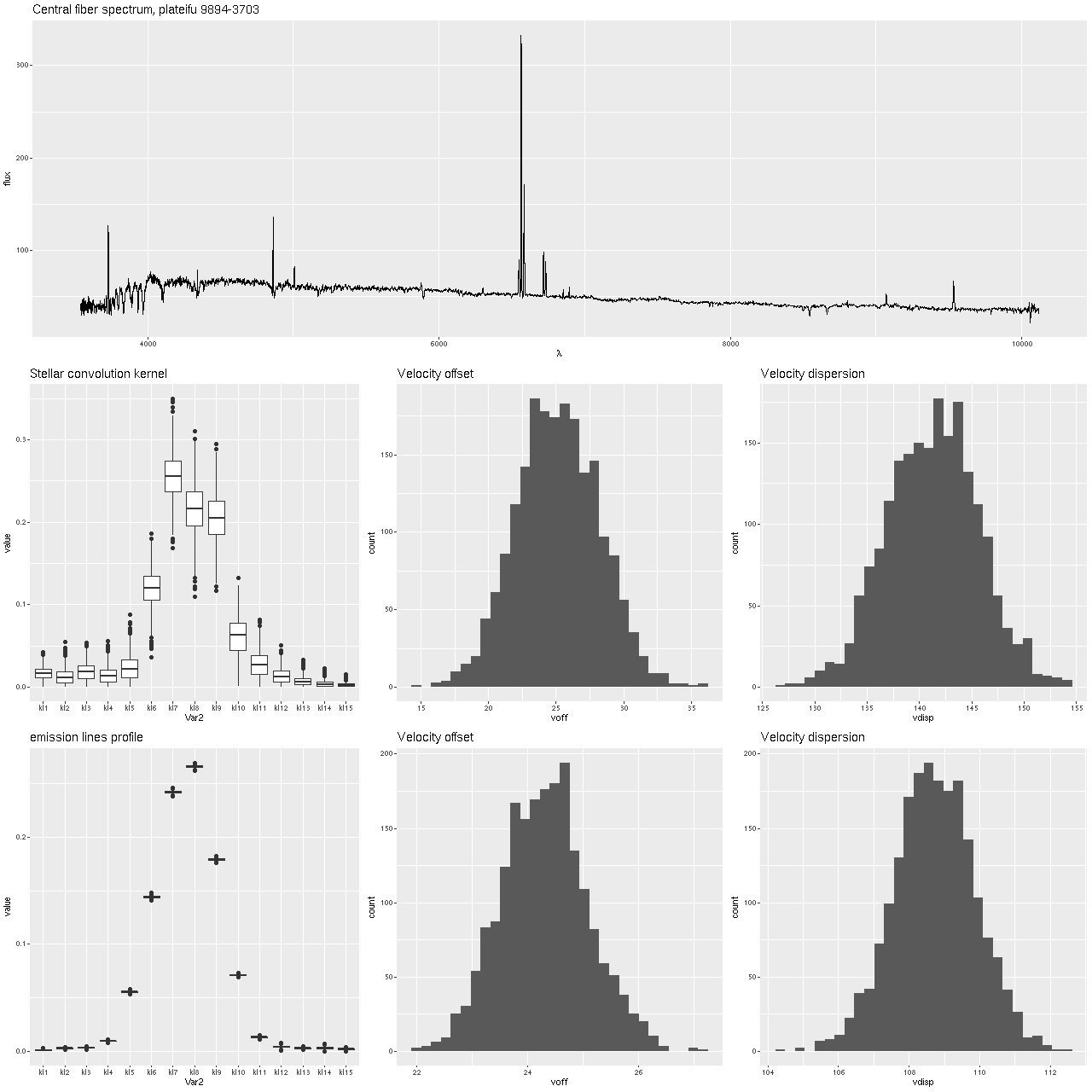
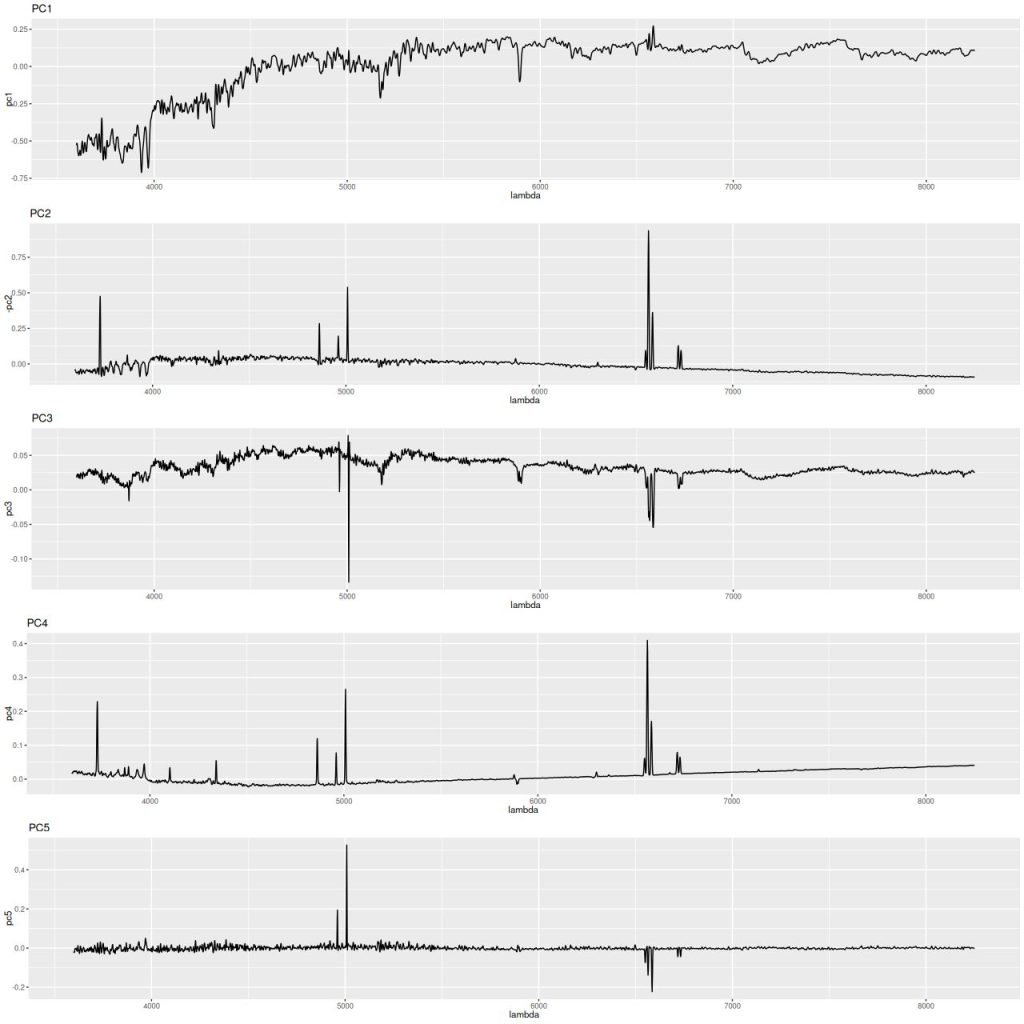
I’ll first discuss the stellar and gas kinematics, since calculating redshift offsets is the first thing I do after loading data and binning to a target S/N. I use a straightforward template matching procedure using as templates a set of 15 eigenspectra that I computed some years ago using an algorithm published by Blanton and Roweis (2007) and a fairly large sample of SDSS galaxy spectra. The first 5 are shown below. The first two look like real spectra of a passively evolving ETG and a star forming galaxy respectively. The rest represent departures from these archetypes. I did not mask emission lines, so both absorption and emission lines are present, often with the opposite of expected signs.
