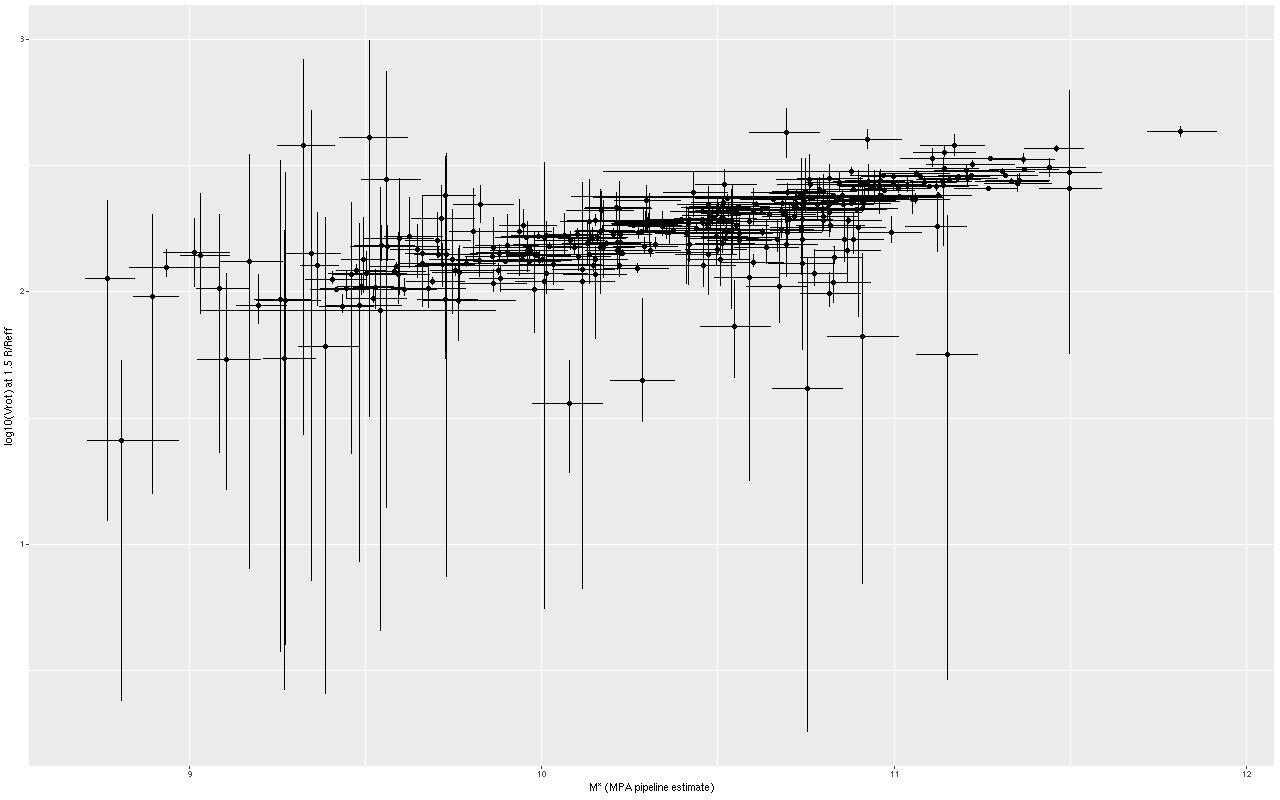
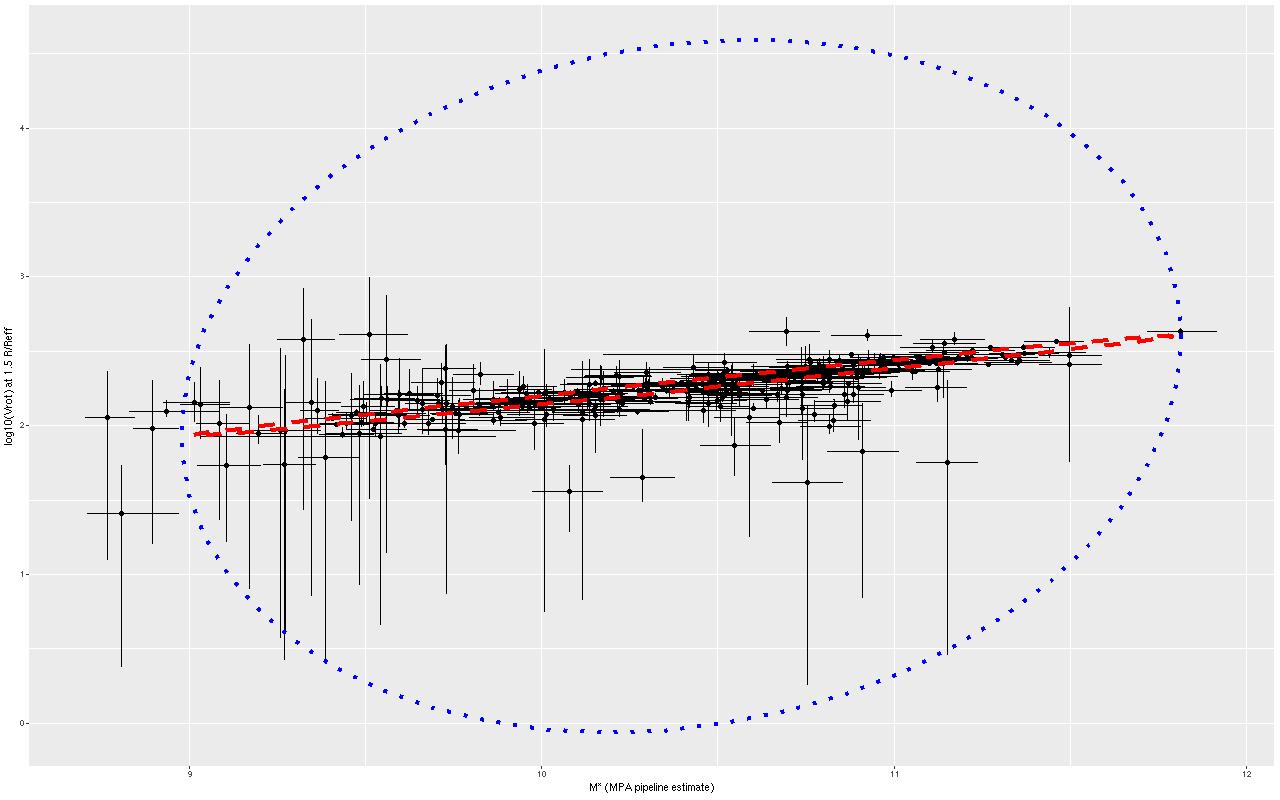
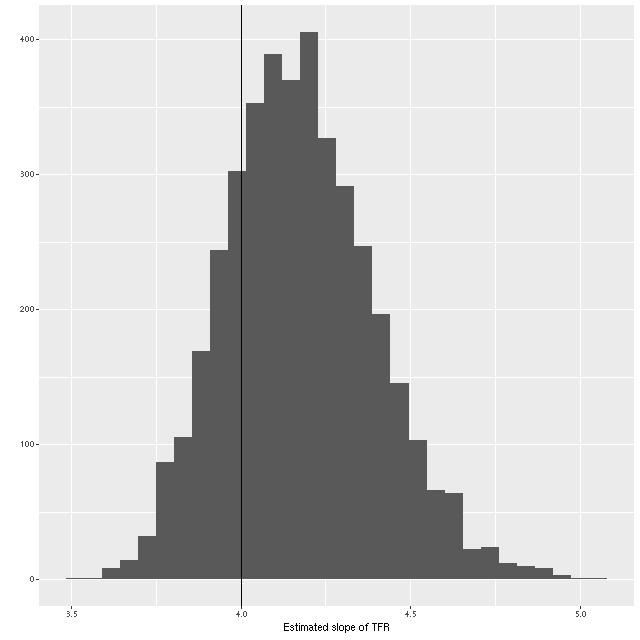
I haven’t had a lot of time for this hobby lately and won’t for another month or so, but I haven’t been completely inactive. When I first started modeling disk galaxy rotation curves with Gaussian processes I used a low order polynomial for the mean function. This was an admitted hack, and not a very good one at that. It’s not uncommon in the rotation curve modeling industry to adopt a functional form for the circular velocity. Sometimes it’s physically motivated (usually based on a bulge/disk/dark matter halo model), sometimes it’s purely phenomenological. With a bit of digging in the literature I found a particularly simple form in Courteau (1997):
