The final release of SDSS MaNGA went public back in early December as promised, and I’ve spent the last month or so of my hobby time looking for manageable sized samples of interesting galaxies. One sample I looked at out of curiosity was the Zoogems target list, which is an HST gap filler imaging program with about 300 galaxies selected (mostly) by Galaxy Zoo volunteers. It turns out there are 11 targets with MaNGA data, of which 5 have been observed by HST so far.

As can be seen from the thumbnails above this is a pretty diverse lot, with several in progress mergers and merger remnants, some normal looking spirals at least two of which were from Masters’ red spirals sample, and 3 of Schawinski’s blue early type galaxies. Only one of those 3 has HST imaging so far (number 8 in the thumbnails above), although there are a surprising 24 blue ellipticals in the final MaNGA release out of 215 in Schawinski’s original sample.
Of the 5 Zoogems galaxies that have been observed so far the one that caught my eye as deserving an early look was number 3 in the top row, NGC 810, an apparent elliptical with an unusual dust lane that’s almost perfectly aligned with the minor axis. There are also hints of shells indicating a likely merger sometime in the past.

The MaNGA data, which is new in DR17, only covers the central part of the galaxy with the companion just photobombing the edge. A larger IFU would have been nice for this observation, but the data quality is better than average in terms of nominal signal to noise. I was able to use all 183 fiber/position combinations in the RSS file without binning.

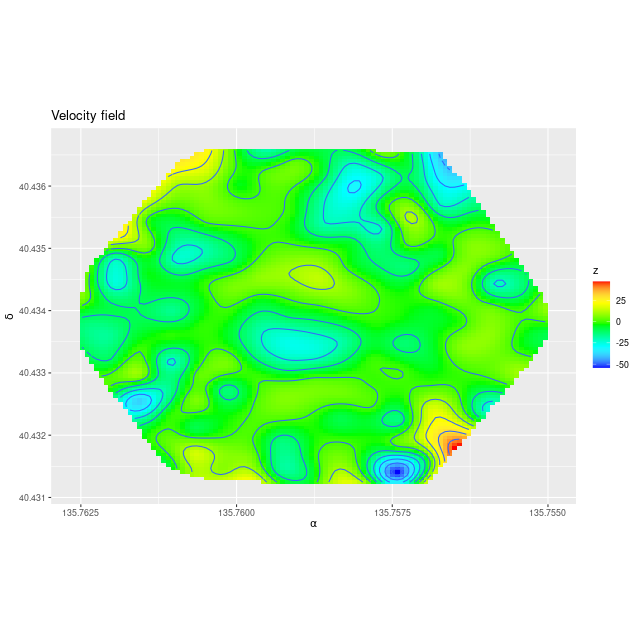
The first step in the analysis process after loading the data is to estimate redshift offsets from the system redshift for each spectrum, and from that it’s straightforward to calculate a velocity field, which in this galaxy looks like1this is actually from the data cube:
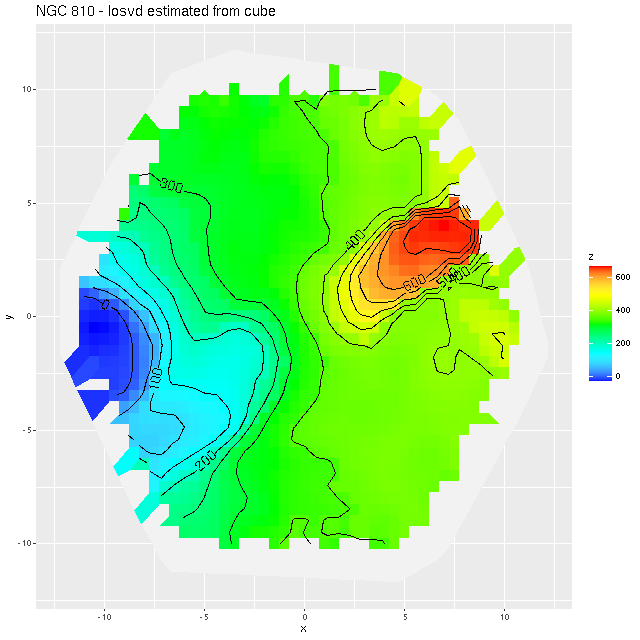
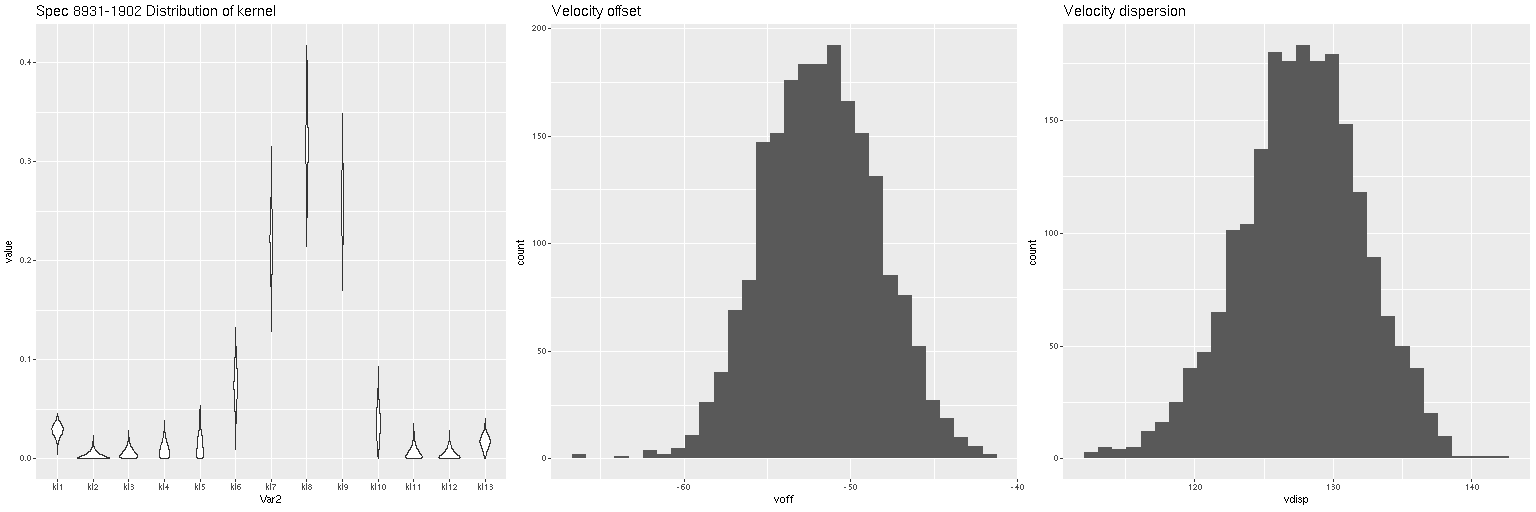
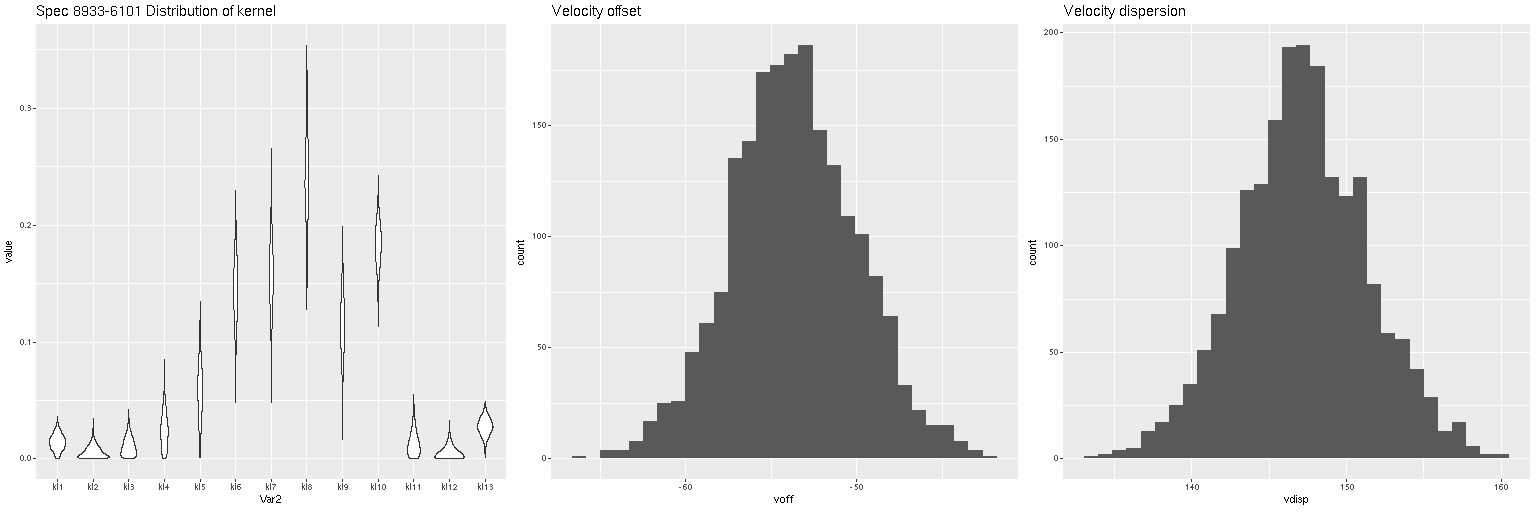
It turns out the redshift assigned to this system was that of the companion galaxy, which was the only SDSS spectroscopic target in the immediate vicinity and is evidently