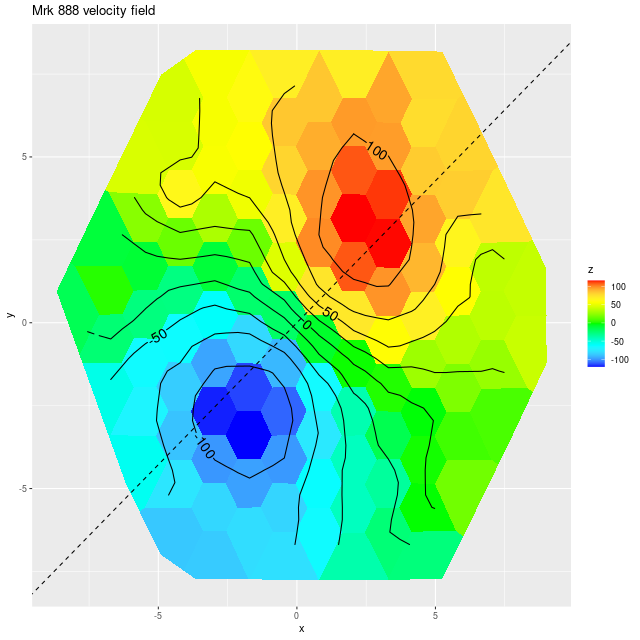
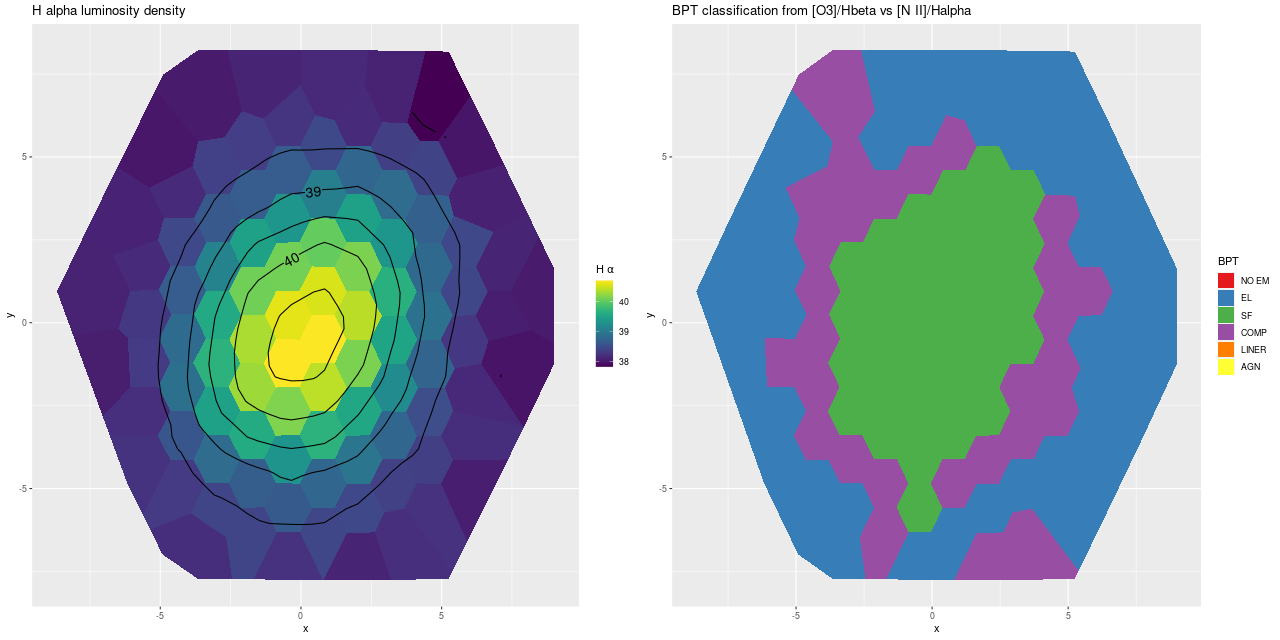
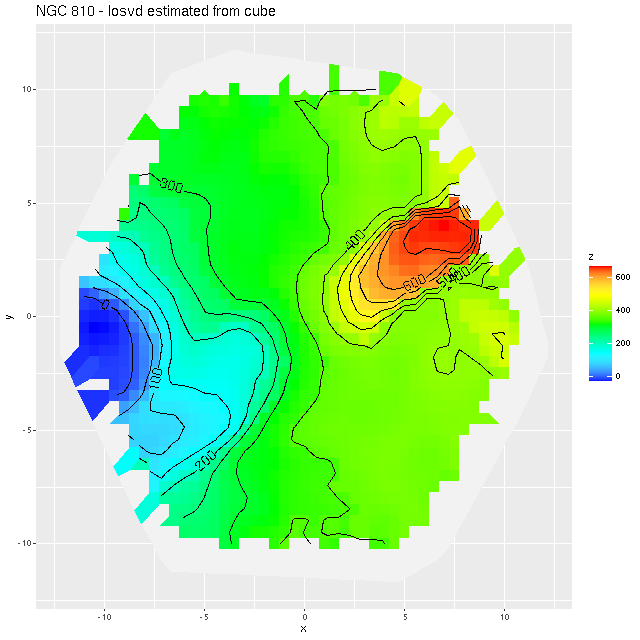
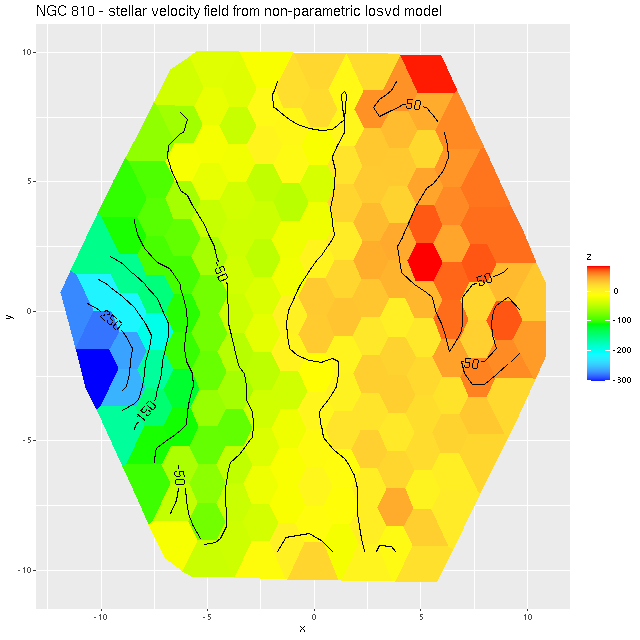
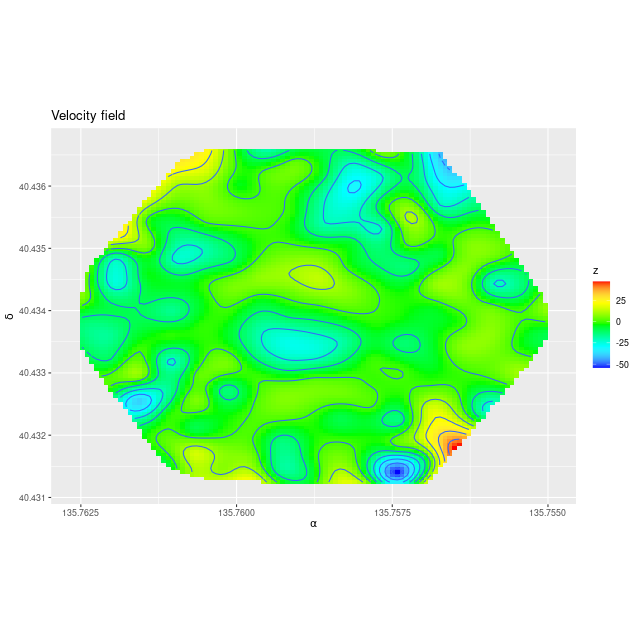
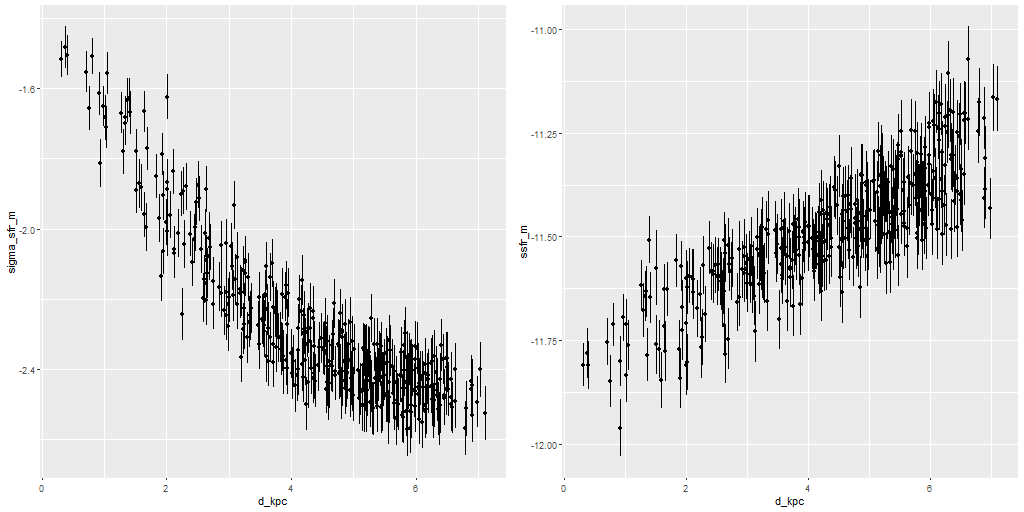
Here is the computed velocity field (converted from redshift offsets from the published system redshift of z=0.01818). As I’ve said before and is obviously the case from the plot above the template fitting procedure gives a blended velocity estimate that in any given spectrum might be dominated by emission, absorption, or a combination. In this case it turns out that emission lines dominate in the IFU center, with the outer parts dominated by stellar motion.