\(v(r) = v_{0} + \frac{2}{\pi} v_{c} \arctan(r/r_{t})\)
Making this the mean function for the GP model involves just a few simple changes to the Stan code I outlined in that post. We only need two parameters for the curve, and the parameter block now looks like:
parameters {
real phi;
real<lower=0., upper=1.> cos_i; // cosine disk inclination
real x_c; //kinematic centers
real y_c;
real v_sys; //system velocity offset (should be small)
real v_c;
real<lower=0> r_t;
real<lower=0.> sigma_los;
real<lower=0.> alpha;
real<lower=0.> rho;
}
The key line in the model block is:
v ~ multi_normal_cholesky(v_sys + sin_i * (2./pi() * v_c * atan(r/r_t) .* yhat ./ r), L_cov);
And then in the generated quantities block are posterior predictions for new data at the observed points and in concentric rings:
// model and residuals at the original points
v_rot = 2./pi() * v_c * atan(r/r_t);
vf_model = gp_pred_rng(xyhat, v-v_sys-sin_i * (v_rot .* yhat ./ r), xyhat, alpha, rho, sigma_los);
vf_model = vf_model + v_sys + sin_i * (v_rot .* yhat ./r);
vf_res = v - vf_model;
// model in rings
v_gp = gp_pred_rng(xy_pred, v-v_sys-sin_i * (v_rot .* yhat ./ r), xyhat, alpha, rho, sigma_los);
v_pred = (v_gp + sin_i * 2./pi() * v_c * atan(r_pred/r_t) .* y_pred ./ r_pred) *v_norm/sin_i;