blueshifted by ~350 km/sec from the target. What’s more interesting though2interesting enough that I made a couple posts on the Galaxy Zoo talk forum, which I rarely do anymore. is the apparent rapidly rotating disk that’s aligned with and somewhat thicker than the dust lane. There may also be overall prolate rotation outside the disk although the presence of the companion makes it hard to tell based solely on visual inspection. In hopes of separating out multiple velocity components I returned to the non-parametric line of sight velocity distribution models that I wrote some posts about last year. Unlike the ones I practiced on previously this galaxy has non-negligible amounts of emission, at least in the central region, so I just temporarily masked the regions around the emission lines that I fit. That results in a pure stellar velocity distribution. The results were a bit surprising:
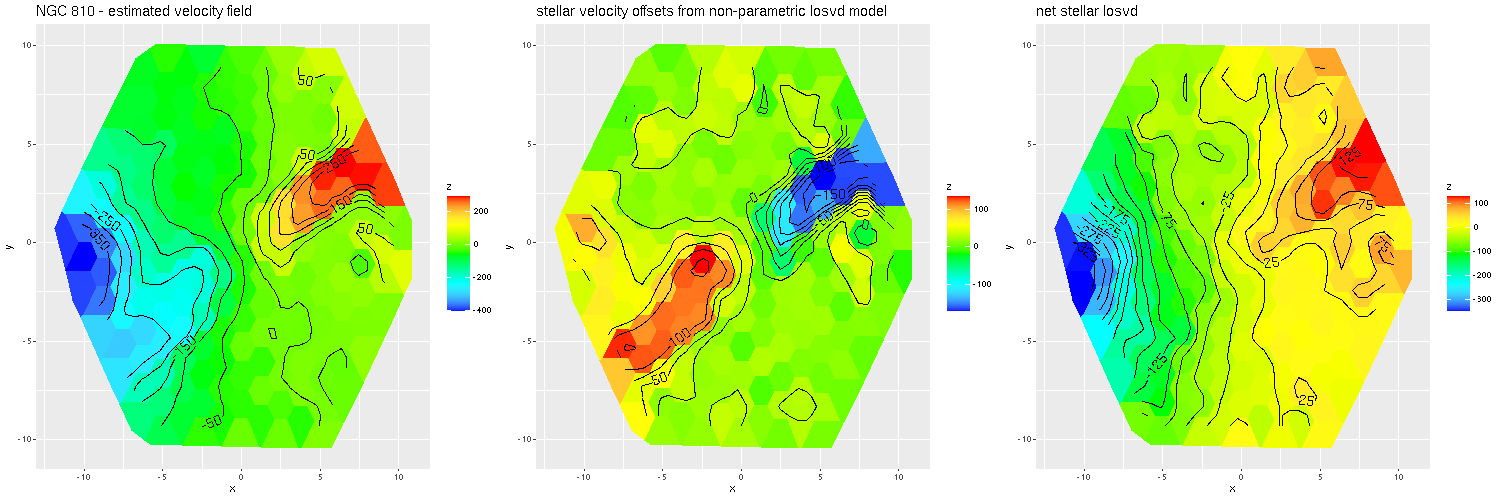
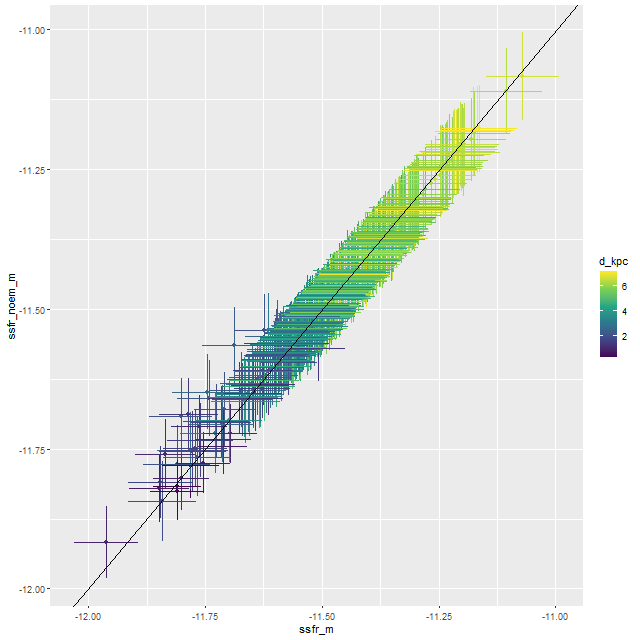
