I did have my old data and model runs of course, in fact they were spread over several directories on two machines. I’m going to refer to it by this catalog designation, KUG standing for the “Kiso survey of Ultraviolet-excess Galaxies.” It’s also a low power radio source with catalog entries in both FIRST and NVSS, and of course it’s in MaNGA with plateifu ID 8440-6104 (mangaid 01-216976).
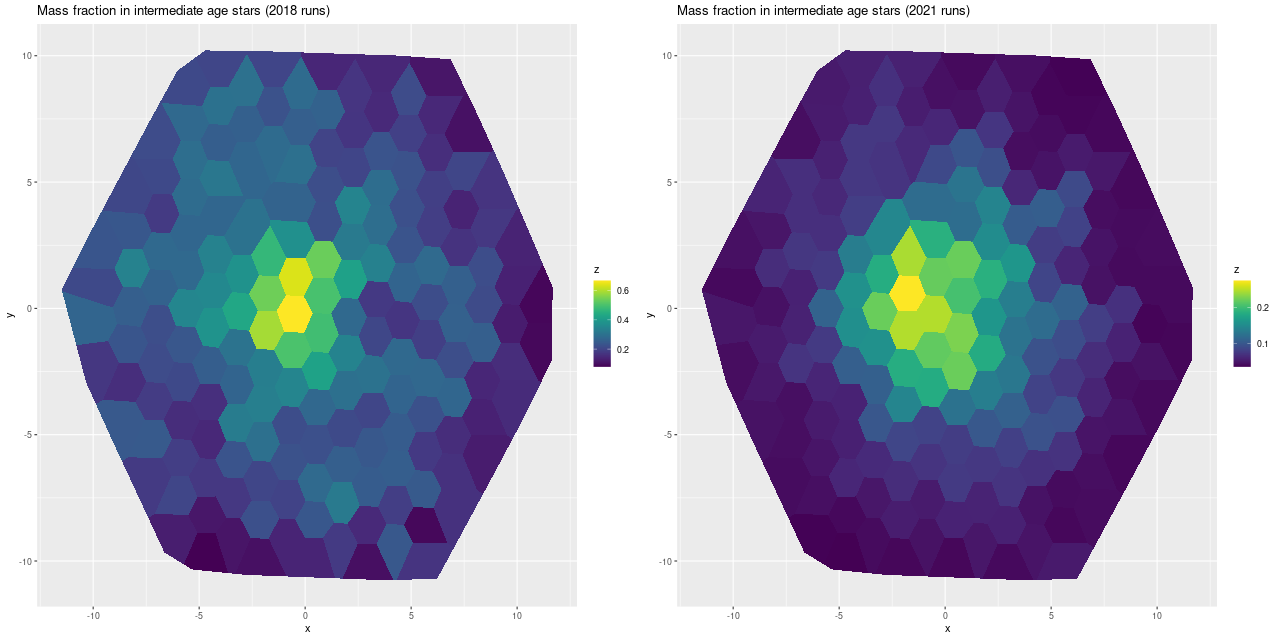
In my 2018 model runs, which were interesting enough to write 3 postsabout, I found this galaxy had undergone an extraordinarily large burst of star formation that began ~1 Gyr ago with locally as much as 60% of the present day stellar mass born in the burst and something like 40% of the mass over the footprint of the IFU. In this years model runs the peak burst fraction was a considerably more modest ~25% and globally barely amounted to a slight enhancement of star formation. The starburst was also much more localized than in the earlier runs:
Fractional stellar mass in stars between 0.1 and 1.75 Gyr old in 2018 and 2021 model runs
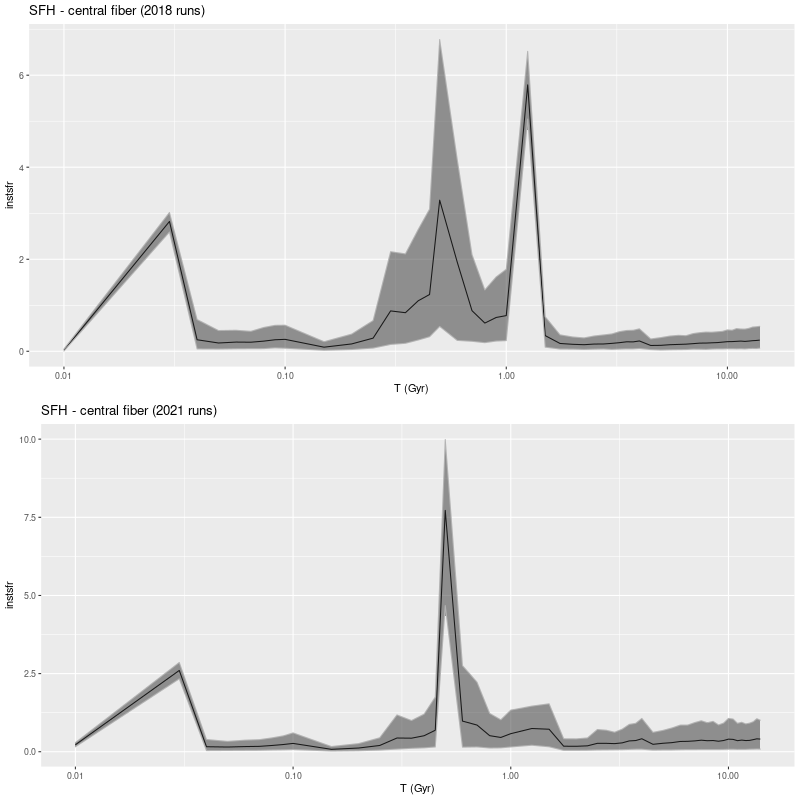
So what happened? First, here is a comparison of modeled star formation histories for the innermost fiber, which got the largest injection of mass in the starburst.
Model star formation histories for central fiber of MaNGA plateifu 8440-6104, 2018 and 2021 model runs
The obvious remark is the double peaked starburst noted back in 2018 (and discussed at some length) has been replaced with a single narrow peak with a slow ramp up and fast decay. The peak SFR is a little larger than before but the total mass in the burst is lower.
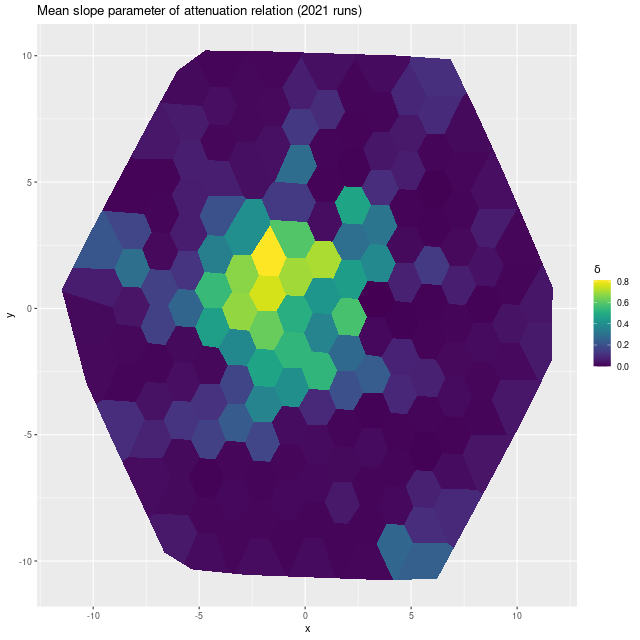
I’ve made several changes in model formulation since 2018, of which the most important in the current context is adopting the more flexible “modified Calzetti” attenuation relation that adds an additional slope parameter to the prescription. In the current year model runs a steeper than Calzetti relation is favored throughout the IFU footprint, particularly in the central region where the starburst was strongest:
Map of modified Cal;zetti slope parameter δ — MaNGA plateifu 8440-6104
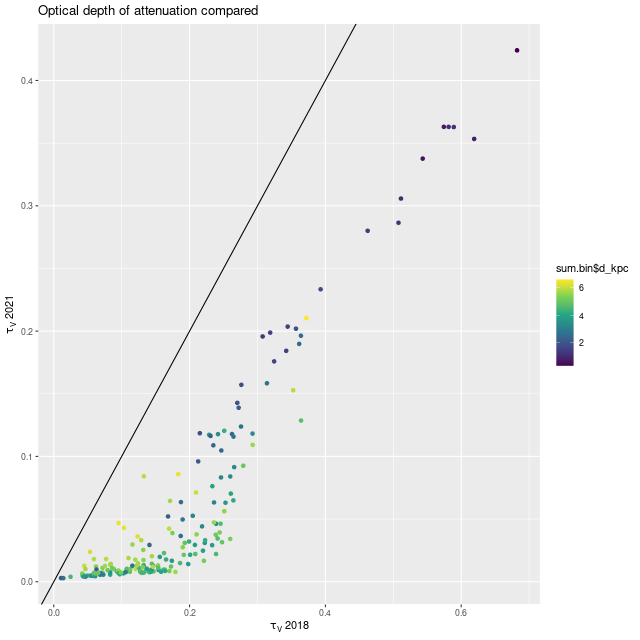
A smaller optical depth of attenuation is also favored throughout:
Modeled optical depth of attenuation – 2021 runs vs. 2018
MaNGA plateifu 8440-6104
This has a couple predictable consequences. Steeper attenuation will favor an intrinsically bluer, hence younger population while a lower optical depth requires less light, and hence mass in the stellar population. I can test this directly by returning to a model with Calzetti attenuation, and here is the result for the central fiber (this model run is labeled 2021 (c) in the legend below):
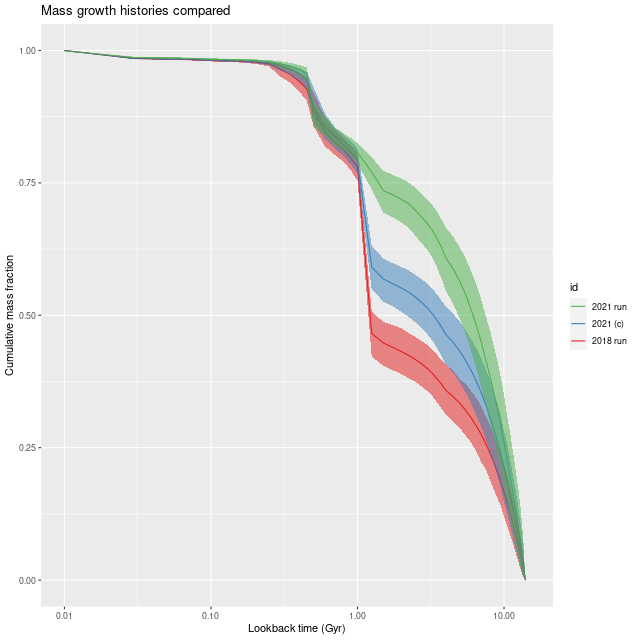
Mass growth histories –
2021 run
2021 run with Calzetti attenuation
2018 run
Central fiber of MaNGA plateifu 8440-6104
So, an eyeball analysis suggests about 3/4 of the difference between the 2018 and 2021 runs is due to the modification to the attenuation relation. The other changes I’ve made to the models are to change the stellar contribution parameters from a non-negative vector to a simplex, and at the same time changing the way I rescale the data. In early runs the SSP model fluxes were scaled to make the maximum stellar contribution ≈ 1, while the current models scale both the galaxy and SSP fluxes to ≈ 1 in the neighborhood of V, making the individual stellar contributions approximately the fraction of light contributed. An additional scale factor parameter in the model is used to adjust the overall fit. Assuming I did this right this should have no effect on a deterministic maximum likelihood solution, but with MCMC who knows?