vrot_pred[1] = 0.;
vexp_pred[1] = 0.;
The full code is available in my github repository at https://github.com/mlpeck/vrot_stanmodels.
This model turned out to have very nice sampling properties using Stan’s version of NUTS, and convergence is fast enough in terms of both number of iterations and walltime to make it easily feasible to model a large sample.
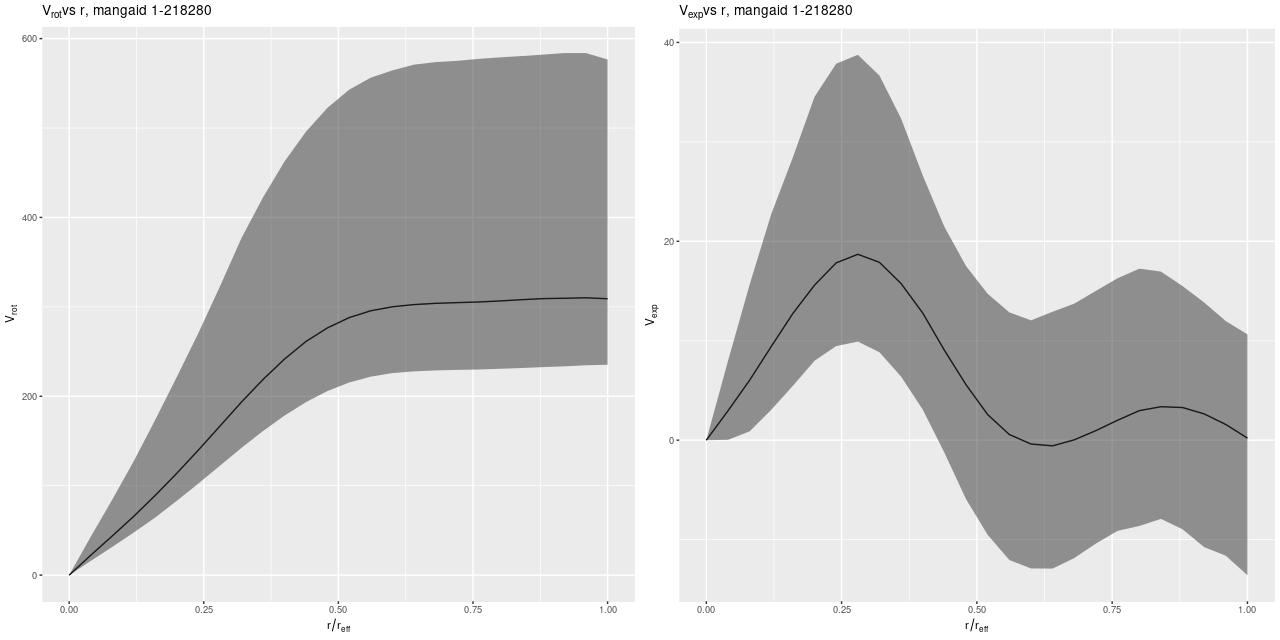
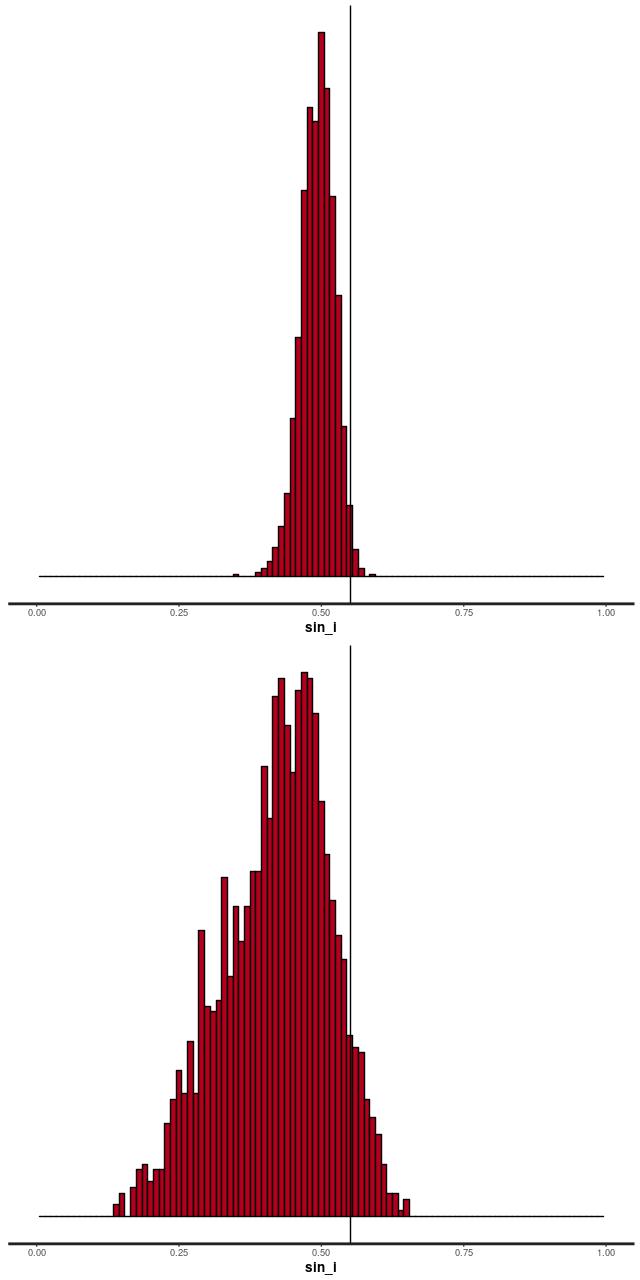
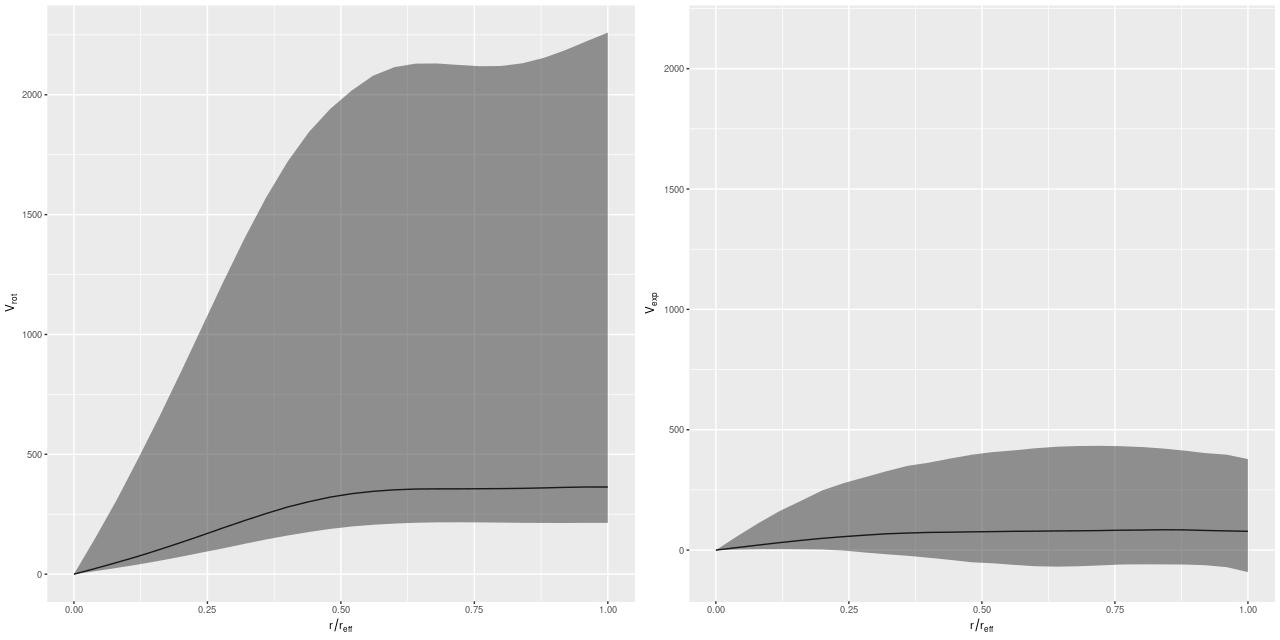
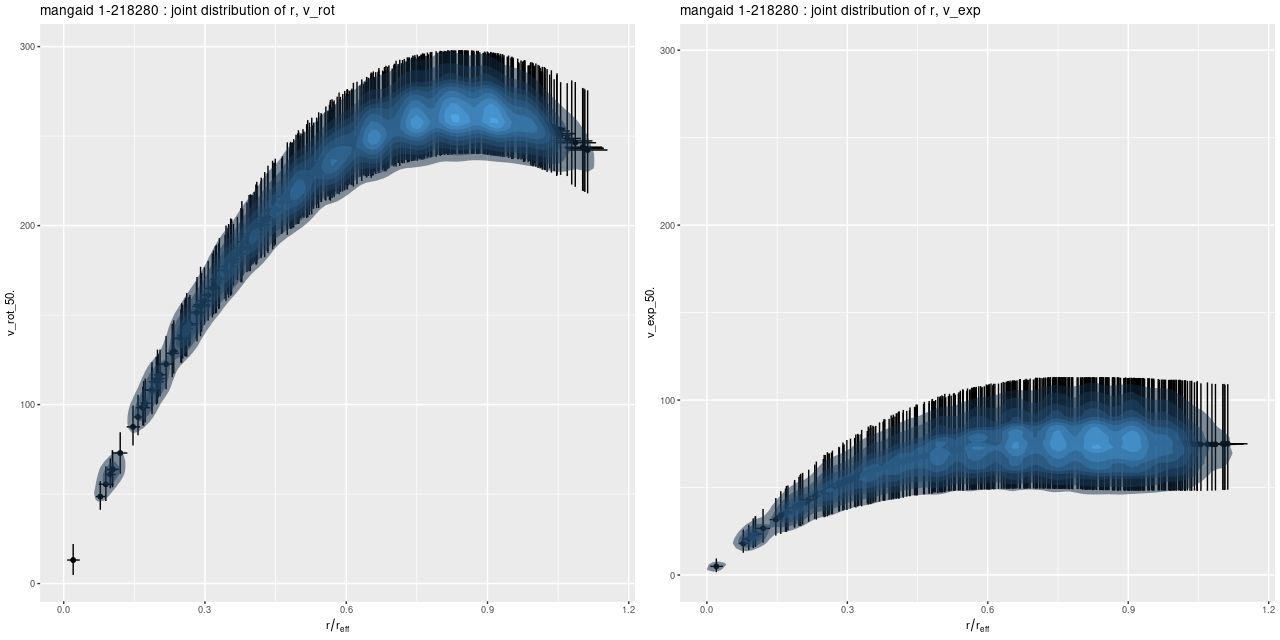
Since I’ve been using this as a running example here are posterior circular and expansion velocity estimates for plateifu 8942-12702 (mangaid 1-218280):