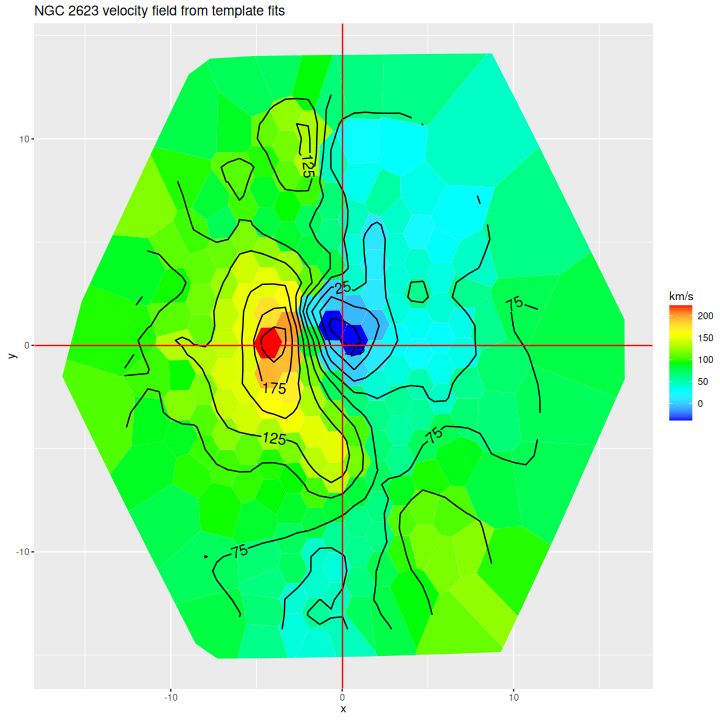
velocity field from template fit
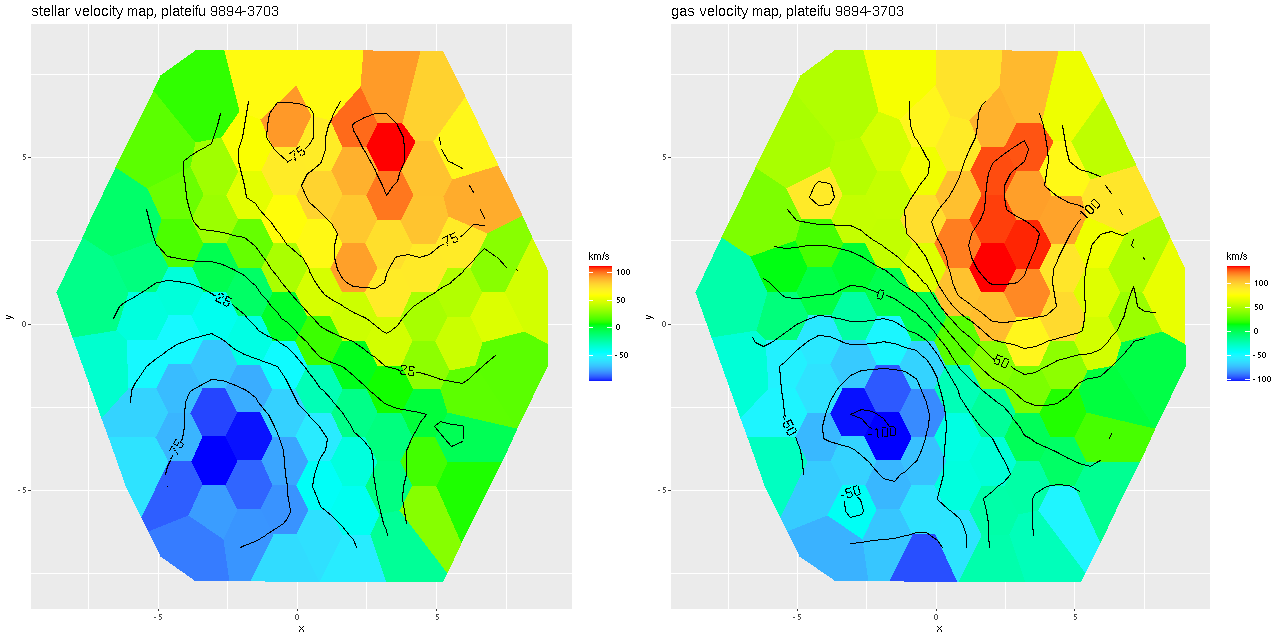
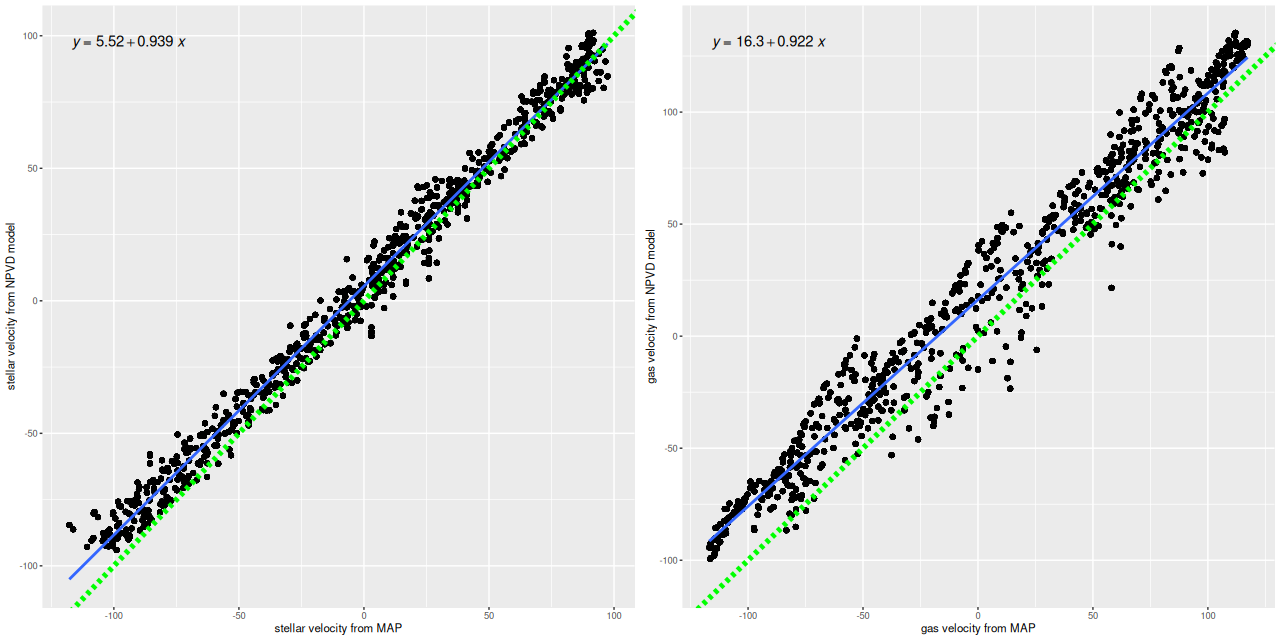
I often check Marvin to compare MaNGA data analysis pipeline measurements to mine. Sometimes visual comparisons are hampered by unfortunate choices of color palettes by the Marvin team. That’s especially the case for velocities where they use shades of red, white, and blue to represent positive, ~ 