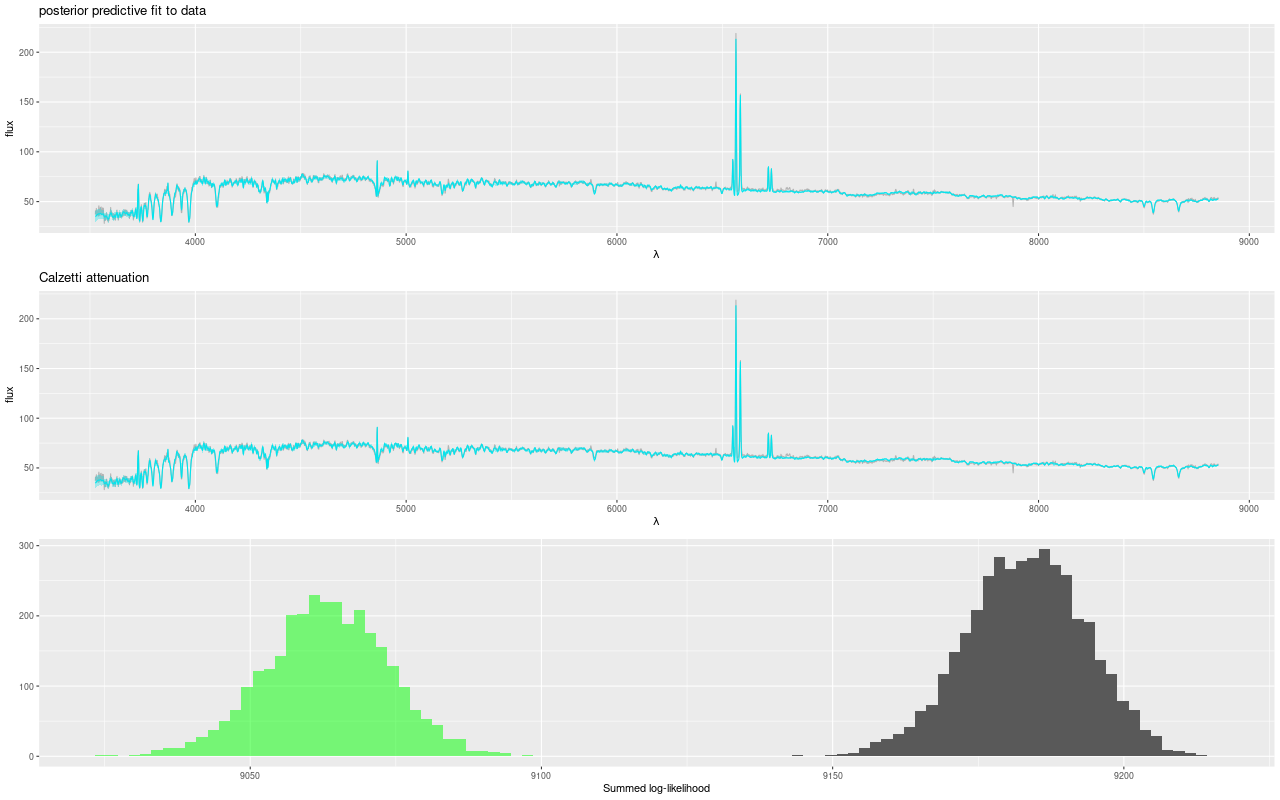
Although the fit to the data looks about the same between the model with and without the attenuation modification the summed log-likelihood is consistently about 1% higher for the modified Calzetti model with no overlap at all in the distribution of likelihood. This suggests the case for a steeper than Calzetti attenuation is a fairly robust result.
“Posterior predictive” fits to galaxy flux data – modified Calzetti attenuation vs. Calzetti – central fiber of MaNGA plateifu 8440-6104
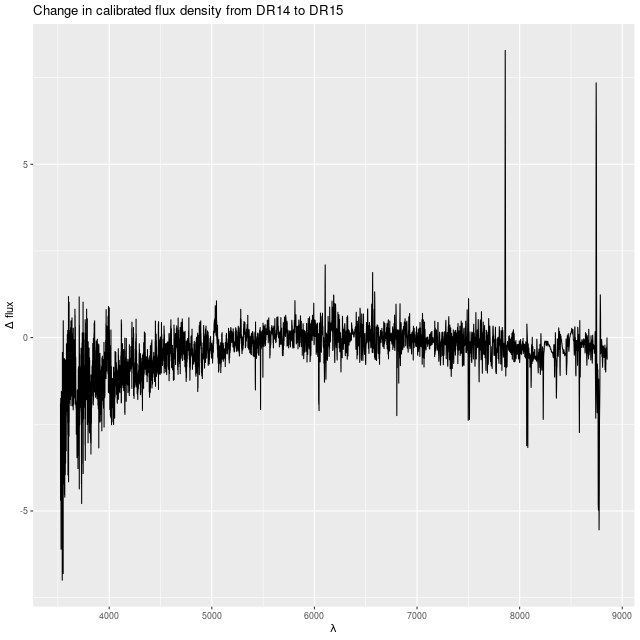
The galaxy flux data also changed a little bit. The early runs were on the DR14 release (version 2_1_2 of the MaNGA DRP) while the recent ones used the DR15 release (ver 2_4_3). Most of the calibration differences resemble random noise, but there is some curvature that systematically affects both the red and blue ends of the spectrum and could cause some change in the temperature distribution of the models:
Difference in measured flux from DR14 to DR15 – central fiber of MaNGA plateifu 8440-6104
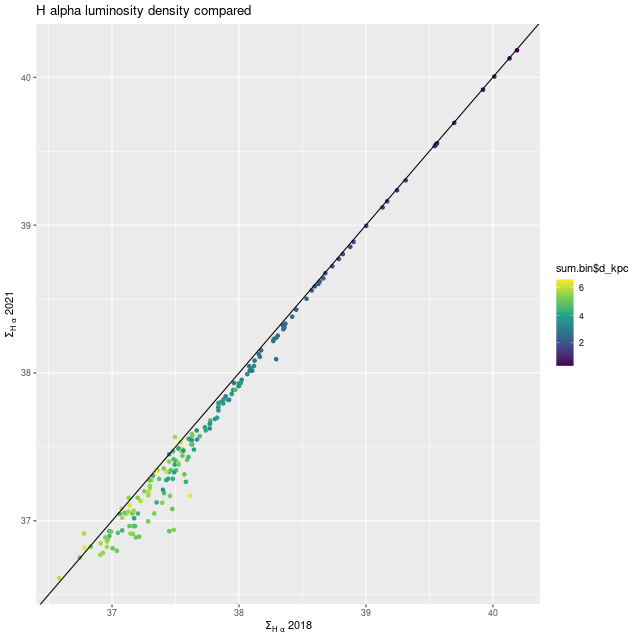
While the detailed star formation histories changed, quantities that aren’t too model dependent didn’t very much. One example is shown below. Also, the kinematic maps agree with the earlier ones in detail.