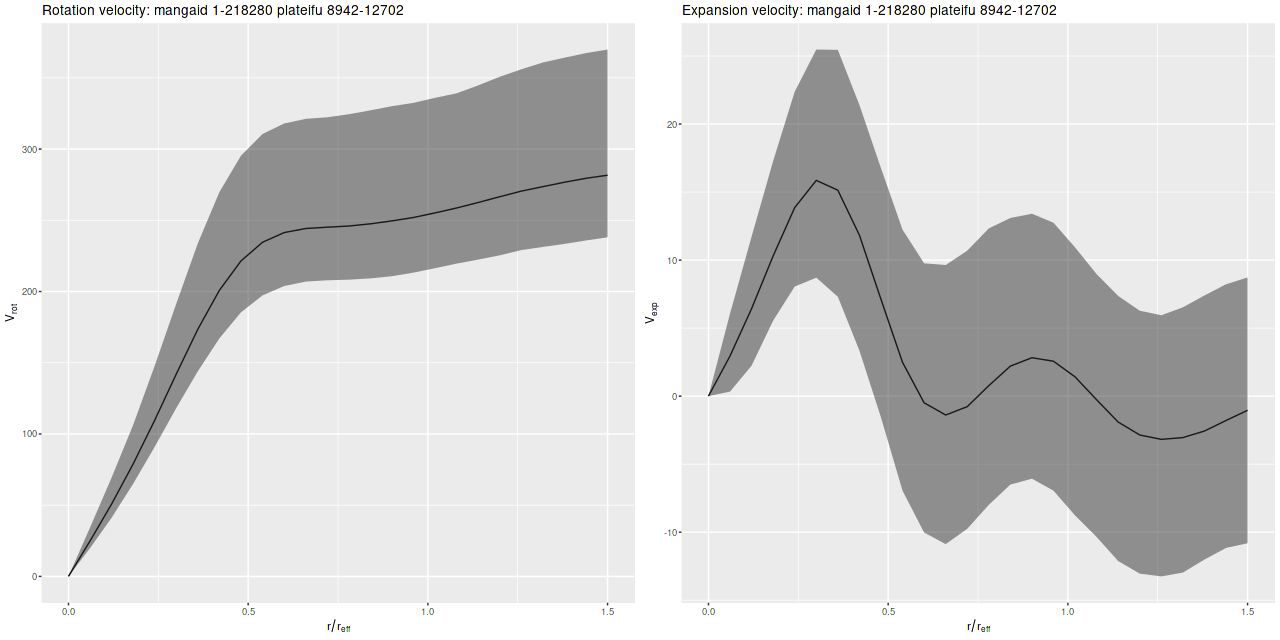
These curves are shaped just slightly differently from the ones I posted in July, but the confidence bounds are somewhat tighter. Whether this is actually due to better inference remains to be seen.
Second topic: SDSS Data release 15 went public in December as promised. I haven’t had time to dig into it much, but I did rerun the query I used to get a sample of high confidence disk galaxies based on GZ2 classifications. Run in the DR15 context that query got 588 hits, an increase of 229 from DR14 and still about 13% of the entire MaNGA galaxy sample excluding ancillary targets that aren’t also part of the main samples.