0, and negative velocities. It was apparent though that the stars and gas are kinematically decoupled at least in the center.
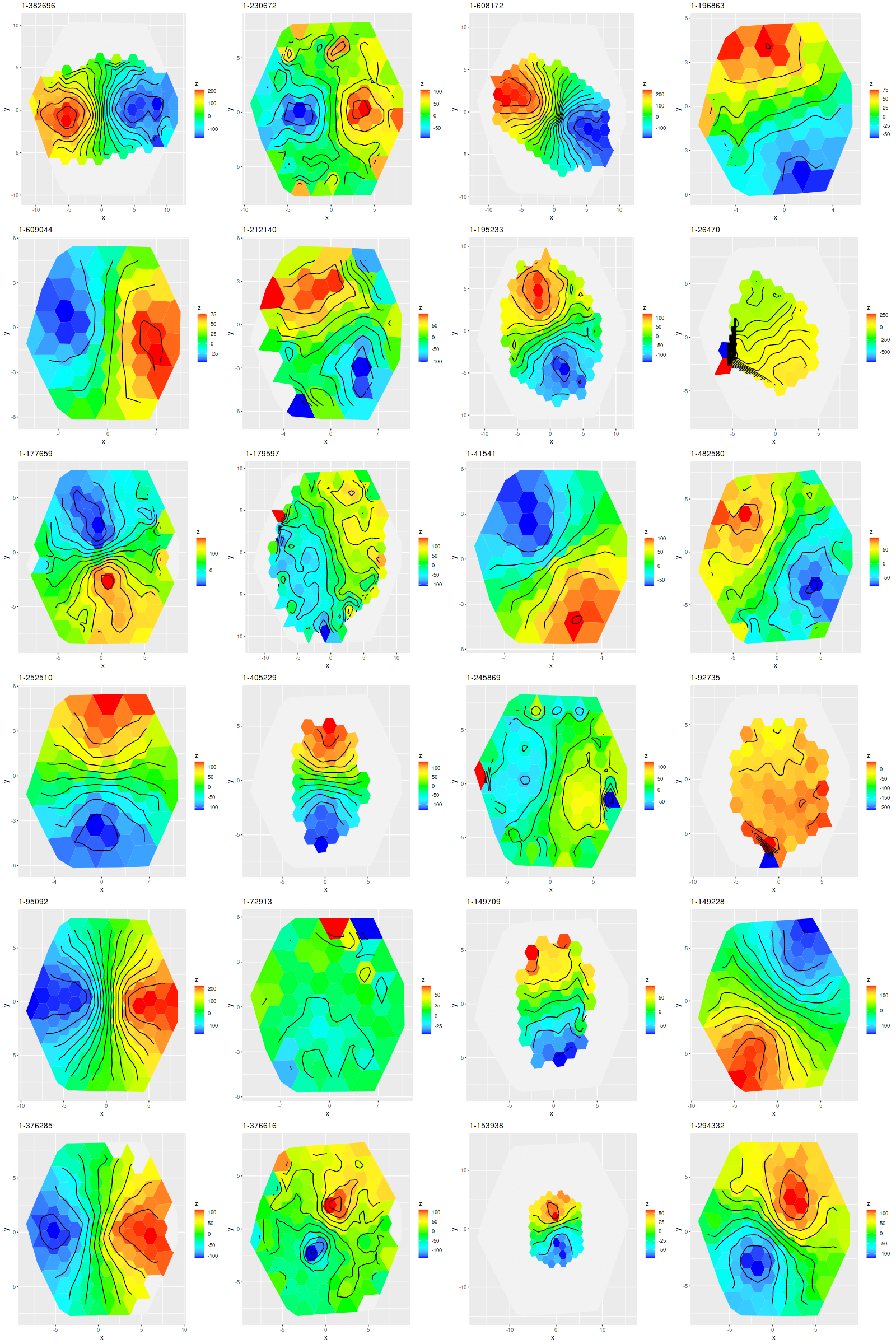
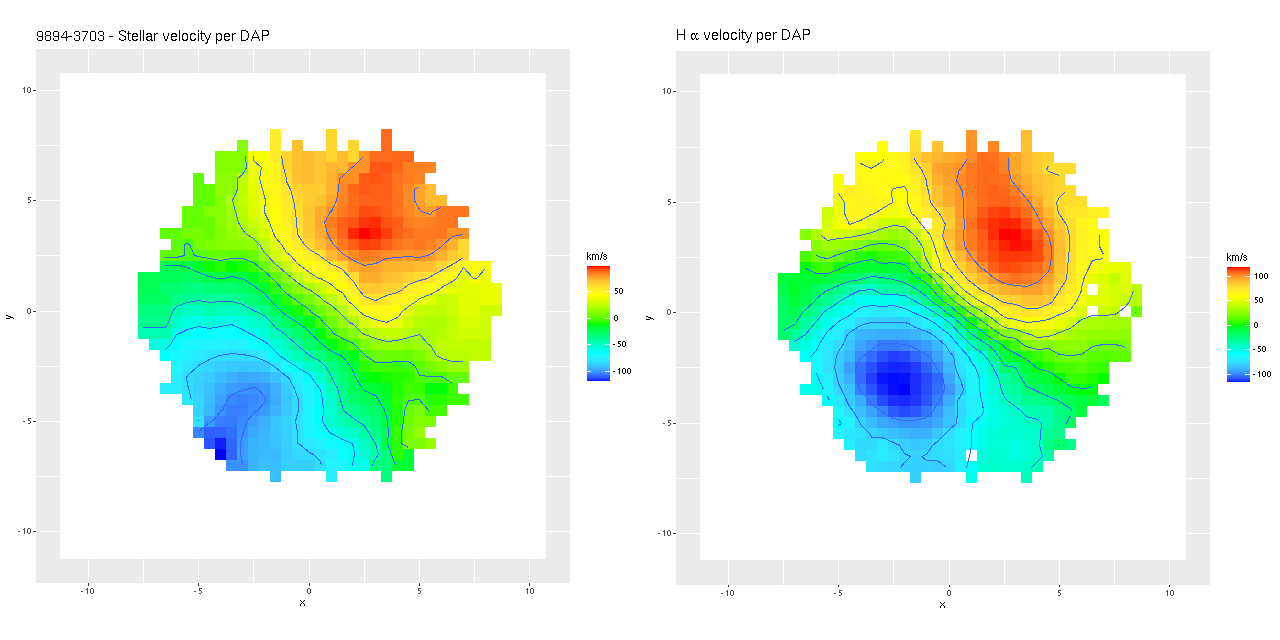
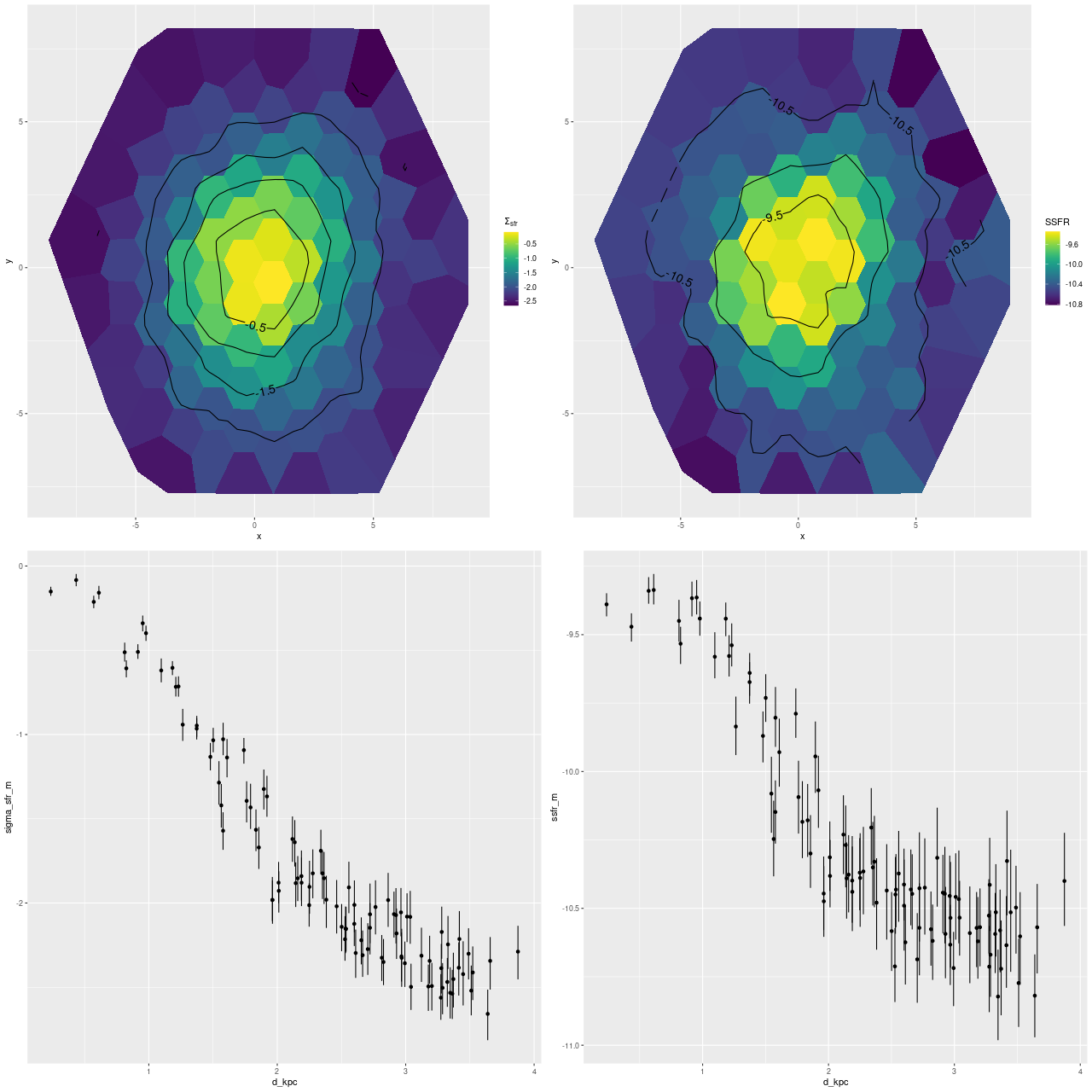
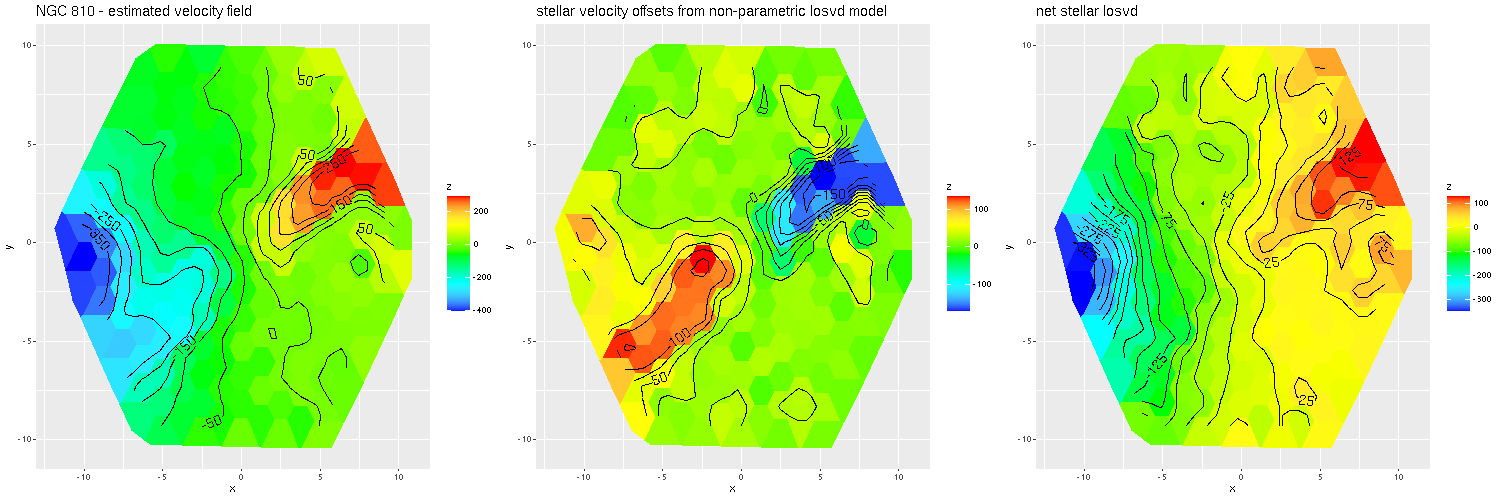
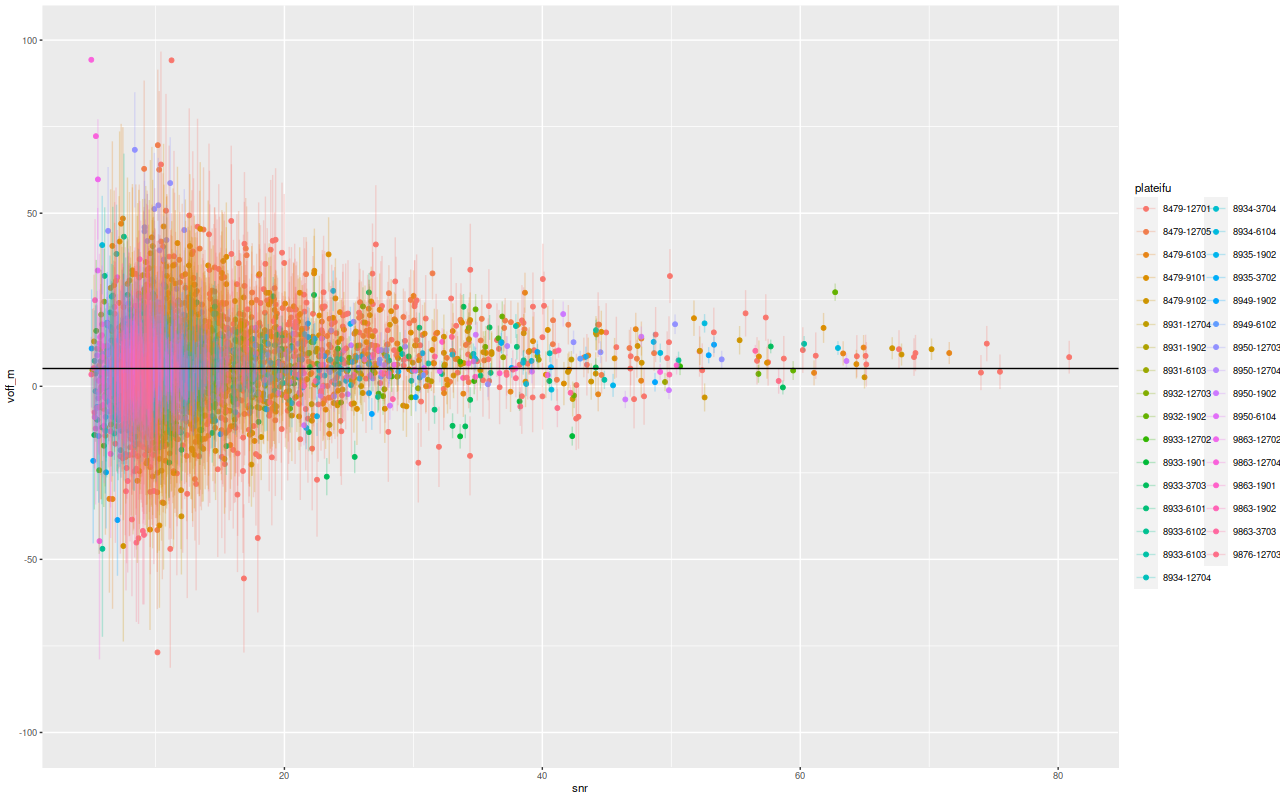
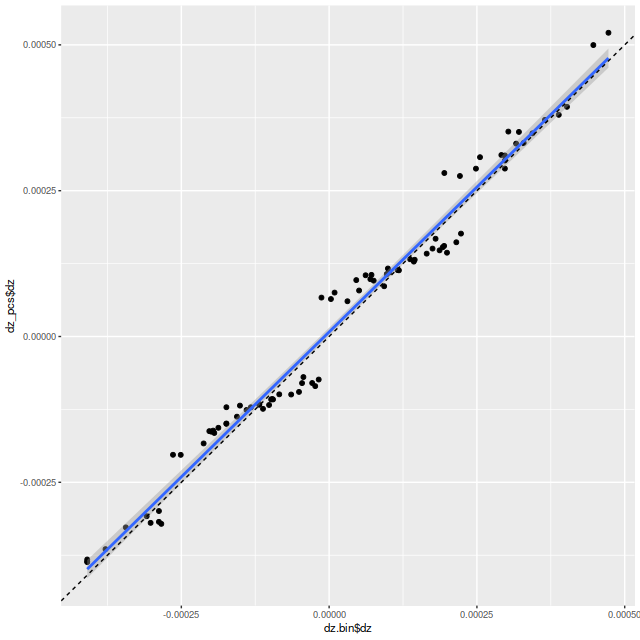
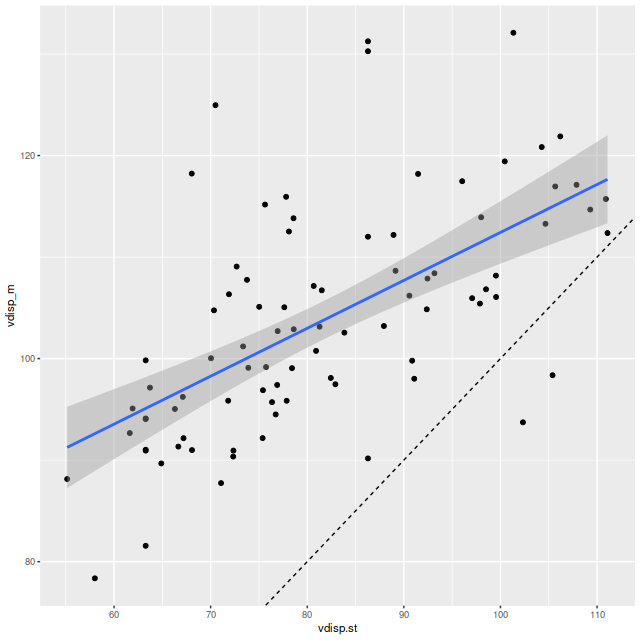
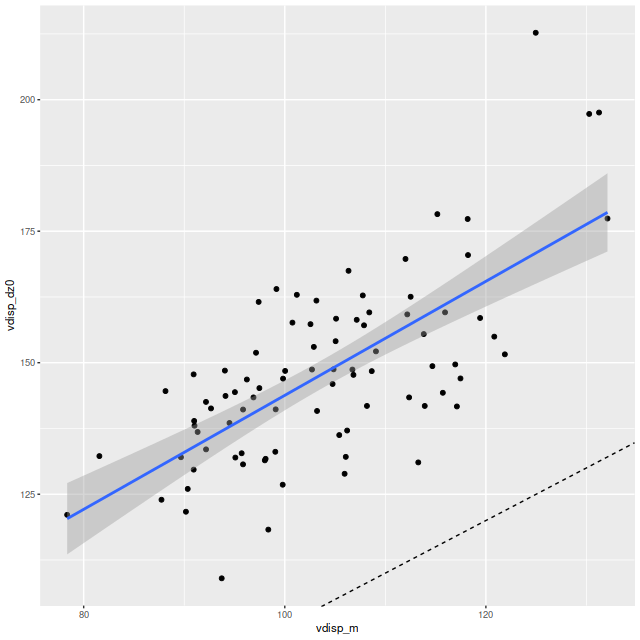
To investigate further I decided to dust off my old code for non-parametric line of sight velocity distribution modeling1which I last wrote about here and several previous posts., made some small modifications, and ran on the same 214 binned spectra. The results for the mean velocity offsets from the system redshift are shown below for stars (L) and gas (R). For easier comparison to Marvin I interpolated the model outputs to 0.5″ x 0.5″ pixels.