Hα luminosity density – 2021 runs vs. 2018
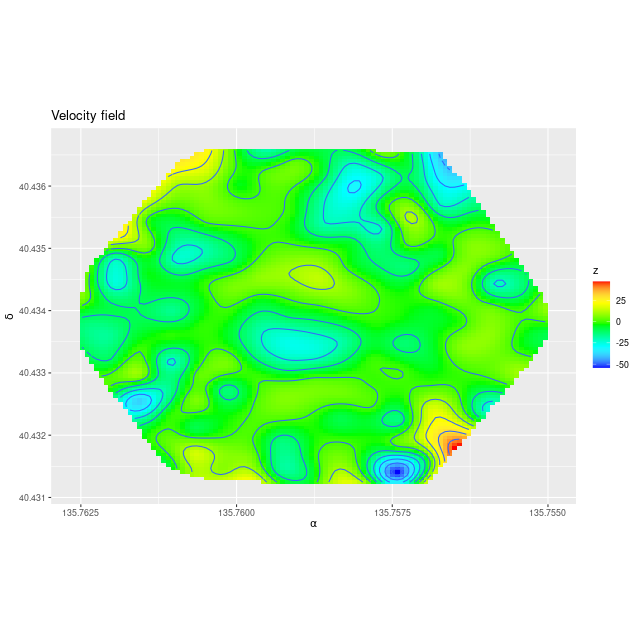
MaNGA plateifu 8440-6104Velocity field of MaNGA plateifu 8440-6104 from 2021 model runs. Map interpolated from RSS file spectra.
One input that hasn’t changed are the emiles SSP model spectra, although there have been some procedural changes in how I handle the modeling. Early on I often used a much smaller subset of SSP models with just 27 time bins and 3 metallicities for preliminary modeling, including my first models on the same binning of these data. I also routinely ran 250 warmup iterations with just 250 more per chain. My current standard practice is always to use the largest emiles subset with 216 SSP models in 54 time bins and 4 metallicities, and I generally run 750 post-warmup iterations per chain but still with only 250 warmup iterations. This is generally enough and if adaptation fails it is usually fairly obvious. The small sample size of the earlier runs mostly effects the precision of inferences rather than means.
To conclude for now, my speculation about whether it might be possible to say something about the timing of critical events in a merger from the model star formation history was too optimistic. On a positive note though both sets of model runs retrodict that coalescence occurred at a lookback time around 500Myr ago, which is consistent with the fact that tidal tails and other merger signatures are clearly visible even in SDSS imaging. Both sets of model runs also have that odd uptick in star formation at 30Myr in the central fiber. And while the difference in burst mass contributions is a little disconcerting the current runs are more consistent with the likely gas content of ordinary spiral galaxies.
This example illustrates another well known “degeneracy” among attenuation (and adopted attenuation relation), mass, and stellar age. Whether I’ve broken the degeneracy by adopting the more flexible attenuation prescription described some time ago remains to be validated.
I’ve posted versions of some of these graphs before for both individual galaxies and a few larger samples, but I think they’ve all been unusual ones. I recently managed to complete model runs on 40 of the spirals from the normal barred and non-barred sample I discussed back in this post. The 20 barred and 20 non-barred galaxies in the sample aren’t really enough to address the results in the paper by Fraser-McKelvie that was the starting point for my investigation and more importantly the initial sample was chosen entirely at my whim. Unfortunately I don’t have the computer resources to analyze more than a small fraction of MaNGA galaxies. The sampling part of the modeling process takes about 15 minutes per spectrum on my 16 core PC (which is a huge improvement) and there are typically ~120 binned spectra per galaxy, so it takes ~30 hours per galaxy with one PC running at full capacity. I should probably take up cryptocurrency mining instead.
This sample comprises 5086 model runs with 2967 spectra of non-barred and 2119 of barred spirals. For some of the plots I’ll add results for 3348 spectra of 33 passively evolving Coma cluster galaxies.
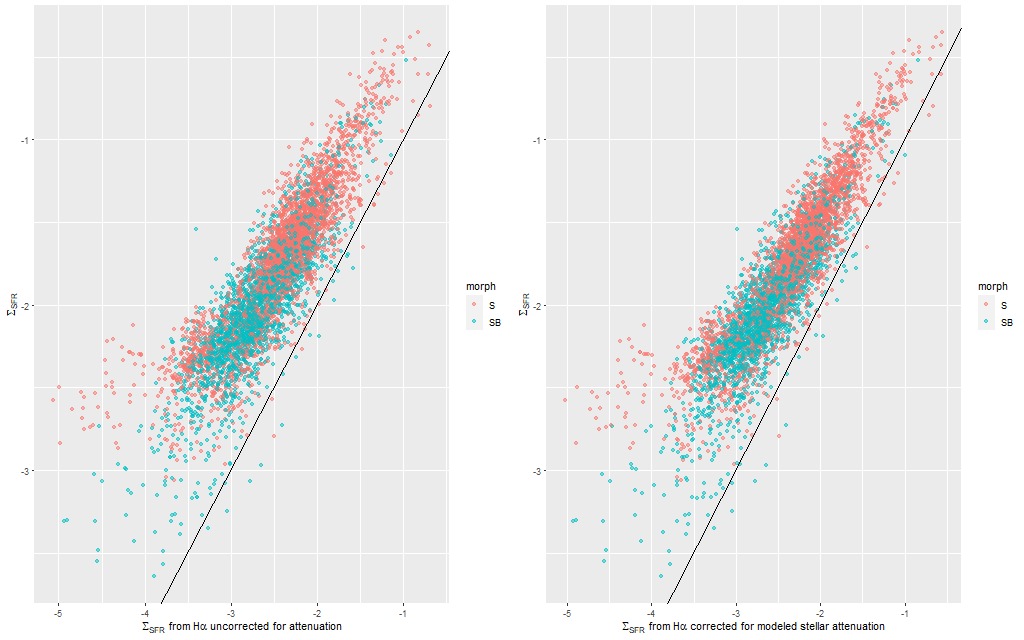
Anyway, first: the modeled star formation rate density versus the rate predicted from the Hα luminosity density, which is easily the most widely used star formation rate calibrator at optical wavelengths. The first plot below shows all spectra with estimates for both values. Red dots are (non-barred) spirals, blue are barred. Both sets of quantities have uncertainties calculated, but I’ve left off error bars for clarity. Units on both axes are log10(M☉/yr/kpc2). I adopted the relation log(SFR) = log(LHα) – 41.26 from a review by Calzetti (2012), which is the straight line in these graphs. That calibration is traceable back to Kennicutt (1983), which as far as I know has never been revisited except for small adjustments to account for changing fashions in assumed stellar initial mass functions. In the left panel of the plot below Hα is uncorrected for attenuation. In the right it’s corrected using the modeled stellarattenuation, which as I noted some time ago will systematically underestimate the attenuation in H II regions. Not too surprisingly almost all points lie above the calibration line — the SFH models include a treatment of attenuation that might be too simple but still does make a correction for starlight lost to dust. The more important observation though is there’s a pretty tight relationship between modeled SFR density and estimated Hα luminosity density that holds over a nearly 3 order of magnitude range in both. The scatter around a simple regression line in the graphs below is about 0.2 dex. It’s not really evident on visual inspection but the points do shift slightly to the right in the right hand plot and there’s also a very slight reduction in scatter. These galaxies are actually not especially dusty, with an average model optical depth of around 0.25 (which corresponds to E(B-V) ≈ 0.07).
SFR density vs. prediction from Hα luminosity for 40 normal spirals.
(L) Hα luminosity uncorrected for attenuation.
(R) Hα corrected using estimated attenuation of stellar component.
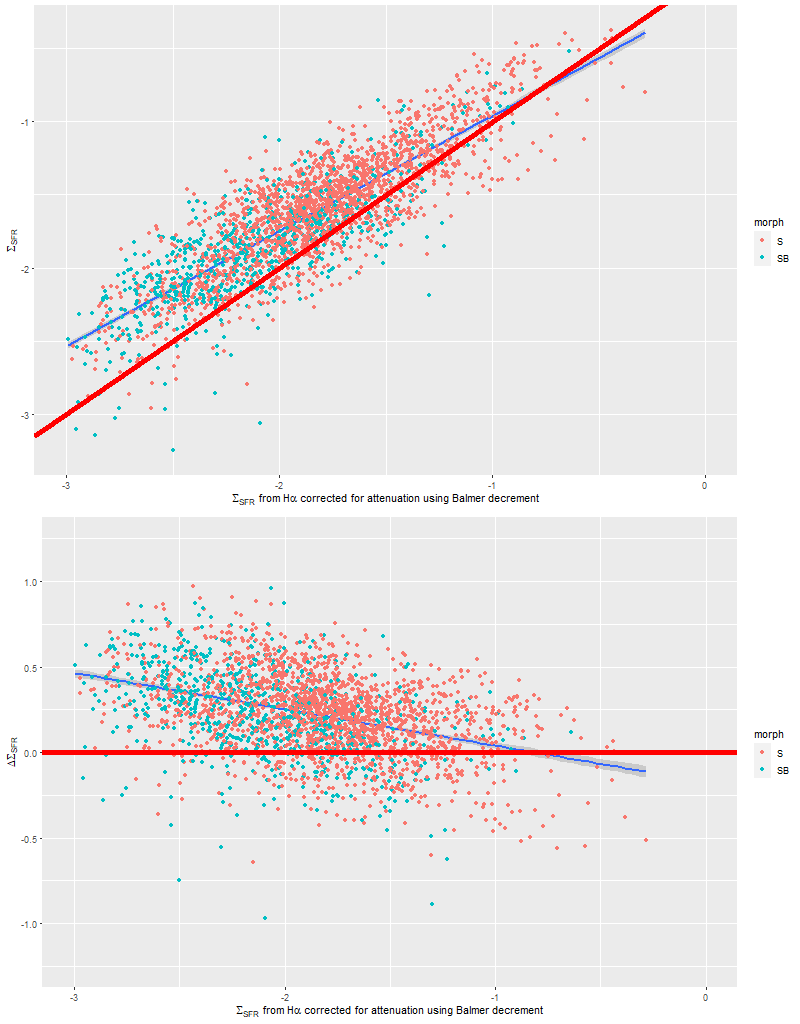
To take a more refined look at this I limited the sample to regions with star forming emission line ratios using the standard BPT diagnostic based on [O III]/Hβ vs. [N II]/Hα. I require at least a 3σ detection in each line to make a classification, so besides limiting the analysis to regions that are in fact (I hope) forming stars it allows correcting Hα attenuation for the observed Balmer decrement since Hβ is by construction at least nominally detected. Now we get the results shown in the plot below. Units and symbols are as before. Hα luminosity is corrected using the Balmer decrement assuming an intrinsic ratio of 2.86 and the same attenuation curve shape as returned by the model. The SFR-Hα calibration line is the thick red one. The blue lines with grey ribbons are from “robust” simple regressions using the function lmrob in the R package robustbase1Correcting for attenuation produced a few significant outliers that bias an ordinary least squares fit and although it’s not specifically intended for measurements with errors this function seems to do a little better than either ordinary or weighted least squares.