I downloaded the RSS files and have done a first pass at rotation curve modeling of the 229 new galaxies. Unfortunately I won’t have time to actually analyze what I have until, most likely, March. To conclude for now here is the kinematically most interesting example I saw from the new to DR15 sample. GZ2 classifiers called this a normal disk galaxy by a large majority
SDSS J114526.10+495244.5
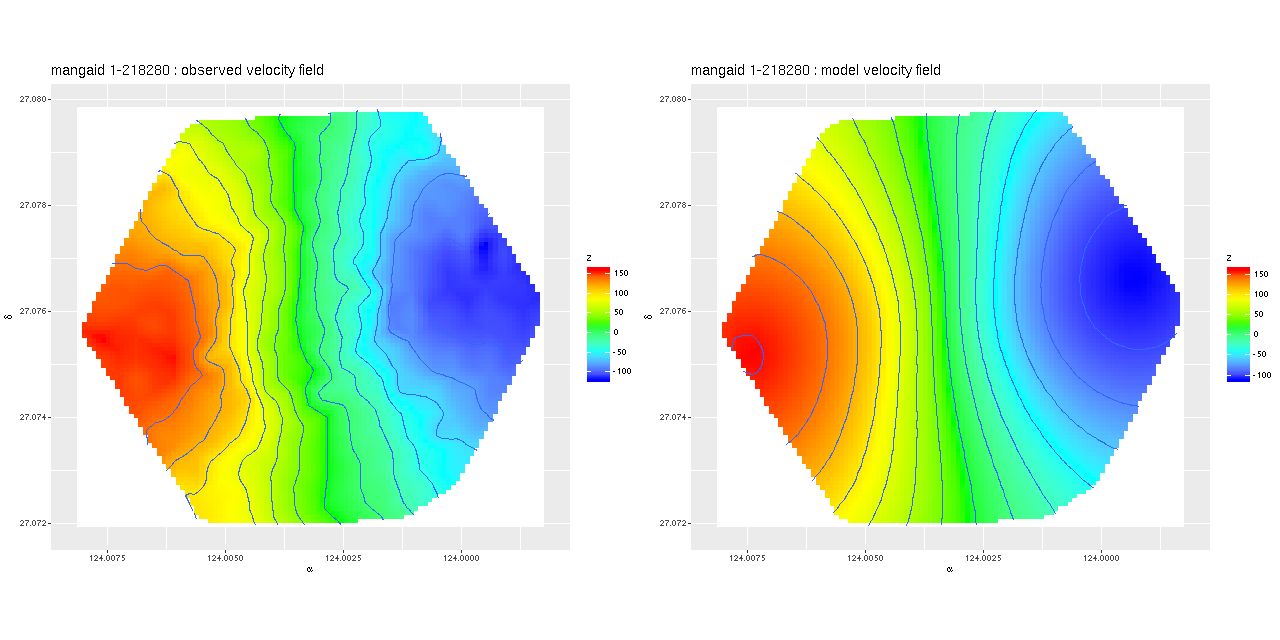
and were about evenly divided on whether it has a bar. And here is its velocity field measured from the stacked RSS file on the left, with the modeled velocity field on the right. The left graph is interpolated to the same resolution as the data cubes.