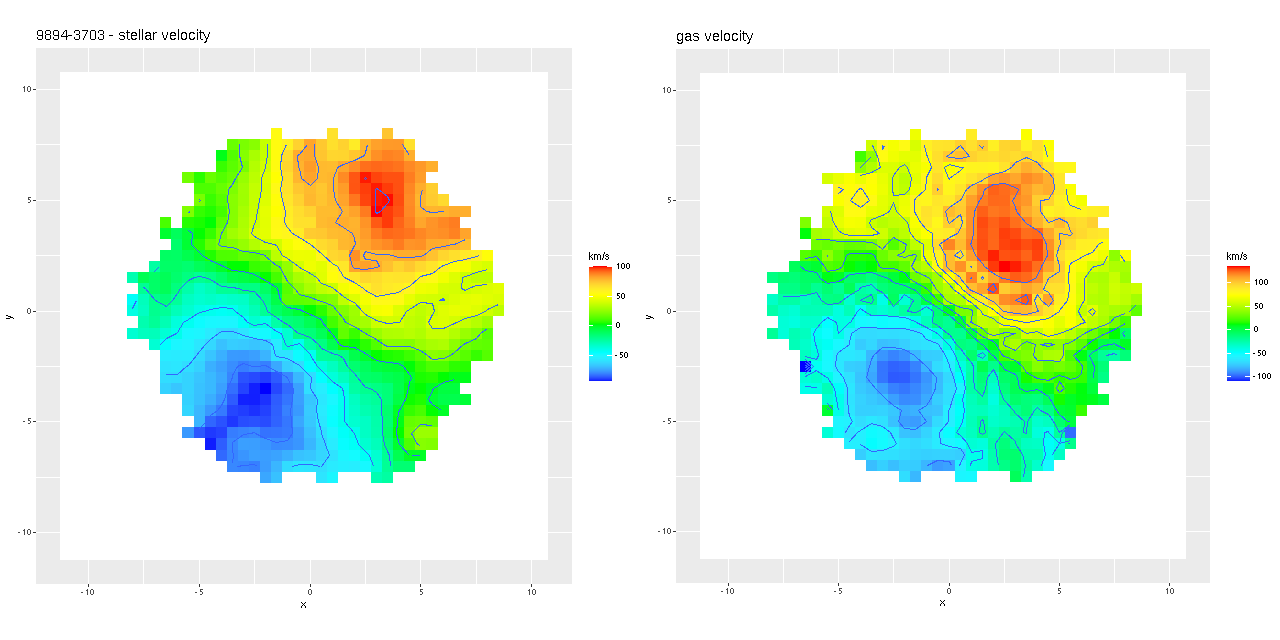
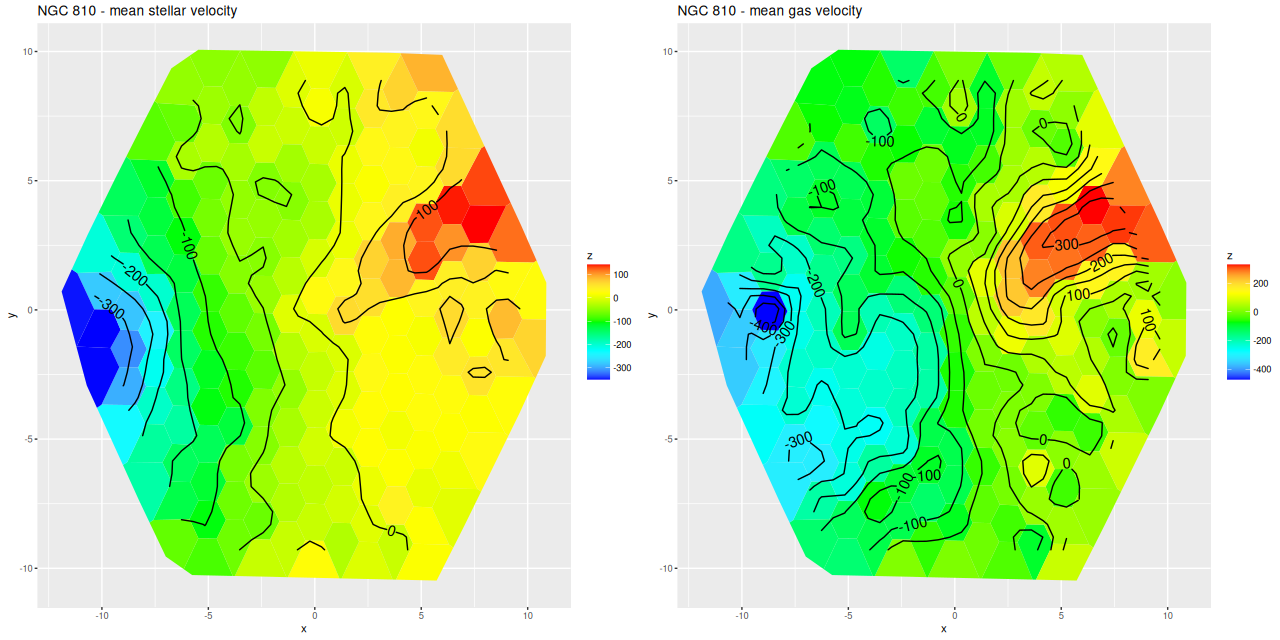
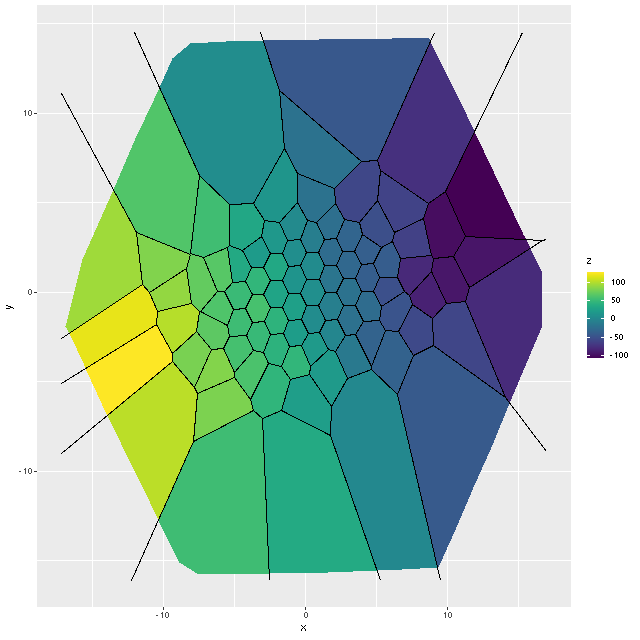
Even though people who claim to know generally disapprove of the use of rainbows in graphics I like to use them for velocity maps. In this case though using a more perceptually uniform palette (viridis with 256 levels) reveals some interesting details that aren’t as evident with a rainbow palette.
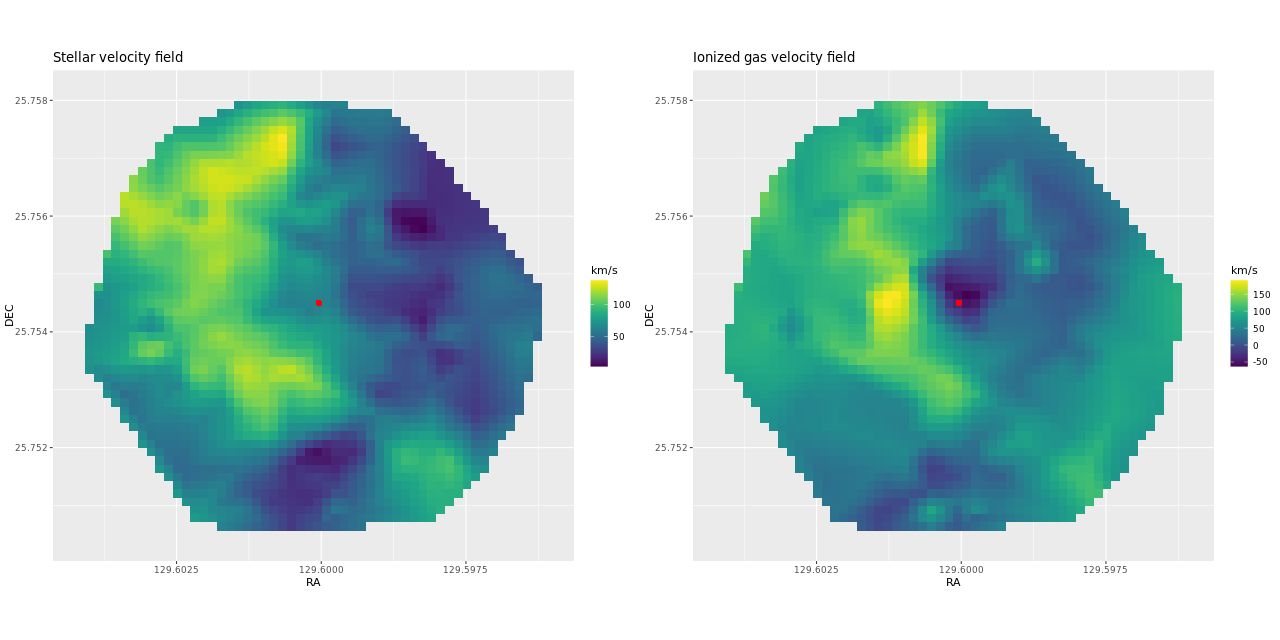
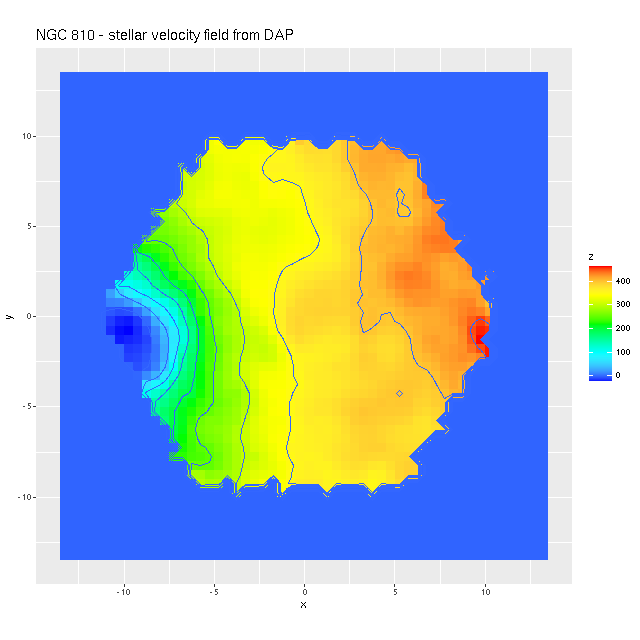
I also downloaded the maps from Skyserver that are displayed in Marvin. Below are the stellar and Hα velocity plots2[N II] 6584 might have been a better choice since it’s brighter than Hα over most of the galaxy.. I haven’t tried a detailed quantitative comparison because it’s not easy to properly register the maps, but it’s evident that these are very similar.