In the left pane above is the velocity field from the RSS data, with the system redshift adjusted to the IFU center. For the LOSVD models I set the adopted redshift of each spectrum to the system redshift plus the offset calculated previously. Now I had hoped to be able to cleanly separate the contribution of the companion from that of the main galaxy, which so far I haven’t been able to do. But what I did find that was unexpected is that the average stellar velocities in the disk partially offset the original measurements (middle pane), so the net stellar velocity field shows a much more slowly rotating stellar disk.
As I’ve written before I use a set of 15 eigenspectra from a principal components analysis of some tens of thousands of SDSS spectra that I performed some years ago for redshift offset estimation. Those galaxies were of all types and include systems both with and without significant emission. The redshift estimation routine just does straightforward template matching and returns a single value for the best fitting offset. Since the templates encode information about both emission and absorption lines that estimate could be most applicable to the ionized gas, stars, or some combination. In this case it’s possible emission lines were driving the original fits, implying the gas and stars in the disk are kinematically decoupled. I have not verified that though.
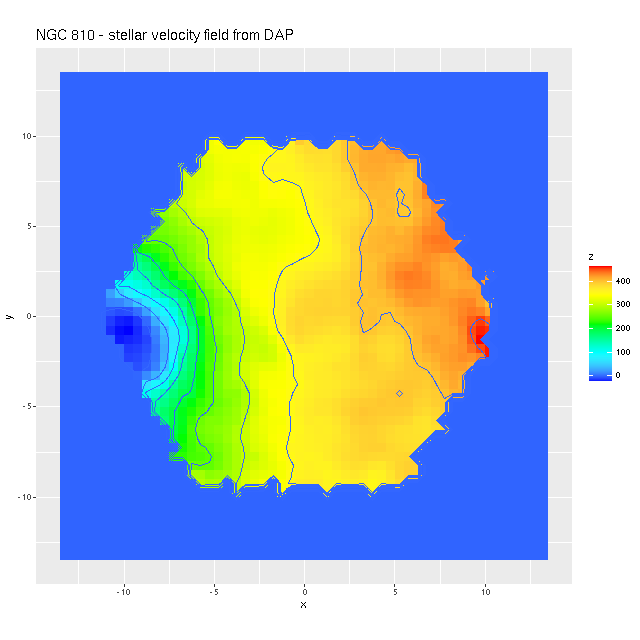
Another issue I noticed is that the stellar velocity field from the official MaNGA Data Analysis Pipeline looks rather different from mine, with barely a hint of a kinematically distinct disk. This wasn’t really evident in the Marvin webpage, which makes some really unfortunate choices for color palettes. So here is the same data rendered with a more nearly perceptually uniform rainbow palette3I know data visualization experts frown on rainbows, but I think they’re OK for things like velocities or redshifts:
I decided to re-run my LOSVD modeling code on the RSS data, this time setting the redshift offset to 0 for each fiber, so this is now measuring velocities relative to the overall system velocity. I also used a larger convolution kernel (25 vs. 21 in the first set of runs). The map of the average velocity offsets is:
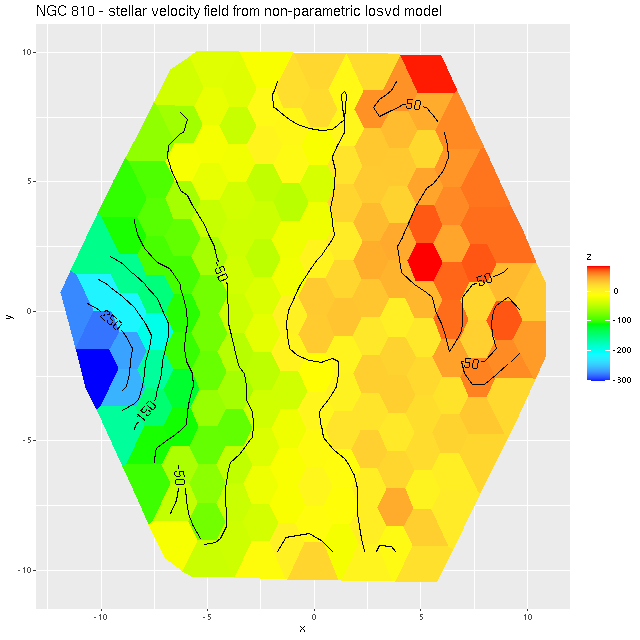
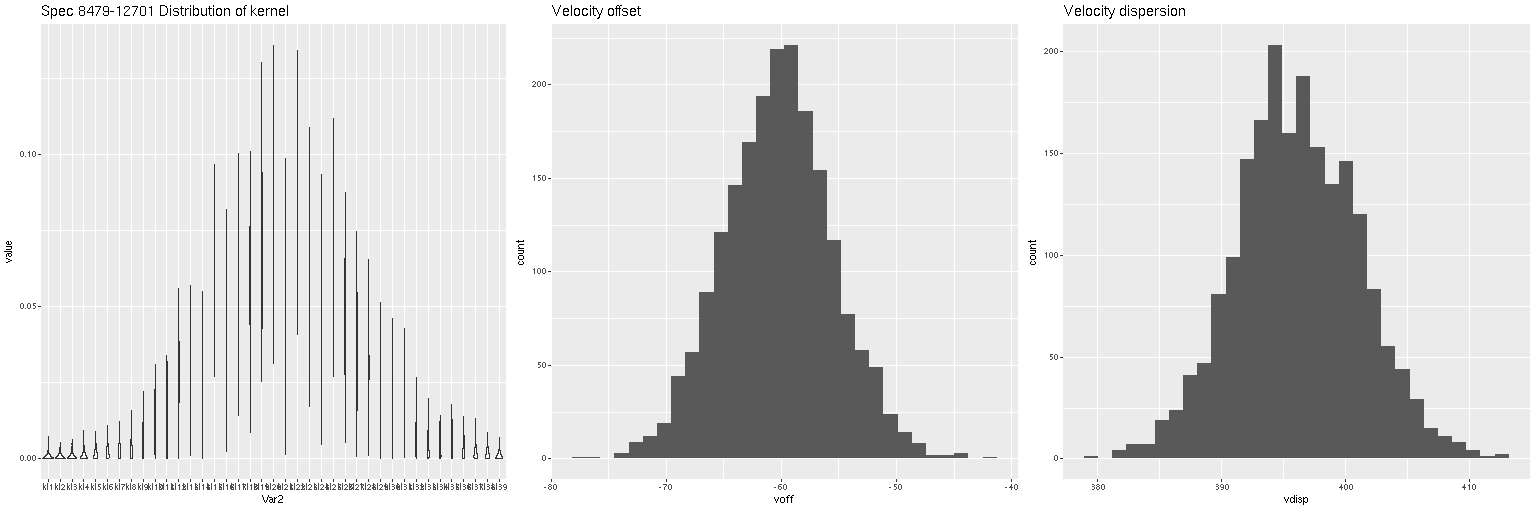