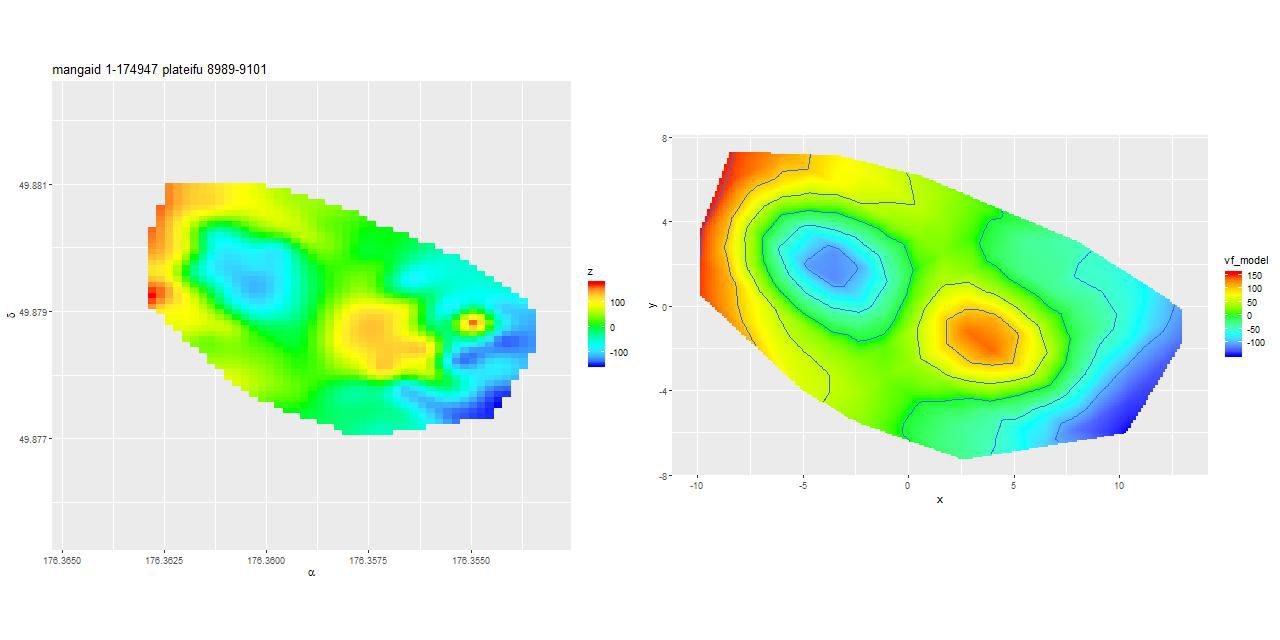
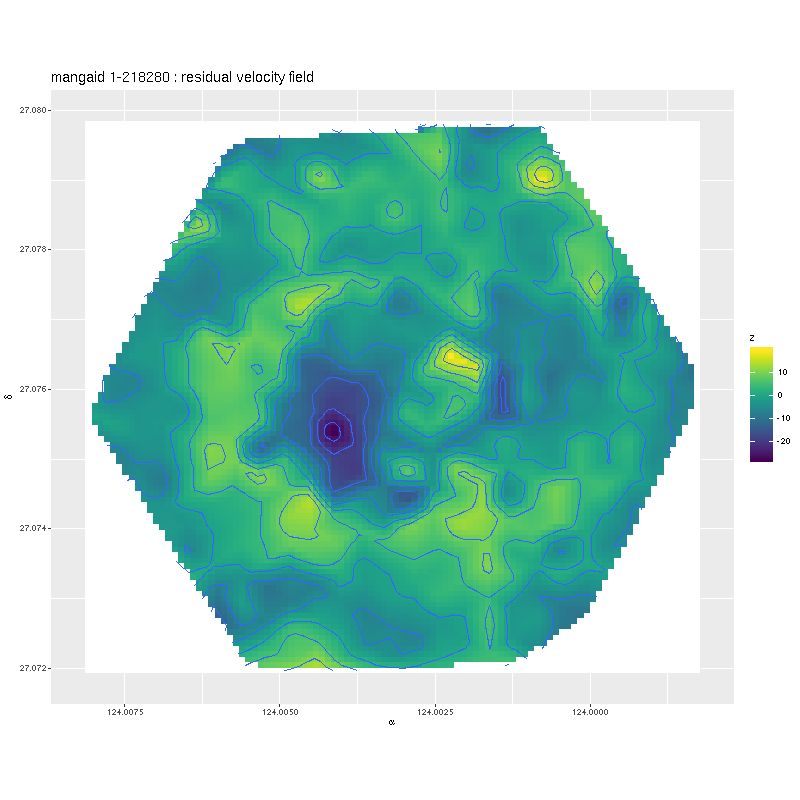
This is an incomplete map because of the signal/noise threshold I set, but it’s apparent that the outer disk is counter-rotating relative to the inner disk. This is confirmed for the stellar velocity field in the SDSS DAP, while the ionized gas rotates in the same sense as the outer disk throughout. Keep in mind that I measure blended velocities that in any