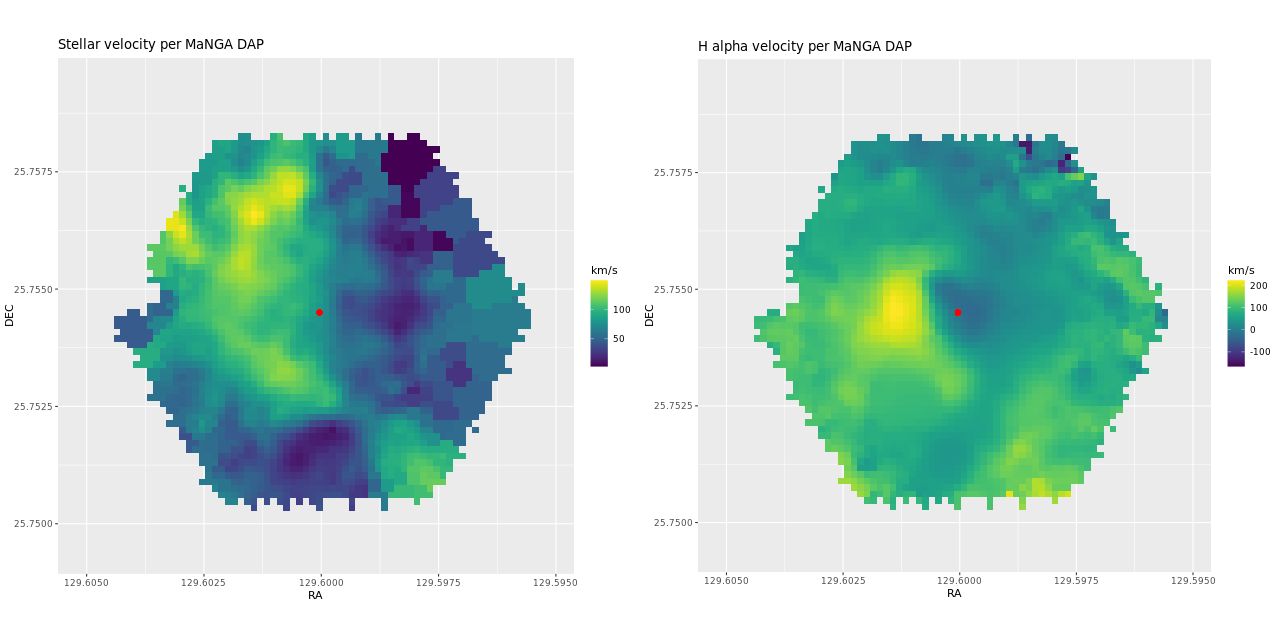
The velocity maps have several interesting features. First, the ionized gas is rapidly rotating within the inner ~2 kpc, but there’s no apparent organized rotation farther out. Zooming in on the center the rotation axis appears to be offset to the east of the IFU center (marked), which is exactly at the position of the nucleus, by ≈ 1.6″ (800 pc) if the unlabelled 75 km/sec contour line is taken as the axis of rotation. In a very thorough analysis of IFU data that preceded MaNGA by more than a decade Lipari et al. (2004) also noted a displacement of the kinematic center of 1.1″ to the east of the nucleus — in good agreement with my estimate given the limited resolution of MaNGA data. There also appears to be good qualitative agreement on gas velocities in the area with overlapping observations, which is roughly the zoomed in region below (see their figure 8a). NGC 2623 was also observed in the CALIFA survey, and its kinematics are discussed in Barrera-Ballesteros et al. (2015). Their velocity fields appear broadly similar, but visual comparison is hampered by the small size of their figures.
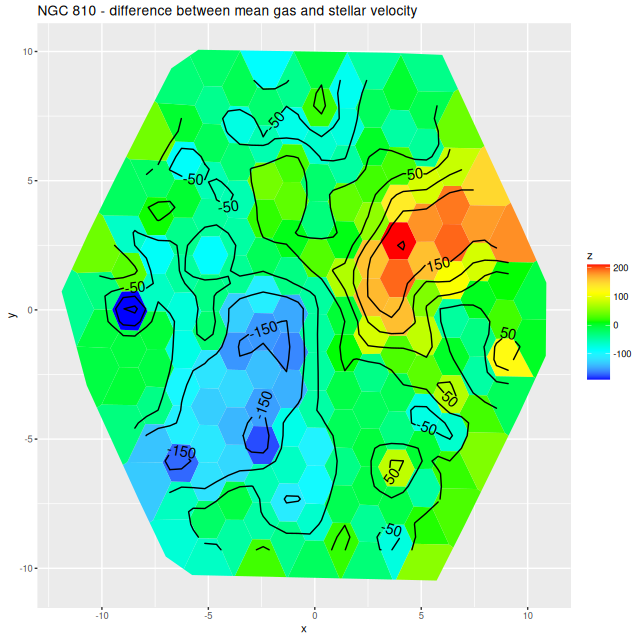
Outside the nuclear region gas and stellar velocities are more nearly equal although with some scatter that may simply be due to measurement errors.
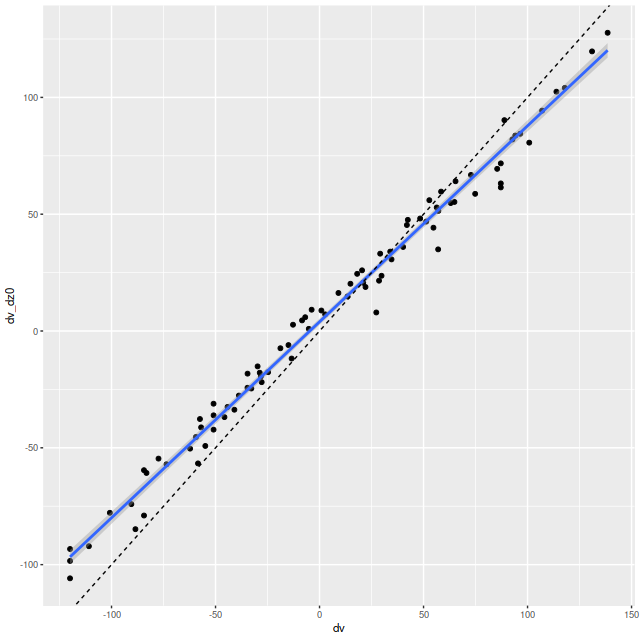
A minor point that’s maybe worth noting is the overall mean velocity in both the stellar and gas measurements is ≈70 km/sec, which suggests the system redshift of z = 0.01818 adopted by MaNGA is low by ≈2×10-4, or z = 0.01842 (cz = 5522 km/sec). This is close to the fiducial heliocentric redshift of 0.01851 adopted by NED and well within the range of values listed there.
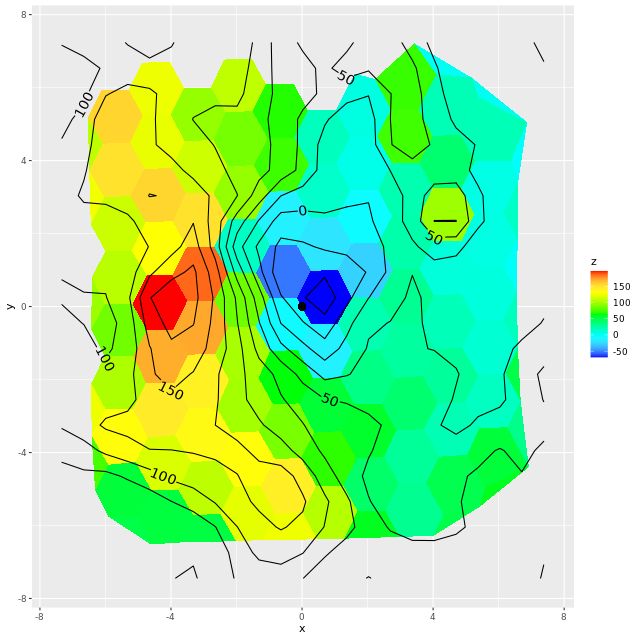
Two features I find really interesting that are especially prominent in the stellar velocity map are a pair of long, irregular, but mostly connected arcs that stretch across the full width of the IFU. One arc is relatively redshifted, exiting (entering?) the IFU at the position of the small portion of the SW tidal tail that’s within the footprint, appears to cross the other arc, then stretches to the south and east of the nuclear region, terminating to the north approximately where the northern tidal tail enters the IFU footprint. The other, relatively blue shifted arc starts in the south in the area of the blue, wedge shaped region (which I will discuss much more later), curves around to the west of the nuclear region, and appears to terminate somewhere in the NW region of the IFU.
To date there is only one N-body simulation of the NGC 2623 merger, by Privon et al. (2013). In their model the blue wedge in the south is material from the progenitor that formed the northern tidal tail, has passed through the main body and is now falling back in. In their simulations there are regions even in the main body of the merger remnant where the progenitors aren’t well mixed. I’m wondering if these apparently connected regions with systematic velocity offsets might reflect that lack of complete mixing, with the blue shifted regions falling into the galaxy from behind and the redshifted falling from above.