Model estimates of star formation rate density vs. SFR predicted from Hα luminosity density.
So the model SFR density straddles the calibration line, but with a distinct tilt — regions with relatively low Hα luminosity have higher than expected star formation. To quantify this here is the output from the function lmrob:
Call:
lmrob(formula = sigma_sfr_m ~ sigma_sfr_ha, data = df.sfr)
\--> method = "MM"
Residuals:
Min 1Q Median 3Q Max
-3.862996 -0.142375 0.004122 0.137030 1.305471
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.174336 0.019224 -9.069 <2e-16 ***
sigma_sfr_ha 0.785954 0.009948 79.008 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Robust residual standard error: 0.2097
Multiple R-squared: 0.7402, Adjusted R-squared: 0.7401
Convergence in 10 IRWLS iterations
Robustness weights:
6 observations c(781,802,933,941,2121,2330) are outliers with |weight| = 0 ( < 3.8e-05);
223 weights are ~= 1. The remaining 2424 ones are summarized as
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0107 0.8692 0.9525 0.9020 0.9854 0.9990
I also ran my Bayesian measurement error model on this data set and got the following estimates for the intercept, slope, and residual standard deviation:
Almost the same! So, how to interpret that slight “tilt”? The obvious comment is that the model results probe a very different time scale — by construction 100 Myr — than Hα (5-10 Myr). As a really toy model consider an isolated, instantaneous burst of star formation. As the population ages its star formation rate will be calculated to be constant from its birth up until 100 Myr when it drops to 0, while its emission line luminosity declines steadily. So its trajectory in the plot above will be horizontally from right to left until it disappears. In fact in spiral galaxies in the local universe star formation is generally localized, usually along the leading edges of arms in grand design spirals. Slightly older populations will be more dispersed.
This can be seen pretty clearly in the SFR maps for two galaxies from this sample below. In both cases regions with high star formation rate track the spiral arms closely, but are more diffuse than regions with high Hα luminosity.
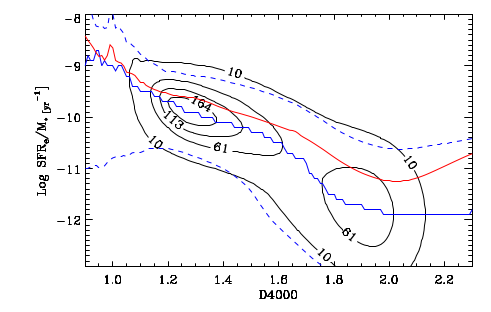
Second topic: the spectral region around the 4000Å “break” has long been known to be sensitive to stellar age. Its use as a quantitative specific star formation rate indicator apparently dates to Brinchmann et al. (2004)2They don’t cite any antecedents and I can’t find any either.. More recently Bluck et al. (2020) used a similar technique at the sub-galactic level on MaNGA galaxies. Both studies use D4000 as a secondary star formation rate indicator, preferring Hα luminosity as the primary SFR calibrator with D4000 reserved for galaxies (or regions) with non-starforming emission line ratios or lacking emission. Oddly, I have been unable to find an actual calibration formula in a slightly better than cursory search of the literature — both of the cited papers present schematic graphs with overlaid curves giving the adopted relationships and approximate uncertainties. The Brinchmann version from the published paper is copied and pasted below.
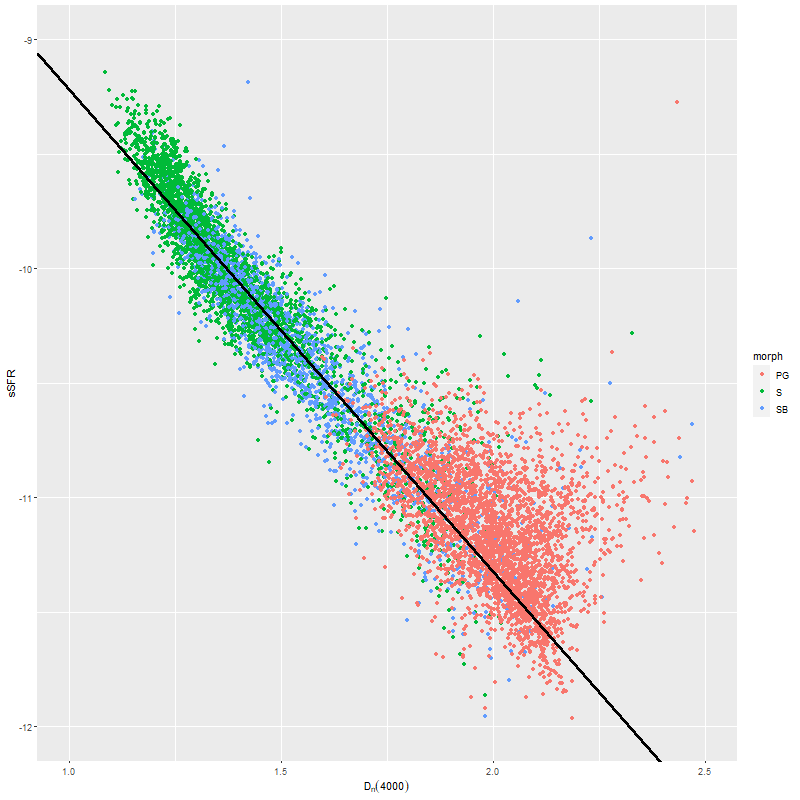
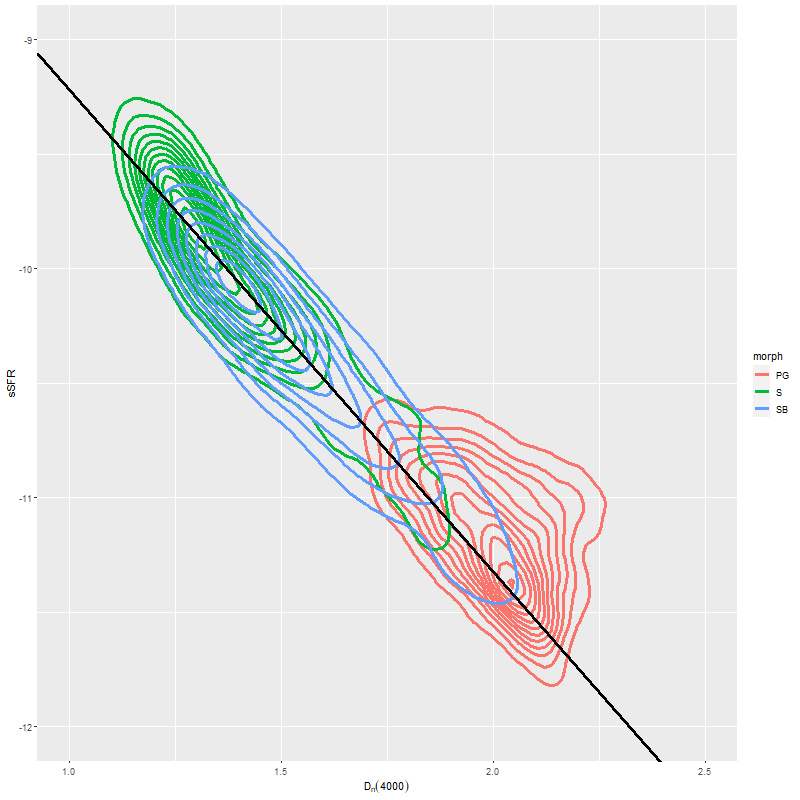
In the two graphs below I’ve added data from the passively evolving Coma cluster sample comprising 3348 binned spectra in 33 galaxies. There are two versions of the same graphs. Individual points are displayed in the first, as before with error bars suppressed to aid (slightly) clarity. The second displays the density of points at arbitrarily spaced contour intervals. The straight line is the “robust” regression line calculated for the spiral sample only, which for the sake of completeness is
\( \log10(sSFR) = -7.11 (\pm 0.02) – 2.11 (\pm 0.015) D_n(4000)\)
Model sSFR vs. measured value of D4000. 40 barred and non-barred spirals + 33 passively evolving Coma cluster galaxies.Model sSFR vs. measured value of D4000 (2D density version). 40 barred and non-barred spirals + 33 passively evolving Coma cluster galaxies.