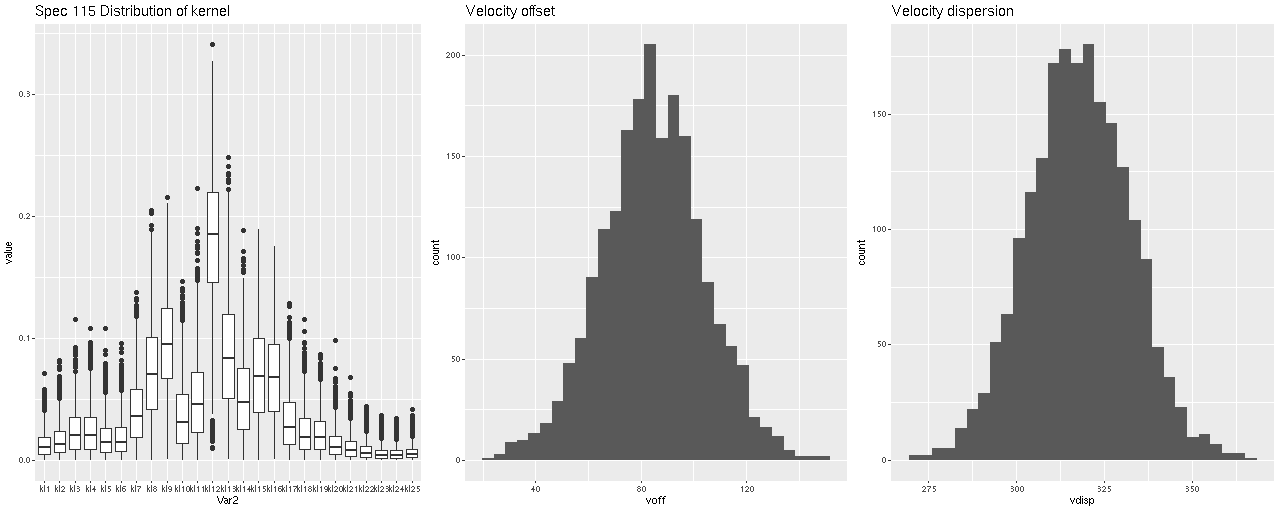
Although not a perfect match this is somewhat closer to the DAP map. I suspect what’s happening here is that there really are at least two, and more likely 3 distinct kinematic components. I haven’t read the DAP release paper in a while and don’t know exactly how they estimate stellar velocities, but in any case their model just returns a single value for visualization purposes. To see the (possible) complexity of the actual data here are the results for a single fiber with the largest positive velocity offset in the map above. Again, I don’t know how much of the structure in the posterior distribution of the convolution kernel is real, but it’s evident there’s more complexity than is captured in the first two moments shown in the middle and right panes.
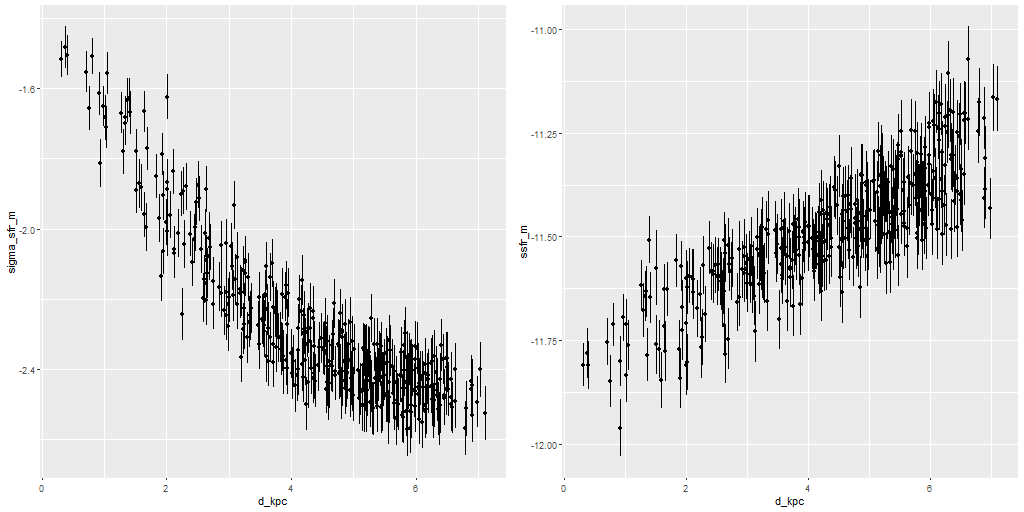
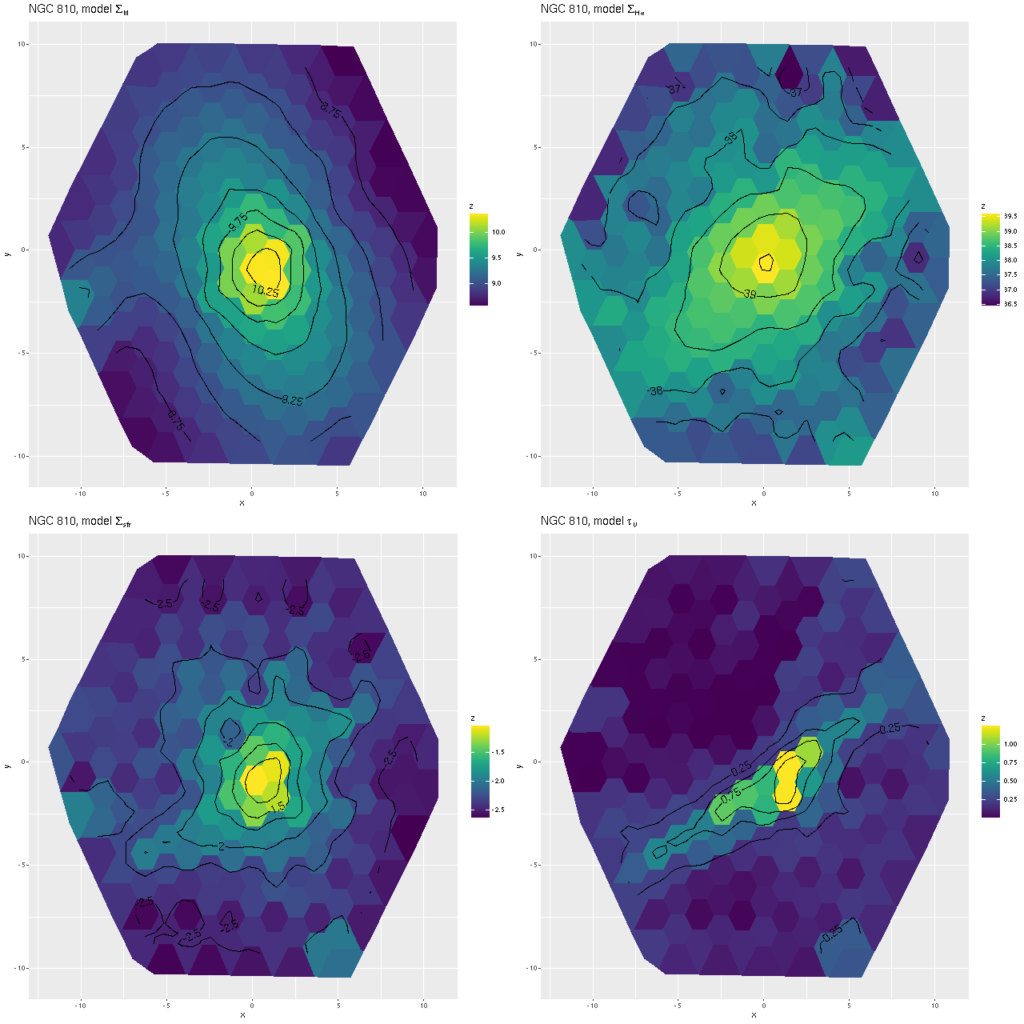
Besides the kinematic modeling I did run star formation history models on the full RSS data set using the same tools as in recent posts. I’m not going to discuss them in detail, but some summary maps are worth showing. In the graphic below these are, from top left, stellar mass density, Hα luminosity density uncorrected for attenuation, SFR density (as usual 100Myr average), and stellar dust attenuation.
There’s no sign of a disk in the stellar mass map, which faithfully follows the distribution of light. A disk is visible in Hα and the small amount of recent starformation is also confined to a disk and nuclear region. In the fourth pane I show the modeled stellar dust attenuation, mostly just to demonstrate that this component of the model does capture something of reality.
Getting back briefly to the first paragraph, there are 8 post-starburst galaxies from the catalog of Melnick and de Propris and 24 from an ancillary program to observe post-starburst galaxies from various sources that was added for DR17. There’s just one galaxy from the former catalog in the latter set, so that makes 31 total, an easily manageable number. There are also 24 of Schawinski’s blue ellipticals. Of course there are many disk galaxies, far too many for me to look at.
Continue reading “NGC 810 – interesting kinematics in a Zoogems and MaNGA target”