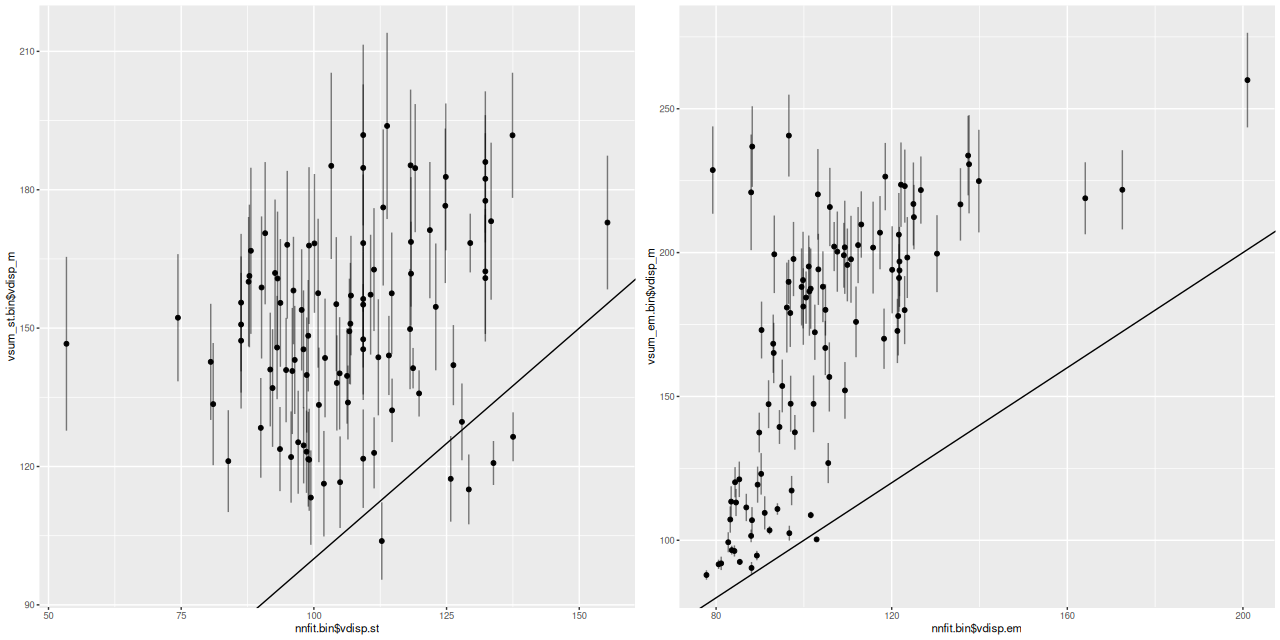
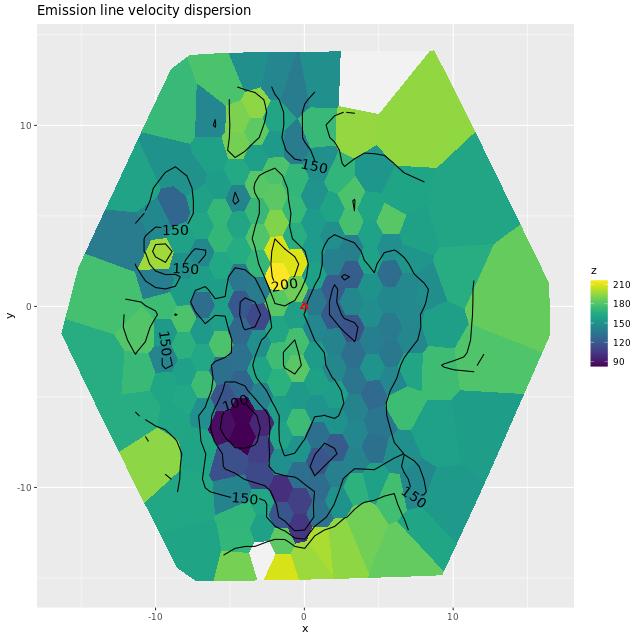
One final plot for now: the average emission line velocity dispersion. These are “raw” values uncorrected for spectral resolution. The relatively high values to the NE of the nucleus might be associated with the outflow discovered by Lipari et al. The low values well south of the nucleus are from H II regions.
This post turned out longer and took longer to write than I expected, so I will break it up into two or perhaps more. Next time I’ll look at some other physical properties and perhaps model star formation histories.
Update
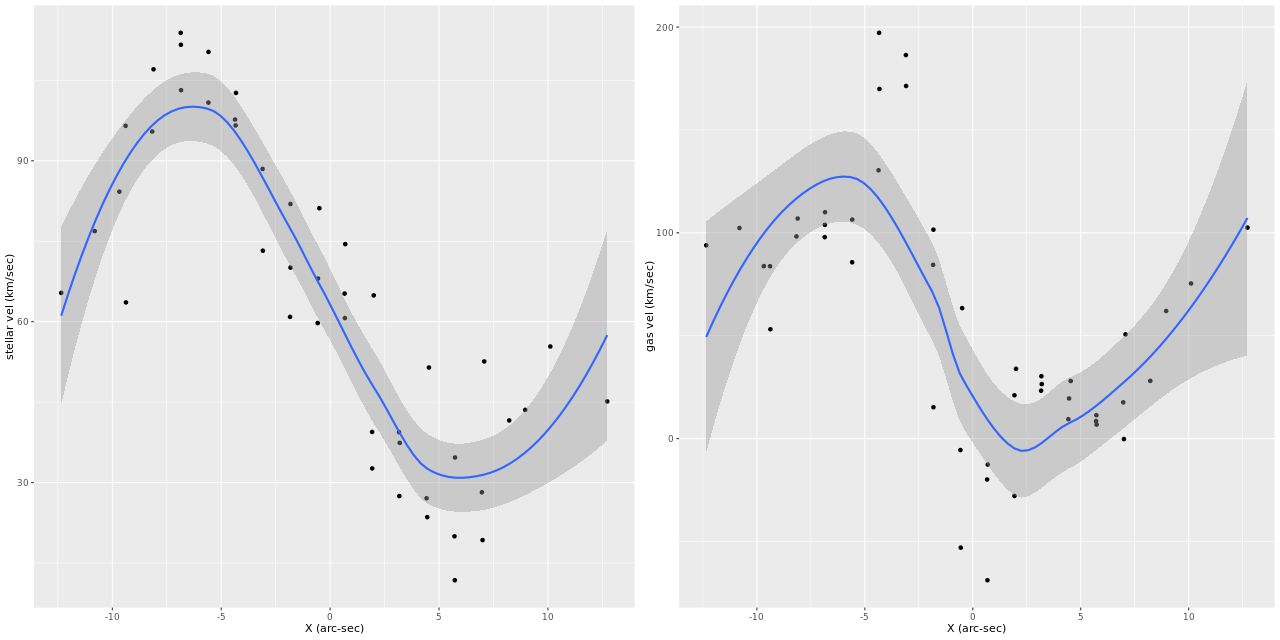
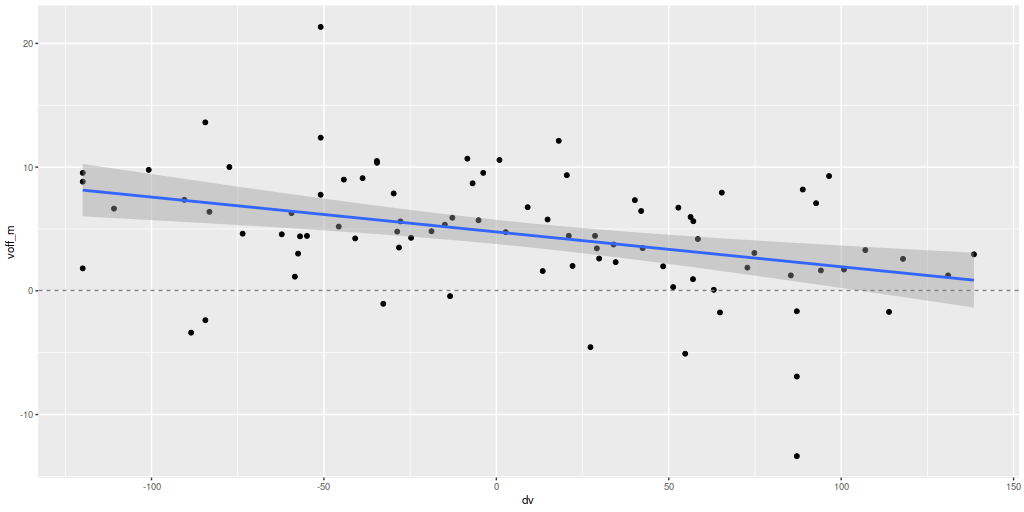
Barrera-Ballesteros found regular stellar rotation out to the maximum radius of 6″ (2.2 kpc) that they had usable data. Both they and Lipari found a sinusoidal rotation curve for the ionized gas. I was skeptical of the claimed large scale stellar rotation since visual inspection of the velocity maps didn’t show an obvious velocity gradient in any direction. But, I decided to take a closer look anyway. Since the kinematic position angle for both is close enough to 90o I just plotted velocities for bins within ±2″ of the horizontal axis. The results are plotted separately for stars (L) and gas (R). The curved lines with “confidence bands” are loess fits to the plotted data and should absolutely not be taken seriously as a model of the rotation curves. It’s notable though that if’s fairly symmetrical for the stellar velocities and if the true system velocity is 70 km/sec larger than adopted by MaNGA its kinematic center is right at the IFU center. The ionized gas kinematic center is clearly seen as offset to the east, as noted above.