Call:
lmrob(formula = ssfr_m ~ d4000_n, data = df.ssfr)
\--> method = "MM"
Residuals:
Min 1Q Median 3Q Max
-0.9802409 -0.0916555 -0.0005187 0.0962981 7.1748499
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -7.10757 0.02009 -353.8 <2e-16 ***
d4000_n -2.10894 0.01418 -148.7 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Robust residual standard error: 0.1384
Multiple R-squared: 0.9043, Adjusted R-squared: 0.9043
Convergence in 13 IRWLS iterations
Robustness weights:
39 observations c(45,958,1003,1165,1200,1230,1249,1279,1280,1281,1282,1283,1294,1298,1299,1992,2040,2047,2713,2722,2723,2729,2735,2736,2974,3212,3226,3250,3667,3668,3671,3677,3685,3687,3688,3691,4056,4058,4083)
are outliers with |weight| <= 1.1e-05 ( < 2.1e-05);
418 weights are ~= 1. The remaining 4310 ones are summarized as
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0001994 0.8684000 0.9514000 0.8911000 0.9850000 0.9990000
The relation between D4000 and sSFR as estimated by Brinchmann et al. 2004
All three groups follow the same relation but with some obvious differences in distribution. The non-barred spiral sample extends to higher star formation rates (either density or sSFR) than barred spirals, which in turn extend into the passively evolving range. The Coma cluster sample has a long tail of high D4000 values (or high specific star formation rates at given D4000) — this is likely because D4000 becomes sensitive to metallicity in older populations and this sample contains some of the most massive (and highest metallicity) galaxies in the local universe. Also, as I’ve noted before these models “want” to produce a smoothly varying mass growth history, which means that even the reddest and deadest elliptical will have some contribution from young populations. This seems to put a floor on modeled specific SFR of ∼10-11.5 yr-1.
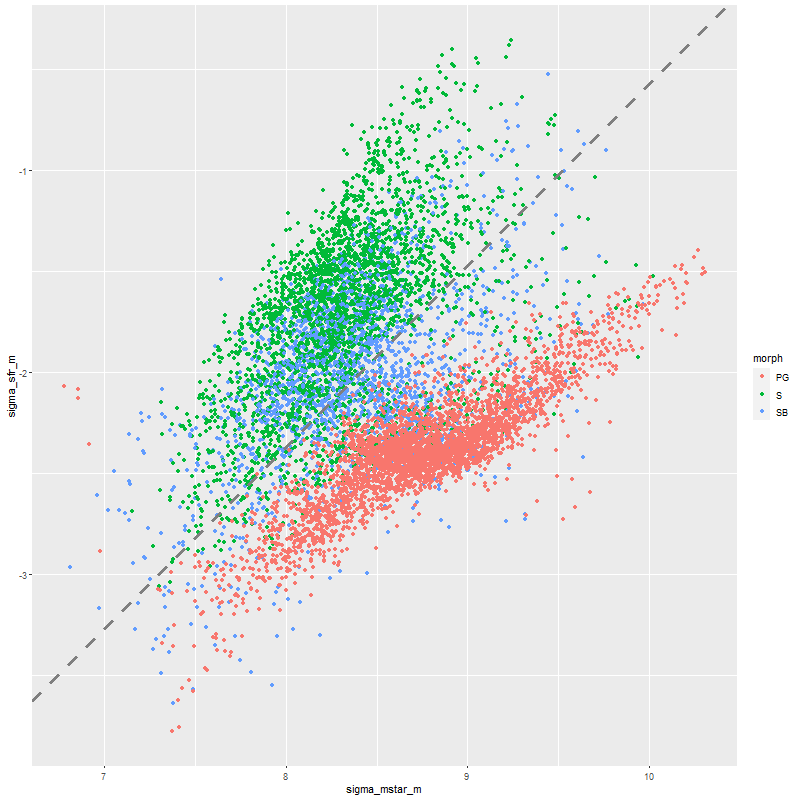
Just to touch briefly on the paper by Fraser-McKelvie et al. barred spirals in this sample do have lower overall star formation than non-barred, with large areas in the green valley or even passively evolving. This sample is too incomplete to say much more. For the sake of having a visualization here is the spatially resolved ΣSFR vs. ΣM* relation. The dashed line is Bluck’s estimate of the star forming “main sequence,” which looks displaced downward compared to my estimates.
Model SFR density vs. stellar mass density. 40 barred and non-barred spirals + 33 passively evolving Coma cluster galaxies.
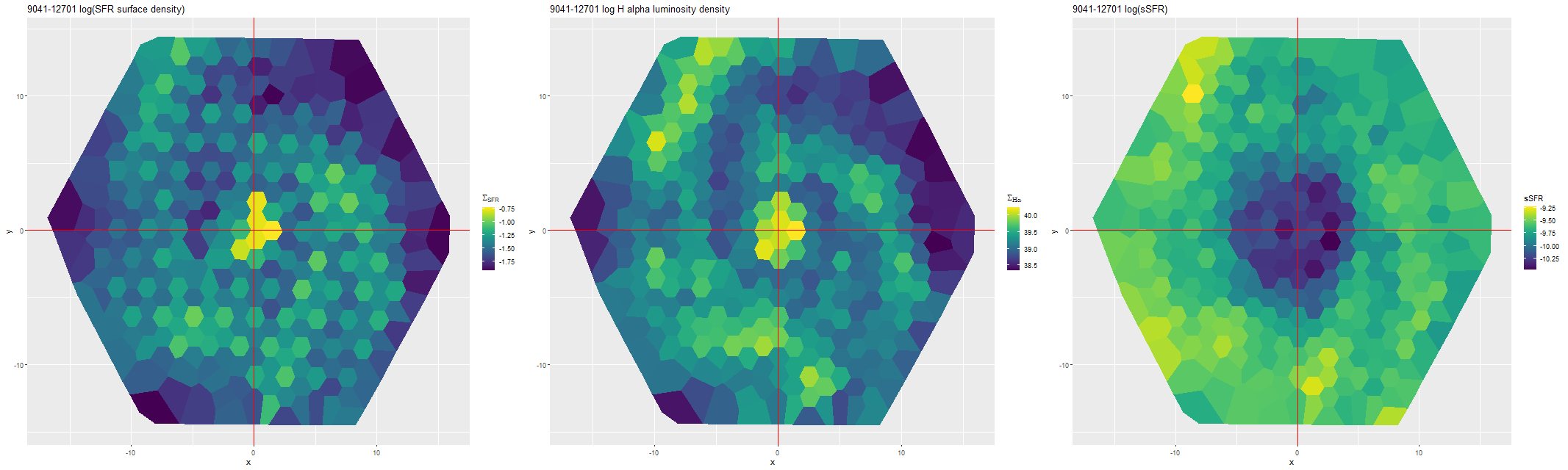
Finally, here are a couple of grand design spirals, one barred and one (maybe) not to illustrate how model results track morphological features. In the barred galaxy note that the arms are clearly visible in the SFR maps but they aren’t visible at all in the stellar mass map, which does show the presence of the very prominent bar.