given case could be dominated either by stellar light or ionized gas — in this galaxy the emission lines are very weak, so I measured the stellar velocity field. The GP based model does a good job of fitting the data, but the rotation curve isn’t exactly the standard shape:
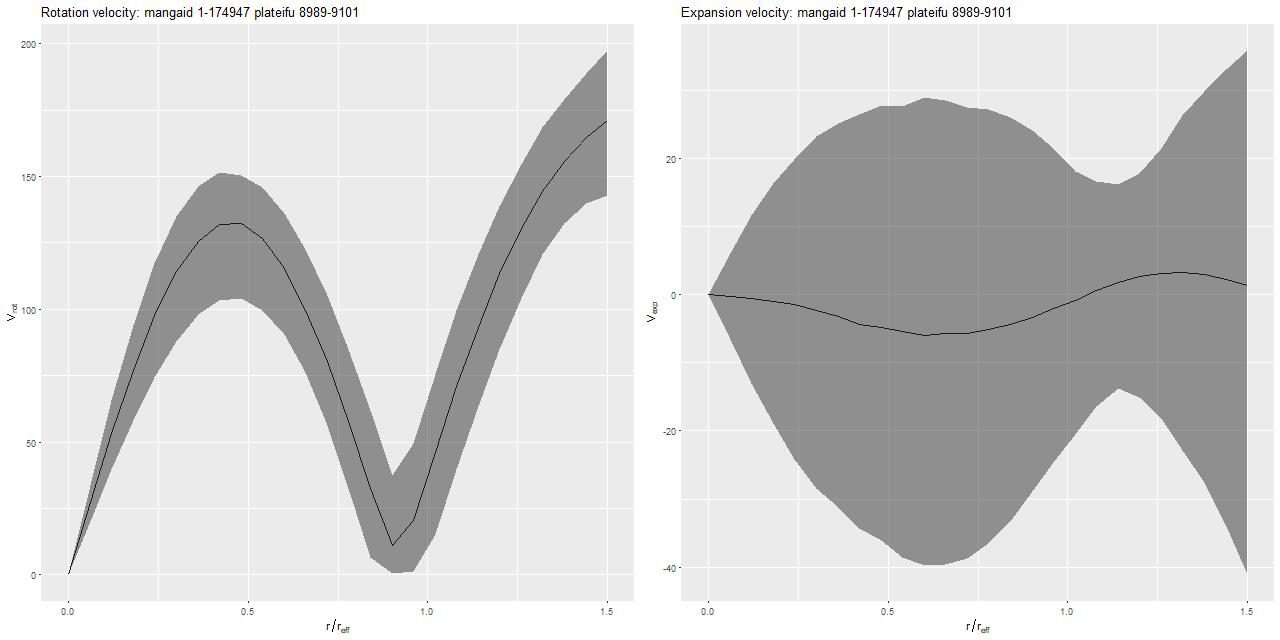
One thing this demonstrates is the versatility of the gaussian process model with a simple mean function (even if it’s wrong).