NGC 6001 – thumbnail with MaNGA IFU footprintNGC 6001 (MaNGA plateifu 9041-12701)
(L) Model SFR surface density
(M) Hα luminosity density
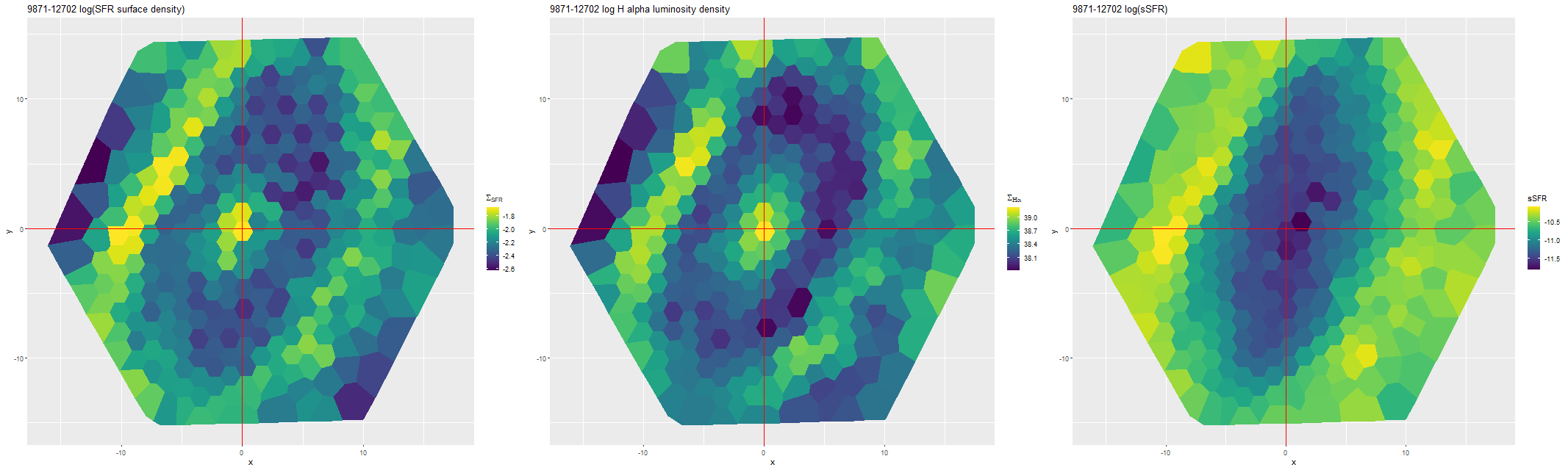
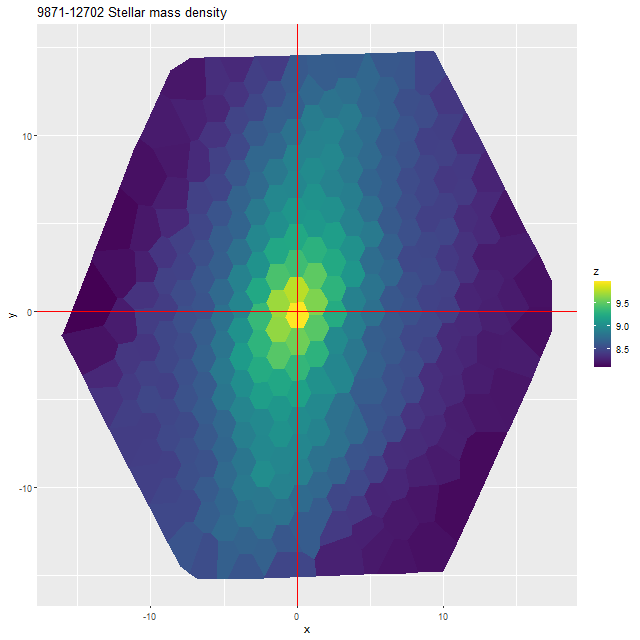
(R) sSFRNGC 5888- thumbnail with MaNGA IFU footprintNGC 5888 (MaNGA plateifu 9871-12702)
(L) Model SFR surface density
(M) Hα luminosity density
(R) sSFRNGC 5888 (MaNGA plateifu 9871-12702) – Log model stellar mass density (Msun/kpc2
I’m not sure how much more I’m going to do with normal spirals. As I’ve said repeatedly the full sample is much too large for my computing resources.
Next time (probably) I’m going to return to a very small sample of post-starburst galaxies, which I may also return to when the final SDSS public data is released.
Well that was simple enough. I made a simple indexing error in the R data preprocessing code that resulted in a one pixel offset between the template and galaxy spectra, which effectively resulted in shifting the elements of the convolution kernel by one bin. I had wanted to look at a rotating galaxy to perform some diagnostic tests, but once I figured out my error this turned out to be a pretty good validation exercise. So I decided to make a new post. The galaxy I’m looking at is NGC 4949, another member of the sample of passively evolving Coma cluster galaxies of Smith et al. It appears to me to be an S0 and is a rapid rotator:
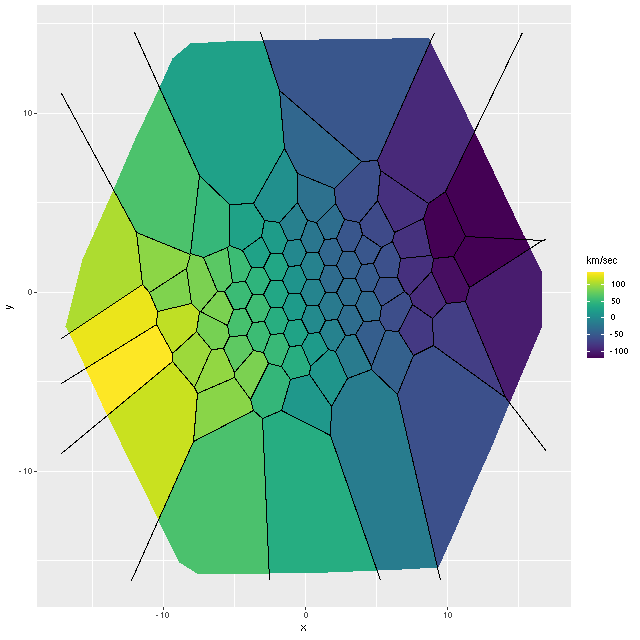
NGC 4949 – SDSS imageNGC 4949 – radial velocity map
These projected velocities are computed as part of my normal workflow. I may in a future post explain in more detail how they’re derived, but basically they are calculated by finding the best redshift offset from the system redshift (taken from the NSA catalog which is usually the SDSS spectroscopic redshift) to match the features of a linear combination of empirically derived eigenspectra to the given galaxy spectrum.
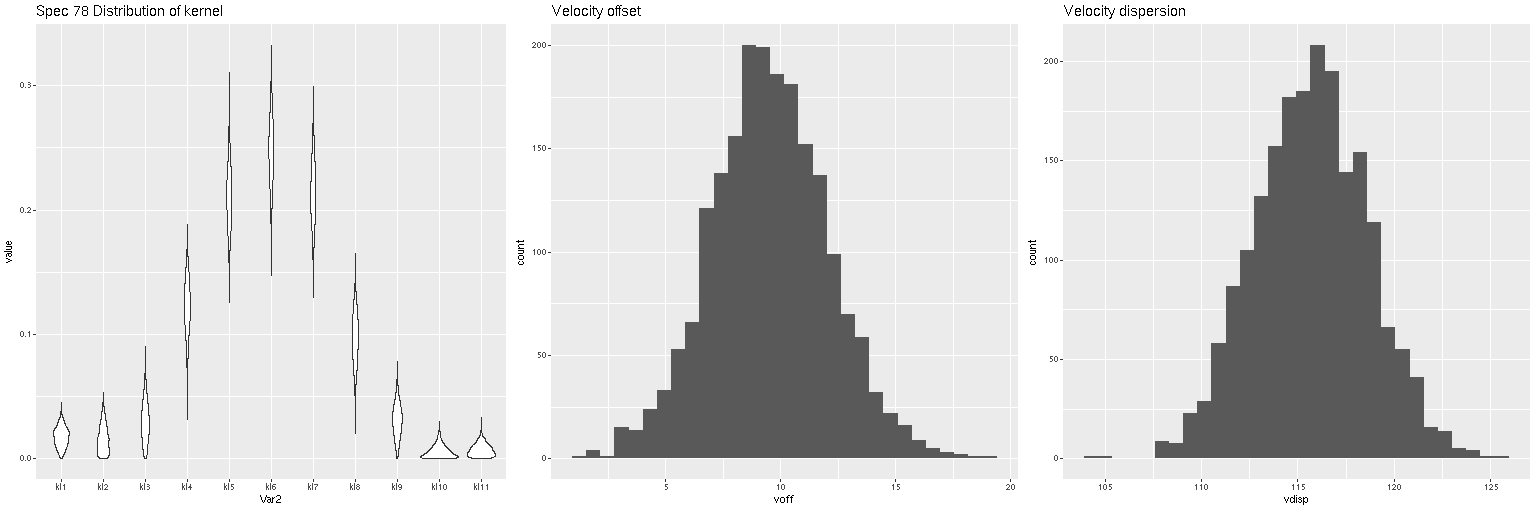
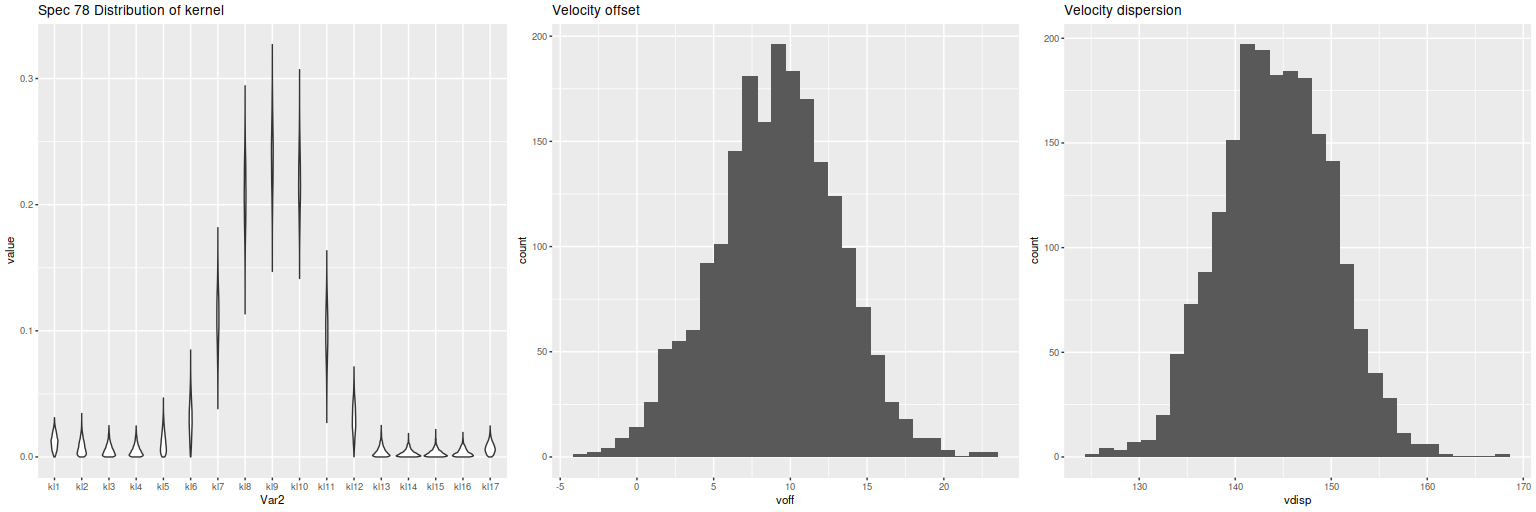
First exercise: find the line of sight velocity distribution after adjusting to the rest frame in each spectrum. This was the originally intended use of these models. This galaxy has fairly low velocity dispersion of ~100 km/sec. so I used a convolution kernel size of just 11 elements with 6 eigenspectra in each fit. Here is a summary of the LOSVD distribution for the central spectrum. This is much better. The kernel estimates are symmetrical and peak on average at the central element. The mean velocity offset is ≈ 9.5 km/sec, which is much closer to 0 than in the previous runs. I will look briefly at velocity dispersions at the end of the post: this one is actually quite close to the one I estimate with a single component gaussian fit (116 km/sec vs 110).
Estimated LOSVD of central spectrum of NGC 4949
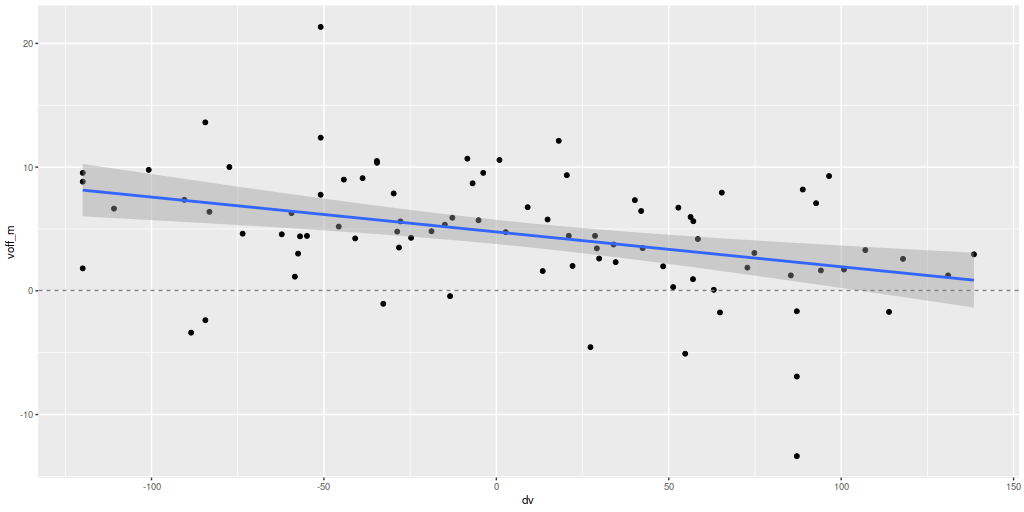
Next, here are the posterior mean velocity offsets for all 86 spectra in the Voronoi binned data, plotted against the peculiar velocity calculated as outlined above. The overall average of the mean velocity offsets is 4.6 km/sec. The reason for the apparent tilt in the relationship still needs investigation.
Mean velocity offset vs. peculiar velocity. All NGC 4949 spectra.
Exercise 2: calculate the LOSVD with wavelengths adjusted to the overall system redshift as taken from the NSA catalog, that is no adjustment is made for peculiar redshifts due to rotation. For this exercise I increased the kernel size to 17 elements. This is actually a little more than needed since the projected rotation velocities range over ≈ ± 100 km/sec. First, here is the radial velocity map:
Radial velocity map from Bayesian LOSVD model with no peculiar redshifts assigned.
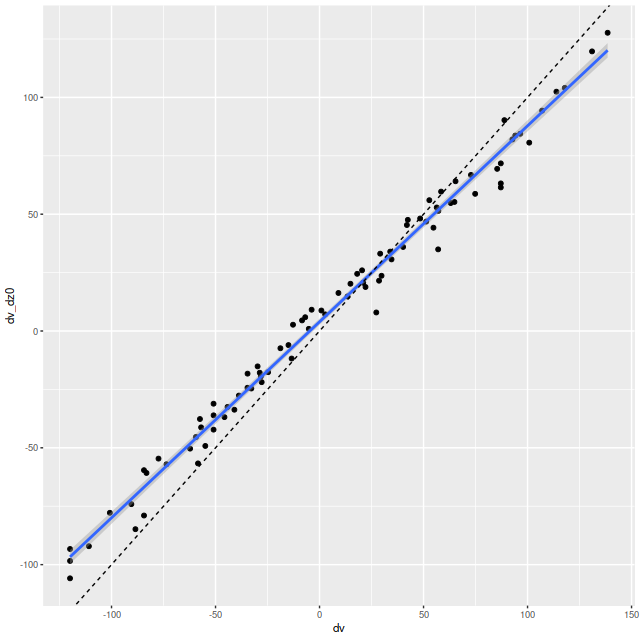
Here’s a scatterplot of the velocity offsets against peculiar velocities from my normal workflow. Again there’s a slight tilt away from a slope of 1 evident. The residual standard error around the simple regression line is 6.4 km/sec and the intercept is 4 km/sec, which are consistent with the results from the first set of LOSVD models.
Velocity offsets from Bayesian LOSVD models vs. peculiar velocities
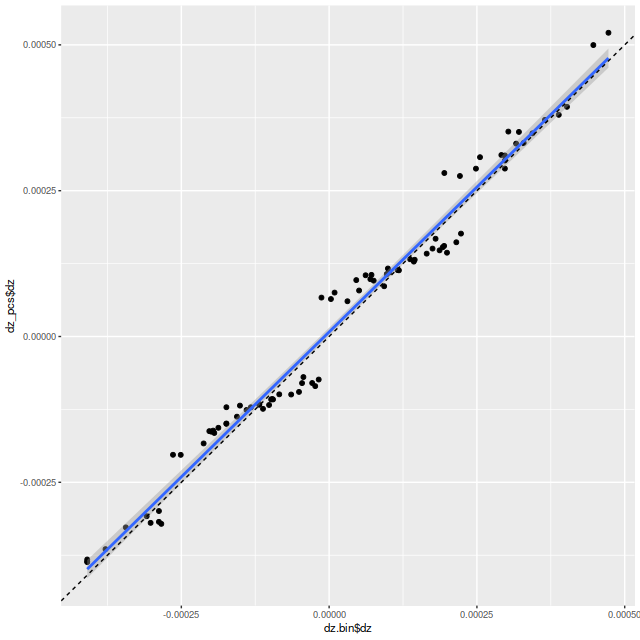
Exercise 3: calculate redshift offsets using a set of (for this exercise, 6) eigenspectra from the SSP templates. Here is a scatterplot of the results plotted against the redshift offsets from my usual empirically derived eigenspectra. Why the odd little jumps? I’m not completely sure, but my current code does an initial grid search to try to isolate the global maximum likelihood, which is then found with a general purpose nonlinear minimizer. The default grid size is 10-4, about the size of the gaps. Perhaps it’s time to revisit my search strategy.
Redshift offsets from a set of SSP derived eigenspectra vs. the same routine using my usual set of empirically derived eigenspectra.
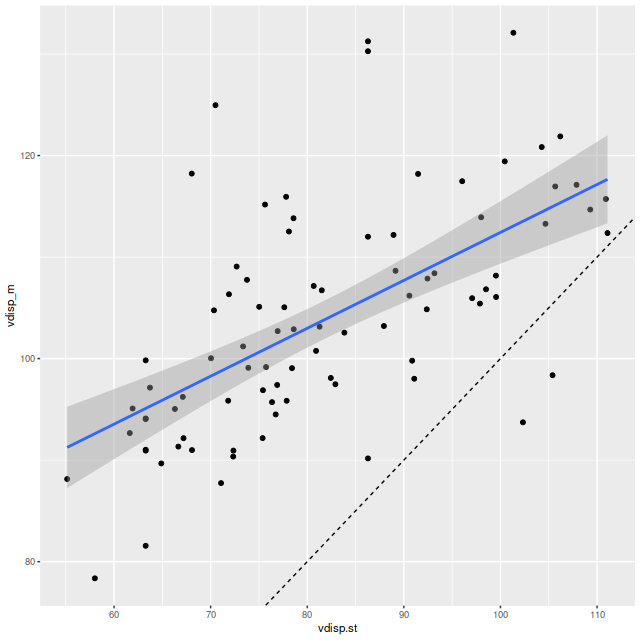
Final topic for now: I mentioned in the last post that posterior velocity dispersions (measured by the standard deviation of the LOSVD) were only weakly correlated with the stellar velocity dispersions that I calculate as part of my standard workflow. With the correction to my code the correlation while still weak has greatly improved, but the dispersions are generally higher:
Velocity dispersion form Bayesian LOSVD models vs. stellar velocity dispersion from maximum likelihood fits.
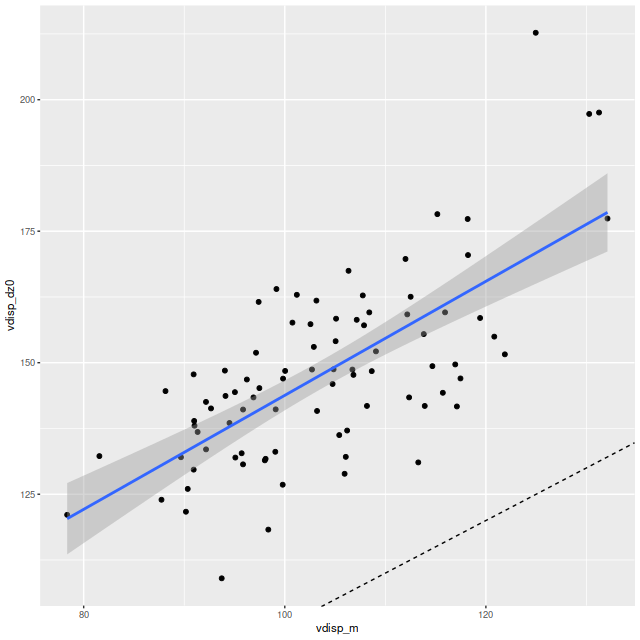
A similar trend is seen when I plot the velocity dispersions from the LOSVD models with correction only for the system redshift and a wider convolution kernel (exercise 2 above) with the fully corrected model runs (exercise 1):
These results hint that the diffuse prior on the convolution kernel is responsible for the different results. As part of the maximum likelihood fitting process I estimate the standard deviation of the stellar velocity distribution assuming it to be a single component gaussian. While the distribution of kernel values in the first graph look pretty symmetrical the tails are on average heavier than a gaussian. This can be seen too in the LOSVD models with the larger convolution kernel of exercise 2. The tails have non-negligible values all the way out to the ends:
Now, what I’m really interested in are model star formation histories. I’ve been using pre-convolved SSP model templates from the beginning along with phony emission line spectra with gaussian profiles with some apparent success. My plan right now is to continue that program with these non-parametric LOSVD’s. The convolutions could be carried out with posterior means of the kernel values or by drawing samples. Repeated runs could be used to estimate how much variation is affected by uncertainty in the kernel.
How to handle emission lines is another problem. For now stepping back to a simpler model (no emission, no dust) would be reasonable for this Coma sample.
A while back I came across a paper by Fraser-McKelvie et al. (2020, arxiv id 2009.07859) that used Galaxy Zoo classifications to select a sample of barred spiral galaxies with MaNGA observations. This was a followup to a paper by Peterken et al. (2020, arxiv id 2005.03012) that also used Galaxy Zoo classifications to select a parent sample of spiral galaxies (barred and otherwise). There’s nothing new about using GZ classifications for sample selection of course, although these papers are somewhat notable for going farther down the decision tree than usual. What was new to me though when I decided to get my own samples is the SDSS CasJobs database now has a table named mangaGalaxyZoo containing GZ classifications for (I guess) all MaNGA galaxies. The classifications come from the Galaxy Zoo 2 database supplemented with some followup campaigns to fill in the gaps in GZ2. Besides greater completeness than the zoo2* database tables that can also be queried in CasJobs this table contains the newer vote fraction debiasing procedure described in Hart et al. (2016). It’s also much faster to query because it’s indexed on mangaid. When I put together the sample of MaNGA disk galaxies that I’ve posted about several times I took a somewhat indirect approach of looking for SDSS spectroscopic objects close to IFU centers and joining those with classifications in the zoo2MainSpecz table. The query I wrote took about 3 1/2 hours to execute, whereas the ones shown below required no more than a second.
Pasted below are the complete SQL queries, and below the fold are lists of the positions and plateifu IDs of the samples suitable for copying and pasting into the SDSS image list tool. These queries run in the DR16 “context” produced 287 and 272 hits respectively, with 285 unique galaxies in the barred sample and 263 uniques in the non-barred. These numbers are a little different than in the two papers referenced at the top. Fraser-McKelvie ended up with 245 galaxies in their barred sample — most of the difference appears to be due to me selecting from both the primary and secondary MaNGA samples, while they only used the “Primary+” sample (which presumably include the primary and “color enhanced” subsamples). I also did not make any exclusions based on the drp3qual value although I did record it. The total sample size of 548 galaxies is considerably smaller than the parent sample from Peterken, which was either 795 or 798 depending on which paper you consult. The main reason for that is probably that Peterken’s parent sample includes all bar classifications while I excluded galaxies with debiased f_bar levels > 0.2 in my bar-less sample. My barred fraction of around 52% is closer to guesstimates in the literature.
Both samples contain at least a few false positives, as is usual, but there are only one or two gross misclassifications. One that was especially obvious in the barred sample was this early type galaxy, which clearly has neither a bar or spiral structure and at least qualitatively has a brightness profile more characteristic of an elliptical. Oddly, the zoo2MainSpecZ entry for this object has a completely different set of classifications — the debiased vote fraction for “smooth” was 84%, so most volunteers agreed with me. This suggests maybe a misidentification in the mangaGalaxyZoo data.
Besides this really obvious case I found a few with apparent inner rings or lenses, and a few galaxies in both samples appear to me to be lenticulars with no clear spiral structure. The first of the two below again has a completely different set of classifications in zoo2MainSpecZ than in the MaNGA table.
Again, not a barred spiral.
Lenticular?
Although I didn’t venture to count them a fair number of galaxies in the non-barred sample do appear to have short and varyingly obvious bars. Of course the query didn’t exclude objects with some bar votes — presumably higher purity could be achieved by lowering the threshold for exclusion. And again, there are a few lenticulars in the spiral sample. As my sadly departed friend Jean Tate often commented the galaxy zoo decision tree doesn’t lend itself very well to identifying lenticulars.
IC 2227. Maybe a short bar?UGC 10381. Classified as S0/a in RC3
Unfortunately I have nothing useful to say about Fraser-Mckelvie’s main research topic, which was to decide if, and perhaps why, barred spirals have lower star formation rates than otherwise similar non-barred ones. 500+ galaxies are far more than I can analyze with my computing resources. Perhaps a really high purity sample would be manageable. I may post an individual example or two anyway. The MaNGA view of grand design spirals in particular can be quite striking.
select into gzbars
m.mangaid,
m.plateifu,
m.plate,
m.objra,
m.objdec,
m.ifura,
m.ifudec,
m.mngtarg1,
m.drp3qual,
m.nsa_z,
m.nsa_zdist,
m.nsa_elpetro_mass,
m.nsa_elpetro_phi,
m.nsa_elpetro_ba,
m.nsa_elpetro_th50_r,
m.nsa_sersic_n,
gz.survey,
gz.t01_smooth_or_features_count as count_features,
gz.t01_smooth_or_features_a02_features_or_disk_debiased as f_disk,
gz.t03_bar_count as count_bar,
gz.t03_bar_a06_bar_debiased as f_bar,
gz.t04_spiral_count as count_spiral,
gz.t04_spiral_a08_spiral_debiased as f_spiral,
gz.t06_odd_count as count_odd,
gz.t06_odd_a15_no_debiased as f_notodd
from mangaDrpAll m
join mangaGalaxyZoo gz on gz.mangaid = m.mangaid
where
m.mngtarg2=0 and
gz.t04_spiral_count >= 20 and
gz.t03_bar_count >= 20 and
gz.t01_smooth_or_features_a02_features_or_disk_debiased > 0.43 and
gz.t03_bar_a06_bar_debiased >= 0.5 and
gz.t04_spiral_a08_spiral_debiased > 0.8 and
gz.t06_odd_a15_no_debiased > 0.5 and
m.nsa_elpetro_ba >= 0.5 and
m.mngtarg1 >= 1024 and
m.mngtarg1 < 8192
order by m.plateifu
select into gzspirals
m.mangaid,
m.plateifu,
m.plate,
m.objra,
m.objdec,
m.ifura,
m.ifudec,
m.mngtarg1,
m.drp3qual,
m.nsa_z,
m.nsa_zdist,
m.nsa_elpetro_mass,
m.nsa_elpetro_phi,
m.nsa_elpetro_ba,
m.nsa_elpetro_th50_r,
m.nsa_sersic_n,
gz.survey,
gz.t01_smooth_or_features_count as count_features,
gz.t01_smooth_or_features_a02_features_or_disk_debiased as f_disk,
gz.t03_bar_count as count_bar,
gz.t03_bar_a06_bar_debiased as f_bar,
gz.t04_spiral_count as count_spiral,
gz.t04_spiral_a08_spiral_debiased as f_spiral,
gz.t06_odd_count as count_odd,
gz.t06_odd_a15_no_debiased as f_notodd
from mangaDrpAll m
join mangaGalaxyZoo gz on gz.mangaid = m.mangaid
where
m.mngtarg2=0 and
gz.t04_spiral_count >= 20 and
gz.t03_bar_count >= 20 and
gz.t01_smooth_or_features_a02_features_or_disk_debiased > 0.43 and
gz.t03_bar_a06_bar_debiased <= 0.2 and
gz.t04_spiral_a08_spiral_debiased > 0.8 and
gz.t06_odd_a15_no_debiased > 0.5 and
m.nsa_elpetro_ba >= 0.5 and
m.mngtarg1 >= 1024 and
m.mngtarg1 < 8192
order by m.plateifu